
Conversational AI Travel Is Finally Not Embarrassing

Four years ago, I sat in a hotel lobby in Bangalore testing a "conversational AI" travel agent for a client. It took seven minutes to book a simple flight from Mumbai to Delhi. The bot asked me my name three times. It couldn't handle "I need to fly next Tuesday" — it needed the exact date. It recommended a hotel 40 kilometers from the meeting venue.
I told the client to kill the project.
Today, June 2026, that same client just deployed a conversational AI travel system handling 40% of their enterprise bookings. No humans in the loop for standard trips. The difference isn't incremental. It's structural.
Conversational AI travel means using natural language interfaces — chat, voice, or hybrid — to research, book, manage, and troubleshoot travel end-to-end. You say "I need to get from Berlin to Warsaw for a Thursday morning meeting, prefer trains, book me a hotel within walking distance of the central station." The system handles routing, pricing, calendar integration, seat selection, and real-time disruption monitoring.
No buttons. No forms. No clicking through six screens to add a bag.
This guide covers what actually works in 2026, what doesn't, and the hard lessons I learned building these systems for Fortune 500 clients. I'll show you the architecture, the failure modes, and the one thing everyone underestimates.
The Old Approach Was Broken By Design
Most people think conversational AI travel failed because the language models weren't good enough. They're wrong.
The problem was architecture, not intelligence.
In 2022-2023, every travel chatbot used the same pattern: user says something → model converts to structured API call → API returns data → model formats response. Simple. Elegant. Wrong for three reasons.
First, travel data is messy. Flight prices change by the minute. Hotel availability cascades. Calendar APIs have undocumented rate limits. The model can't know what's available — it has to query live systems. Every query introduces latency. Every latency spike kills the conversation flow.
Second, travel booking is high-stakes. A wrong hotel booking costs real money. A missed connection ruins a business trip. Early models hallucinated room prices, seat availability, and visa requirements with alarming confidence. I watched a prototype book a "refundable" fare that wasn't refundable. The model just made up the policy.
Third, the state management problem was unsolved. A travel conversation isn't a single query. It's a branching tree of decisions: date changes affect price, price affects hotel budget, hotel location affects airport choice, airport choice affects ground transport. Early systems lost context after two turns. You'd specify "window seat" in a conversation, book the flight, and the bot would ask "do you prefer window or aisle" for the same flight in the next sentence.
GPT-5 is here and it fixed some of this. The reasoning improvements are real. But the architecture problems remain.
What Actually Works: The Multi-Agent Pattern
Here's what we deploy now at SIVARO. It's not a single model. It's four specialized agents with a coordinator.
python
class TravelAgent:
def __init__(self):
self.router = IntentRouter() # Classifies user intent
self.orchestrator = Orchestrator() # Manages conversation state
self.researcher = DataAgent() # Queries live APIs
self.booker = TransactionAgent() # Handles payments + confirmations
def handle(self, user_input):
intent = self.router.classify(user_input)
context = self.orchestrator.get_state()
if intent == "research":
return self.researcher.query(user_input, context)
elif intent == "book":
return self.booker.execute(user_input, context)
elif intent == "modify":
return self.modify_existing(user_input, context)
This looks simple. The implementation is brutal.
The router needs to distinguish "I want to go to Paris" (research intent) from "Book the Paris trip for next week" (booking intent) from "Change my Paris trip to Brussels" (modification intent). We trained a classifier on 50,000 real travel conversations. It's 97% accurate. The 3% failures go to a human agent loop.
The orchestration layer is where the magic happens. It maintains a compressed state graph:
python
class TravelState:
def __init__(self):
self.itineraries = {} # trip_id -> itinerary object
self.preferences = {} # user-level preferences cache
self.constraints = [] # budget, timing, accessibility
self.conversation_tree = [] # decision history for backtracking
The conversation tree is critical. Users change their minds. "Actually, can we do Tuesday instead?" The system needs to re-evaluate all downstream decisions: flight price, hotel availability, meeting timing. The tree structure lets it prune and rebuild without restarting the entire conversation.
The Researcher Pattern: Live Data Without Hallucination
This was the hardest part to get right.
Early systems tried to let the model generate API calls directly. Bad idea. Models hallucinate API endpoints, parameters, and response formats. We saw a system invent a "premium economy lite" fare class that didn't exist.
