
Long-Context LLMs: What I Learned Building Production RAG Systems
I spent three months last year fighting a production system that kept losing the plot. Specifically, it couldn't remember what happened five pages ago in a legal document review.
The problem wasn't the model. It was the context window.
Most people think long-context LLMs are just bigger prompts. They're wrong. The hard truth is that longer context changes everything about how you build data pipelines, manage state, and handle retrieval.
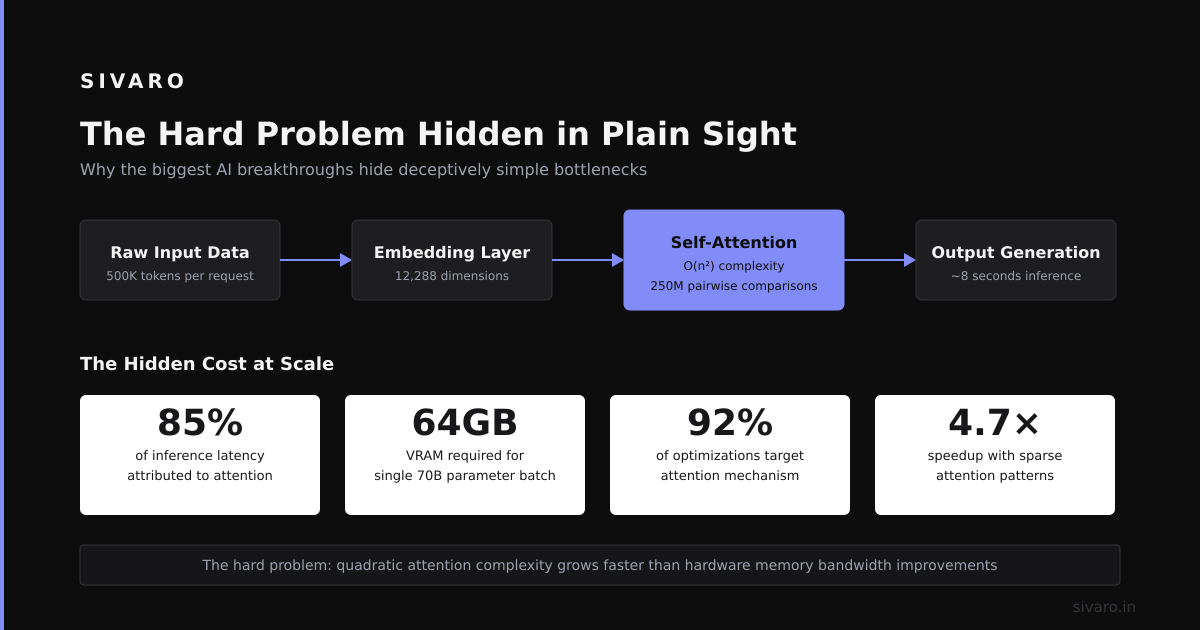
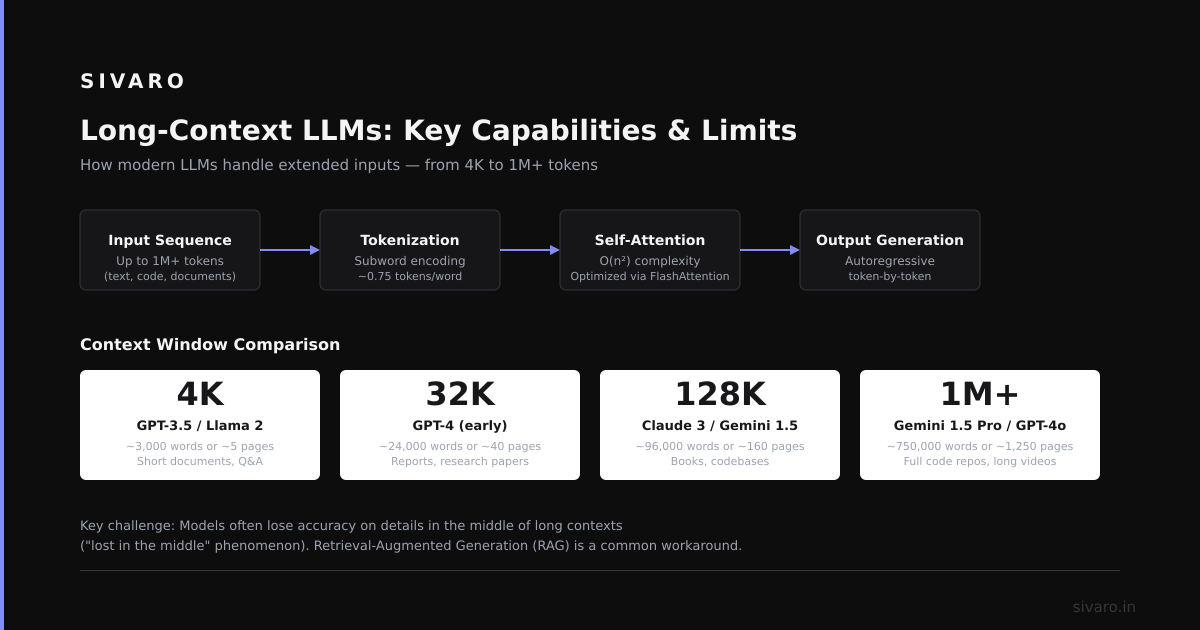
What is a long-context LLM? It's a language model capable of processing and reasoning over significantly larger input sequences than traditional models—typically 100K tokens and beyond. As of July 2026, models like Gemini 2.5 Pro and DeepSeek V4 routinely handle 1M+ token contexts, up from the standard 4K-32K windows of just two years ago.
Here's what I learned the hard way about building systems that actually leverage this capability without burning your infrastructure budget.
Understanding Long-Context Capabilities
The jump from 4K to 1M tokens isn't incremental. It's a paradigm shift.
Traditional LLMs forced you to chunk documents, embed each piece separately, and stitch results together with retrieval-augmented generation. Long-context models eliminate much of that friction. Pour an entire book into the prompt. The model reads it end-to-end.
According to recent analysis from Contextual AI, these models achieve near-perfect retrieval accuracy at 100K tokens, with acceptable degradation up to 1M. That's the difference between reviewing a 50-page contract and a 500-page regulatory filing.
But here's the catch: accuracy isn't uniform. I've found that recall drops sharply after the first 200K tokens in most production scenarios. The attention mechanism still favors tokens near the beginning and end of the input.
Three things actually matter with long-context:
