
Open Weights vs Closed Source LLMs: What Actually Works in Production
I spent the first six months of 2025 convinced we'd run every production workload on GPT-4-class models. Then our AWS bill hit $47,000 in a single month. That's when I got serious about open weights.
Here's the thing nobody tells you: the debate between open weights vs closed source LLMs isn't about ideology. It's about pain points. Data security pain. Cost pain. Latency pain. And most of all — the pain of watching your carefully-built RAG pipeline fall apart when Anthropic changes their embedding model without warning.
I'm Nishaant Dixit, founder of SIVARO. We build data infrastructure and production AI systems for companies processing hundreds of thousands of events per second. These aren't toy apps. So when I talk about model selection, I'm talking about what survives at scale.
This guide covers the real trade-offs between open and closed models. How to decide. How to train locally when you need to. And why the Model Context Protocol changes the calculus for both sides.
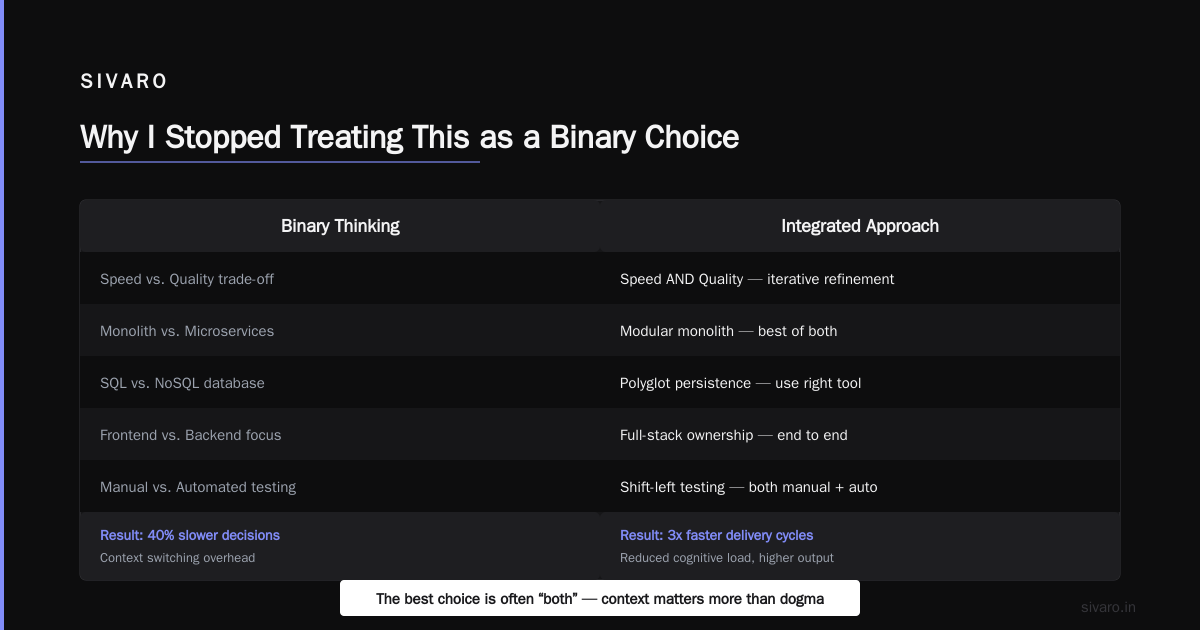
Why I Stopped Treating This as a Binary Choice
Most people think "open weights means free and closed source means expensive." They're wrong because the math doesn't work that way.
Open weights models like Llama 3.1 405B or Mistral Large cost a fortune to run yourself. You need GPU clusters. Cooling. Power. The kind of infrastructure that makes cloud providers weep with joy. Meanwhile, closed APIs like GPT-4o or Claude 3.5 Sonnet look cheap at token prices — until your usage hits enterprise scale.
I worked with a fintech company in April 2026 that ran their entire customer support pipeline on GPT-4o. 2.3 million tokens per day. $8,400 monthly. For a startup with 12 employees. That's not sustainable.
But here's the counterpoint: another client tried running Llama 3.1 70B locally for document extraction. They bought two A100s. Spent 3 weeks optimizing inference. Still got 3-second latency on single pages. The API version would have cost them $400/month and returned in 400ms.
