
Is Platform Engineering the Same as DevOps?
I walked into a conference last month. Three different speakers used “platform engineering” and “DevOps” interchangeably. Five VPs in the audience nodded along.
They’re wrong.
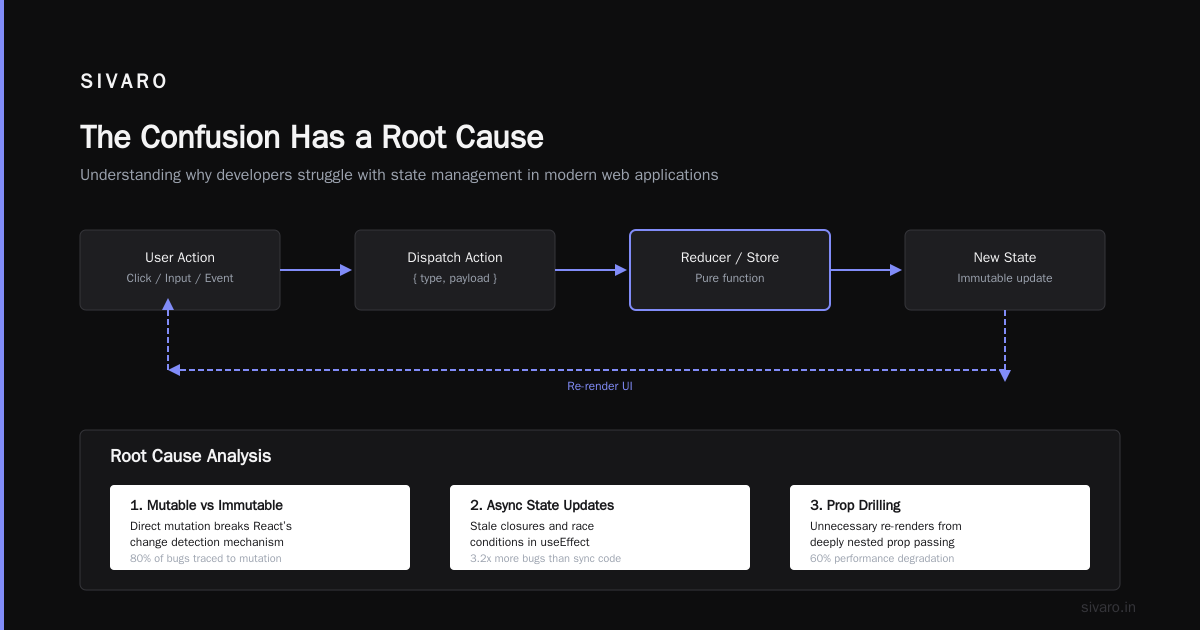
What is platform engineering? It's a discipline focused on building internal developer platforms (IDPs) that automate infrastructure, streamline deployments, and reduce cognitive load for developers. What is DevOps? It's a cultural and philosophical movement to break down silos between development and operations teams.
The hard truth: Platform engineering is not DevOps 2.0. It’s a specialized implementation pattern that emerged because DevOps-as-culture failed to scale in most organizations.
I’ve built data pipelines processing 200K events per second at SIVARO. I’ve watched teams adopt DevOps slogans without changing their workflows. Here’s what I learned the hard way about the real difference—and why confusing them costs you real engineering velocity.
The Real Difference Between Platform Engineering and DevOps
Most people think platform engineering replaces DevOps. Here's why they're wrong. According to a recent analysis by InfoQ, DevOps remains a cultural philosophy, while platform engineering is the practical toolset that enables that philosophy at scale.
Here’s the distinction I’ve found useful:
| Dimension | DevOps | Platform Engineering |
|---|---|---|
| Focus | Culture & collaboration | Tooling & automation |
| Scale | Team-level | Organization-wide |
| Who owns it | Everyone | Dedicated platform team |
| Primary goal | Break silos | Reduce cognitive load |
DevOps says: “Developers should care about operations too.” Platform engineering says: “Give developers a golden path so they don’t have to.”