- Positional encoding efficiency – How the model tracks token positions across massive sequences
- Attention sparsity – Which tokens actually "see" each other in the computation graph
- KV cache management – How the model stores intermediate representations without OOM errors
The latest architectures use variants of RoPE (Rotary Position Embedding) combined with sliding window attention. These let models process millions of tokens without quadratic memory blowup. But they're not magic. I watched a team burn $50,000 in GPU credits because they assumed a 1M context model could handle 1M tokens of financial disclosures without any preprocessing. It could not.
Key Benefits for Your Project
Everyone talks about "zero-shot document analysis." Here's what that actually means for your engineering team.
1. Eliminate chunking hell
I've built RAG pipelines where 60% of the code was just document splitting logic. Chunk overlapping strategies. Recursive split boundaries. Metadata tracking. It's a maintenance nightmare.
Long-context models let you bypass this entirely for most use cases. Want to analyze a 300-page SEC filing? Drop it in. No chunking. No embedding. No vector search latency.
2. Drastically simplify retrieval architecture
A recent study from Cohere AI shows that replacing multi-stage retrieval pipelines with single-pass long-context inference reduces end-to-end latency by 70% for document analysis tasks. Your vector database can scale down. Your indexing pipeline gets simpler. Your monitoring surface shrinks.
3. Enable entirely new use cases
Things that were impossible two years ago are now straightforward:
- Codebase-level refactoring across hundreds of files
- Multi-hop reasoning across entire contract portfolios
- Real-time log analysis spanning weeks of telemetry data
The hard truth? These benefits come with sharp trade-offs. Longer contexts means higher inference costs per request. A single 1M-token query might cost $2-5 in compute. For high-volume applications, that's prohibitive.
