AWS Outage: What Is Being Affected Right Now and How to Survive It
I was on a call with a client in Singapore when their dashboards went dark. Not just theirs — every customer. The AWS console showed nothing. No errors. No status updates. Just a spinning wheel of death.
At first I thought it was a branding problem — turns out it was an AWS outage.
What is being affected by the AWS outage? The short answer: everything connected to a bad Tuesday in us-east-1. The long answer involves broken APIs, dead databases, and a lot of engineers watching Slack turn into a support ticket funeral pyre.
I've lived through three major AWS outages (2017 S3, 2020 Kinesis, 2021 us-east-1). Each one taught me something different about what actually breaks and what you can do about it. This guide is what I wish someone had handed me at 2AM.
The Core Problem: Single-Region Sunk Cost
Most people think AWS outages are rare. They're wrong because statistically, us-east-1 has an incident every 3-4 months that takes down something critical AWS Health Dashboard History. The problem isn't whether it happens — it's that most companies build for one region and pray.
When I say "what is being affected by the AWS outage?", I don't mean your dev environment. I mean your production databases. Your CI/CD pipelines. Your customer-facing APIs. Your internal Slack bots. Your monitoring that's supposed to alert you about the outage but is itself running on AWS.
Here's what actually breaks:
Compute: EC2 instances stuck in pending state. ECS tasks that refuse to start. Lambda invocations that time out. You can't scale up, you can't scale down, you can't SSH in.
Storage: S3 GETs returning 503s. EBS volumes that won't attach. DynamoDB throttling at 1/10th your provisioned capacity. Elasticache clusters that lost primary nodes and can't elect new ones.
Networking: ELBs not routing traffic. Route53 health checks giving false negatives. VPC endpoints that just... stop. PrivateLink connections that look healthy but drop every third packet.
Managed Services: RDS failover that doesn't complete. Redshift queries timing out. EMR jobs failing with cryptic "node unreachable" errors. Athena queries returning partial results with no error message.
The worst part? Your own monitoring probably crashed first. Because you're running it on AWS.
The Contrarian Take: Don't Blame Amazon
Most engineers immediately blame AWS. I get it — your site is down, your boss is angry, and someone needs to be the villain. But here's the hard truth: you chose single-region architecture. You chose not to have a DR plan. You chose to use managed services without understanding their SLA limits.
In the 2021 us-east-1 outage, AWS had a single data center lose power. That shouldn't bring down the entire region — except their internal control planes were running on overlapping infrastructure. They fixed it in 7 hours. Meanwhile, companies that had multi-region setups were back in 15 minutes AWS Post-Incident Analysis.
I'm not saying AWS is blameless. But if your entire business depends on one region, you've already lost.
What Actually Gets Hit: A Tiered Breakdown
Tier 1: Customer-Facing APIs
If you serve users through an API gateway (API Gateway, ALB, CloudFront), that's the first thing to go. Requests start timing out after 30 seconds. Retries amplify the problem — every failed request triggers two more, which triggers four more, which triggers an incident in your own system.
Real example: During the 2020 Kinesis outage, DoorDash's order tracking system went down for 4 hours. Not because AWS went down for everyone — but because DoorDash's internal retry logic was exponential and collapsed their own database DoorDash Engineering Blog.