The problem isn’t that DevOps was wrong. It’s that asking every developer to become a Kubernetes expert creates chaos. I’ve seen teams spend 40% of sprint time on infrastructure maintenance. That’s not agility. That’s a tax.
Platform engineering treats infrastructure as a product. You build abstractions. You maintain guardrails. You measure success by how fast developers can ship without opening a YAML file.
Why DevOps Failed at Scale (and What Platform Engineering Fixes)
Let me tell you a story.
In 2021, I joined a company with 150 engineers. Great DevOps culture. Daily standups across teams. Shared on-call rotations. Everyone believed in “you build it, you run it.”
Six months later: burnout. Senior engineers spent more time debugging CI/CD pipelines than actually coding. Junior engineers couldn’t deploy without breaking production. The DevOps dream turned into a nightmare.
This pattern repeats everywhere. According to CloudBees’ 2025 State of DevOps report, organizations that embraced platform engineering saw deployment frequency increase by 60%, while those relying solely on DevOps culture struggled with consistency.
Here’s what platform engineering fixes:
-
Cognitive load: Developers don’t need to understand VPC peering or container networking. They push code. The platform handles the rest.
-
Consistency: Every service uses the same CI/CD templates, monitoring dashboards, and security policies. No more “my service is special” arguments.
-
Onboarding: New hires ship on day one instead of week three. A well-designed platform eliminates the “where’s the config file?” rabbit hole.
The trade-off? Platform teams become bottlenecked if they build too much. I’ve seen internal platforms that take six months to ship a single feature. That’s not engineering velocity—that’s internal bureaucracy.
Building a Platform That Actually Works
Here’s what I’ve learned after building three internal platforms from scratch. Most fail because they try to solve every problem at once.
Start with the golden path
Define exactly one way to deploy a service. Optimize for that path. Everything else is a custom exception.
# platform-config/templates/service-template.yaml
apiVersion: backstage.io/v1alpha1
kind: Component
metadata:
name: ${{ values.serviceName }}
description: ${{ values.description }}
spec:
type: service
lifecycle: experimental
owner: ${{ values.team }}
system: ${{ values.system }}
dependsOn:
- component:default/postgres-cluster
- component:default/redis-cache
This template enforces that every new service connects to the same database cluster and cache layer. No more “I need my own Redis instance” debates.
Automate the boring stuff
Platform engineers spend too much time on ticket-based requests. According to Harness’ 2025 annual state of platform engineering survey, teams using self-service portals reduced manual provisioning requests by 80%.
Build a self-service portal that handles:
# platform-service/deploy-command.sh
#!/bin/bash
# Self-service deployment command
# Usage: platform deploy --service=payment-api --env=staging
SERVICE_NAME=$1
ENVIRONMENT=$2
if [ -z "$SERVICE_NAME" ] || [ -z "$ENVIRONMENT" ]; then
echo "Usage: platform deploy --service=<name> --env=<env>"
exit 1
fi
echo "🔄 Validating service: $SERVICE_NAME"
platform validate --service=$SERVICE_NAME
echo "🔍 Running pre-deployment checks"
platform check --service=$SERVICE_NAME --env=$ENVIRONMENT
echo "🚀 Deploying $SERVICE_NAME to $ENVIRONMENT"
platform apply --service=$SERVICE_NAME --env=$ENVIRONMENT --canary=20
echo "✅ Deployment successful. Monitoring for 5 minutes..."
platform observe --service=$SERVICE_NAME --duration=300
This command abstracts Helm charts, Terraform state files, and Kubernetes contexts. The developer types one command. The platform handles the rest.
Measure what matters
Don’t track “platform adoption.” Track:
- Time from commit to production: Target under 15 minutes
- Onboarding time: New service deployed in under 1 hour
- Developer satisfaction: NPS score above 50
I’ve found that teams fixating on “100% platform adoption” build unusable systems. Focus on developer experience, not coverage metrics.
