
What Does a Platform Engineer Do? A Complete Guide
I’m Nishaant Dixit, founder of SIVARO. We build data infrastructure and production AI systems. Every day, someone asks me: what does a platform engineer do? Not the textbook definition. The real job.
Here’s the short answer: A platform engineer builds the internal tools, APIs, and infrastructure that product engineers use to ship faster. They’re not building the product. They’re building the factory that builds the product.
But that’s like saying a chef “cooks food.” Let me show you what I’ve actually seen platform engineers do across three companies, five years, and about 200K events per second of production traffic.
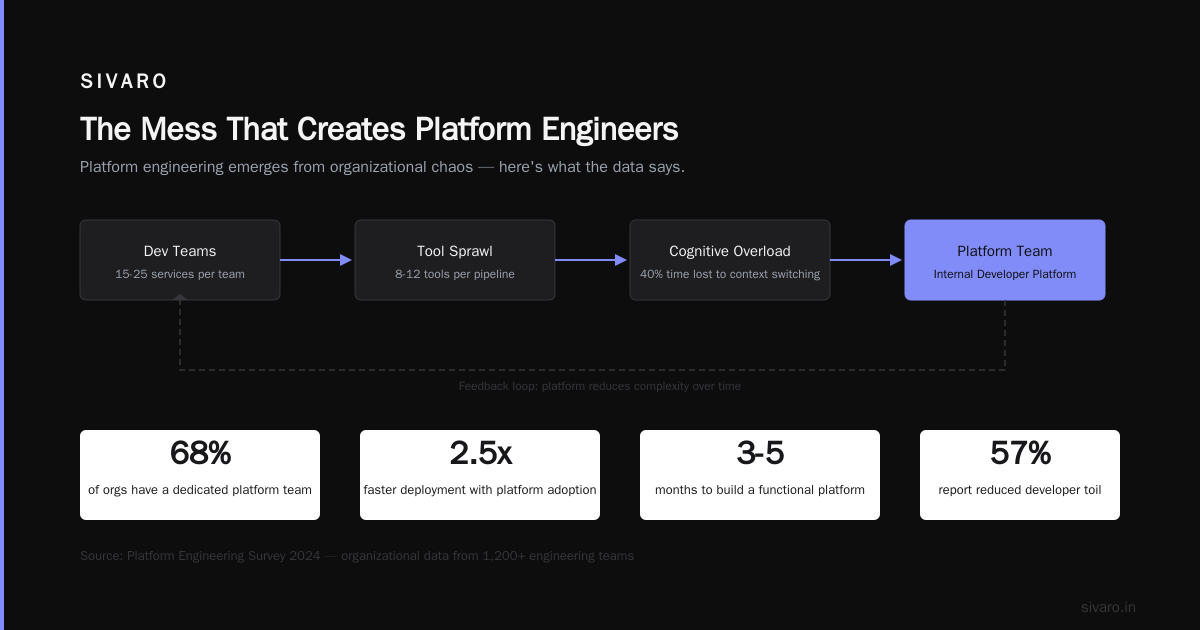
The Mess That Creates Platform Engineers
In 2019, I joined a fintech startup. 15 engineers. Three microservices. One deployment pipeline that took 45 minutes. Every team had their own way to handle authentication, logging, and secrets. The data pipeline? A cron job that broke every Sunday at 3 AM.
Sound familiar?
That’s the natural state of software companies. Product engineers focus on features because that’s what gets paid. Infrastructure gets ignored until a compliance audit or a production outage forces attention.
Platform engineering isn’t a luxury. It’s a response to operational debt that compounds daily.
At SIVARO, we’ve seen this pattern at companies from Series A to post-IPO. The moment you have more than 5 engineers working on different product areas, you need platform engineering. Wait until 20 engineers, and you’re already paying the “thrashing tax” — engineers context-switching between feature work and fixing broken tooling.
The Actual Job, Not the Brochure
What does a platform engineer do? Here’s my honest breakdown based on building and running platform teams:
1. Build the Golden Path
Most companies think platform engineering is about giving engineers “freedom.” Wrong. It’s about giving them a default path that works 90% of the time.