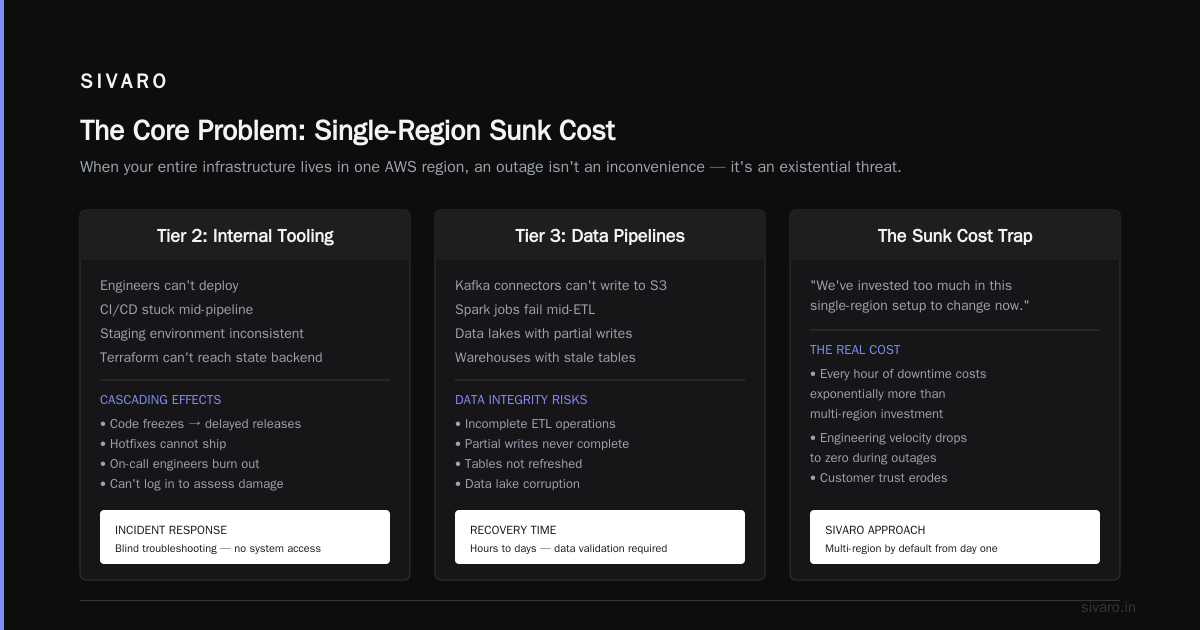
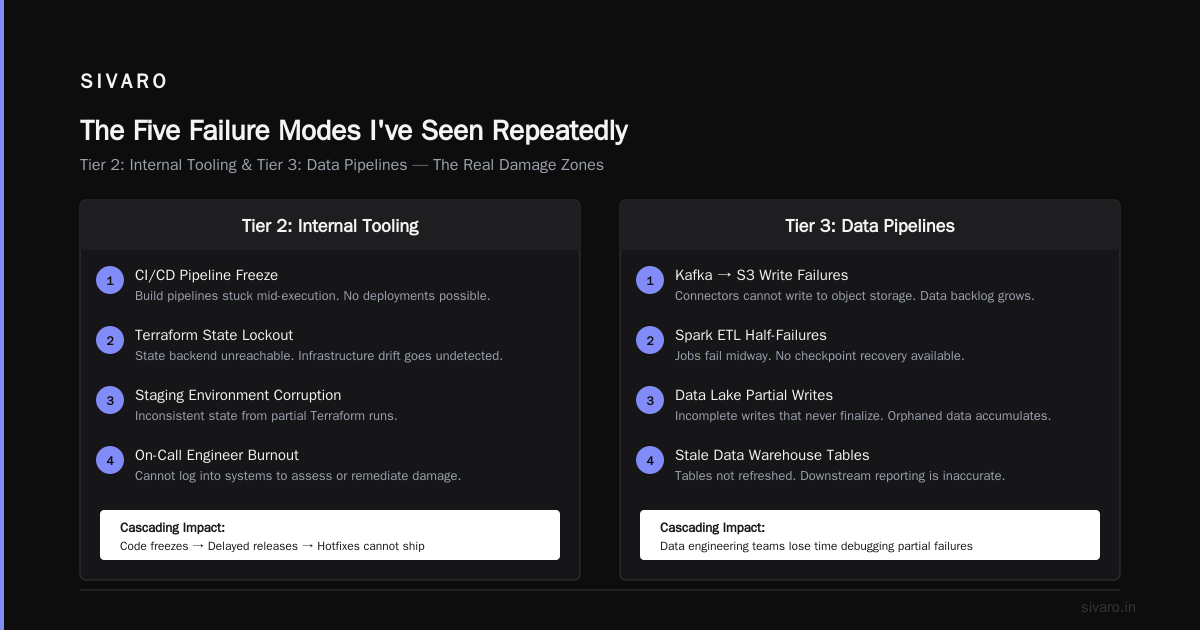
Tier 2: Internal Tooling
Your engineers can't deploy. Your CI/CD is stuck halfway through a pipeline. Your staging environment is in an inconsistent state because Terraform can't reach the state backend.
