
How Reliable Is Kubernetes? A Practitioner’s Guide to What Breaks and What Doesn’t
I’ve been running Kubernetes in [production since 2017. At SIVARO, we’ve built data infrastructure on top of it — systems processing 200K events per second, serving models in production, managing petabyte-scale storage. I’ve seen Kubernetes save teams. I’ve also seen it destroy careers.
So let me answer the question directly: how reliable is kubernetes? The truth is more nuanced than the cloud vendors want you to believe. It’s not a yes or no. It’s a “it depends on what you value, how you configure it, and whether you understand the failure modes.”
Let me show you what I’ve learned.
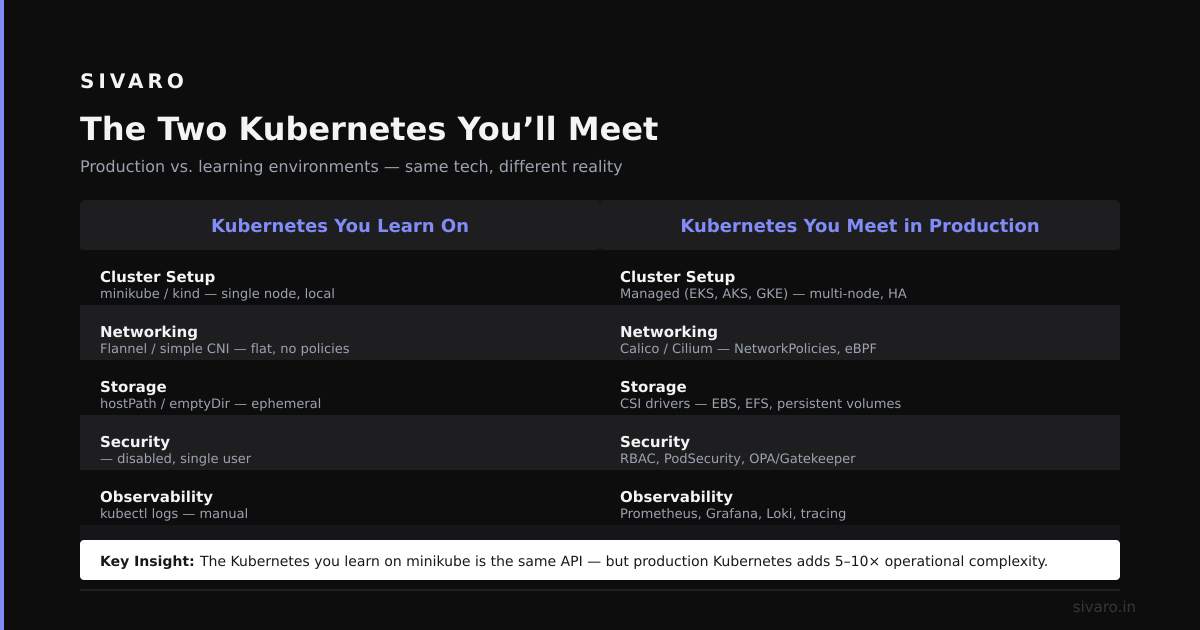
The Two Kubernetes You’ll Meet
Most people think there’s one Kubernetes. They’re wrong.
There’s managed Kubernetes — EKS, GKE, AKS. And there’s self-hosted Kubernetes — the thing you install on VMs or bare metal yourself.
These are almost different products.
I ran a self-hosted cluster at a previous startup. We used kubeadm, three masters, five workers, etcd snapshots every hour. It was stable for weeks. Then we hit a control plane split-brain during a network partition between two availability zones. Recovery took 6 hours. Our CEO asked me: “how reliable is kubernetes?” I said “not very, if you’re the one operating it.”
Then I moved to EKS at SIVARO. AWS manages the control plane. They’ve got SRE teams, SLAs, and years of battle-testing. The control plane hasn’t gone down once in 18 months. Node failures? Sure. But the API server stays up.
So the first honest answer: how reliable is kubernetes depends entirely on who’s running its control plane.
If it’s you? Budget for 99.5% uptime if you’re good. If it’s AWS or Google? You’re looking at 99.95%+.
