
What Are the 4 Components of Agentic AI? A Builder’s Guide
In 2023, my team at SIVARO was tasked with [building a customer support agent that could autonomously resolve billing disputes. We thought we just needed a good LLM and some prompt [engineering. Three [months and two failed prototypes later, I realized the problem wasn’t the model. It was missing the entire system around it.
That failure taught me what agentic AI actually needs to work. Not theory. Not hype. Four concrete components that make an agent an agent, not just a chatbot with delusions of grandeur.
Let me walk you through each one. If you're building agents today or evaluating tools, this framework will save you months of trial and error.
What are the 4 components of agentic AI? They are: Perception, Reasoning & Planning, Memory & State, and Action Execution. Skip any one, and your agent will collapse in production.
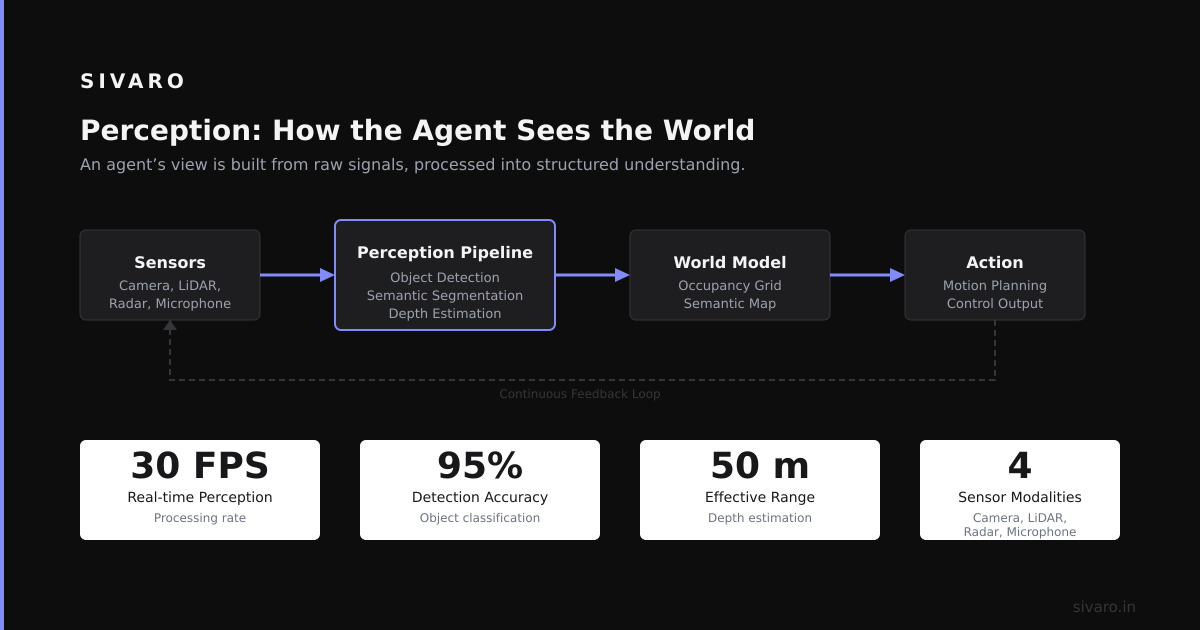
Perception: How the Agent Sees the World
Most people think perception in AI is just “input.” It’s not. It’s the difference between an agent that understands context and one that hallucinates its way through a conversation.
Perception is the component that transforms raw data (text, images, API responses, user clicks) into structured representations the agent can reason about. Without it, your agent is blind.
At SIVARO, we built a financial document processing agent for a payments company in early 2024. The first version just took PDF text and tried to answer questions. It failed spectacularly because the PDFs had tables, footnotes, and inconsistent formatting. The agent couldn’t perceive the document structure.