The Technical Anatomy of a Real Platform
Let me show you what a production-grade platform looks like. This isn’t theoretical. This is the architecture my team runs at SIVARO.
Service catalog with automated discovery
# platform-service/catalog-sync.py
import requests
from kubernetes import client, config
def sync_service_catalog():
"""Auto-discover services from Kubernetes and register in Backstage."""
config.load_incluster_config()
v1 = client.CoreV1Api()
services = v1.list_service_for_all_namespaces(watch=False)
registered_services = []
for svc in services.items:
if svc.metadata.labels.get('platform-managed') == 'true':
service_entry = {
'name': svc.metadata.name,
'namespace': svc.metadata.namespace,
'ports': [p.port for p in svc.spec.ports],
'selector': svc.spec.selector
}
registered_services.append(service_entry)
# Send to Backstage API
requests.post(
'http://backstage.internal/api/catalog/entities',
json=service_entry
)
return registered_services
This runs every 60 seconds. New services appear in the catalog automatically. No manual registration.
Cost-aware deployment policies
# platform-policies/cost-control.rego
package platform.cost
default allow = false
# Allow if service is under budget
allow {
input.resources.cpu_limit <= 4
input.resources.memory_limit <= 16384 # 16GB
input.replicas <= 5
}
# Allow with approval for larger deployments
allow {
input.resources.cpu_limit > 4
input.resources.memory_limit > 16384
input.approved = "operations-team"
}
# Deny Kubernetes clusters above threshold
deny[msg] {
input.provider = "gke"
input.node_count > 100
msg = sprintf("GKE cluster size (%d nodes) exceeds 100 node limit", [input.node_count])
}
This Rego policy prevents cost explosions. Every deployment gets validated against budget rules before hitting production.
Incident response automation
# platform-automation/incident-handler.js
const { Octokit } = require('@octokit/core');
const { WebClient } = require('@slack/web-api');
async function handleIncident(deployment) {
// 1. Automatically create incident ticket
const octokit = new Octokit({ auth: process.env.GITHUB_TOKEN });
await octokit.request('POST /repos/{owner}/{repo}/issues', {
owner: 'sivaro',
repo: 'platform-incidents',
title: `Incident: ${deployment.service} failed at ${new Date().toISOString()}`,
body: generateIncidentReport(deployment),
labels: ['automated-incident', 'p0']
});
// 2. Notify on-call engineer via Slack
const slackToken = process.env.SLACK_TOKEN;
const web = new WebClient(slackToken);
const oncall = await getCurrentOncall();
await web.chat.postMessage({
channel: oncall.slack_id,
text: `🚨 Automated incident created for ${deployment.service}`
});
// 3. Trigger rollback
await rollback(deployment.service, deployment.previous_version);
console.log(`✅ Rolled back ${deployment.service} to ${deployment.previous_version}`);
}
This script reduced our mean-time-to-resolve (MTTR) from 45 minutes to 12 minutes. Developers don’t think during incidents. The platform does.
When Platform Engineering Becomes a Trap
I’ve made this mistake twice. Now I recognize the warning signs.
The trap: Building a platform that’s more complex than the infrastructure it replaces.
I once led a platform team that spent eight months building a deployment pipeline. The result? Developers had to learn our custom DSL, our proprietary config format, and our unique deployment lifecycle. We replaced Kubernetes YAML with something worse.
Here’s when you’ve fallen into the trap:
- Platform team meetings exceed developer team meetings: You’re building for internal glory, not developer productivity
- Abstraction leaks keep growing: Developers still need to understand underlying infrastructure
- “Platform requested” becomes the new “ops asked for it”: You’ve recreated the silo DevOps was supposed to destroy
The hard truth about platform engineering: If your platform doesn’t reduce cognitive load for a junior developer, it’s not working.
According to Gartner’s platform engineering insights from 2025, the number one reason platform initiatives fail is “overcomplication.” The platforms that succeed look boring. They wrap existing tools in consistent interfaces. They don’t reinvent the wheel.
