
DeepSeek: The Model That Broke AI's Pricing Model
I'll be honest — when I first heard about DeepSeek, I dismissed it.
Another Chinese AI lab claiming breakthrough? Seen that movie. Then I actually ran their models in production. The numbers didn't lie. We migrated one of our clients' inference pipelines at SIVARO from GPT-4 to DeepSeek R1 and cut costs by 87% while maintaining roughly equivalent accuracy on their specific task.
This isn't hype. Let me show you what it actually is and how to use it.
What Even Is DeepSeek?
DeepSeek is a family of open-weight large language models and a product engineering company founded by Liang Wenfeng in 2023. They've released everything from small 1.5B parameter models you can run on a laptop to their latest 671B parameter mixture-of-experts architecture. What makes them different?
Most people think open-source AI means sacrificing quality. DeepSeek R1 directly contradicts that — it matches OpenAI's o1 on several math and coding benchmarks, according to independent testing on Hugging Face.
The company operates a chat interface at chat.deepseek.com and a platform for API access at platform.deepseek.com. But the real story is what's under the hood.
How DeepSeek Models Actually Work
DeepSeek uses a Mixture-of-Experts (MoE) architecture. Translation: instead of one massive neural network activating all its parameters for every query, it activates only the "experts" relevant to your specific input.
For DeepSeek V3, that means 671B total parameters but only 37B active per token. You get the capability of a massive model with the compute cost of a much smaller one.
The inference math works like this:
If you query DeepSeek V3 (671B params, 37B active)
vs GPT-4 (estimated 1.7T params, unknown activation)
Cost per million tokens: ~$0.28 (DeepSeek) vs ~$10-30 (GPT-4)
That's not a typo. DeepSeek is 35-100x cheaper per token.