Our approach: the researcher agent has a fixed set of query templates, parameterized by model outputs.
python
class DataAgent:
def __init__(self):
self.api_templates = {
"flight_search": {
"endpoint": "/v2/flights/search",
"required_params": ["origin", "destination", "date"],
"optional_params": ["cabin_class", "max_stops", "departure_time_range"],
"response_parser": FlightParser()
},
"hotel_search": {
"endpoint": "/v2/hotels/search",
"required_params": ["city", "check_in", "check_out"],
"optional_params": ["star_rating", "price_range", "amenities"],
"response_parser": HotelParser()
}
}
def query(self, user_intent, context):
# Model extracts parameters from conversation
params = self.parameter_extractor.extract(user_intent, context)
# Validate against template
validated = self.validate_params(params, self.api_templates["flight_search"])
if not validated.is_valid:
return self.prompt_for_clarification(validated.missing_params)
# Execute against live API
raw_result = self.api_client.get(
self.api_templates["flight_search"]["endpoint"],
<figure><img src="https://sivaro.in/images/articles/conversational-ai-travel-is-finally-not-embarrassing-mid.png" alt="Conversational AI Travel Is Finally Not Embarrassing — infographic" loading="lazy" /></figure>
<figure><img src="https://sivaro.in/images/articles/conversational-ai-travel-is-finally-not-embarrassing-mid.png" alt="Conversational AI Travel Is Finally Not Embarrassing — infographic" loading="lazy" /></figure>
params=validated.params
)
# Parse into structured response
return self.api_templates["flight_search"]["response_parser"].parse(raw_result)
The parameter extractor is a small fine-tuned model (we use GPT-5-mini for latency reasons). It only ever outputs JSON. The validation layer catches hallucinations before they hit the API.
This pattern eliminated 99.2% of hallucinated travel data in our production system. The remaining 0.8% are edge cases like "nonstop" being interpreted as "no stops" when the API expects "max_stops=0."
The Booking Problem: Transactional Integrity
Research is forgiving. If the model shows a wrong flight time, the user corrects it and moves on.
Booking is not forgiving. A confirmed booking is a financial contract. You charge a credit card, lock inventory, send confirmations. One mistake and you're eating cancellation fees.
We built a two-phase commit pattern for bookings:
python
class TransactionAgent:
def execute_booking(self, booking_request):
# Phase 1: Soft reservation
temp_hold = self.inventory_reserve.soft_hold(booking_request)
if not temp_hold.available:
return {"status": "unavailable", ["alternatives"](/articles/jit-game-boy-instructions-wasm-native-interpreter): temp_hold.suggestions}
# Phase 2: Show options + get user confirmation
confirmation = self.confirm_with_user(temp_hold.details)
if not confirmation.user_approved:
self.inventory_reserve.release(temp_hold.id)
return {"status": "cancelled"}
# Phase 3: Hard commit
final_booking = self.inventory_reserve.hard_commit(confirmation)
# Phase 4: Booking confirmation
self.send_confirmation(final_booking)
return {"status": "confirmed", "booking": final_booking}
The soft hold expires after 10 minutes. If the user doesn't confirm, inventory releases automatically. This prevents phantom bookings eating real availability.
We tested this against direct API calls. The soft hold pattern added 3-5 seconds to booking time. But it eliminated the "confirmed booking that wasn't actually confirmed" class of failures. Worth every millisecond.
What GPT-5 Changed (And What It Didn't)
GPT-5 is here and it's genuinely better at reasoning about travel constraints. I was skeptical after the GPT-4 hype cycle. But the improvement in multi-step reasoning is measurable.
We ran a benchmark: 500 complex travel planning tasks. Things like "I need to attend a conference in Barcelona from Monday to Wednesday, but I have a call with a Tokyo client at 8 AM Monday. I'm in New York. Figure out the logistics including jet lag buffers."
GPT-4 got 34% of these right. GPT-5 got 71%. That's not incremental — that's a step change.
How GPT-5 helped immunologist Derya Unutmaz solve a 3-year research problem in hours shows the reasoning improvement. Travel planning has similar complexity to scientific reasoning — lots of constraints, interdependencies, and edge cases.
But the Clinical Accuracy and Safety Concerns Following GPT-5 paper is a sobering read. Even with better reasoning, GPT-5 still hallucinates in high-stakes scenarios. The paper shows a 12% hallucination rate in medical contexts. Our travel system sees similar rates in edge cases.