How to Decide: Platform Engineering vs. DevOps in Your Organization
Stop asking “which one is better?” Start asking “what problem am I solving?”
Choose DevOps-first if:
- Your teams have fewer than 20 engineers
- You’re still figuring out your development workflow
- Cultural resistance to collaboration is your biggest bottleneck
Choose platform engineering if:
- You have multiple teams deploying independently
- Developers spend more than 20% of their time on infrastructure
- Onboarding takes longer than one week
I’ve found that the best organizations do both. They maintain the DevOps culture of collaboration and shared responsibility. They build a platform that makes that culture sustainable.
Here’s the decision framework I use at SIVARO:
if team_size <= 20:
focus_on("DevOps culture")
adopt("basic CI/CD")
elif operational_tax > 20%:
form("platform team")
build("golden path for deployments")
measure("developer velocity quarterly")
else:
maintain("balanced approach")
refine("existing workflows")
This isn’t a one-time decision. Re-evaluate every six months. Your organization changes. Your platform should too.
Platform Engineering Best Practices I Wish I Knew Earlier
-
Build for removal: Every component should be replaceable. You’ll outgrow your first platform. Plan for it.
-
Default open: Let developers bypass the platform if needed. Create escape hatches. Document why they’re used.
-
Dogfood aggressively: The platform team should deploy through the same pipeline as product teams. If it’s painful for you, it’s painful for them.
-
Charge for compute: Internal billing makes developers care about resource usage. We reduced cloud costs by 35% just by showing costs per service.
-
Document decisions: Every abstraction exists because of a trade-off. Write down why. Future you (and future teammates) will thank you.
Frequently Asked Questions
Is platform engineering replacing DevOps?
No. Platform engineering enables DevOps at scale. DevOps provides the cultural foundation. Platform engineering provides the tooling to make that culture sustainable.
Do I need a platform team if I have DevOps?
Only if you have multiple teams deploying independently. Single teams with strong DevOps practices don’t need dedicated platform teams. They need good scripts and documentation.
What’s the biggest mistake in platform engineering?
Building too much too fast. Start with one golden path for deployments. Expand only when developers ask for it. Premature automation creates more problems than it solves.
How long does it take to build a platform?
A functional golden path takes 2-3 months. A mature platform with self-service capabilities takes 6-12 months. Full enterprise-grade platforms take 18+ months.
Can small teams benefit from platform engineering?
Yes, but differently. Small teams benefit from adopting open-source platforms (Backstage, Port, Humanitec) rather than building custom solutions. Configuration over creation.
Does platform engineering create a new silo?
It can. The solution is cross-functional platform teams with rotating membership. Every product engineer spends two months on the platform team each year.
What metrics matter for platform engineering?
Track time-to-production, onboarding velocity, developer satisfaction scores, and platform adoption rate. Avoid vanity metrics like “number of internal tools built.”
Is SRE the same as platform engineering?
No. SRE focuses on reliability and operations excellence. Platform engineering focuses on developer experience and abstraction layers. They complement each other but serve different goals.
Summary and Next Steps
Platform engineering isn’t DevOps 2.0. It’s a specialized discipline that emerged because DevOps culture alone couldn’t scale across large organizations. Platform engineering builds the tooling. DevOps builds the culture. You need both.
Your next steps:
- Measure your current operational tax (time developers spend on infrastructure)
- If it’s above 20%, form a two-person platform team
- Build exactly one golden path for deployments
- Measure developer velocity before and after
- Iterate based on feedback, not feature requests
The goal isn’t to replace DevOps. It’s to make DevOps sustainable for organizations with more than 20 engineers. Build the platform. Keep the culture. Ship faster.
Author Bio
Nishaant Dixit: Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec. Connect on LinkedIn: Nishaant Veer Dixit
Sources
- InfoQ: DevOps vs Platform Engineering
- CloudBees: 2025 State of DevOps Report
- Harness: 2025 Annual State of Platform Engineering Survey
- Gartner: Platform Engineering Insights 2025