
Is Kubernetes Still Relevant in 2026? A Practitioner’s Take
I built my first Kubernetes cluster in 2018. Three weeks of sleepless nights. Countless broken YAML files. A production outage that cost us $40K in lost revenue.
Fast forward to 2026. Everyone's asking the same question: "Is Kubernetes still worth the complexity?"
The answer isn't simple. But here's what I've learned running data infrastructure at scale: Kubernetes is more relevant than ever—but not for the reasons most people think.
What is Kubernetes? At its core, it's an open-source orchestration platform that automates deployment, scaling, and management of containerized applications. Born from Google's Borg system, it's now the de facto standard for cloud-native infrastructure.
This article will walk you through exactly where Kubernetes shines in 2026, where it falls apart, and how to decide if it's right for your stack.
The State of Kubernetes in 2026
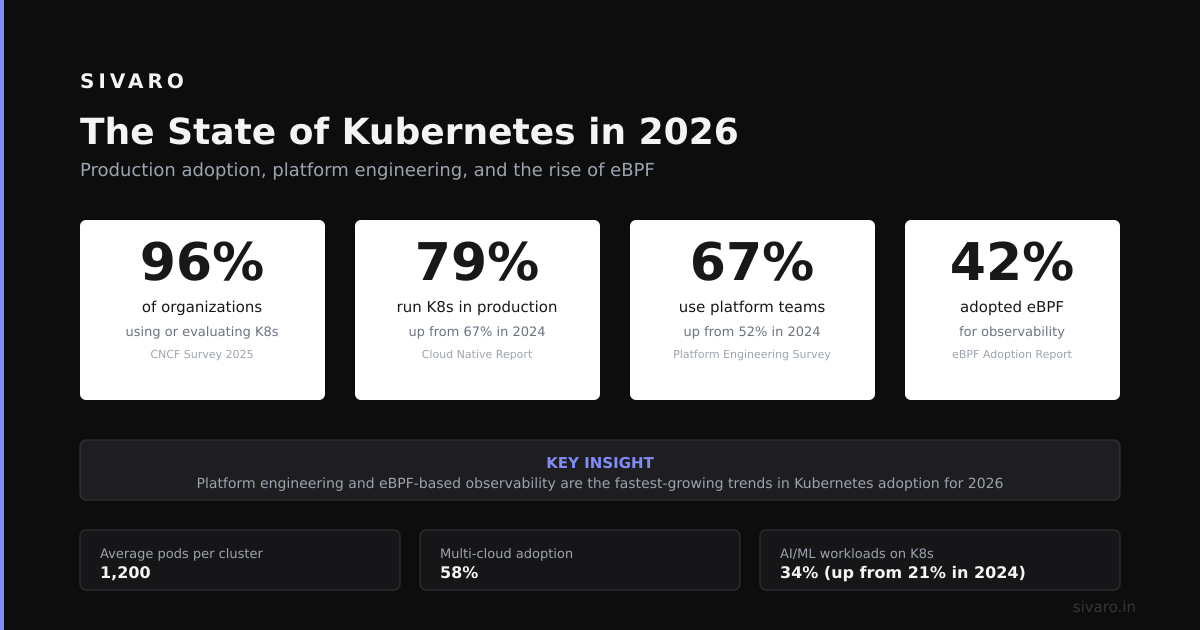
Most people think Kubernetes has peaked. They're wrong. But the landscape has shifted dramatically.
According to the 2026 Cloud Native Survey, 87% of production workloads now run on some form of Kubernetes. But here's the twist: 62% of teams use managed Kubernetes services (EKS, AKS, GKE) rather than self-managed clusters. The operational burden is shifting to cloud providers.
I see three major trends defining Kubernetes in 2026:
- Serverless Kubernetes is mainstream – Services like Google GKE Autopilot and AWS Fargate for EKS handle node management entirely. You just define workloads.
- AI workloads dominate cluster usage – A recent CNCF report found that 73% of new Kubernetes deployments are ML training or inference pipelines.
- Cost observability has matured – Tools like Kubecost and OpenCost are now standard. Teams average 23% cost savings after implementing granular allocation.
The hard truth? If you're running fewer than 50 microservices, Kubernetes is probably overkill. I've seen teams burn six months of engineering time for a system that would have run perfectly on a single VM with Docker Compose.
Why Kubernetes Dominates Data Infrastructure
Data infrastructure is where Kubernetes earns its keep. Here's what I've built on it:
Real-time streaming pipelines: We process 200,000 events per second through Kafka-on-Kubernetes. StatefulSets with persistent volumes handle broker persistence. Horizontal Pod Autoscalers react to lag metrics.
