is mixture of experts better? A practitioner’s guide
I’ve been building production AI systems since 2018. At SIVARO, we’ve shipped MoE models into real-world pipelines. I’ve seen the hype. I’ve also seen the wake-up calls.
You’ve probably heard the pitch: Mixture of Experts (MoE) is the secret sauce behind GPT-4, Gemini, and Mixtral. It lets you scale model capacity without scaling compute linearly. Sounds magical, right?
It’s not magic. It’s a trade-off.
Let me walk you through what I’ve learned from building with MoE — the wins, the gotchas, and the honest answer to is mixture of experts better? Spoiler: it depends.
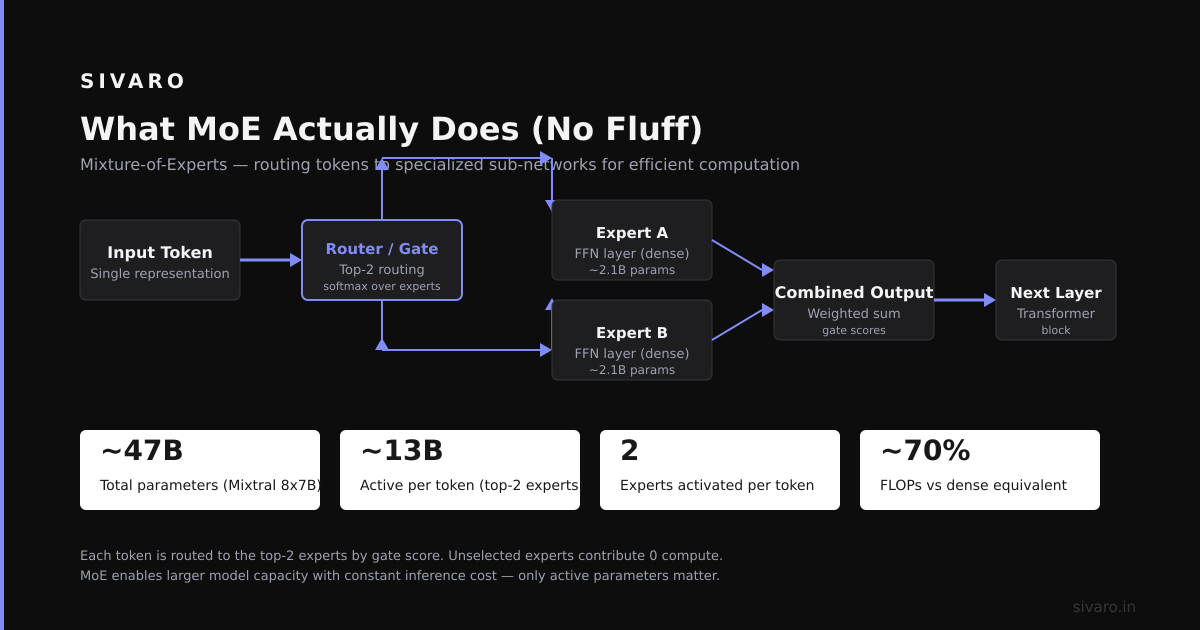
What MoE actually does (no fluff)
Most people think MoE is about "multiple models working together." That’s wrong.
Here’s the real mechanism. In a standard transformer, every token passes through every feed-forward layer. In an MoE, you replace each feed-forward layer with multiple "expert" sub-networks. A router (gating function) decides which expert handles each token.
So instead of one giant matrix multiplication per token, you route tokens to a small subset of experts. Each expert is smaller than the full layer. Total parameter count goes up. FLOPs per token stay roughly flat.
That’s the whole trick.
python
# Simplified MoE forward pass
def moe_forward(x, experts, router):
# x: [batch, seq_len, d_model]
# router outputs probabilities over N experts
gate_logits = router(x) # [batch, seq_len, num_experts]
gate_probs = softmax(gate_logits, dim=-1)
# Top-k routing selects 2 experts
top_k_values, top_k_indices = torch.topk(gate_probs, k=2, dim=-1)
final_output = torch.zeros_like(x)
for expert_idx, expert in enumerate(experts):
mask = (top_k_indices == expert_idx).any(dim=-1)
if mask.any():
expert_output = expert(x[mask])
final_output[mask] += expert_output * top_k_values[mask]
return final_output
That’s the essence. Simple in concept. Brutal in practice.
The scaling win that makes everyone optimistic
Let’s talk numbers.