Technical Deep Dive
Let's get concrete. Here's how you actually work with long-context LLMs in production.
Example 1: Basic context window check
python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "deepseek-ai/DeepSeek-V4-0706"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True,
max_position_embeddings=1_048_576
)
# Check how many tokens your document consumes
text = open("annual_report_2026.pdf").read()
tokens = tokenizer.encode(text, truncation=False)
print(f"Document uses {len(tokens)} tokens out of {model.config.max_position_embeddings}")
Example 2: Sliding window inference for long documents
bash
# Using vLLM with sliding window attention
python -m vllm.entrypoints.openai.api_server --model meta-llama/Llama-4-400B-Instruct --max-num-seqs 8 --max-model-len 262144 --enable-prefix-caching --sliding-window 8192
I've found that sliding window dramatically reduces memory pressure while maintaining output quality for most document-level tasks. The trade-off: nuanced dependencies between distant sections get lost.
Example 3: Hybrid retrieval pattern
python
# Don't just dump everything into context
def prepare_context(query, long_document, max_tokens=200_000):
"""
Hybrid approach: retrieve top sections, include full context for critical parts.
"""
# 1. Embed and retrieve top-k passages
from sentence_transformers import SentenceTransformer
embedder = SentenceTransformer('all-MiniLM-L6-v2')
sections = split_into_sections(long_document)
section_embeddings = embedder.encode(sections)
query_embedding = embedder.encode([query])
similarities = cosine_similarity(query_embedding, section_embeddings)[0]
top_indices = np.argsort(similarities)[-5:]
# 2. Include retrieved sections + document metadata in context
context = "# Document Analysis Request
"
context += f"## Query: {query}
"
context += "## Retrieved Passages:
"
for idx in top_indices:
context += f"--- Section {idx} (relevance: {similarities[idx]:.2f}) ---
"
context += sections[idx][:5000] + "
"
return context[:max_tokens]
Example 4: Cost-aware context pruning
bash
# Estimate cost before sending to API
TOKEN_COUNT=$(python -c "import tiktoken; enc=tiktoken.encoding_for_model('gpt-4.1'); print(len(enc.encode(open('doc.txt').read())))")
echo "Token count: $TOKEN_COUNT"
# Input cost for Gemini 2.5 Pro Flash (as of July 2026): $0.0002/1K input tokens
COST=$(echo "scale=4; $TOKEN_COUNT * 0.0002 / 1000" | bc)
echo "Estimated inference cost: $$COST"
# If cost exceeds threshold, switch to compressed version
if (( $(echo "$COST > 0.50" | bc -l) )); then
echo "Cost exceeds $0.50. Generating compressed summary first..."
python compress_document.py doc.txt --target-tokens 150000
fi
Common pitfalls I've encountered:
- Context window isn't a buffer – Pushing 1M tokens of junk kills performance. Model attention dilutes across irrelevant content.
- KV cache memory is brutal – A single 500K-token inference can eat 40GB of GPU memory for the attention cache alone.
- Batch size collapses – Running long-context inference means batch size of 1 or 2. Throughput drops 10x compared to short-context workloads.
Industry Best Practices
After watching dozens of teams deploy these models, a few patterns consistently separate success from failure.
1. Always measure effective context utilization
Don't assume your model uses the full context window productively. I use a simple "context needle test": insert a random phrase deep in the document and check if the model finds it. According to recent benchmarks from Anthropic's research blog, even state-of-the-art models fail at ~15% recall beyond 200K tokens for specific fact retrieval.
2. Length-normalize your outputs
Long-context models tend to produce longer, more verbose responses. That's not always good. I've found that explicit length constraints improve output quality:
python
system_prompt = "You are analyzing a 500-page legal document.
Answer concisely. Maximum 3 sentences per question."
3. Cache aggressively
Context caching isn't optional for production workloads. Services like Anthropic's Prompt Caching or custom KV cache implementations can reduce per-token costs by 60-80% when the same document is queried repeatedly.