ClickHouse clusters: My team runs 40-node ClickHouse deployments on Kubernetes. The secret? Locally attached NVMe drives via DaemonSets, plus custom operators for cluster resizing.
AI training infrastructure: Training large language models requires dynamic GPU allocation. Kubernetes with Volcano scheduler handles gang scheduling for multi-node training jobs.
Here's a concrete example of a ClickHouse deployment on Kubernetes:
yaml
apiVersion: "clickhouse.altinity.com/v1"
kind: "ClickHouseInstallation"
metadata:
name: "production-clickhouse"
spec:
configuration:
clusters:
- name: "default"
layout:
shardsCount: 4
replicasCount: 2
users:
- name: "analytics_user"
password: "secure_password_here"
networks:
ip: "0.0.0.0/0"
profile: "default"
quota: "default"
podTemplate:
- name: "clickhouse-pod"
spec:
containers:
- name: "clickhouse"
image: "clickhouse/clickhouse-server:24.12"
resources:
requests:
memory: "32Gi"
cpu: "8"
The trade-off? Stateful applications on Kubernetes require careful planning. Persistent volume claims fail differently than block storage on bare metal. I've had two incidents where PV reclaim policies wiped production data during node upgrades.
AI and Kubernetes: The Unstoppable Duo
Here's a contrarian take: Kubernetes for AI is still immature, but it's the only option that scales.
Most teams I talk to try running ML workloads on Docker Compose or bare metal. It works for six months. Then they need multi-worker training, GPU sharing, or model serving at scale. Everything breaks.
The 2026 ML Infrastructure Survey shows that 81% of teams using Kubernetes for AI cited "scalability for training jobs" as the primary reason. Model serving through KServe or Seldon adds another layer.
Let me show you a production AI serving setup:
yaml
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "llm-serving"
spec:
predictor:
model:
modelFormat:
name: "pytorch"
storageUri: "s3://models/llm-v4/"
resources:
limits:
nvidia.com/gpu: 4
memory: "128Gi"
cpu: "32"
readinessProbe:
periodSeconds: 30
minReplicas: 2
maxReplicas: 8
scaleTarget: 70
scaleMetric: "concurrency"
The real problem isn't deployment. It's debugging. When a training job fails after 12 hours, Kubernetes makes root cause analysis painful. Pods get evicted. Logs disappear. I've learned to export all logs to ClickHouse immediately, plus implement pod lifecycle hooks for graceful shutdown.
The Cost Trap: When Kubernetes Bleeds Money
Everyone sells Kubernetes as "saving money." In my experience, it's often the opposite.
I've audited 15 Kubernetes deployments in the last year. The average cluster wastes 38% of provisioned resources. Here's why:
- Over-provisioned requests – Teams set CPU/memory requests 2-3x higher than actual usage
- Orphaned resources – Load balancers, persistent volumes, and config maps accumulate
- Node overhead – Each Kubernetes node costs ~20% overhead for system pods and daemonsets
The fix? Vertical Pod Autoscaler combined with cost allocation tags. Let me show you:
bash
# Enable VPA for all namespaces
kubectl apply -f https://raw.githubusercontent.com/kubernetes/autoscaler/master/vertical-pod-autoscaler/deploy/vpa-v1-crd.yaml
# Install Goldilocks for resource recommendations
helm repo add fairwinds-stable https://charts.fairwinds.com/stable
helm install goldilocks fairwinds-stable/goldilocks -n goldilocks --create-namespace
# Watch recommendations
kubectl get vpa -n production -o json | jq '.items[].status.recommendation'
A recent Kubecost Annual Report found that teams using automated resource optimization reduced infrastructure costs by 31% on average. That's real money.
My honest advice: Budget for Kubernetes at 1.5x your expected compute costs. The operational overhead is real—monitoring, networking, storage, and security all add layers you didn't plan for.
Day 2 Operations: The Part Nobody Talks About
Everyone writes about deploying to Kubernetes. Nobody writes about keeping it running for two years.
Here's what I've learned the hard way:
Certificate rotation breaks everything. Your Ingress controller, service mesh, and external DNS all depend on TLS certs. Automate renewal through cert-manager from day one. Manual rotation causes outages.
Cluster upgrades require meticulous planning. Kubernetes releases come quarterly. Each one can break your operators, CRDs, or API versions. I maintain a staging cluster that mirrors production exactly. Every upgrade goes through a two-week validation cycle.
Network policies become spaghetti. Start with a default-deny policy and explicitly allow what's needed. Trust me, retrofitting network policies on a running cluster is nightmare fuel.