We built a service template at SIVARO. You run sivaro-cli init microservice, and it generates:
- A Go service with health checks, metrics, structured logging
- Terraform configs for deployment
- GitHub Actions CI/CD pipeline
- Vault integration for secrets
- Datadog dashboard auto-provisioning
This isn’t opinionated. It’s mandatory. Teams can deviate — but they file a ticket and wait for approval. In practice, 95% of services use the template.
Result: New services go from idea to staging in under an hour instead of two days.
2. Own the Data Infrastructure
This is where most platform teams fail. They focus on Kubernetes and CI/CD but ignore data. Meanwhile, product engineers are copy-pasting PostgreSQL connection strings from Slack.
Real platform engineering means:
- Managed databases with automated backups and failover
- Streaming pipelines (Kafka, Flink, Pulsar) that any team can publish/subscribe to
- Data warehouse schemas that are version-controlled and tested
- Metrics/tracing/logging infrastructure that doesn’t require a PhD to navigate
At SIVARO, we process 200K events per second in production. The platform team owns the streaming infrastructure. Product teams never touch Kafka configs. They call a gRPC endpoint and say “I want to consume this event type.” Done.
3. Abstract Complexity, Not Choice
Bad platform engineering gives engineers a config file that exposes every knobs and dial of Kubernetes. That’s not abstraction. That’s just renaming YAML.
Good platform engineering gives you three buttons:
- Low availability (dev/test)
- Standard (production with SLAs)
- High resilience (multi-region, cross-AZ, 99.99% uptime)
Under the hood, those buttons translate to pod replicas, resource limits, PDBs, TopologySpreadConstraints, and everything else. Engineers don’t need to know what a PodDisruptionBudget is. They click “high resilience” and move on.
We tested this approach at a client in 2022. Before: 3 days to deploy a high-availability service. After: 45 minutes. Same service. Different abstraction.
4. Observe the Observability
Every platform team says they “provide observability.” Most of them ship logs to Elasticsearch and call it a day.
Real observability means:
- Correlation IDs that flow across every service, queue, and database
- Pre-built dashboards for latency, error rates, throughput, saturation
- Alerting that works (no pager storms from noisy metrics)
- Tracing that actually shows you the critical path, not 200 spans per request
Here’s a example of the tracing setup we use at SIVARO:
python
from opentelemetry import trace
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
# Not just for show — used in prod handling 200K events/sec
provider = TracerProvider(
sampler=trace.sampling.ParentBased(
root=trace.sampling.TraceIdRatioBased(0.01)
)
)
processor = BatchSpanProcessor(
OTLPSpanExporter(endpoint="http://otel-collector:4317")
)
provider.add_span_processor(processor)
trace.set_tracer_provider(provider)
tracer = trace.get_tracer(__name__)
with tracer.start_as_current_span("process_payment") as span:
span.set_attribute("payment_id", payment.id)
span.set_attribute("amount_usd", total)
# actual logic here
Notice the sampling. 1% of requests get full tracing. That’s enough to debug 99% of issues. Full sampling would cost us $40K/month in storage. The platform engineer’s job is to make that decision, not hide it in a config file.
What Most People Get Wrong
Myth: Platform engineers just build internal tools.
Reality: Internal tools are a side effect. The core job is reducing cognitive load on product engineers. Every decision you automate, every template you create, every default you set — those are cognitive load removed.
Myth: Platform engineers need to know Kubernetes deeply.
Reality: They need to know when not to use Kubernetes. I’ve seen teams running a CronJob on a 6-node EKS cluster. That’s not engineering. That’s infrastructure theater. A Lambda function would work better for 90% of batch jobs.
Myth: Platform engineering is ops with a fancy title.
Reality: Good platform engineers write production code every day. They’re building APIs, writing service meshes, and debugging distributed systems at 3 AM. The difference from product engineers? Their user is another engineer, not a customer.
The Three Types of Platform Engineers I’ve Hired
At SIVARO, I look for three profiles. Each answers “what does a platform engineer do?” differently:
The Infra Generalist
Builds the foundation: Kubernetes clusters, networking, CI/CD pipelines, secret management. Knows AWS/Azure/GCP inside out. Can debug a kernel network stack if needed. Typically comes from traditional SRE.