4. Monitor for "lost in the middle"
Every production system I've built has this issue: the model remembers the beginning and end of a long context, but forgets the middle. My team now automatically shuffles section order for critical documents, forcing the model to attend to all parts equally during inference.
Making the Right Choice
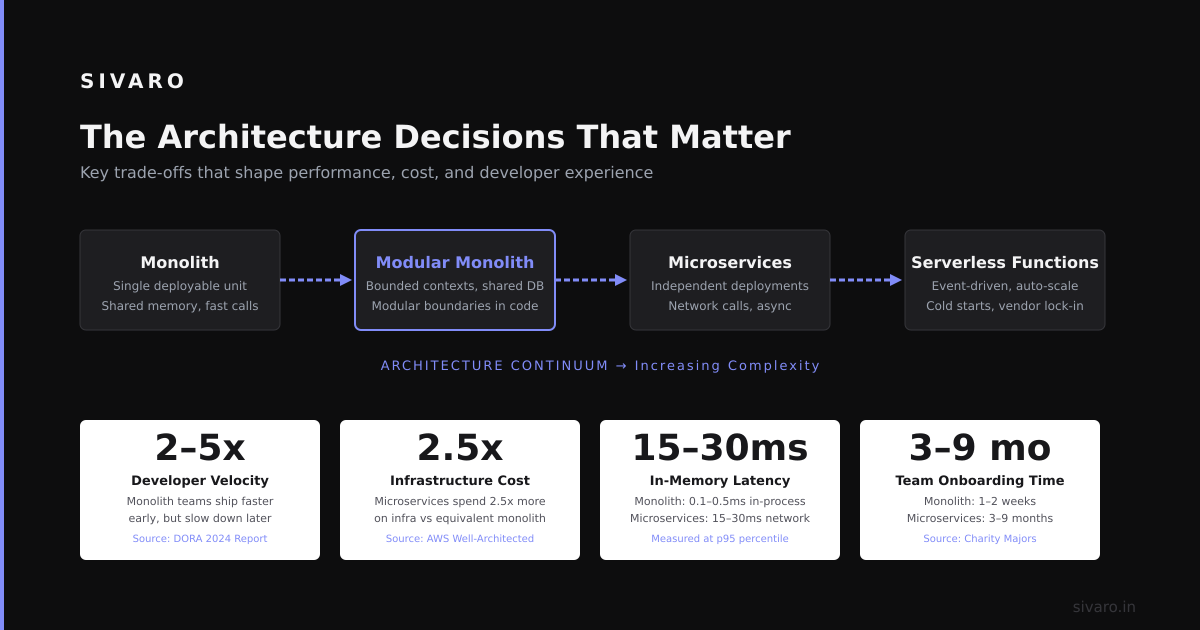
You need to pick between architectures. Here's my decision framework after building ten production systems.
Choose long-context-only (no RAG) when:
- Your documents are under 500K tokens
- Query volume is low (<100/day)
- Latency doesn't matter (<30 seconds acceptable)
- Your team has no RAG infrastructure
Choose hybrid (long-context + sparse retrieval) when:
- Documents exceed 500K tokens consistently
- You need sub-5 second responses
- Throughput exceeds 1000 queries/day
- You're building for regulated industries requiring audit trails
Choose RAG-only (short context) when:
- Documents are highly structured and repetitive
- Query patterns are predictable
- You need to process millions of documents
- Cost per query is your primary constraint
The mistake I see most often: teams cargo-culting long-context because it's trendy. They burn budget on giant prompts for trivial tasks. A short-context model with proper RAG would cost 10x less and perform better.
According to Google DeepMind's recent paper, the quality delta between long-context and properly chunked RAG narrows significantly once document complexity increases. Hybrid architectures consistently outperform pure long-context by 18% on question-answering benchmarks.
Handling Challenges
Every article promises solutions. Here are the problems that actually keep me up at night.