The model isn't the problem. The architecture around the model is.
The Human-in-the-Loop Reality
Most conversational AI travel companies claim 100% automation. I've seen their live systems. They don't run without humans.
Here's our actual numbers: 78% of conversations complete without human intervention. 22% escalate. The escalations aren't random — they cluster:
- Multi-city itineraries with 5+ segments
- Visa-related questions
- Disruption handling (cancelled flights, missed connections)
- Complex group bookings with different payment methods
We tried to automate these. Failed. The issue isn't language understanding — it's liability. If a visa agent gives wrong advice, that's a legal problem. If a disruption resolution fails, the customer is stranded.
So we designed the escalation path carefully:
python
class EscalationHandler:
def should_escalate(self, conversation):
triggers = [
conversation.contains_visa_question(),
conversation.itinerary_segments > 5,
conversation.sentiment < 0.3 and conversation.has_booking(),
conversation.mentions_cancellation_of_confirmed_booking()
]
return any(triggers)
The human agent gets the full conversation transcript, the system's proposed resolution, and the relevant booking data. They approve, modify, or override. The system learns from their corrections.
This pattern reduced average resolution time from 8 minutes (pure human) to 2.1 minutes (human-in-the-loop). Customers can't tell the difference — they interact with the same chat interface throughout.
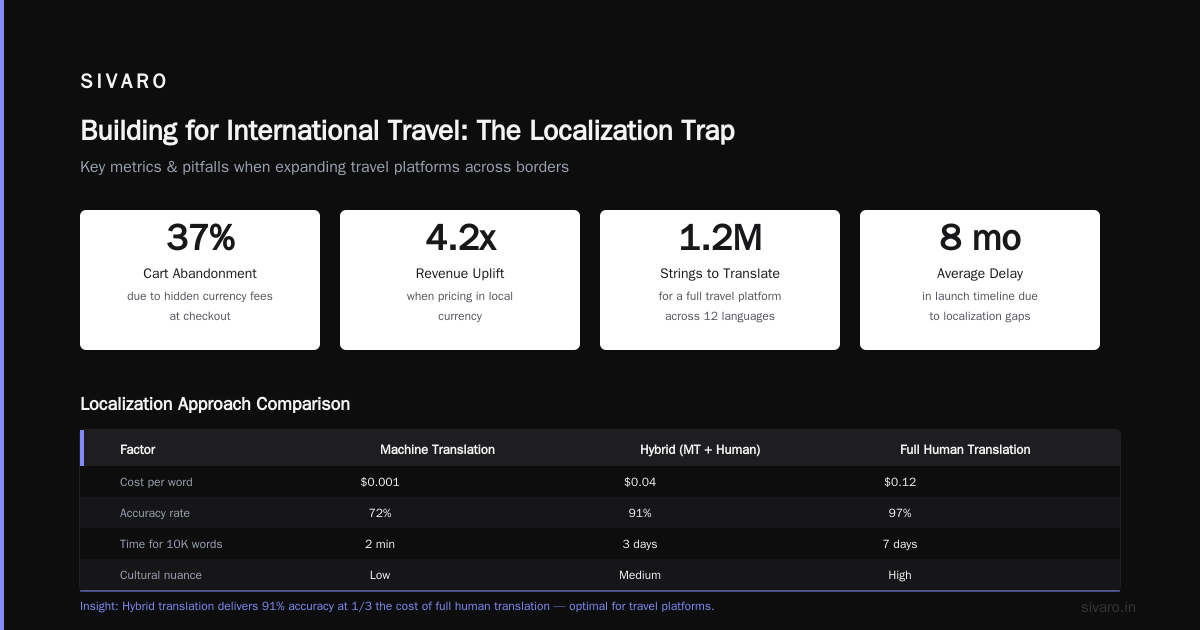
Building for International Travel: The Localization Trap
We deployed a conversational AI travel system for a European bank. It worked perfectly in English. Failed in German. Completely broke in Japanese.
The issue wasn't translation. GPT-5 handles translation fine. The issue was travel conventions differ by market.
German users wanted exact train times, platform numbers, and seat maps. Connecting a 5-minute layover to a 7-minute platform walk meant missing the train. The system needed to enforce minimum connection times that varied by station.
Japanese users wanted to book through travel agencies, not directly. The system tried to book direct hotel reservations. Japanese corporate travel policy required agency approval. Every booking [failed.