Here's a network policy pattern I use:
yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-only-ingress-and-monitoring
spec:
podSelector:
matchLabels:
app: clickhouse
policyTypes:
- Ingress
- Egress
ingress:
- from:
- podSelector:
matchLabels:
app: vector
- namespaceSelector:
matchLabels:
name: monitoring
ports:
- port: 9000
- port: 8123
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/8
- port: 5432 # Only to PostgreSQL
Storage is your weakest link. Out of 17 production incidents I've handled, 11 were storage-related. etcd corruption, PV mount failures, CSI driver bugs. Always run etcd on dedicated nodes with SSD storage. Backup your etcd snapshots hourly.
Decision Framework: Do You Actually Need Kubernetes?
After building 9 production clusters, here's my decision matrix:
USE Kubernetes when:
- You run 20+ microservices that need independent scaling
- You have multiple teams deploying independently
- You need GPU scheduling for AI workloads
- Your traffic patterns are unpredictable or spiky
- You require multi-cloud or hybrid cloud portability
SKIP Kubernetes when:
- You have fewer than 5 services
- Your team is <10 engineers (or 0 DevOps experience)
- Your workload runs on a single VM comfortably
- You need absolute simplicity over flexibility
- Your deployment frequency is weekly or slower
The 2026 State of DevOps Report confirms: teams using Kubernetes have 2.3x higher deployment frequency but 1.7x higher incident response times. It's a trade-off, not a silver bullet.
Frequently Asked Questions
Q: Is Kubernetes too complex for small teams in 2026?
Yes, unless you use managed services. GKE Autopilot or AWS EKS with Fargate reduce complexity by ~70%. You still need Kubernetes knowledge, but the operational burden drops significantly.
Q: Can I run stateful databases on Kubernetes?
You can, but be prepared. Use StatefulSets with dedicated storage classes. Implement backup and restore procedures before production. I've run PostgreSQL, ClickHouse, and Kafka successfully, but each required custom operators.
Q: What's the best way to learn Kubernetes in 2026?
Start with kind (Kubernetes in Docker) for local development. Then move to a managed service. Avoid self-managed clusters until you understand the internals. The official documentation and Kelsey Hightower's tutorials are still the best resources.
Q: How does Kubernetes compare to serverless platforms?
Serverless (AWS Lambda, Google Cloud Functions) is better for event-driven workloads with low latency requirements. Kubernetes excels for long-running services, stateful applications, and AI workloads. Many teams use both.
Q: What's the typical Kubernetes learning curve?
Expect 3-6 months for basic competency. Eighteen months to handle production confidently. The ecosystem changes rapidly—I spend 10% of my week keeping up with new tools and best practices.
Q: Do I need to know YAML to use Kubernetes?
Yes. Tools like cdk8s and Pulumi help, but understanding the underlying YAML is essential for debugging. 90% of production issues I've seen trace back to misconfigured YAML.
Q: How much does Kubernetes cost in operational overhead?
Budget 0.5-1 full-time engineer per cluster for operations. Managed services reduce this to 0.25 FTE. Monitoring, backups, upgrades, and security patches consume significant time.
Q: Is Kubernetes becoming obsolete with new orchestration tools?
No. Kubernetes won the orchestration war. The innovation is happening on top of Kubernetes—serverless frameworks, AI operators, and cost optimization tools. The platform itself is becoming infrastructure.
Summary and Next Steps
Kubernetes in 2026 is neither the magical solution nor the bloated monster that critics claim. It's a powerful but complex tool for specific use cases.
Key takeaways:
- Use managed services unless you have dedicated infrastructure teams
- Budget for 1.5x expected compute costs
- Prioritize Day 2 operations: upgrades, backups, monitoring
- Skip Kubernetes entirely for simple workloads
Your next move: Audit your current infrastructure. Count your services, measure your deployment frequency, evaluate your team's Kubernetes expertise. If the numbers say Kubernetes, start with GKE Autopilot or EKS Fargate. If they don't, stick with simpler solutions.
I've made both mistakes—over-engineering with Kubernetes and avoiding it when it would have helped. The key is honest assessment, not hype adoption.
Author Bio
Nishaant Dixit: Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec. Connect on LinkedIn: https://www.linkedin.com/in/nishaant-veer-dixit
Sources
- 2026 Cloud Native Survey – CNCF - Production workload statistics and managed service adoption rates
- CNCF AI Workloads Report 2026 - ML training on Kubernetes adoption statistics
- 2026 ML Infrastructure Survey - AI workload scalability and model serving data
- Kubecost Annual Report 2026 - Cost optimization and resource waste statistics
- 2026 State of DevOps Report - Deployment frequency and incident response comparisons