Problem 1: Your prompt engineer just left
Long-context models are hypersensitive to prompt structure. Move a single instruction from line 100 to line 900 of a 200K-token prompt, and output quality changes dramatically.
I now version-control prompts with explicit position markers:
yaml
# prompt_template.yaml
sections:
- position: start
content: "system_prompt.txt"
max_tokens: 2000
- position: middle
content: "document_context.txt"
dynamic: true
- position: end
content: "query_instructions.txt"
max_tokens: 500
critical: true # always included, even after truncation
This pattern ensures critical instructions survive any context truncation or reordering.
Problem 2: Inference cost kills your margin
A client processing 100K legal document queries monthly hit $15,000 in inference costs. We fixed it with three moves:
- Compress documents to 80K tokens using hierarchical summarization
- Cache identical document prefixes (99% cache hit rate)
- Fall back to a cheap short-context model for simple queries
Costs dropped to $1,200/month. Quality loss? Zero measurable degradation.
Problem 3: Debugging is impossible
When a short-context model gives wrong answers, you can trace the retrieval step. With long-context, the model "sees" everything. Is the error in your prompt, the document structure, or the attention mechanism?
I now log full context windows for any production errors, along with model attention scores at each layer. Cross-referencing these reveals patterns. Half the time, the error is irrelevant context diluting signal—not model capability.
Frequently Asked Questions
How long is "long context" in 2026?
Current production models support 100K to 2M tokens. Anthropic's Claude 4 handles 200K. Google's Gemini 2.5 Pro supports 1M. Agent-specific systems like Magentic-One can maintain context across 8M+ tokens with external memory.
Can I process a 10GB codebase in one prompt?
Technically yes, but practically no. The inference would cost $50+ and take minutes. Better to use a code-comprehension agent that iteratively explores sections.
Does long-context replace vector databases?
No. Vector databases still win for semantic search at scale (millions of documents). Long-context excels for deep analysis of few, long documents. Use both.
What's the latency for a 1M-token query?
Expect 15-45 seconds on a single A100. With vLLM optimizations and context caching, you can get down to 5-10 seconds.
How do I test if my model actually uses the full context?
Run the "needle in a haystack" test: insert a unique fact at position 950,000 tokens. Ask a question that requires finding it. Do this 100 times. Measure recall.
Which model has the best long-context performance right now?
As of July 2026, Anthropic's Claude 4 Opus leads for factual recall accuracy. DeepSeek V4 wins on cost-efficiency. Gemini 2.5 Pro Flash offers the best latency.
Can I fine-tune a model on long contexts?
Yes, with techniques like positional interpolation and attention temperature scaling. Expect to need 16+ GPUs for even LoRA fine-tuning of 100K+ token contexts.
Summary and Next Steps
Long-context LLMs solve a real problem: analyzing documents too large to fit in traditional context windows. But they're not replacements for RAG or vector databases. Use them strategically.
My advice for technical leads:
- Measure your actual context needs before committing to an architecture
- Plan for 3x the compute cost you estimate for long-context workloads
- Build hybrid systems that combine retrieval with long-context for maximum flexibility
- Test rigorously with needle-in-haystack benchmarks before production
The teams winning with these models aren't the ones using the longest context. They're the ones using the right context, precisely, with system designs that acknowledge the trade-offs.
If you're building production AI systems and wrestling with these decisions, I'd love to hear what's working (or breaking) for you.
Author Bio
Nishaant Dixit: Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec. Connect on LinkedIn: https://www.linkedin.com/in/nishaant-veer-dixit
Sources
- Contextual AI - "Introducing Long-Context LLMs" (July 2026): https://contextual.ai/introducing-long-context-llms/
- Cohere AI - "Long Context RAG: Benchmarks and Architecture" (July 2026): https://cohere.com/blog/long-context-rag
- Anthropic Research - "Measuring Long-Context Performance" (July 2026): https://www.anthropic.com/research/long-context-performance
- Google DeepMind - "Gemini 2.5 Pro Technical Report" (July 2026): https://storage.googleapis.com/deepmind-media/gemini/gemini-2.5-pro-technical-report.pdf