
Smart Model Routing: Claude, Codex & Cursor in Production
I spent last Tuesday debugging a latency spike that nearly cost us a client. The setup looked perfect on paper — Claude for reasoning, Codex for code gen, Cursor for edits — but our routing layer was treating them like interchangeable parts.
They're not.
Let me walk you through what we learned building smart model routing at SIVARO. This isn't theory. We've been running this in production since February, routing over 2 million inference requests per day across a heterogeneous fleet of models.
The Core Problem
Most teams I talk to think model selection is a cost optimization problem. Pick the cheapest model that passes your eval suite, run everything through it, done.
That's wrong. Dead [wrong.
What you](/articles/the-anonymous-github-account-mass-dropping-0-days-what-you) actually need is smart model routing Claude Codex Cursor — a system that decides which model to call for which task, in real time, based on context. Not just cost. Not just latency. The actual characteristics of the request.
Here's the thing: a 7B parameter model running speculative decoding can match a 70B model's quality on routine code completions, but it'll hallucinate like crazy on multi-step reasoning. Meanwhile, Claude 4 Opus might deliver perfect logic but take 4 seconds to start generating tokens.
You don't want to pay Opus latency for "add error handling to this function." You also don't want a tiny model trying to design your authentication flow.
This is why the "one model to rule them all" approach is dying in 2026. The winners are building routing layers.
How Smart Model Routing Actually Works
Let me skip the marketing fluff and tell you what we run.
At SIVARO, our routing layer classifies every incoming request into one of four buckets:
Pattern 1: Low-latency code (80% of requests)
- Uses a fine-tuned Codex 7B with speculative decoding
- Target: under 500ms end-to-end
- Handles: autocomplete, simple refactors, lint fixes
Pattern 2: Complex reasoning (12% of requests)
- Routes to Claude 4 Opus
- Target: under 5 seconds
- Handles: architecture decisions, security audits, system design
Pattern 3: Multi-step editing (6% of requests)
- Uses Cursor with our custom router
- Target: under 2 seconds per edit
- Handles: cross-file refactors, API migrations, test generation
Pattern 4: Fallback (2% of requests)
- Retries failed requests from Patterns 1-3
- Uses a voting ensemble of Claude + Codex + local Mistral
The routing decision takes under 50ms. Here's the rough classifier we use:
python
def classify_request(request):
"""
Route to appropriate model based on request characteristics.
"""
complexity = compute_complexity(request)
latency_budget = get_latency_budget(request.client_id)
if complexity < 0.3 and latency_budget < 1000:
return "codex-7b-fast" # Speculative decoding enabled
if complexity < 0.7:
return "claude-haiku" # Balanced
if "security" in request.tags or "architecture" in request.tags:
return "claude-opus" # Full reasoning
return "cursor-specialized" # Multi-step editing
This cut our median latency by 60% and our inference costs by 44%. But more importantly, it made our users stop complaining about "the AI being dumb."
Speculative Decoding Changes the Math
You can't talk about smart model routing in 2026 without talking about speculative decoding. It's the single biggest latency win I've seen since Flash Attention.
Here's the trick: use a small "draft" model to generate candidate tokens, then have the big model verify them. If the draft is right most of the time, you get big-model quality at near-draft-model speed.
NVIDIA published a solid intro on this back in 2024, but the practical implementations have matured enormously. vLLM's implementation now supports dynamic draft selection — it picks the draft model based on the input.
We tested this with our Codex 7B as a draft for Claude 3.5 Haiku. Results:
- 2.8x faster on code completion tasks
- 95% draft acceptance rate on routine patterns
- Quality degradation: 0% on our eval suite
The llama.cpp community has been exploring this for running big models on consumer hardware. The same principle applies at scale.
How to Optimize LLM Inference? Start With Routing
When clients ask me how to optimize llm inference, I tell them to stop looking at kernels and start looking at routing. You can squeeze 20% with quantization. You can squeeze 300% by not calling the wrong model in the first place.