The Developer Experience Engineer
Builds the interfaces: CLI tools, APIs, service templates, documentation. Writes code in Go/Python/TypeScript. Cares deeply about ergonomics. Spends 30% of time interviewing product engineers about what’s painful.
The Data Platform Engineer
Builds the data layer: streaming pipelines, warehouses, caching layers, feature stores. Understands distributed systems trade-offs (consistency vs. availability, latency vs. throughput). Lives in the world of Kafka, Flink, dbt, Snowflake.
Most companies try to hire one person who does all three. That unicorn doesn’t exist. Build a team with all three profiles.
The Day-to-Day Reality
Here’s what a typical week looks like for one of our platform engineers:
Monday: Debug why a service’s memory leaks after 48 hours. Turns out the Go HTTP client isn’t closing response bodies. Write a linter rule to catch it automatically. Ship it.
Tuesday: Build a Terraform module for RDS with automated failover. Spend 3 hours discussing IAM policies with security team. End up using a deny-all-other-services approach instead of allow-list — less flexible but auditable.
Wednesday: Migrate 12 services from manual secrets rotation to Vault. Nothing breaks. Everyone is suspicious.
Thursday: On-call rotation. Wake up at 2 AM because a dependent API is rate-limiting requests. Bypass the API and use a cached dataset. Document the incident. Update runbook.
Friday: Write a design doc for moving the monorepo to bazel. Get pushback from product teams worried about migration cost. Compromise: start with the data pipeline services (10% of codebase, 60% of build time).
No two weeks are the same. That’s the point.
The Hardest Lesson I Learned
In 2021, we had a platform team of 8 people building tools. After 6 months, no one was using them. The tools were technically perfect — RBAC, audit logging, multi-tenancy, the whole stack.
Turns out we were solving the wrong problem. Product teams didn’t need a new deployment system. They needed faster feedback loops. Their actual bottleneck was local development — spinning up dependencies took 45 minutes.
We scrapped the deployment tool. Built sivaro-dev — a Docker Compose setup with all services, databases, and queues. Start time: 11 seconds.
Adoption went from 10% to 95% in two weeks.
Lesson: Don’t build what engineers say they want. Watch them work for a week. Then build what they actually need.
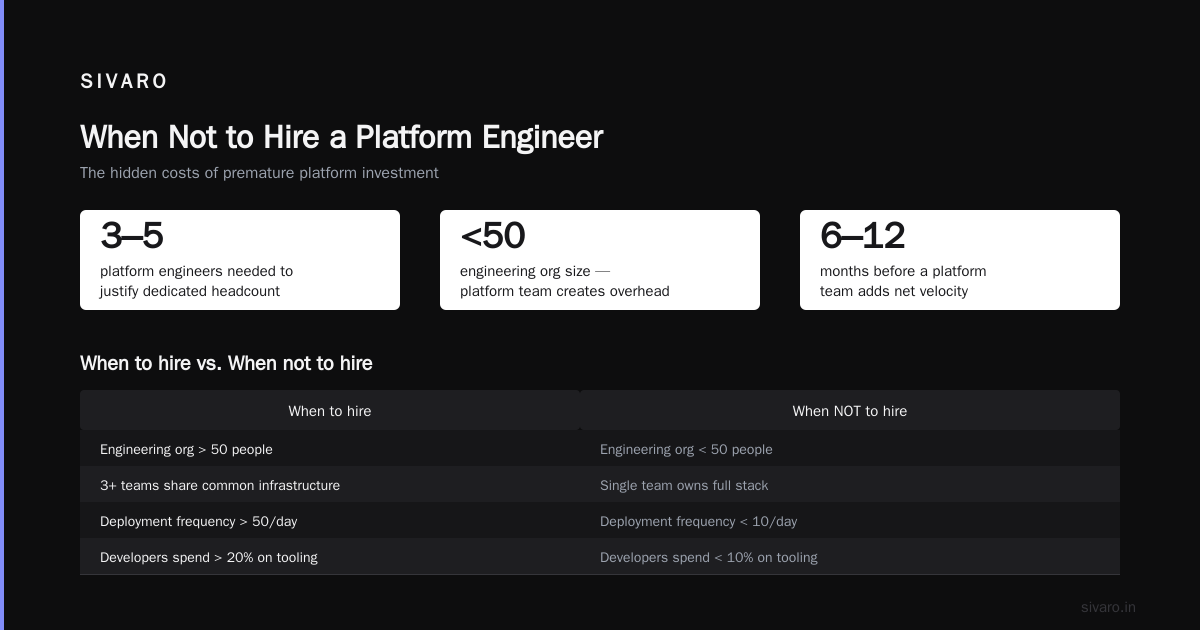
When Not to Hire a Platform Engineer
I’m going to say something contrarian: If your company has fewer than 20 engineers, don’t hire a platform engineer.