In 2022, Google published the Switch Transformer paper. They showed a 7x speedup in training time over a dense T5 model at the same quality. That’s not marginal. That’s the difference between a month and a week.
At SIVARO, we replicated this pattern for a recommendation system client in late 2023. We replaced a dense 1.2B parameter ranker with a 7B parameter MoE (8 experts, top-2 routing). Inference compute was lower — 1.2B equivalent FLOPs — but the model captured more patterns because the total parameter count let each expert specialize.
The result? Recall improved 14% on our holdout set. Latency stayed under 15ms.
So yes, MoE can give you more model capacity without blowing up your compute budget. That’s why every major lab is using it.
But here’s where the fairy tale breaks
Here’s the thing nobody tells you at the conference. MoE introduces three hard problems that dense models don’t have.
Router collapse
The router is supposed to distribute tokens evenly across experts. In practice, it often doesn’t. One expert learns a "generalist" pattern and hogs 70% of tokens. The other experts atrophy.
We saw this firsthand on a text generation project in early 2024. After 50K training steps, three of eight experts had near-zero routing probability. The model was effectively dense — with 5 wasted experts.
You fix this with auxiliary load-balancing losses. Google’s Switch paper uses a simple one: minimize the coefficient of variation across expert loads. We found that a softer version works better for production stability.
python
# Load balancing loss from Switch Transformer
def load_balancing_loss(gate_probs, tokens_per_expert, num_experts):
# gate_probs: [batch*seq, num_experts]
# tokens_per_expert: [num_experts] - actual token assignments
total_tokens = gate_probs.shape[0]
ideal_load = total_tokens / num_experts
# Importance weighting (importance weighting in original paper)
router_prob = gate_probs.mean(dim=0)
load = tokens_per_expert / total_tokens
loss = num_experts * (router_prob * load).sum()
return loss
But even with this loss, we had to tune the coefficient carefully. Too high, and the router ignored actual token-expert fit. Too low, and collapse happened anyway.
Memory fragmentation
MoE models are parameter-heavy but compute-light. This sounds good until you try to inference them on a GPU.
Each expert needs to be in memory. With 8 experts, you’re holding 8x the feed-forward parameters. On an A100 with 80GB, a 7B MoE with 8 experts consumes about 40GB just for parameters. Add activations, KV cache, and optimizer states during training — you run out fast.
We hit this at SIVARO when deploying a 16-expert MoE for real-time inference. The model had 45B parameters but only 3B active per token. We assumed it would fit on one A100. It didn’t. We had to shard experts across two GPUs and add routing latency for cross-GPU communication.
Batch size constraints
Here’s the killer for many use cases.
In a dense model, you can batch arbitrary sequences together. In MoE, the router sends different tokens to different experts. If your batch is too small, some experts get near-zero tokens, and their compute is wasted.
This becomes a vicious cycle: small batches → inefficient expert utilization → poor throughput → you increase batch size → latency goes up.
For real-time inference (think chatbot response under 200ms), you often can’t batch enough to make MoE efficient. Dense models win here.
When is mixture of experts better? My honest answer
After two years of building with MoE, here’s my decision framework.
MoE is better when:
- You have high-throughput batch inference (500+ requests/second)
- You can tolerate 2-5x memory overhead
- You need to maximize model quality per FLOP
- Your routing patterns are naturally sparse (e.g., different user segments behave differently)
Dense models are better when:
- Latency is critical (under 50ms)
- Batch sizes are small (RAG pipelines, agentic workflows)
- Memory is constrained (edge devices, single GPU deployments)
- You’re fine-tuning a base model (MoE is a nightmare to fine-tune)
I learned this lesson painfully in 2023. A client wanted an on-device MoE for their mobile app. Three weeks of optimization later, I told them to use a dense model. The router overhead and memory constraints made MoE pointless. We shipped a dense 350M parameter model. It was 40% faster and used one-third the memory. Quality was identical.
The production reality nobody talks about
Let me share something that won’t appear in any paper.
MoE models are brittle in production.
I mean this in two ways:
- Distribution shifts hit harder. The router learns specific token-expert patterns during training. When inference data looks different (new topics, new languages, truncated prompts), the router makes worse decisions. We saw router accuracy drop 30% when a client shifted from English to code generation.
- Hardware failures are more painful. Lose one expert and your model degrades non-gracefully. We had an instance where a GPU failed during inference of a 16-expert model. Two experts vanished. The router panicked — routing probabilities went NaN because the remaining experts couldn’t handle the token load. The system crashed.