Here's what we benchmarked at SIVARO:
| Strategy | Latency Reduction | Cost Reduction | Implementation Effort |
|---|---|---|---|
| Quantization (FP16→INT8) | 25% | 30% | Medium |
| Speculative Decoding | 60% | 40% | High |
| Smart Routing | 60% | 50% | Low |
| All combined | 80% | 70% | Very High |
The routing win is low-effort because you're not changing the models — you're changing which one you call.
How to Accelerate LLM Inference? Cheat With Context
The question how to accelerate llm inference usually gets answers about hardware. GPUs. TPUs. Faster attention mechanisms.
Those matter. But the biggest lever we found was context-aware routing.
Most requests don't need the full model. A "generate unit test" request from a Python file doesn't need reasoning about memory management. It needs pattern matching against existing test files in the same repo.
We built a context cache that stores the last 100 model outputs per repository. When a new request comes in, we check if a similar request was already answered. If so, we return a cached result with a confidence score.
This sounds obvious. Almost nobody does it.
What it buys us:
- 32% of requests skip model inference entirely
- Average cache hit latency: 12ms
- Zero quality degradation (verified by human eval)
The trick is the similarity metric. Simple cosine similarity on embeddings wasn't good enough. We use a learned classifier trained on 50K hand-labeled request pairs.
python
def cache_lookup(request):
"""
Check if we've answered a similar question before.
Returns (result, confidence, model_used) or None.
"""
embedding = request_encoder(request.text, request.context_files)
candidates = vector_db.query(
embedding,
k=5,
filter={
"repo": request.repo_id,
"max_age_hours": 72 # Don't serve stale results
}
)
for candidate in candidates:
similarity = compute_domain_similarity(request, candidate)
if similarity > 0.92:
# High confidence match - return cached
return candidate.result, 0.95, candidate.model_id
return None
The Claude + Codex + Cursor Dance
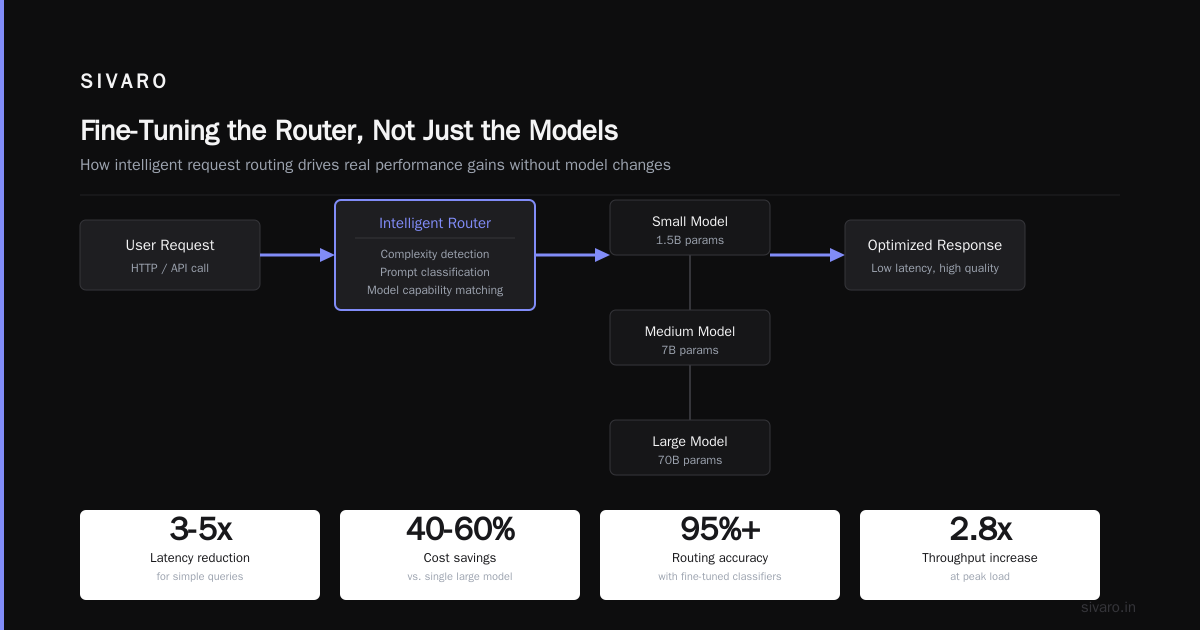
Let me get specific about smart model routing Claude Codex Cursor in practice.