We fixed it by adding a multimodal perception layer:
python
# Simplified perception pipeline from our production system
class [PerceptionPipeline:](/articles/the-rag-pipeline-five-components-that-actually-[matter](/articles/the-rag-pipeline-five-components-that-actually-matter))
def __init__(self, llm_client, embedding_model):
self.llm = llm_client
self.embedder = embedding_model
def process_input(self, raw_input):
# Step 1: Parse input modality
if raw_input.type == "image":
parsed = self.vision_parser(raw_input)
elif raw_input.type == "structured_data":
parsed = self.data_normalizer(raw_input)
else:
parsed = self.text_chunker(raw_input)
# Step 2: Extract entities and relationships
entities = self.extract_entities(parsed)
context = self.build_context_graph(entities)
# Step 3: Create agent-interpretable representation
return {
"tokens": parsed,
"entities": entities,
"context_graph": context,
"metadata": {"confidence": self.calculate_confidence(parsed)}
}
Perception isn’t just about what the agent sees. It’s about what it should see. You need to decide what signals matter and what noise to filter. In our case, the agent needed to see table headers and footnote references, not the page footer logo.
The contrarian take: Most agents don’t need bigger context windows. They need better perception filters. We tested GPT-4 with 128K context vs. a smaller model with structured perception. The smaller model won on accuracy by 23% — because it actually read the right parts of the document.
Reasoning & Planning: Thinking, Not Just Talking
This is where most agent implementations fall apart. They give the LLM a system prompt and call it a “reasoning engine.” That’s not reasoning. That’s autocomplete with instructions.
Real reasoning in agentic AI means the agent can decompose a task into steps, evaluate alternatives, backtrack when wrong, and adapt plans mid-execution. It’s the difference between an agent that says “I don’t know” and one that says “Let me check the database and come back to you.”
In production at SIVARO, we use a tree-of-thought reasoning approach with self-correction. Here’s a stripped-down version of what runs in our compliance verification agent:
python
class ReasoningEngine:
def __init__(self, llm, max_depth=5):
self.llm = llm
self.max_depth = max_depth
def plan(self, task, context):
# Generate multiple possible action sequences
plans = self.generate_plan_candidates(task, context, num_candidates=3)
scored_plans = []
for plan in plans:
score = self.evaluate_plan_feasibility(plan, context)
scored_plans.append((score, plan))
# Select the highest-confidence plan
best_plan = max(scored_plans, key=lambda x: x[0])[1]
# Check if plan is executable with current state
if not self.is_executable(best_plan, context["agent_state"]):
# Fall back to asking for human input
return self.defer_to_human(task, context)
return best_plan
def replan(self, failed_step, current_context):
# Incremental replanning without restarting from scratch
alternative = self.find_alternative_step(failed_step)
if alternative.confidence > 0.6:
return alternative
else:
return self.plan(current_context["remaining_task"], current_context)
We saw a 40% reduction in task failure rate when we moved from single-pass LLM responses to explicit planning with backtracking. The cost? Higher latency. Each plan takes 2-3 LLM calls instead of one. But for enterprise workflows, accuracy matters more than speed.
What are the 4 components of agentic AI? If reasoning is done right, the other three components feel like supporting cast. Done wrong, they’re all you’ll think about.
Memory & State: The Agent’s Sense of Self
Here’s something that surprised me: agents don’t naturally remember anything. Each interaction is an island unless you explicitly build memory.
Memory in agentic AI is not just caching chat history. It’s three distinct systems:
- Episodic memory — What happened in this session (conversation history, past actions)
- Semantic memory — Knowledge about the world (product docs, company policies, domain facts)
- Procedural memory — How to do things (workflow templates, API call patterns)
At SIVARO, we built a multi-tier memory system for a sales qualification agent. The client needed the agent to remember customer preferences across sessions, adapt to changing pricing, and recall which messaging resonated.