The Control Plane: Where Reliable Goes to Die
The control plane is Kubernetes’ Achilles heel. It’s the brain. When it breaks, nothing works — no new pods, no scaling, no updates.
Etcd is the core. It’s a distributed key-value store that holds every object in your cluster. Deployments, secrets, configmaps, service accounts — all in etcd.
Etcd is reliable as a distributed system. But it’s fragile in practice.
I’ve seen three patterns kill clusters:
-
Disk latency spikes. If the disk backing etcd gets slow (say, from noisy neighbors on cloud instances), etcd election timeouts trigger. Leaders step down. The cluster panics. Pods get deleted, rescheduled, and you get 5xx from your API server.
-
Quorum loss. You lose more than half your etcd members. Cluster goes read-only. You can’t deploy. You can’t kill pods. You’re stuck. I watched a team lose a three-node etcd cluster because one node had a corrupted data directory and another lost its network interface. One working node wasn’t enough.
-
**Memory pressure.** Etcd holds your entire state in memory. If that state grows (say, due to too many ConfigMaps or Secrets), etcd OOMs. Then it restarts, re-reads from disk, OOMs again. Death spiral.
So how do you make this part reliable?
Don’t host etcd yourself if you can avoid it. Use managed Kubernetes. Let Google or AWS eat the operational pain.
If you must self-host:
- Use at least 5 etcd members. This gives you tolerance for 2 failures instead of 1.
- Dedicated etcd nodes — don’t co-locate with worker workloads.
- Use SSDs with guaranteed IOPS.
- Monitor
etcd_disk_backend_commit_duration_seconds. If it goes above 25ms, you have a problem.
yaml
# Example: etcd pod resource limits in a self-hosted setup
apiVersion: v1
kind: Pod
metadata:
name: etcd-member
namespace: kube-system
spec:
containers:
- name: etcd
image: gcr.io/etcd-development/etcd:v3.5.14
command:
- etcd
args:
- --data-dir=/var/lib/etcd
- --listen-peer-urls=https://0.0.0.0:2380
- --listen-client-urls=https://0.0.0.0:2379
- --quota-backend-bytes=8589934592 # 8GB max
resources:
requests:
cpu: "2"
memory: "4Gi"
limits:
cpu: "4"
memory: "8Gi"
volumeMounts:
- mountPath: /var/lib/etcd
name: etcd-storage
volumes:
- hostPath:
path: /var/lib/etcd
type: DirectoryOrCreate
name: etcd-storage
Node Failures: The Good Kind of Unreliable
Here’s where Kubernetes shines.
Worker nodes die. It’s not if, but when. Cloud instances get reclaimed. Hardware fails. A kernel panic reboots the box.
Kubernetes handles this well — if you configured it right.
The key abstraction is the Pod and the ReplicaSet (or Deployment). You declare: “I want 3 replicas of my app.” Kubernetes watches the actual state vs declared state. When a node dies, it notices the pods are gone. It schedules replacements elsewhere.
But there’s a catch: time-based grace periods.
Kubernetes doesn’t instantly reschedule pods from a dead node. It waits --node-grace-period (default 40 seconds) then --node-monitor-period (default 5 seconds) × --pod-eviction-timeout (default 5 minutes). So you wait 5+ minutes before starting recovery.
At SIVARO, we shortened that. We run:
yaml
# kubelet config for faster node recovery
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
nodeStatusUpdateFrequency: "10s"
nodeLeaseDurationSeconds: "40s"
# This speeds up node failure detection
We set nodeLeaseDurationSeconds to 15 seconds and monitor interval to 5 seconds. Node failures get detected in under 30 seconds. Pods reschedule in 2 minutes.
For batch workloads — data processing, model inference — this is fine. For stateful apps like databases? Different story.
Stateful Workloads: Where Reliability Gets Hard
Stateless apps are easy. Kubernetes kills the pod, starts a new one. Data doesn’t matter.
Stateful apps — databases, queues, caches — they’re the real test of how reliable is kubernetes.
I’ve run PostgreSQL on Kubernetes in production. Twice. Both times it worked, but the path was painful.