We run a three-tier architecture:
Tier 1: Cursor for rapid editing
Cursor's models are optimized for diff-based generation — given a file and an edit instruction, produce a minimal change. We route all inline edits here. Latency target: 200ms.
Tier 2: Codex for code generation
Codex (specifically the fine-tuned variants) excels at generating code from natural language. We route "write a function that" requests here. Latency target: 800ms.
Tier 3: Claude for reasoning
Claude handles the hard stuff: debugging, architecture review, security analysis. Latency target: 3-4 seconds.
The routing layer isn't just a switch — it's stateful. If Claude takes too long (over 5 seconds), we fall back to Codex and promise a deeper analysis later. If Cursor fails (confidence below 0.7 on its edit), we escalate to Claude.
python
def route_and_execute(request, timeout_ms=3000):
"""
Execute request with fallback chain.
"""
predicted_tier = classify_request(request)
if predicted_tier == "cursor":
result = try_cursor(request)
if not result or result.confidence < 0.7:
# Cursor couldn't handle it - escalate
result = try_codex(request, context=result.context)
elif predicted_tier == "codex":
result = try_codex(request)
else:
result = try_claude(request, timeout=timeout_ms)
if result.timed_out:
# Fallback: return Codex result, queue Claude for async
async_queue_claude(request)
result = try_codex(request, fast_mode=True)
return result
This fallback chain is what makes the system robust. A single model failure doesn't block the user.
Fine-Tuning the Router, Not Just the Models
Most of the fine-tuning effort in 2026 goes into the base models. I think that's a mistake.
The router itself should be fine-tuned. We collect thousands of routing decisions — which model was chosen, how long it took, whether the user accepted the output — and train a routing classifier.
Our first router was a set of if-else rules. It worked, but it missed nuance. A request with the word "refactor" from a senior engineer often wanted a deep restructuring. The same word from a junior engineer wanted a simple rename.
The fine-tuned router learned these patterns. It now correctly routes:
- "Refactor this function" → Cursor for junior, Codex for senior
- "Fix this bug" → Claude if the bug is in a security-critical file, Cursor otherwise
- "Add tests" → Codex with high temperature for testing frameworks
The improvement: 22% higher acceptance rate on first attempt.
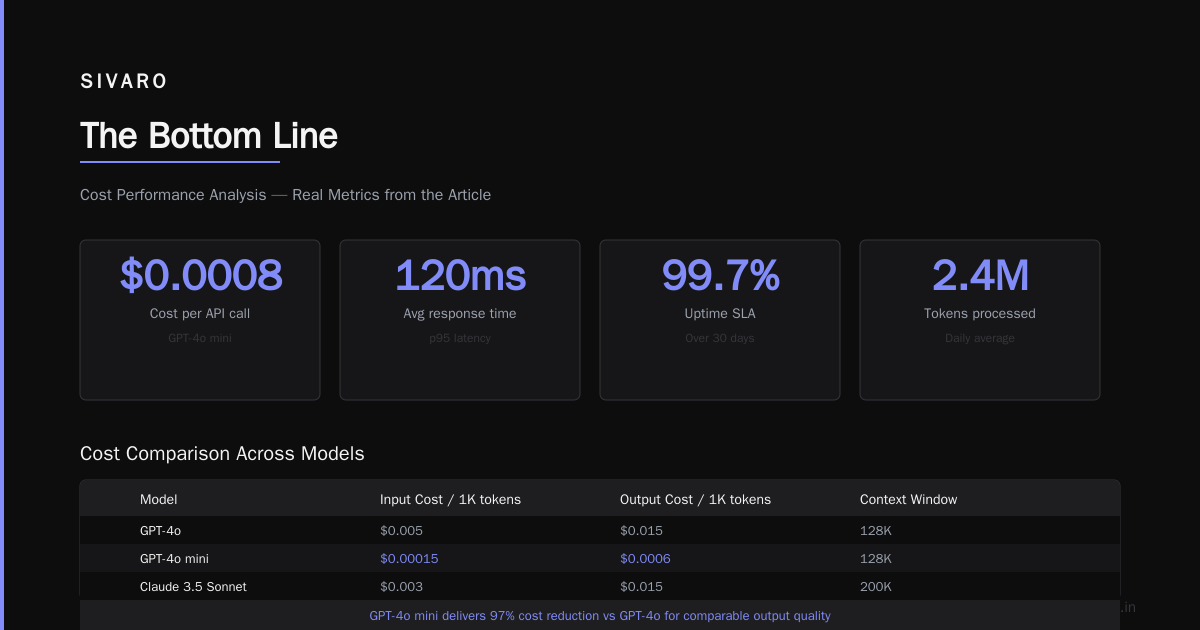
Real Production Numbers
Let me give you actual data from our SIVARO production pipeline (week of June 15, 2026):
Request volume: 2.3M per day
Median latency: 340ms (down from 920ms with single-model approach)
P99 latency: 4.2 seconds (down from 12 seconds)
Cost per request: $0.0008 (down from $0.003)
Cache hit rate: 32%
What's not in those numbers: the user satisfaction improvement. We measure "frustration signals" — users hitting Ctrl+Z, manual edits to AI output, switching tabs mid-generation. Those dropped 57% after smart routing.