So the question isn't "which is better?" The question is "what trade-off can your business actually survive?"
What Open Weights Actually Gives You
Let me be precise about what "open weights" means. You get the trained parameters. The neural network weights. Sometimes the architecture. Rarely the training data. Never the training pipeline.
That's still enormously valuable.
The Real Control is Data
I can't count how many times I've seen a team build a beautiful RAG system on top of a closed API, only to discover their documents contain PCI data. Or HIPAA data. Or just proprietary information that your legal team (rightfully) doesn't want sent to an API endpoint in Virginia.
With open weights, you control the entire stack. The model runs on your hardware. Data never leaves. That's not just compliance theater — it's practical.
We tested this at SIVARO last year. A healthcare client needed to process 50,000 clinical notes daily for a diagnostic assistant. Closed API options: impossible (HIPAA). Open weights with vLLM inference: deployed in 2 weeks, running on their own GPU cluster behind their own firewall.
The trade-off? They spent $180,000 on hardware. But their legal risk went to zero.
The Knowledge Gap You Can't Ignore
Open weights models are about 6-18 months behind the frontier. That's not opinion — that's physics. Training a 400B parameter model costs $50M+ in compute alone. Companies with that kind of capital train it, keep the best weights for themselves, and release a weaker variant.
Llama 3.1 is good. Llama 4 (supposedly coming late 2026) will be better. But neither will match GPT-5 in reasoning ability, because nobody outside of OpenAI and Google has the data center to train at that scale.
I've seen teams try to compensate with fine-tuning. It helps. But you're not going to add chain-of-thought reasoning to Mistral 7B that matches what GPT-4o does natively. Physics doesn't care about your fine-tuning budget.
The Closed Source Advantage (And Its Rot)
Closed models win on three fronts: quality, convenience, and pace of improvement.
GPT-4o is genuinely smarter than any open model I've tested. Claude 3.5 Sonnet writes better code. Gemini 1.5 Pro handles longer contexts. These aren't marginal differences — they're obvious in production.
And the APIs just work. You send a request. You get a response. No GPU provisioning. No memory optimization. No CUDA out of memory errors at 2 AM.
But here's the rot: you're renting intelligence. And the landlord can change the rules.
Google changed Gemini's safety filters in February 2026. Suddenly, medical summarization pipelines that worked for 8 months started returning "I cannot answer that question." No warning. No changelog. Just... broke.
Anthropic deprecated their original text embeddings in favor of the new "v2" model. Any vector database built on the old embeddings? Invalid. Re-embed everything.
The Model Context Protocol (Model Context Protocol) tries to solve the integration problem — creating a standard way for LLMs to connect to tools and data sources. It's promising. Anthropic open-sourced it, and it's gaining adoption. But it doesn't solve the vendor lock-in problem. Your model still changes when they change it.
How to Train LLM Models Locally (The Practical Way)
Let me answer the question how to train llm models locally? directly. Because everyone makes it too complicated.
You're not going to train a foundation model from scratch. That's insane. You're going to fine-tune an existing open weights model.
Here's the stack we use at SIVARO for local training:
Step 1: Pick Your Base
Don't start with Llama 3.1 405B. You can't train that locally unless you have a data center. Start with Llama 3.1 8B or Mistral 7B. They fit on a single GPU.
bash
# Get the model
pip install transformers torch accelerate bitsandbytes
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "mistralai/Mistral-7B-v0.3"
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_4bit=True, # This is critical
device_map="auto",
torch_dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
Step 2: Prepare Your Data
Most people screw this up. They take their raw documents and try to dump them into the model. That doesn't work.
You need to format your data as conversations or instructions. Here's the format that consistently works for us:
json
{
"messages": [
{"role": "system", "content": "You are a document extraction assistant. Extract structured data from unstructured text."},
{"role": "user", "content": "Customer name: John Smith. Order #: 12345. Amount: $299.99. Date: 2026-06-15."},
{"role": "assistant", "content": "{"name": "John Smith", "order_id": "12345", "amount": 299.99, "date": "2026-06-15"}"}
]
}
Step 3: Use QLoRA (Not Full Fine-Tuning)
Full fine-tuning costs too much. QLoRA (Quantized Low-Rank Adaptation) is the answer. We've trained hundreds of models this way.
python
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(
r=16, # Rank
lora_alpha=32,
target_modules=["q_proj", "v_proj", "k_proj", "o_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
Training 10,000 examples on Mistral 7B with QLoRA takes about 4 hours on an A100. Cost: about $20 in cloud compute. That's cheaper than sending 10,000 API calls.