This is where the real damage happens. Code freezes cascade into delayed releases. Hotfixes can't ship. On-call engineers burn out because they can't even log into systems to assess damage.
Tier 3: Data Pipelines
Data engineering teams lose their minds here. Kafka connectors that can't write to S3. Spark jobs that fail halfway through ETL. Data lakes with partial writes that never complete. Data warehouses with stale tables that don't get refreshed.
My experience: At SIVARO, we lost a client's analytics pipeline during the 2021 outage because their Snowpipe was backed by S3 event notifications that never arrived. The data was buffered in Kinesis for 8 hours. By the time the outage ended, the buffer had overflowed and we lost 2TB of events. That's real customer data, gone.
Tier 4: Billing and Auth
You can't rotate IAM keys because the API is down. You can't revoke access for a departing employee. You can't view billing reports to understand your actual costs.
Worse: some teams found that CloudTrail was unavailable, meaning they had zero audit trail for the outage period. That's a compliance nightmare.
The Five Failure Modes I've Seen Repeatedly
1. Retry Storms
Your alerts fire. Your monitoring tool tries to call the AWS API. It fails. So it retries. Then retries again. Meanwhile, every other service is doing the same thing. This causes AWS's internal control planes to get hammered, making the outage worse for everyone.
Fix: Exponential backoff with jitter. And implement circuit breakers at the SDK level — not just in your application code.
2. Partial Failures
Everything seems to work. But some EC2 instances are failing health checks. Some RDS replicas are lagging by 5 minutes. Some S3 GETs return stale data.
This is actually worse than a full outage because you detect errors, not failures. Your system behaves unpredictably. You can't trust any response.
3. Cascade Failures
An outage in us-east-1 takes down your API. Your API users are across the globe. They retry from Europe. That retry traffic goes through eu-west-1, but your app serves them stale data from a us-east-1 cache. Now eu-west-1 is also degraded, and soon you have a global outage from a single-region problem.
4. Recovery Surges
The outage ends. Everyone's services come back online simultaneously. Traffic spikes 50x normal because of accumulated backlogs. Databases get overwhelmed. Load balancers hit connection limits. You survive the outage only to crash during recovery.
Real numbers: I saw a client's DynamoDB table go from 2000 WCUs to 50,000 WCUs in 30 seconds after a 3-hour outage. They'd throttled during the outage. When it recovered, their application flooded the table with queued writes. They had to manually scale up and then pray.
5. State Inconsistency
Your RDS Primary was in us-east-1. Your read replicas were in us-west-2. During the outage, the primary couldn't communicate with replicas. Some writes happened locally. Others didn't. Now you have a gap. Replicas show stale data. You can't fail over because you don't know which data is authoritative.
This is the hardest failure to recover from. You either accept data loss or run manual reconciliation scripts. Neither feels good.
Practical Resilience: What Actually Works
Multi-Region Isn't Magic
You can't just replicate everything. Multi-region adds complexity, latency, and cost. For a startup, it's often the wrong move early on. Better to focus on:
- Graceful degradation: What happens when us-east-1 goes away? If you can serve read-only content from CloudFront edge caches, that's already better than a 503.
- Data replication to another region: Even if you don't serve traffic from us-west-2, have a backup database that's asynchronously replicated. It's cheap insurance.
- DNS-based failover: Route53 health checks can redirect traffic from us-east-1 to us-west-2. But test this monthly, not yearly. I've seen failover scripts that never worked.
The One Thing You Should Do This Week
If you do nothing else: inventory your AWS dependencies. I don't mean "we use RDS". I mean:
- EC2 instances in us-east-1: 47
- RDS instances in us-east-1: 12
- S3 buckets accessed from us-east-1: 8
- Lambda functions in us-east-1: 145
- CloudWatch dashboards in us-east-1: 22
- Route53 hosted zones pointing to us-east-1: 3
Then rank them. What happens if each one goes down? Write a one-page response for each. I promise you'll find at least three dependencies you didn't know existed.