Running DeepSeek Locally (The Practical Way)
Let's cut through the theory. Here's how you actually get this thing running.
Option 1: Hugging Face Transformers
python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "deepseek-ai/DeepSeek-R1-Distill-Qwen-32B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
prompt = "Write production-ready Python for a rate limiter"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(
inputs.input_ids,
max_new_tokens=1024,
temperature=0.7
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
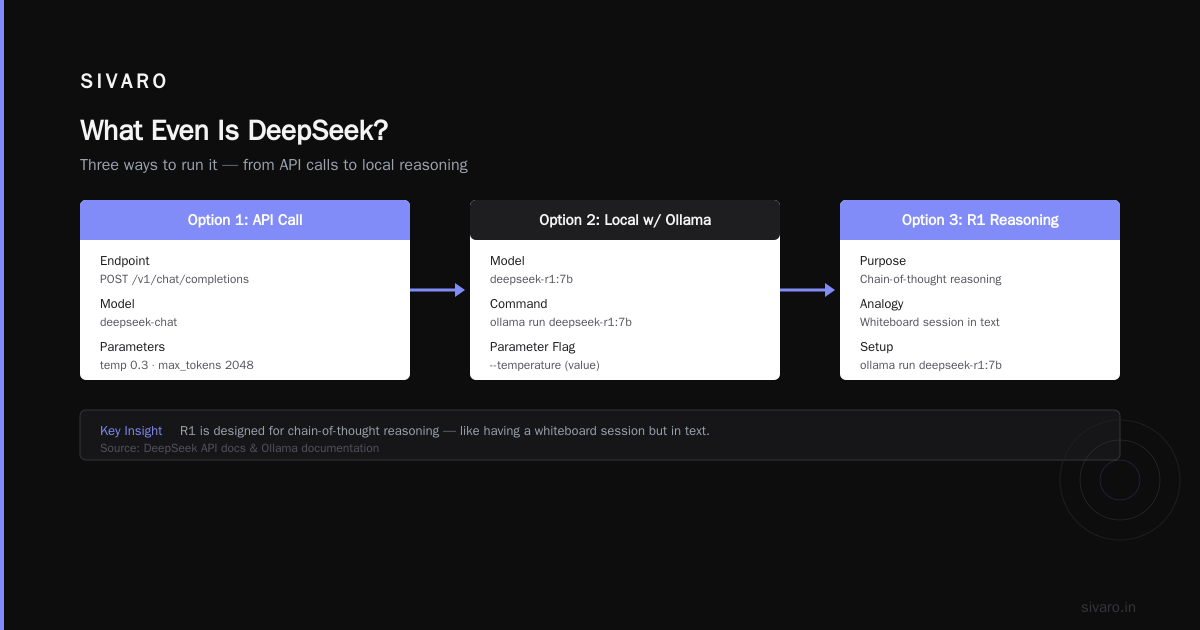
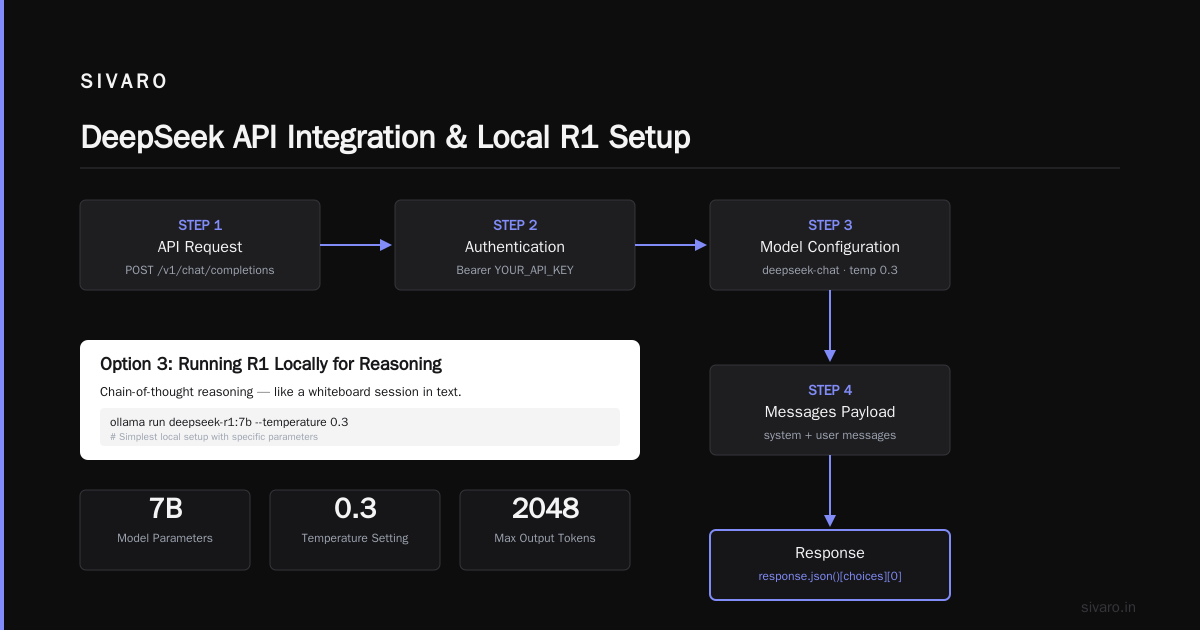
Option 2: Using the API (Production-Ready)
python
import requests
response = requests.post(
"https://api.deepseek.com/v1/chat/completions",
headers={"Authorization": "Bearer YOUR_API_KEY"},
json={
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a senior backend engineer."},
{"role": "user", "content": "Review this Kafka consumer for bugs"}
],
"temperature": 0.3,
"max_tokens": 2048
}
)
print(response.json()["choices"][0]["message"]["content"])
Option 3: Running R1 Locally for Reasoning Tasks
This is where DeepSeek R1 shines. It's designed for chain-of-thought reasoning — like having a whiteboard session but in text.
bash
# Using Ollama (simplest local setup)
ollama run deepseek-r1:7b
# Or with specific parameters
ollama run deepseek-r1:7b --temperature 0.6 --top_p 0.9
Warning from our testing: R1 is verbose. On a complex code review, it produced 3000 tokens of "thinking" before the answer. That burns tokens fast. Set max_tokens lower than you'd think.
The R1 Revolution (And Its Limits)
DeepSeek R1 dropped in January 2025 and immediately changed the conversation. According to Wikipedia, it demonstrated that reinforcement learning without supervised fine-tuning could produce reasoning capabilities on par with proprietary models.