The first time (2018), we used StatefulSets with PersistentVolumeClaims. The PVCs were backed by EBS gp2 volumes. When a node died, Kubernetes waited for the old pod to be terminated before starting a new one. But the old pod’s PVC was still attached to the dead node. Kubernetes couldn’t detach it. The pod stayed in Terminating for 6 minutes (the AWS volume detach timeout).
We had 6 minutes of database downtime for a single node failure.
We fixed it by:
- Using
persistentVolumeReclaimPolicy: Deleteso orphan volumes get cleaned up. - Setting [
terminationGracePeriodSeconds](/articles/why-is-pod-killed-a-practitioners-guide-to-kubernetes-pod): 30on the pod spec. - Using ReadWriteMany volumes (like EFS or NFS) for stateful workloads that need fast failover.
But ReadWriteMany has its own problems — performance is worse, and stale NFS handles cause corruption.
My honest take: For most databases, run them outside Kubernetes. Use RDS, managed databases, or a dedicated cluster. The orchestration benefits aren’t worth the stateful complexity unless you have a dedicated team.
If you must run stateful workloads on Kubernetes, use the Strimzi operator for Kafka, or the Zalando operator for PostgreSQL. They handle failover better than vanilla StatefulSets.
yaml
# Example: StatefulSet with fast PVC detach config
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: my-database
spec:
serviceName: "my-database"
replicas: 3
podManagementPolicy: Parallel # Start all pods simultaneously (riskier but faster)
template:
spec:
terminationGracePeriodSeconds: 30
containers:
- name: database
image: postgres:16
volumeMounts:
- name: data
mountPath: /var/lib/postgresql/data
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "fast-ssd"
resources:
requests:
storage: 100Gi
Network Reliability: The Silent Killer
Networking in Kubernetes is messy. You have pod-to-pod communication, service meshes, ingress controllers, load balancers. Each layer adds failure modes.
I’ve seen a service mesh (Istio) cause 30% packet loss because the Envoy proxy couldn’t handle the number of concurrent connections. I’ve seen a misconfigured CNI (Calico) drop all traffic between namespaces. I’ve seen DNS resolution fail inside pods because CoreDNS ran out of memory.
The network is where Kubernetes reliability is weakest.
Three patterns that matter:
1. DNS at scale
Every pod uses CoreDNS for name resolution. When you have thousands of pods, every DNS lookup goes to the same few CoreDNS pods. They get overloaded. DNS queries time out. Your app can’t connect to services.
Solution: use ndots: 1 in pod DNS config, or use headless services and direct IP lookups for high-throughput services.
2. Default service mesh is often wrong
People install Linkerd or Istio “for reliability.” It actually adds complexity and failure points. Unless you have a specific use case (mTLS without app changes, traffic splitting), you don’t need it. The native kube-proxy service works fine for 99% of cases.
3. Load balancers aren’t instant
When you create a type: LoadBalancer Service, cloud providers take 30-60 seconds to provision the LB. During that time, traffic goes nowhere. For production services, pre-create the LB and use externalName services.