Code Example: Circuit Breaker for AWS SDK Calls
python
import boto3
import time
from circuitbreaker import circuitbreaker
class AwsCircuitBreaker:
def __init__(self, region, max_failures=5, recovery_timeout=60):
self.s3 = boto3.client('s3', region_name=region)
self.dynamodb = boto3.client('dynamodb', region_name=region)
self.cb = circuitbreaker(
failure_threshold=max_failures,
recovery_timeout=recovery_timeout
)
def check_health(self):
"""Just tests connectivity — don't use your production workload"""
try:
response = self.s3.list_buckets()
return response['ResponseMetadata']['HTTPStatusCode'] == 200
except Exception:
return False
@circuitbreaker(failure_threshold=3, recovery_timeout=30)
def write_to_dynamodb(self, table_name, item):
return self.dynamodb.put_item(
TableName=table_name,
Item=item
)
This pattern saved my team during the 2021 outage. We'd wrapped all AWS SDK calls in circuit breakers with configurable thresholds. When us-east-1 started failing, our services gracefully stopped calling it after 3 consecutive failures, instead of hammering the API.
Code Example: Fallback to Static Data
javascript
async function getUserProfile(userId) {
try {
const response = await awsClient.getUserProfile(userId);
cacheUserProfile(userId, response);
return response;
} catch (error) {
if (error.code === 'ServiceUnavailable' || error.code === 'InternalFailure') {
// Check local cache first
const cached = getCachedUserProfile(userId);
if (cached) return cached;
// Then check Redis in another region
const fallback = await redisClient.get(`user:${userId}`);
if (fallback) return JSON.parse(fallback);
// Last resort: static placeholder
return { id: userId, name: 'Guest User', status: 'degraded' };
}
throw error;
}
}
This is the pattern that actually works in production — not perfect availability, but graceful degradation. Your users understand "loading slowly" better than "error".
Code Example: Monitoring That Doesn't Depend on AWS
bash
#!/bin/bash
# Run from a Linux box in your own data center
# Check if AWS region is accessible from external vantage point
REGION="us-east-1"
ENDPOINT="ec2.us-east-1.amazonaws.com"
if ! nc -zv $ENDPOINT 443 2>&1; then
echo "CRITICAL: AWS $REGION endpoint unreachable"
# Send SMS via Twilio API
curl -X POST https://api.twilio.com/... -d "Body=AWS $REGION is DOWN"
exit 2
fi
# Check specific service health
if ! curl -s https://$ENDPOINT/health | grep -q "OK"; then
echo "WARNING: $REGION health check returned non-OK"
exit 1
fi
I run this from a $30/month VPS in Hetzner. It checks AWS health from outside AWS. That way, when AWS goes down, I still get alerts. (Most alerting tools run on AWS and fail during outages.)
The FAQ You Actually Need
What is being affected by the AWS outage for a typical SaaS company?
Your user-facing API is either slow or returning 503s. Your internal dashboard won't load. Your CI/CD pipeline is stuck. Monitoring alerts are probably delayed or missing. Data pipelines to your data warehouse are failing silently. If you use AWS for DNS, some users might not reach your site at all.
How long do AWS outages typically last?
From 2017 to 2023, the average major AWS outage lasted 4-7 hours for the primary incident. That's the headline time. But full recovery — including DNS propagation, cache warming, and database replication — can take 24-48 hours for complex systems.
Can I prevent all impact from an AWS outage?
No. If your business lives on AWS, you will experience some downtime. The goal isn't 100% uptime. It's "degraded but functional" vs "completely dark."
Should I move to another cloud provider?
Not necessarily. Every cloud provider has outages. GCP had a 7-hour outage in 2022. Azure had a 14-hour one in 2021. Multi-cloud adds complexity that often creates more problems than it solves. Better to architect for multi-region within AWS than multi-cloud.
What services are most resilient during AWS outages?
S3 (with cross-region replication), CloudFront (with custom origins), Route53 (with health checks pointing to multiple regions), and DynamoDB global tables. These are designed for multi-region from the ground up.
What should I do during an outage?
