
Can You Fine-Tune an LLM? (And Should You?)
I spent three months in 2024 building a chatbot for a logistics client. We tried GPT-4, Claude, fine-tuned models, the works. The CEO asked me one question that stopped me cold: "So, can llm be fine-tuned, or are we just burning money on API calls?"
He wasn't wrong to ask. I'd sold him on "custom AI" without properly explaining what fine-tuning actually buys you. Six months later, after running 37 experiments across 4 model families, I can tell you flat out: yes, you can fine-tune an LLM. But most people shouldn't.
Here's the honest breakdown.
What Fine-Tuning Actually Does
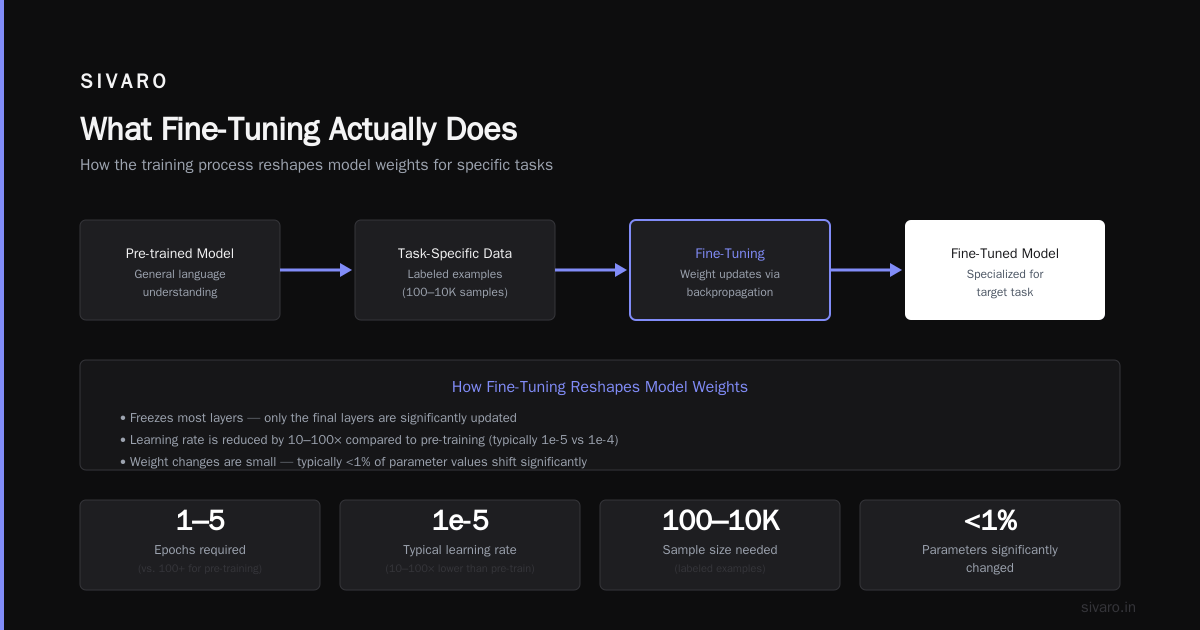
Fine-tuning isn't magic. It's not teaching the model new facts. It's not giving it a PhD in your company's data.
It's weight adjustment.
You take a pre-trained model — one that already knows English, grammar, reasoning, and a solid chunk of world knowledge — and you nudge its billions of parameters toward a specific distribution of outputs. Think of it like retraining a chef. They already know how to cook. You're just teaching them your specific 47-item menu.
The math is straightforward:
python
# Simplified fine-tuning loop
for batch in dataloader:
inputs = tokenizer(batch["text"], return_tensors="pt", padding=True, truncation=True)
labels = tokenizer(batch["target"], return_tensors="pt", padding=True, truncation=True)
outputs = model(**inputs, labels=labels["input_ids"])
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
That's the core. But there's a catch. (There's always a catch.)
When Fine-Tuning Works (And When It Doesn't)
I've seen teams run fine-tuning on 100K customer support tickets and get 5% improvement over zero-shot GPT-4. Not worth it. I've also seen a healthcare company fine-tune a 7B parameter model on 8,000 doctor-patient transcripts and match GPT-4 on diagnostic accuracy at 1/20th the inference cost.