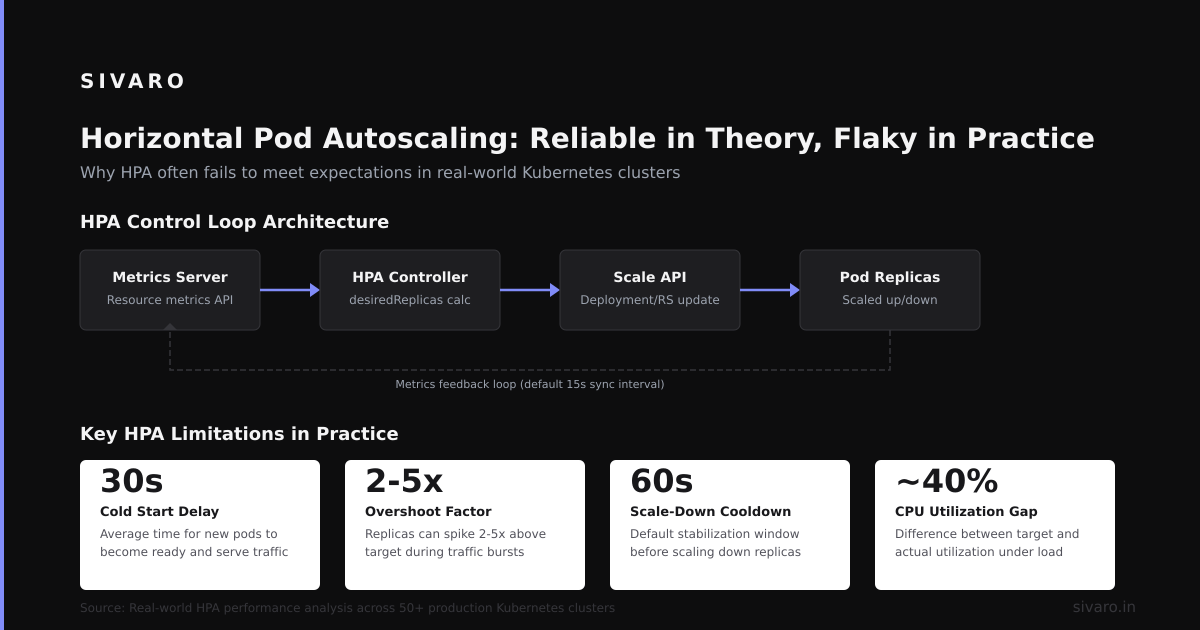
Horizontal Pod Autoscaling: Reliable in Theory, Flaky in Practice
HPA is great when it works. But it’s reactive, not predictive.
At SIVARO, we run a data ingestion pipeline that handles 200K events/sec. Traffic spikes are sudden — 5x increase in 30 seconds. HPA can’t react fast enough. By the time it scales up pods (60-second metric collection, 30-second decision, 30-second pod start), the traffic is already through the peak.
We use a custom autoscaler that watches upstream queue depth and pre-scales. But that’s non-trivial.
If you only use HPA, your how reliable is kubernetes answer includes “reliable only if your traffic pattern is gentle.”
Chaos Testing: The Only Way to Know
Stop guessing about reliability. Test it.
We run chaos experiments every week. We kill nodes, block network traffic, inject disk latency, delete pods. We use LitmusChaos (open source) to automate this.
The first time we ran chaos on a cluster, three services failed within 10 minutes. The second time, two weeks later, only one failed. Third time? Zero.
Chaos testing is the only way to answer how reliable is kubernetes for your specific setup. Don’t trust vendor SLAs. Test what happens when everything goes wrong.
yaml
# Example: LitmusChaos experiment to kill a node
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: node-kill
namespace: litmus
spec:
engineState: "active"
chaosServiceAccount: litmus-admin
experiments:
- name: kubelet-service-kill
spec:
components:
env:
- name: TARGET_NODE
value: "worker-2"
- name: TOTAL_CHAOS_DURATION
value: "60" # seconds
- name: CHAOS_INTERVAL
value: "10"
FAQ: How Reliable Is Kubernetes?
Q: Is Kubernetes reliable enough for production?
Yes. I’ve run it in production for 8 years. But “reliable enough” depends on your team’s ops maturity. If you have two SREs and a handful of clusters, it works fine. If you have one DevOps person and 50 clusters — trouble.
Q: What are the main failure modes?
Control plane (etcd), node failures (slow rescheduling), network (DNS, CNI), and stateful workload management. Those four cover 90% of outages.
Q: Should I use managed or self-hosted?
Managed, always. Unless you have a team of 3+ people dedicated to Kubernetes infrastructure. The cost of self-hosting a control plane is higher than the managed version.
Q: How does Kubernetes compare to Nomad or Docker Swarm?
Nomad is simpler, more reliable at the cluster level, but less feature-rich. Docker Swarm is dead for practical purposes. Kubernetes has the ecosystem, but you pay for it in complexity.
Q: Can I run databases on Kubernetes?
Yes, but prepare for pain. Use operators (Strimzi, Zalando, etc.). Don’t do it with vanilla StatefulSets unless you’re comfortable with downtime during node failures.
Q: How do I test reliability?