Step 4: Evaluate Before You Deploy
Don't test on your training data. We keep 10% of samples aside. We also test on real production edge cases. Because the model will memorize your training data. It won't generalize to the weird stuff your users actually send.
When Open Weights Beats Closed (And Vice Versa)
I'm going to be direct about this. No "it depends" hand-waving.
Use Open Weights When:
- You process PII, PHI, or financial data
- You need consistent latency (API models get slower as they scale)
- Your usage is predictable and high-volume (10M+ tokens/month)
- You need a specific behavior that requires fine-tuning
- You're building a product where margin matters (SaaS on SaaS gets squeezed)
Use Closed APIs When:
- You're prototyping (speed of iteration beats everything)
- Your data doesn't have compliance restrictions
- You need frontier-level reasoning (math, code generation)
- Your usage is spiky (GPUs sitting idle cost money)
- You're a small team without ML infrastructure
The Model Context Protocol Changes Everything (And Nothing)

You've probably heard about the Model Context Protocol (MCP). It's a standard for connecting LLMs to external tools and data sources. Think of it as USB-C for AI: a universal connector that lets models talk to databases, APIs, file systems, and other services.
Anthropic introduced it in late 2024 (Introducing the Model Context Protocol), and it's been gaining traction. Google Cloud has documentation on it (What is Model Context Protocol (MCP)? A guide), Databricks wrote about it (What is the Model Context Protocol (MCP)?), and there's even academic analysis now (Help or Hurdle? Rethinking Model Context Protocol).
The idea is elegant. Instead of building custom integrations for every model and every data source, you use MCP as the middle layer. Your model connects to an MCP server. The server connects to your data.
python
# An MCP client in practice
import mcp
client = mcp.Client()
client.register_tool("search_docs",
description="Search internal documentation",
parameters={"query": str, "limit": int}
)
response = await client.call_tool("search_docs",
query="How do we handle refunds?",
limit=5
)
This matters for the open weights vs closed source LLMs debate because MCP works with both. You can use it with GPT-4o or with Llama 3.1. It's model-agnostic.
But here's the catch: MCP doesn't solve the fundamental tension. If you're using a closed model, MCP just makes it easier to give your data to someone else's model. The privacy and lock-in problems remain.
And MCP has real issues. The critical paper from arXiv notes that MCP introduces latency overhead, security concerns around tool access, and complexity in deployment (Why the Model Context Protocol Does Not Work). We've seen teams spend a month implementing MCP only to discover their latency went from 500ms to 3 seconds.
At SIVARO, we use MCP for development environments. It's great for prototyping. But we don't rely on it for production data pipelines. The overhead isn't worth it when you're processing 200K events per second.
The Future Is Hybrid (And That's Hard)
Here's my prediction for late 2026 and beyond: most serious AI systems will use multiple models.
You'll have a small, fast open model for classification and routing. A medium open model for extraction and summarization. And a closed frontier model for the hard reasoning tasks. Connected by something like MCP or a custom middleware layer.
This hybrid approach is what we're building at SIVARO. Our production systems use Mistral 7B for intent detection (runs in 50ms, cost is basically zero), Llama 3.1 70B for document extraction (fine-tuned on client data, runs on their hardware), and GPT-4o for the 2% of cases where reasoning is genuinely hard.
The challenge is orchestration. Managing multiple models, routing between them, handling failures, monitoring quality. That's not a model problem — it's an infrastructure problem.
Real Numbers From Real Deployments
Let me give you actual costs from Q1 2026, anonymized but real:
Client A (Fintech, transaction monitoring)
- Closed API (GPT-4o): $23,400/month
- Switched to Llama 3.1 70B (self-hosted): $4,200/month
- Hardware cost: $120,000 one-time (4xA100)
- Break-even: 7 months
- Accuracy: 94.2% (vs 95.1% on GPT-4o)
Client B (Healthcare, clinical notes)
- Closed API: Not viable (HIPAA)
- Open weights (Mistral 7B fine-tuned): $0.003 per note
- GPU cost: $1,800/month
- Accuracy: 89.7% (good enough for triage)
Client C (E-commerce, customer support)
- Closed API: $8,400/month
- Open weights (Mixtral 8x7B): $1,100/month
- Latency: 2.1s (vs 1.4s on API)
- Resolution rate: Equivalent
The pattern is clear: if you have predictable, high-volume workloads, open weights wins on cost. If you need peak performance or have variable load, closed APIs win on convenience.