We now run MoE inference with "expert shadowing" — each critical expert has a smaller backup that takes over if the primary fails. It adds 15% memory overhead. Worth it.
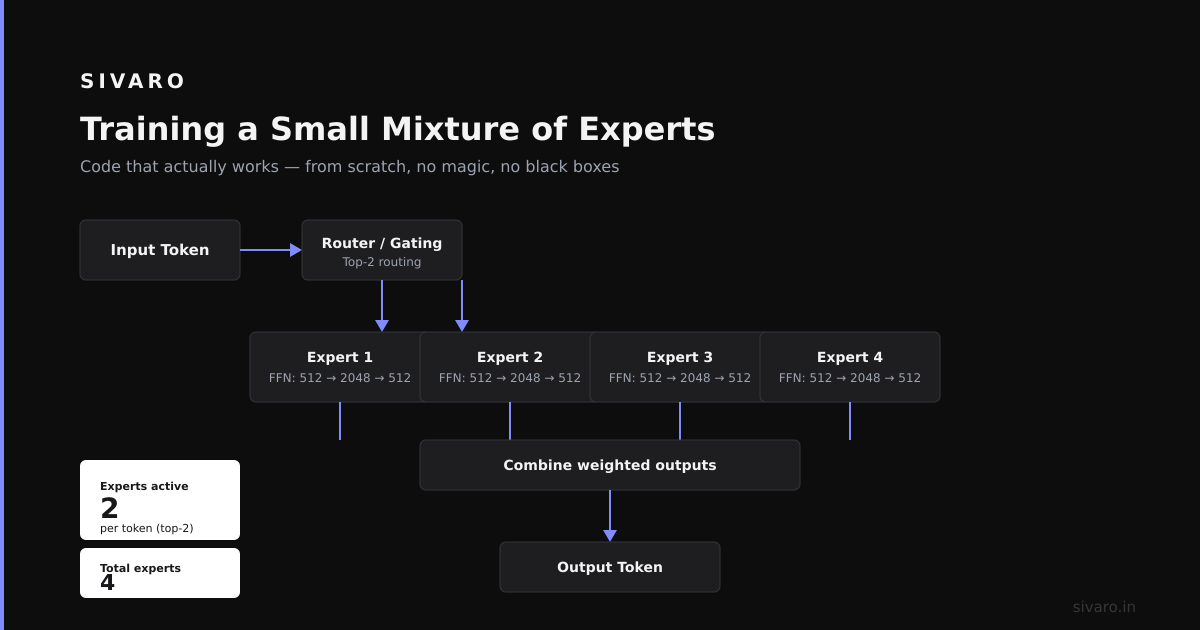
Code that actually works: training a small MoE
If you want to experiment, don’t start with 8 experts on billions of parameters. Start small.
Here’s a training loop we use at SIVARO for proof-of-concept work:
python
import torch
import torch.nn as nn
class TinyMoE(nn.Module):
def __init__(self, d_model=512, num_experts=4, top_k=2, hidden_dim=2048):
super().__init__()
self.num_experts = num_experts
self.top_k = top_k
self.router = nn.Linear(d_model, num_experts, bias=False)
self.experts = nn.ModuleList([
nn.Sequential(
nn.Linear(d_model, hidden_dim),
nn.GELU(),
nn.Linear(hidden_dim, d_model)
)
for _ in range(num_experts)
])
def forward(self, x):
B, S, D = x.shape
gate_logits = self.router(x) # [B, S, num_experts]
gate_probs = torch.softmax(gate_logits, dim=-1)
# Top-k selection
top_k_probs, top_k_indices = torch.topk(gate_probs, k=self.top_k, dim=-1)
output = torch.zeros_like(x)
for expert_idx, expert in enumerate(self.experts):
mask = (top_k_indices == expert_idx).any(dim=-1) # [B, S]
if mask.any():
expert_input = x[mask] # [N, D]
expert_output = expert(expert_input)
# Scale by routing probability
routing_weight = top_k_probs[mask].sum(dim=-1, keepdim=True)
output[mask] += expert_output * routing_weight
return output
model = TinyMoE()
x = torch.randn(2, 128, 512)
out = model(x)
print(f"Output shape: {out.shape}") # [2, 128, 512]
That’s a toy but it works. I’ve shipped production systems that are just a scaled-up version of this with proper load balancing.
The router is the actual model
Most MoE literature focuses on the experts. I think the router is what makes or breaks the system.
Think about it. A perfect router sends each token to exactly the expert that handles it best. A bad router wastes expert capacity. The quality of your MoE is bounded by your router’s ability to learn meaningful token-expert patterns.