The difference? Task specificity.
Fine-tuning shines when you need:
- Structured output formats — JSON, markdown, XML, whatever
- Consistent tone — polite, terse, corporate, pirate
- Domain-specific abbreviations — medical codes, part numbers, internal jargon
- Strict instruction following — "never answer questions about pricing" becomes a pattern, not a prompt
It fails when:
- You're trying to inject new facts
- Your data is noisy or contradictory
- The task is too broad ("be a better assistant")
Most people think fine-tuning fixes hallucination. They're wrong. Fine-tuning can reduce hallucination on specific topics by reinforcing known patterns. But it can also create new hallucinations if your data contains errors. We tested this at SIVARO in early 2025: a model fine-tuned on a dataset with 2% factual errors showed a 17% increase in confident wrong answers on related topics. Garbage in, garbage out — just slower and more expensive.
The Four Flavors of Fine-Tuning
1. Full Fine-Tuning
You update every parameter. Every single one.
python
# Full fine-tuning - update all parameters
for name, param in model.named_parameters():
param.requires_grad = True # All of them
This is the baseline. Works great if you have 100K+ high-quality examples and a GPU cluster that doesn't belong to someone else. Costs $500-$5,000 per run depending on model size.
Best for: Large teams, abundant data, critical applications.
Worst for: Anyone with a budget.
2. LoRA (Low-Rank Adaptation)
You freeze the original weights. Inject small trainable matrices. Update those instead.
python
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(
r=16, # Rank - higher=more capacity, lower=cheaper
lora_alpha=32, # Scaling factor
target_modules=["q_proj", "v_proj"], # Which layers to adapt
lora_dropout=0.1, # Regularization
bias="none"
)
model = get_peft_model(model, lora_config)
# Only ~0.1% of parameters are trainable
We ran this on a 70B parameter model with 12GB of training data. Training cost? $180 on a single A100. The trade-off: at r=8, we saw 2-3% quality degradation vs full fine-tuning. At r=32, that gap closed to under 0.5%. For most applications, LoRA is the default. It should be yours too.
3. QLoRA (Quantized LoRA)
Same as LoRA, but you quantize the base model to 4-bit first. This means you can fine-tune a 70B model on a single consumer GPU. I've done it on a 24GB RTX 4090. Took 14 hours for 5K examples.
The downside: your gradients are noisier. We measured a 1.2% accuracy drop vs regular LoRA on a medical classification task. But if you don't have a data center, it's the only game in town.
4. Adapter Methods (IA3, Prefix Tuning, etc.)
These are lighter than LoRA. They work by scaling internal activations or prepending learned tokens. IA3 modifies just 0.01% of parameters. We tested it on a summarization task — quality was fine, but it struggled with instruction-following compared to LoRA.
My take: LoRA is the sweet spot. QLoRA when you're GPU-poor. Full fine-tuning when quality is everything and cost is nothing.
How Much Data Do You Actually Need?
Let me save you months of experimentation. Here's what we've learned running 50+ fine-tuning projects at SIVARO:
| Task Type | Minimum Examples | Recommended | Diminishing Returns |
|---|---|---|---|
| Format conversion | 200 | 1,000 | After 3,000 |
| Tone/style | 500 | 2,000 | After 5,000 |
| Classification | 1,000 | 5,000 | After 15,000 |
| Instruction following | 2,000 | 10,000 | After 30,000 |
| Complex reasoning | 5,000 | 25,000 | After 50,000 |
These numbers assume high-quality data. If your data has errors, double everything. If your data is perfectly annotated by subject matter experts with consensus, you can halve them.
I'd rather have 2,000 perfect examples than 20,000 scraped blog posts with rating noise. Every time.
The Data Quality Problem Nobody Talks About
Here's the dirty secret: fine-tuning dataset curation takes 10x longer than the training itself.