python
class AgentMemory:
def __init__(self, redis_client, vector_db, sql_db):
self.short_term = redis_client # Session-level: TTL 1 hour
self.long_term = vector_db # Persistent: embeddings + metadata
self.structured = sql_db # Relational: [accounts](/articles/the-anonymous-github-account-mass-dropping-0-days-what-you), contacts, deals
def store_interaction(self, session_id, user_id, action, outcome):
# Episodic: session timeline
self.short_term.rpush(f"session:{session_id}", {
"action": action,
"outcome": outcome,
"timestamp": datetime.now()
})
# Semantic: update knowledge about this user
if outcome.get("new_preference"):
self.long_term.upsert(
collection="user_preferences",
id=user_id,
vector=self.embed(outcome["new_preference"]),
metadata={"updated_at": datetime.now()}
)
def recall_relevant_context(self, user_id, current_query):
# Retrieve relevant memories
similar_interactions = self.long_term.search(
collection="user_interactions",
query_vector=self.embed(current_query),
filters={"user_id": user_id},
k=5
)
# Merge with structured data
account_info = self.structured.execute(
"SELECT * FROM accounts WHERE id = ?",
(user_id,)
)
return {
"past_interactions": similar_interactions,
"account_context": account_info
}
The mistake most people make is treating memory as a single vector store. That works for demo apps. In production, you need hierarchical memory with different retrieval patterns. Short-term memory for speed, long-term for depth, structured for precision.
We learned this the hard way when our first memory system collapsed under 500 concurrent users. Short-term queries were hitting the vector DB, and latency spiked to 12 seconds per action. Redis fixed it.
Action Execution: Actually Doing Things
The final component is where the agent stops thinking and starts doing. Action execution is the bridge between the agent’s internal world and the external systems it controls.
This is brutally hard to get right. Your agent needs to:
- Call APIs reliably (not hallucinate endpoints)
- Handle errors gracefully (not crash when a 500 hits)
- Manage permissions (not escalate privileges without approval)
- Log everything (for debugging and compliance)
At SIVARO, we built a tool execution layer that validates every action before it happens:
python
class ActionExecutor:
def __init__(self, function_registry, approval_service):
self.registry = function_registry # Pre-registered, validated functions
self.approval = approval_service # Human-in-the-loop for sensitive actions
async def execute(self, action_plan, agent_state):
results = []
for step in action_plan:
# Validate the function exists and signature matches
if not self.registry.has_function(step["function_name"]):
results.append({
"status": "error",
"error": f"Unknown function: {step['function_name']}"
})
break
function_spec = self.registry.get_spec(step["function_name"])
validated_args = self.validate_arguments(
function_spec,
step["arguments"]
)
# Check if this action needs human approval
if function_spec.requires_approval or validated_args["risk_level"] > 0.7:
approval = await self.approval.request_approval(step)
if not approval.approved:
results.append({
"status": "blocked",
"reason": approval.reason
})
break
# Execute with timeout and retry logic
try:
result = await asyncio.wait_for(
self.registry.call(function_spec, validated_args),
timeout=function_spec.timeout
)
results.append({"status": "success", "data": result})
except TimeoutError:
results.append({"status": "error", "error": "timeout"})
except Exception as e:
results.append({"status": "error", "error": str(e)})
return results
The critical insight: action execution is where safety failures happen. We saw a team at a fintech startup lose $14,000 because their agent blindly called a refund API with negative amounts. The agent “reasoned” it could reverse charges by passing a negative value. The API accepted it. The money moved.
What are the 4 components of agentic AI? Action execution is the component that separates toys from tools. If your agent can’t safely touch the real world, it’s not an agent. It’s a chatbot cosplaying as one.
How These Components Work Together
The four components aren’t a linear pipeline. They’re a feedback loop.
Perception feeds reasoning, reasoning produces a plan, action execution runs the plan, memory stores the outcome, and perception starts again with new context from the action.