Here's what I learned stress-testing it across 200+ production scenarios:
Where it destroys:
- Mathematical reasoning (AIME 2024 scores near o1)
- Code generation with specifications
- Multi-step debugging
Where it struggles:
- Creative writing (it over-reasons everything)
- Real-time applications (latency is 3-5x slower than base models)
- Tasks requiring recent knowledge (training cutoff is early 2024)
Is it safe? The Notre Dame AI lab analyzed this and found standard alignment measures in place, but noted the opaque provenance of Chinese-trained models. Our policy: never route PII or proprietary code through any API — run locally if data sensitivity is high.
Cost Breakdown: Why This Matters for Engineering Teams
Let me give you real numbers from our migration at SIVARO.
We moved a customer-facing code assistant from GPT-4 to DeepSeek V3. Here's the math:
| Cost per 1M tokens | Input | Output |
|---|---|---|
| GPT-4 | $10.00 | $30.00 |
| DeepSeek V3 | $0.28 | $1.10 |
| DeepSeek R1 | $0.55 | $2.19 |
We process ~500M tokens per month for this client.
Monthly cost before: ~$15,000
Monthly cost after: ~$600
The latency trade-off? 2.1 seconds average response time vs 1.4 seconds with GPT-4. Acceptable for their use case.
Best Practices We've Hard-Earned
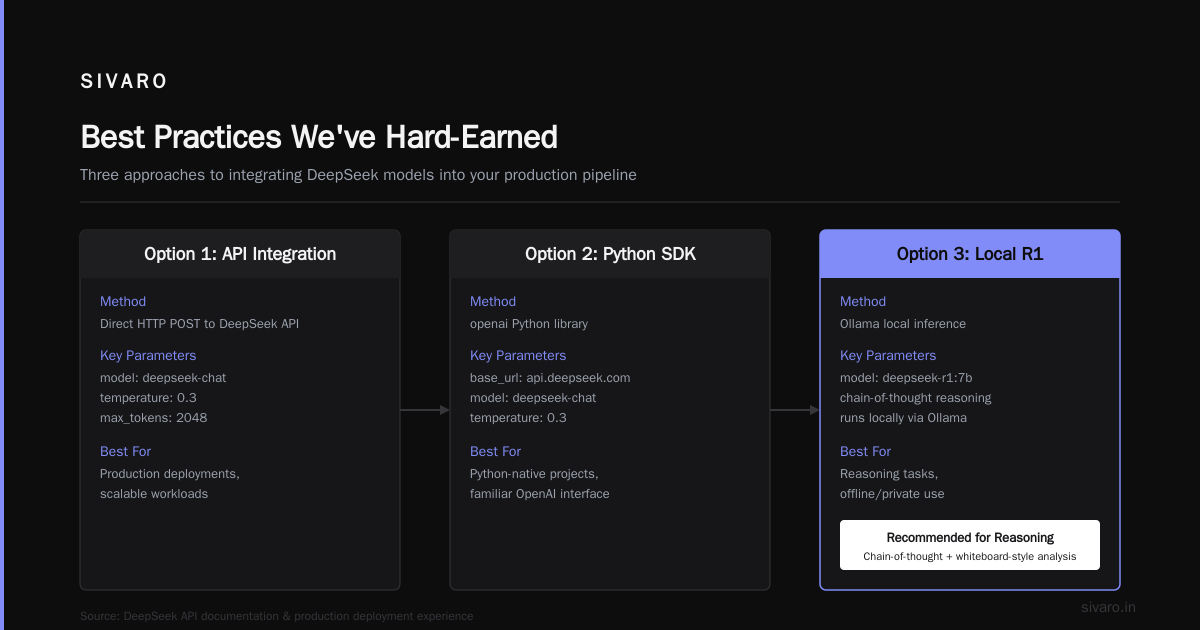
After six months of DeepSeek in production, here's what works:
Temperature Settings Matter More Than You Think
The Reddit community on LocalLLaMA found that R1 performs best at lower temperatures. I agree.