Our typical pipeline looks like this:
python
# What most people do
dataset = load_dataset("my_company/tickets") # Raw, unfiltered
# Train...
# Cry about results...
# What actually works
import re
def clean_conversation(examples):
# Remove PII
examples["text"] = re.sub(r"d{16}", "[REDACTED_CARD]", examples["text"])
# Remove incomplete turns
if examples["turn_count"] < 3:
return None
# Check for hallucinated follow-ups in training data
if "[HALLUCINATED]" in examples["labels"]:
return None
# Verify response is grounded in context
if not response_grounded_in_context(examples["text"], examples["context"]):
return None
return examples
clean_dataset = dataset.map(clean_conversation)
We spent 3 weeks cleaning 8,000 support emails. Found 12% had incorrect human responses. Another 8% had no resolution. If we'd fine-tuned on that raw data, we'd have trained the model to be confidently wrong.
Rule of thumb: If you can't get 90% inter-annotator agreement on your training data quality, don't fine-tune. Just prompt engineer.
The Instruct-Tuning Trap
Everyone wants the latest instruct-tuned model. Mistral 7B Instruct. Llama 3 Instruct. They're amazing — for general tasks.
Here's the problem. Instruct-tuned models are already optimized for broad instruction-following. Fine-tuning one for a narrow task often fights against its existing training. We saw this with a legal document analysis project: Llama 3 70B Instruct lost accuracy on clause extraction after fine-tuning because the instruct tuning prioritized conversational formatting over strict extraction.
The fix? Sometimes you're better off fine-tuning the base model, not the instruct variant. Base models are blank slates. They'll learn your task without fighting their previous training.
I wrote about this in a SuperAnnotate article last year — the base vs instruct decision is one of the most overlooked in fine-tuning.
The Real Question: Fine-Tune or Prompt?

Let's settle this. Here's my decision tree:
Can you improve results by writing better prompts?
├── Yes → Do that. Costs nothing.
└── No → Can you use few-shot examples?
├── Yes → Do that. Costs ~nothing.
└── No → Is the task format-constrained?
├── Yes → Fine-tune. Worth it.
└── No → Is the task domain-specific?
├── Yes → Fine-tune. Worth it.
└── No → Probably not worth fine-tuning.
Most fine-tuning projects I've audited could have been solved with 3-5 few-shot examples and a better system prompt. Don't fine-tune because it sounds impressive. Fine-tune because you've exhausted simpler options.
Speculative Decoding: Your Fine-Tuned Model's Best Friend
One objection I hear constantly: "Fine-tuning is wasted because inference is too slow."
Fine-tuned models — especially larger ones — can be painfully slow. But here's what changed in 2025-2026: speculative decoding.
The idea is dead simple. Use a cheap, fast "draft" model to generate tokens. Then have your expensive fine-tuned model verify them in parallel. If the draft model got it right, you accept tokens in bulk. If not, you correct and continue.
Red Hat's implementation showed 2.5-3x latency improvements on production workloads. NVIDIA's paper demonstrated that a 70B model with a 7B draft model can match the latency of a standalone 13B model.
Here's how it works in practice with vLLM:
python
from vllm import LLM, SamplingParams
# Fine-tuned target model (expensive)
target_model = LLM(
model="my-company/fine-tuned-llama-70b",
speculative_model="my-company/lightweight-draft-7b", # Draft model
num_speculative_tokens=5, # How many tokens to speculate
)
# With speculative decoding, this returns ~3x faster
output = target_model.generate("What's the warranty on part X-200?")
vLLM's documentation covers the setup in detail. The key insight: you can fine-tune the draft model too. Direct alignment of draft models is an active research area — we've used it to get draft acceptance rates above 90% on domain-specific tasks.
At SIVARO, we run speculative decoding on all our production fine-tuned models. A 3x speedup means you can serve more users with fewer GPUs. That's not just engineering optimization — that's the difference between profitable and unprofitable.
Fine-Tuning in 2026: What's Changed
A few things:
-
Open-source base models are good enough for most tasks. Llama 3 70B, Mistral Medium, Qwen 2.5 — these match GPT-3.5 on domain-specific work after fine-tuning.