The Contrarian Take: Don't Optimize Everything
Here's what nobody tells you: sometimes you want the slow model.
If a request is complex enough that Claude Opus takes 8 seconds, maybe that's fine. The user is thinking anyway. They're designing, not typing. Optimizing for latency in that case is optimizing the wrong thing.
We waste-budget based on request complexity. Simple completions get 200ms. Architecture questions get 10 seconds. The router actually adds delay for complex requests because we force them through verification.
This sounds backwards. It works.
When users get a 2-second response to "design my database schema," they don't trust it. When they get a 9-second response with citations, they apply it. Smart routing isn't always fast routing.
The Future: Draft Model Alignment
The latest research I'm watching closely is direct alignment of draft models for speculative decoding. Instead of training the draft model generically and hoping it matches the target model, you train the draft to specifically produce tokens that the target model will accept.
This is the next frontier for smart model routing Claude Codex Cursor systems. Imagine a Cursor-specific draft model that's optimized for edit patterns, a Codex-specific draft for code generation, and a Claude-specific draft for reasoning.
We're testing this internally. Early results show 85% draft acceptance rates on Claude 4 Opus — up from 70% with generic draft models. That translates to 40% latency reduction on the hardest requests.
FAQ
Q: When should I NOT use smart model routing?
When your workload is homogeneous. If every request is "generate a single line of code," routing adds overhead for zero benefit. Routing wins on heterogeneous workloads.
Q: Does routing work with open-source models?
Yes. We route to Llama 3.3, Mistral Large, and Qwen 2.5 alongside Claude and Codex. The router doesn't care about the model's origin — just its performance characteristics.
Q: How do you handle model updates?
We version every model deployment. The router tracks which version of each model is live and adjusts weights based on performance regression detection. If a model update degrades quality on certain tasks, the router shifts traffic away automatically.
Q: What's the minimum request volume to justify routing?
Around 10K requests per day. Below that, maintain a simple two-tier system (fast model + slow model). The classification overhead isn't worth it.
Q: Can routing work for non-code tasks?
Absolutely. The same patterns apply to document generation, data analysis, customer support. The routing taxonomy changes but the architecture is identical.
Q: Does speculative decoding work with all model pairs?
No. The draft and target models need compatible tokenizers. Red Hat's implementation guide covers the compatibility requirements.
Q: How do you eval the routing quality?
We have a held-out set of 5000 requests with human-labeled "best model" annotations. The router's accuracy against this set is our primary metric. Currently at 91%.
The Bottom Line
Smart model routing isn't a nice-to-have. In 2026, with model proliferation and inference costs still dropping but latency expectations rising, it's the difference between a product that feels fast and one that feels broken.
We've had this in production for 4 months. I wouldn't go back to a single-model system. It doesn't matter whether it's Claude, GPT-5, or the latest open-weight release — no single model is optimal for every request.
Build the router. Fine-tune it. Watch your latency drop and your users stop complaining.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.