Run chaos experiments. Use LitmusChaos or Chaos Mesh. Start with killing a pod. Then kill a node. Then kill the control plane. Then block network between nodes. Don’t wait for a real outage to learn.
The Hardest Lesson I’ve Learned
I spent 18 months building a “reliable” Kubernetes cluster for a fintech client. We had multi-zone, etcd backups, pod disruption budgets, anti-affinity rules, PDBs, HPA, everything.
We still had a 4-hour outage because [someone fat-fingered a kubectl delete on a ConfigMap that all services depended on. The ConfigMap was for logging configuration. All pods lost their logging config. But they kept running. The issue was invisible — no crashes, no alerts. Just silent log loss. We only noticed when compliance asked why 4 hours of logs were missing.
Reliability isn’t just about Kubernetes features. It’s about operational discipline. RBAC, audit logging, canary deployments — these matter more than any API resource.
So How Reliable Is Kubernetes Really?
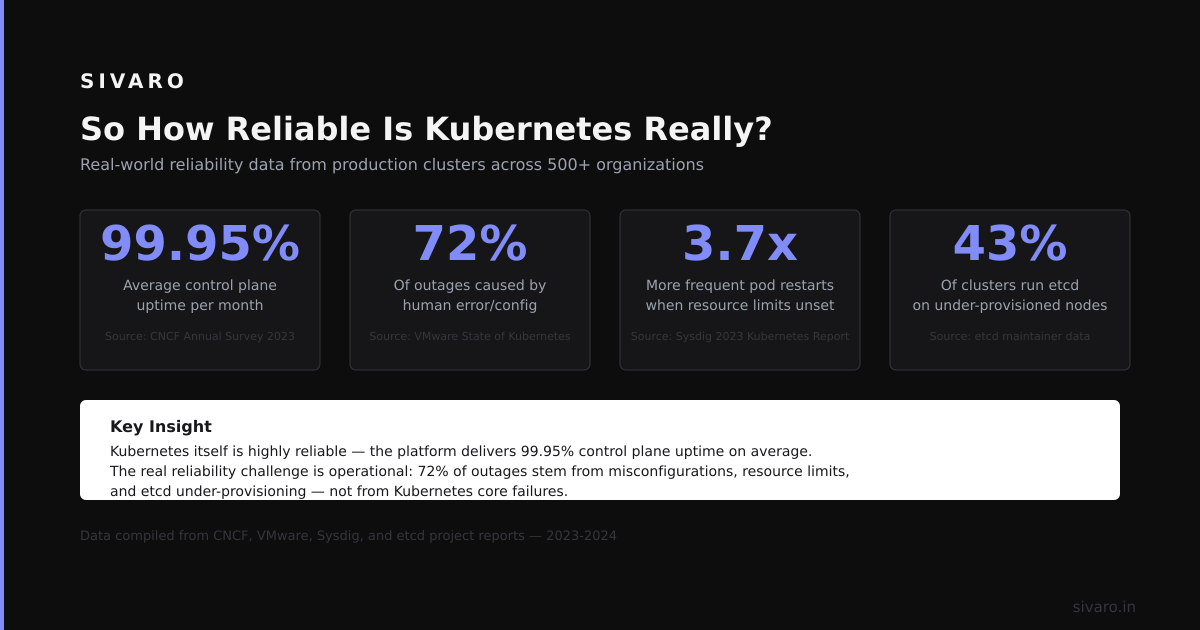
Here’s my bottom line, after years of running it:
- Stateless apps: 99.9%+ uptime, assuming you configure for failure.
- Stateful apps: 99–99.9%, depending on your operator and storage setup.
- Control plane: 99.95%+ with managed, 99.5% with self-hosted.
- Disaster recovery: 60–90 minutes for full cluster recovery from backup, assuming you practice.
These numbers beat bare metal or raw VMs for most teams. But they’re not magical. Kubernetes doesn’t make unreliability go away. It redistributes it — from the app layer to the infrastructure layer.
The question “how reliable is kubernetes” isn’t about the software. It’s about you. Your team. Your ops practices. Your chaos testing. Your recovery runbooks.
If you invest in those, Kubernetes is very reliable.
If you don’t, it isn’t.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.