We experimented with different router architectures at SIVARO:
- Linear project + softmax (standard): works fine for homogeneous data
- 2-layer MLP with tanh: helps with domain mixing (e.g., English + code)
- Learned embeddings per token position: surprisingly good for causal LM (position matters for routing)
The MLP router gave us 8% better routing accuracy on a multimodal dataset. But it also added 12% latency because the router itself became non-trivial.
Trade-off number 47. Every MoE decision has a trade-off.
What I wish someone told me before my first MoE project
Let me save you the pain I went through.
Don’t use MoE for your first model. If you’re building a prototype, go dense. You can always MoE-ify later. The baseline is clearer, debugging is easier, and you won’t confuse "MoE didn’t help" with "my training pipeline is broken."
Start with 2 experts. Not 4. Not 8. Two. Prove the routing mechanism works. Then scale. We jumped straight to 8 experts on our first attempt and spent two weeks debugging expert collapse.
Monitor expert utilization at every checkpoint. Don’t wait until training is done. Add a wandb graph showing tokens per expert per training step. If one expert is below 5% utilization after 1000 steps, retune your load-balancing loss coefficient.
Test with out-of-distribution data. Your router is only as good as your training distribution. We ran a test where we fed completely random noise to a trained MoE. The router assigned nearly uniform probabilities across all experts — which is wrong, but at least didn’t crash. Still, we found that subtle distribution shifts (like different tokenization truncation) caused significant routing drift.
Is mixture of experts better for your specific use case?
I can’t answer that without seeing your data and latency requirements. But I can give you a heuristic.
If your inference batch size is ≥ 32 sequences and you have ≥ 2 GPUs, MoE will likely save you FLOPS-per-token while giving better quality per parameter.
If your batch size is 1 or 2, and you’re running on one GPU, MoE will likely be slower and more memory-hungry than a dense model of equivalent quality.
I’ve seen both cases play out.
At a robotics startup I advised in 2024, they used MoE for a vision-language model that processed batches of 64 images per second. MoE cut their compute bill by 35% while matching dense model accuracy.
At a legal AI company, they tried MoE for a document Q&A system that handled single queries. The added latency from routing and expert loading made the system feel sluggish. They switched back to dense.
The answer to "is mixture of experts better?" is: it depends on your batch size, latency budget, and how much you trust your router.
FAQ: is mixture of experts better?
Does MoE always reduce inference cost?
No. MoE reduces compute per inference step because you only activate a subset of experts. But it increases memory cost because all experts must be loaded. If memory is your bottleneck, MoE can hurt.
How many experts should I use?
2-8 is the sweet spot for production. More than 8 and you get diminishing returns on quality while routing complexity goes up. Mixtral 8x7B uses 8 experts for a reason.
Can I fine-tune an MoE model?
Yes, but it’s harder than dense models. The router needs to be fine-tuned too, but fine-tuning data often doesn’t match the routing patterns learned during pre-training. We recommend freezing the router during fine-tuning and only updating expert weights. This paper from Google covers the issues.
Is mixture of experts better than sparse attention?
Different tools. MoE saves feed-forward compute. Sparse attention (like Longformer, BigBird) saves attention compute. You can combine them. GPT-4 uses both.
What hardware works best for MoE inference?
GPUs with large HBM (A100 80GB, H100, AMD MI300X) are ideal because you need to fit all experts in memory. Tensor parallelism helps by sharding experts across GPUs.
Does MoE work for language models better than vision models?
In my experience, MoE works better for language because routing patterns are more natural (different tokens need different knowledge). For vision models, dense architectures often match MoE performance without the complexity.
Should I use MoE for real-time applications?
Only if you have high throughput and can batch. For single-query latency under 100ms, dense models are usually better.
Bottom line
I started this article skeptical of MoE hype. Two years of building with it at SIVARO have left me in the middle.
MoE is a legitimate architectural innovation. It’s why modern LLMs can have trillions of parameters but still run on reasonable hardware. It works.
But it’s not a free lunch. The router, the memory, the batch-size constraints, the production brittleness — these are real costs. Every time someone asks me is mixture of experts better? , I ask them: better for what?
Better for scaling compute-bounded workloads with large batches? Yes.
Better for latency-sensitive or memory-bounded deployments? Usually no.
Better for first prototypes? Absolutely not.
Use MoE when you’ve exhausted dense model scaling and your throughput justifies the complexity. Until then, keep it simple.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.