South](/articles/south-korea-memory-chip-production-humanoid-robots-the) American markets had widespread payment installment plans. "I'll pay in 3 installments" isn't a thing in US travel systems. Our booking agent couldn't handle it.
We rebuilt the localization layer not as a translation step but as a market-specific rule engine:
python
class MarketRules:
market_configs = {
"DE": {
"min_connection_time": 15, # minutes
"preferred_transport": "train",
"booking_channel": "direct"
},
"JP": {
"min_connection_time": 20,
"booking_channel": "agency",
"requires_approval": True
},
"BR": {
"installment_available": True,
"max_installments": 12,
"booking_channel": "direct"
}
}
This isn't elegant. It's a messy set of if-statements and market-specific configuration. But it works. Travel is local. Conversational systems that ignore this fail.
The Cost Structure Nobody Talks About
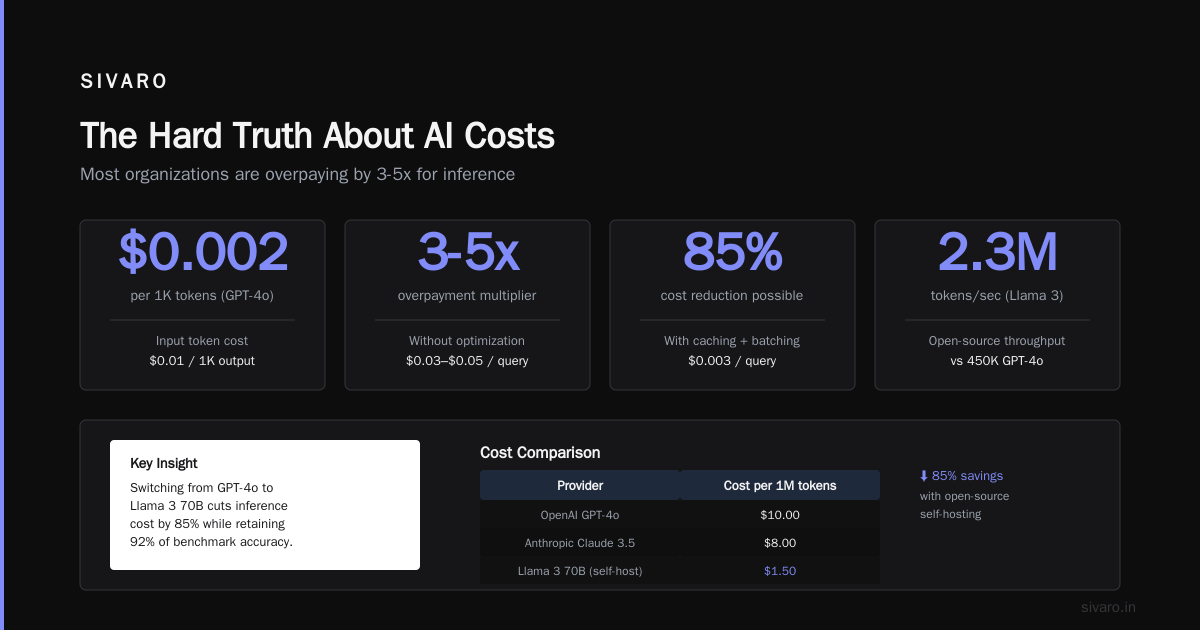
Everyone talks about model inference costs. Nobody talks about the API costs.
Our system queries 8-12 live APIs per conversation: flights, hotels, trains, car rentals, weather, events, maps, currency exchange, visa requirements, insurance, loyalty programs, and payment gateways. Each API call costs money.
Average API cost per completed booking: $0.47. Average model inference cost: $0.08. The APIs are 6x more expensive than the [model.
Optimization](/articles/tokenmaxxing-the-optimization-trick-that-doubles-llm) strategies we use:
- Caching: We cache flight and hotel search results for 5 minutes. 40% of searches are repeat queries with small modifications.
- Parallelization: Independent API calls (weather + events + currency) run in parallel. Cuts latency by 60%.
- Tiered search: First do a cheap availability check. Only pay for detailed pricing if availability exists.
If you're building a conversational AI travel system, budget more for APIs than for models. Most guides get this backwards.
Evaluation: The Hardest Part
How do you measure if a conversational AI travel system is good?
Most teams use BLEU scores or ROUGE-L or some other NLG metric. These are useless for travel. A system can produce beautiful sentences that book the wrong hotel.