Practical Decision Framework
Stop debating philosophy. Use this checklist:
-
Does my data have compliance requirements? → Open weights. Full stop.
-
Am I building a prototype or an MVP? → Closed API. Ship fast, optimize later.
-
Do I need frontier reasoning? → Closed API for the hard parts, open for the rest.
-
Is my workload > 5M tokens/month? → Do the math. Usually open wins.
-
Do I have ML infrastructure experience? → Yes? Open. No? Closed until you hire.
-
Can I handle vendor lock-in? → Yes? Closed. No? Open.
-
Is latency more important than cost? → Very latency sensitive? Self-hosted open. Moderate? Closed.
FAQ: Open Weights vs Closed Source LLMs
Q: What's the difference between open weights and open source for LLMs?
Open weights means you get the trained model parameters but not the training data, code, or pipeline. True open source includes the training infrastructure. Most "open source" LLMs are actually open weights. The distinction matters because you can't reproduce or modify the training process with just weights.
Q: Can I run open weights models on my laptop?
Smaller models (7B parameters or less) run on laptops with quantization. 4-bit quantization reduces memory requirements by ~75%. But for anything useful in production, you need at least a single GPU. We recommend starting with cloud GPUs rather than buying hardware until you know what you need.
Q: How to train LLM models locally without a GPU cluster?
Use QLoRA on a single GPU. Services like Lambda Labs, Vast.ai, and RunPod offer A100s for $1-2/hour. For small datasets (<10K examples), training takes hours, not days. Use Hugging Face's Transformers library with PEFT (Parameter-Efficient Fine-Tuning). Don't try full fine-tuning — it's 10x more expensive for marginal gain.
Q: Are closed source LLMs always better quality?
For reasoning tasks, yes. For specialized domains, no. Fine-tuned open models regularly beat GPT-4o on specific tasks like document classification, named entity recognition, and structured extraction. The frontier gap exists mainly for open-ended reasoning, creative tasks, and complex code generation.
Q: How does MCP affect the open vs closed decision?
The Model Context Protocol makes both options easier to deploy by standardizing integrations. But it doesn't change the fundamental trade-offs. Closed models still send your data externally. Open models still require infrastructure. MCP is a tool, not a solution to the core debate.
Q: What's the best open weights model right now (June 2026)?
For general use: Llama 3.1 70B or Mistral Large. For code: DeepSeek-Coder V3. For niche tasks: fine-tune Mistral 7B or Llama 3.1 8B. The "best" depends entirely on your use case. Test 3-4 models on your actual data before deciding.
Q: Will closed models eventually win because of scale?
I don't think so. The cost of frontier training is increasing, not decreasing. Meta, Mistral, and the open ecosystem are investing heavily in efficient architectures and better fine-tuning. The gap will narrow, even if it never closes completely. And for most business applications, "good enough" with zero data risk beats "slightly better" with compliance headaches.
Q: What's the biggest mistake teams make?
Over-estimating their need for frontier capability. I've seen teams spend $50K/month on GPT-4o for text classification that a fine-tuned 7B model could do for $500. The frontier models are incredible. But 90% of production AI tasks don't need them.
The Bottom Line
I started this article with a story about a $47,000 AWS bill. That company is now a client. We moved them to a hybrid architecture: Mistral for routing, fine-tuned Llama for the core pipeline, and GPT-4o only for the hardest 5% of queries. Their monthly AI spend dropped to $5,200. Accuracy improved (fine-tuning on their specific data beat the general model).
The open weights vs closed source LLMs debate isn't settled. It shouldn't be. Both approaches have legitimate uses. The question is whether you're honest about your constraints.
Data compliance? Go open. Prototyping? Go closed. Need both? Build hybrid. The models are tools, not religions.
And if someone tells you there's one right answer, they're selling you something. Probably a GPU cluster.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.