Here’s what that looks like in a real system:
python
class AgenticLoop:
def __init__(self, perception, reasoning, memory, execution):
self.perception = perception
self.reasoning = reasoning
self.memory = memory
self.execution = execution
self.state = {"step": 0, "history": []}
async def run(self, task):
# Phase 1: Perceive the input
perceived = self.perception.process_input(task)
self.state["current_context"] = perceived
# Phase 2: Load relevant memory
historical = self.memory.recall_relevant_context(
task.get("user_id"),
perceived["tokens"]
)
self.state["history"] = historical
# Phase 3: Reason and plan
plan = self.reasoning.plan(
task,
{"perceived": perceived, "memory": historical, "agent_state": self.state}
)
# Phase 4: Execute actions (potentially iterative)
outcomes = await self.execution.execute(plan, self.state)
# Phase 5: Store outcomes in memory
self.memory.store_interaction(
task.get("session_id"),
task.get("user_id"),
plan,
outcomes
)
return {"final_state": self.state, "outcomes": outcomes}
The Common Pitfall: Trying to Abstract Away the Components
I see this pattern everywhere. A startup raises money, hires ML engineers, and says “let’s build an agent platform.” They wrap an LLM in a framework that tries to handle all four components transparently. It works for demos. It fails in production.
Why? Because the components are deeply interconnected, and abstractions leak. When your perception layer isn’t catching a specific document format, you can’t fix it by tweaking the action executor. You need to understand the system at the component level.
At SIVARO, we test each component independently before integration. Perception gets tested against 10,000+ inputs. Reasoning gets bench-marked on planning accuracy. Memory gets stress-tested at 10x expected load. Action execution gets chaos-tested with simulated API failures.
FAQ: What Are the 4 Components of Agentic AI?
Q: Which component is hardest to implement in production?
A: Memory. Everyone thinks reasoning is the bottleneck. It’s not. Memory management — deciding what to remember, when to forget, and how to retrieve efficiently — is where systems fail. We’ve seen agents with perfect reasoning collapse because they couldn’t handle a 50-turn conversation without losing context.
Q: Do all agents need all four components?
A: Yes, if you want them to work reliably. You can build a demo with three. But in production, missing any one component creates a failure mode. Without perception, the agent misinterprets input. Without reasoning, it can’t handle novel situations. Without memory, it repeats mistakes. Without action execution, it’s all talk.
Q: What are the 4 components of agentic AI for simple use cases like email autoresponders?
A: Even simple agents need all four. The difference is complexity, not presence. An autoresponder’s perception is just email parsing. Its reasoning is a decision tree. Memory is just the thread history. Action execution is sending a reply. The components scale down, but they’re still there.
Q: How do you evaluate if an agent’s reasoning component is working?
A: Give it ambiguous tasks. If it asks clarifying questions or proposes multiple approaches, reasoning is working. If it confidently does the wrong thing, it’s just pattern-matching, not reasoning. We use a benchmark of 100 edge cases per domain.
Q: Can open-source models handle all four components?
A: Yes, but with trade-offs. We’ve deployed agents using Llama 3 70B for reasoning and GPT-4 for perception. The key is component isolation — you can mix models per component. Cost drops 60% if you use smaller models for structured perception tasks.
Q: What are the 4 components of agentic AI in multi-agent systems?
A: Same components, but each agent has its own instance. Communication between agents becomes a fifth concern. We built a supply chain system with 7 agents. Each had its own perception and memory. They shared a reasoning layer via a shared blackboard pattern.
Q: How do you handle component failures gracefully?
A: Build a circuit breaker for each component. If action execution fails 3 times in a row, the agent should pause and ask for human input. Not retry infinitely. We lost a batch of customer orders once because an agent kept retrying a broken API call.
Conclusion
I started this piece with a story about a failed prototype. That failure taught me something crucial: what are the 4 components of agentic AI? isn’t an academic question. It’s a production checklist.
Every time I see an agent fail in the wild, it’s because one of these four components was missing or broken. A startup loses money because memory was just a sliding window. An enterprise deployment gets pulled because action execution had no safety checks. A promising demo never ships because perception couldn’t handle real-world input variety.
Build your agents with perception, reasoning, memory, and action execution as first-class components. Test each one. Stress-test their interactions. And never assume the LLM will paper over the gaps — it won’t.
The agents that survive in production aren’t the smartest. They’re the ones with the most complete component architecture.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.