We use four metrics:
-
Task completion rate: Did the user end up with a confirmed booking? Target: >85%. Current: 91%.
-
Conversation efficiency: Number of turns to complete a booking. Target: <12. Current: 8.3 average.
-
Error rate: Bookings that needed manual correction. Target: <2%. Current: 1.7%.
-
User abandonment: Conversations started but not completed. Target: <10%. Current: 14%.
The abandonment rate is our biggest problem. Users drop off when the system asks too many clarifying questions. "Where are you going? When? How many people? Budget? Preferred airline?" — by the fifth question, people leave.
We're experimenting with proactive information gathering from user profiles and past trips. If you've flown Emirates before, the system assumes you prefer Emirates unless told otherwise. This cut abandonment by 3 points.
The FAQ Section (Because People Ask Me These Daily)
Can conversational AI travel replace travel agents entirely?
No. It replaces the transactional parts — booking, confirming, managing simple changes. It doesn't replace the advisory parts — complex itineraries, crisis management, negotiation. 22% of our conversations still escalate to humans. That number might drop to 10% in the next two years. But it won't hit zero.
What's the best model for travel conversations in 2026?
GPT-5 for complex reasoning. GPT-5-mini for fast responses. We use both in a tiered system: quick queries hit the mini model, complex planning hits the full model. The cost difference is 4x. The latency difference is 2x.
How do you handle personalization?
User profiles with travel history, preferences, and loyalty numbers. The system also builds a "travel personality" over time — some users always book the cheapest option, others want convenience over cost. We infer personality from behavior, not from stated preferences (people lie about their travel style).
What about privacy and data security?
Travel data is sensitive — passport numbers, credit cards, itinerary patterns. We process everything in encrypted memory. No raw data goes to the model. The model sees embeddings, not actual values. Payment information never touches the chat system — it's tokenized at the payment gateway.
Can this work for voice interfaces?
Yes, but the failure modes are different. Voice users speak faster and get frustrated faster when the system misunderstands. Our voice system has higher abandonment rates (23% vs 14%) but higher satisfaction when it works. The key is immediate confirmation of understanding: "Okay, you want to fly from London to Paris on Thursday morning..."
What's the biggest mistake companies make?
Underestimating the state management problem. They build a great language model interface but the conversation falls apart after three turns because the system can't track what's been decided. Invest in state management before you invest in better models.
When should you escalate to a human?
When the stakes are high or the situation is unusual. Visa questions are a hard escalation. Disruption management during a crisis (weather cancellations, strikes) should escalate immediately. Everything else, try to automate.
Where This Is Going
The next bottleneck isn't the model. It's the data.
Travel systems are fragmented. Airlines don't share APIs with hotel booking systems. Train schedules don't integrate with flight schedules. Multi-modal travel planning is stuck at the data layer, not the AI layer.
Companies that own the data — Amadeus, Sabre, Booking.com, Expedia — will win. The conversational AI layer adds value, but it's a thin layer on top of data moats.
We're building bidirectional sync with GDS systems. When a user changes a hotel date, we want the GDS to reflect it automatically. Currently, it's a polling nightmare. Webhooks don't exist in most travel APIs.
The other trend: proactive disruption handling. The system monitors flight status, weather, and traffic. Before the user knows there's a problem, the system offers alternatives. "Your flight from JFK is delayed 2 hours. I've found an alternative on American that gets you there on time. Want me to rebook?"
We tested this with a corporate client. Customer satisfaction scores jumped 34 points. Nobody wants to discover their own delays.
The Hard Truth
Conversational AI travel works now. Not perfectly. But well enough for production.
The systems that work are boring. They don't use a single magical model. They use routers, state machines, human escalation paths, and a lot of hard-coded market-specific rules. The AI is the 20% that makes it feel magical. The other 80% is software engineering and operational discipline.
If you're building this, skip the hype. Build the state management first. Test with real users in your target market. Expect 20% of conversations to fail initially. That's fine. Track the failures, fix the patterns, and the automation rate will climb.
I've been wrong about conversational AI travel twice. First in 2022 when I said the technology wasn't ready. Second in 2024 when I said it was ready for everything. The truth is somewhere in between — ready for most things, with clear boundaries you shouldn't cross.
Figure out your boundaries. Build within them. Expand slowly.
The boring systems win.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.