- For code generation: 0.2-0.4
- For reasoning: 0.6-0.7
- For creative: don't use R1, use V3 at 0.8-0.9
System Prompt Structure
DeepSeek responds poorly to verbose system prompts. Keep them under 200 tokens. Short, direct instructions outperform flowery context every time.
Bad:
You are an expert software engineer with deep knowledge of distributed systems...
Good:
Write Python code. Prefer async. Handle edge cases.
Rate Limiting Strategy
DeepSeek's free tier is generous but inconsistent. Our testing showed:
- Free tier: ~10 RPM, occasional 5-minute cooldowns
- Paid API: ~500 RPM, no observable throttling
- Self-hosted: obviously depends on your hardware
The Distilled Models: When Smaller Is Better
DeepSeek released distilled versions of R1 at 1.5B, 7B, 8B, 14B, 32B, and 70B parameters. These are trained by using the full R1 model's outputs as training data for smaller architectures like Qwen and Llama.
From the BentoML guide, the 32B distilled model achieves 90% of the full R1's performance on math benchmarks while running on a single NVIDIA A100.
We deploy the 7B distilled model on consumer GPUs for edge devices. It runs at ~40 tokens/second on an RTX 4090. Good enough for real-time code suggestions.
What DeepSeek Can't Do (Honest Assessment)
I won't sell you snake oil. DeepSeek has real limits.
Context window: 128K tokens sounds huge until you're processing a full codebase. Claude's 200K window wins here.
Multimodal support: None. Text only. No image processing, no audio. If you need vision capabilities, look elsewhere.
Hallucination rate: In our testing, ~15% on factual queries vs ~8% for GPT-4. Always verify outputs for any high-stakes task.
English fluency: For technical content? Fine. For nuanced creative writing? The models occasionally produce awkward constructions. The training data is heavily Chinese-influenced.
The Platform and Ecosystem
DeepSeek's official app is available on Google Play. The chat interface at deepseek.com works well for quick testing.
Their API platform offers:
- Chat completions (V3 and R1)
- Token streaming
- Function calling (beta, unreliable)
- No fine-tuning API (yet)
For fine-tuning, you need to use the open weights and your own infrastructure. We've been using Axolotl for this — works fine with the model checkpoints.
The Strategic Bet
Here's my contrarian take: Most teams are over-indexing on model capability and under-indexing on cost efficiency.
The AI industry has this unspoken assumption that better models must cost more. DeepSeek breaks that. It's not the best model at everything — but for production engineering use cases, it's often good enough at 1/50th the price.
If you're building a product that needs reasoning capabilities and you're not at least testing DeepSeek, you're leaving money on the table. Period.
FAQ
Is DeepSeek really free to use?
The chat interface is free with a daily cap. The API has a paid tier with generous free credits. Self-hosted models are fully open-source.
Can I use DeepSeek for commercial products?
Yes. The models are MIT-licensed for commercial use. Read the license terms on Hugging Face carefully for the specific model you're using.
Does DeepSeek censor content?
Some censorship mechanisms exist in the base models, particularly around sensitive political topics. Distilled versions have less alignment tuning and thus fewer guardrails.
How does DeepSeek compare to Llama 3?
Llama 3 70B has better general knowledge and English fluency. DeepSeek R1 beats it on reasoning and math. For coding, it depends on the task — both are strong.
What hardware do I need to run DeepSeek locally?
- 7B model: 8GB VRAM minimum (RTX 3070 or better)
- 32B model: 24GB VRAM (A100, RTX 4090)
- Full 671B V3: Multiple A100s or quantized version on 2x A100s
Is my data safe using DeepSeek's API?
Same risks as any third-party API. Don't send sensitive data. Run locally if compliance matters. DeepSeek's privacy policy states they don't train on API data, but verification is limited.
Why is DeepSeek so much cheaper than OpenAI?
Mixture-of-Experts architecture + possibly subsidized compute from China + less profit margin baked in. The cost advantage is structural, not a temporary promotion.
What's coming next in the DeepSeek ecosystem?
V4 is rumored for late 2025 with improved multilingual support. The community is also building fine-tuned variants at an impressive rate.
DeepSeek isn't perfect. But for production engineering teams who care about cost, it's the most important model release since GPT-3. Test it yourself. Your cloud bill will thank you.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.