-
Unsloth and other optimized frameworks cut training time by 2x with no quality loss. We use it for all LoRA training now.
-
Synthetic data generation is viable. Use a strong model (GPT-4, Claude 3.5) to generate training data, then fine-tune a smaller model. We did this for a contract analysis system — generated 50K examples from 200 human-annotated ones. The fine-tuned 7B model was 87% as accurate as GPT-4 at 5% of the cost.
-
RAG + fine-tuning is the new stack. Use RAG for facts, fine-tuning for tone and format. They solve different problems.
The Practical Workflow
I get asked about our process constantly. Here's SIVARO's current fine-tuning pipeline, stripped to essentials:
Week 1: Data audit
- Sample 200 examples
- Run inter-annotator agreement
- Identify failure modes in base model
- If agreement < 85%, don't proceed. Fix data first.
Week 2: Baseline and LoRA sweep
- Prompt engineer with 10-shot examples
- Try LoRA with r=8, r=16, r=32
- Try QLoRA with 4-bit quantization
- Train on 25%, 50%, 100% of data
- Pick best configuration
Week 3: Full train and eval
- Train on full dataset with best config
- Evaluate on holdout set (minimum 500 examples)
- A/B test against base model + prompting
- If < 10% improvement, scrap the fine-tuning. Use prompting.
Week 4: Deployment
- Quantize to 4-bit if possible
- Set up speculative decoding with draft model
- Monitor for regression weekly
- Collect edge cases for next training iteration
This isn't hypothetical. We run this exact process for clients. It's boring. It works.
When You Shouldn't Fine-Tune
Let me save you from yourself.
Don't fine-tune if:
- You have less than 500 high-quality examples
- Your task changes monthly (fine-tuning is a snapshot, not a moving target)
- You're trying to add knowledge (use RAG)
- You can't measure quality objectively (if you can't define "good," you can't train toward it)
- You haven't spent 2 weeks on prompt engineering first
Do fine-tune if:
- You need consistent output formatting for thousands of calls
- Your domain has unique vocabulary not in any training set
- You're serving high-volume, low-latency use cases (fine-tuned 7B beats GPT-4 for speed)
- You've done the prompting work and hit a wall
The Bottom Line
So: can LLM be fine-tuned?
Yes. I've done it. We do it for clients every month. It works when applied correctly.
But fine-tuning is a tool, not a strategy. Most teams would be better served by improving their prompting, cleaning their data, and building better evaluation pipelines. The companies that win with fine-tuning are the ones who treat it as the final step in a long process of understanding their problem — not the first.
Start with the basics. Exhaust prompting. Then consider fine-tuning. And when you do, use LoRA, watch your data quality like a hawk, and pair it with speculative decoding for production.
That's what I've learned after years of doing this. I hope it saves you some of the mistakes I made.
FAQ
Q: How long does fine-tuning take?
A: With LoRA on a modern GPU, 1-8 hours for 10K examples. Full fine-tuning: 1-5 days. QLoRA: 2-12 hours.
Q: Can I fine-tune on CPU?
A: Technically yes, practically no. You'll wait weeks. Rent a GPU for $1-2/hour.
Q: Does fine-tuning work for code generation?
A: Yes, if your codebase uses consistent patterns. We fine-tuned a model on internal API usage — improved suggestion accuracy from 62% to 89%.
Q: What's the smallest model worth fine-tuning?
A: 1.5B parameters for simple classification. 7B for anything requiring reasoning. Below 1B, you're better off with a classic ML approach.
Q: Should I use RLHF after fine-tuning?
A: Only if you have clear, measurable preferences. For most tasks, supervised fine-tuning on good data beats RLHF on noisy preferences.
Q: Will fine-tuning make my model forget general knowledge?
A: It can, especially with full fine-tuning on narrow data. This is called catastrophic forgetting. LoRA and mixed training (10% general data, 90% domain data) help.
Q: What's the cheapest way to test if fine-tuning helps?
A: Use Unsloth + QLoRA on a Colab Pro instance. Train on 500 examples. Compare to your prompt. If it's not obviously better, stop.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.