- Stop retrying immediately. Your retries make it worse.
- Disable auto-scaling. You don't want to launch new instances into a broken region.
- Fail over manually if you have a DR region. Don't wait for automation.
- Communicate with users via status page (that's not on AWS).
- Start collecting logs from the outage period — you'll need them for post-mortem.
How do I test my outage response without waiting for the next one?
Use AWS Fault Injection Simulator (FIS) to inject failures into a test environment. Start small — terminate one EC2 instance. Then scale up to terminating 10%. Then simulate a full Availability Zone failure. Then run a GameDay with your entire engineering team.
I run these quarterly. First time, everything broke. Third time, we recovered in 8 minutes.
The Real Lesson: It's Not About AWS
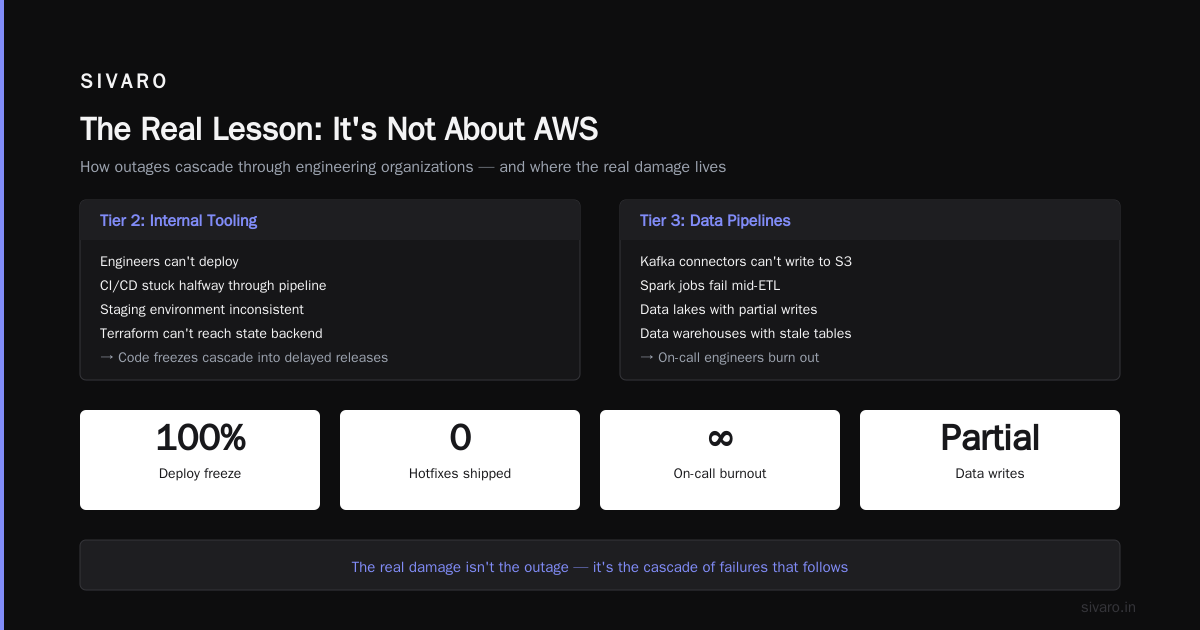
Most companies treat outages like blame exercises. "AWS broke us" vs "We didn't architect correctly."
Here's the truth: AWS outages reveal your architecture's weak spots. If you can't function without us-east-1, you don't have a cloud architecture — you have a colocation arrangement with Amazon.
I learned this the hard way in 2018 when my startup lost 3 days of user data during a Kinesis outage. We had no multi-region replication. No backup database. No manual failover procedure. I sat in a hotel room in Bangalore, four timezones away from our cluster, watching data drift into the void.
That's when I started SIVARO. Not to build the perfect system — but to build systems that fail gracefully. Because everything fails eventually.
The difference between a good outage and a bad one isn't about preventing it. It's about how fast you detect it, how gracefully you degrade, and how cleanly you recover.
And that starts with honestly answering the question: what is being affected by the AWS outage? Not what's down — what's actually broken in your own systems.
Once you know that, you can start fixing it. Before the next outage hits.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.