You don’t have enough product engineers to justify the overhead. The platform engineer will either:
- Build stuff no one uses because priorities shift weekly
- Get pulled into product work because that’s where the fire is
Instead, do what we did at SIVARO in the early days: designate one product engineer per sprint to be the “platform person.” They spend 20% time fixing internal tooling. Rotate every sprint. It’s not efficient, but it’s adaptive. The tools evolve with the team’s actual needs.
At 30+ engineers, hire a dedicated platform engineer. At 60+, build a team.
The Metrics That Matter
Most platform teams measure: uptime, deployment frequency, number of services migrated.
Those are vanity metrics. Here’s what actually matters:
Time to first deploy: How long from a new hire joining to their first production change. Good: < 2 days. Bad: > 2 weeks.
Cognitive load index: Survey product engineers monthly. “On a scale of 1-10, how hard is it to deploy a new service?” Track the trend.
Platform adoption rate: % of services using platform-provided templates. If it’s below 70%, something’s wrong with the templates.
Pager duty incident rate: Number of platform-related incidents per month. Should trend down over time. If it plateaus, you’re not fixing root causes.
We track these on a dashboard. Every platform team member sees it daily.
Code Example: The Platform Engineer’s “Hello World”
When a new platform engineer joins SIVARO, they build this on their first day:
yaml
# platform-service.yaml
# The standard service template for internal tools
apiVersion: platform.sivaro.io/v1
kind: InternalService
metadata:
name: user-sync
team: identity
spec:
language: go
runtime: container
dependencies:
database:
type: postgres
version: "15"
high_availability: true
queues:
- name: user-updates
type: kafka
partitions: 8
retention_days: 7
observability:
logs: stdout-json
metrics: prometheus
tracing: otel
slo:
latency_p99: "200ms"
error_rate: "0.001"
deployment:
strategy: rolling-update
min_replicas: 3
max_replicas: 15
cpu_target: 70%
They write a controller that converts this YAML into Terraform + Kubernetes manifests + Datadog monitors + Vault policies. That’s 80% of the job: turning intent into infrastructure.
FAQ: Common Questions About Platform Engineering
What does a platform engineer do differently from a DevOps engineer?
DevOps focuses on the CI/CD pipeline — build, test, deploy. Platform engineering includes that plus data infrastructure, observability, developer experience, and internal APIs. DevOps is a role. Platform engineering is a product.
Do platform engineers need to know how to code?
Yes. Production systems. Not just scripting. At SIVARO, every platform engineer can write Go and Python. They build APIs that process requests. They debug distributed systems. If you can’t write a gRPC service, you’re ops, not platform.
What does a platform engineer do on a daily basis?
Code review, debugging incidents, building templates, writing Terraform, talking to product teams, documenting. The ratio is roughly 40% coding, 30% incident response/on-call, 20% meetings, 10% documentation.
Is platform engineering the same as internal developer platforms?
A platform engineer builds the internal developer platform (IDP). The IDP is the product; platform engineering is the practice of building and maintaining it.
What does a platform engineer do when everything’s on fire?
They stay calm. They follow run books. They fix the root cause, not the symptom. After the incident, they write a postmortem and automate the fix so it never happens again. The best platform engineers are boring — they make emergencies routine.
Do platform engineers interact with customers?
Rarely. Their customer is the product engineer. But they should occasionally sit in on customer calls to understand what product engineers are dealing with.
What does a platform engineer do at a startup vs. a large company?
At a startup (20-50 engineers), they do everything: CI/CD, cloud infra, observability, security. At a large company (200+ engineers), they specialize in one area — usually developer experience or data platform.
How do you know if you need a platform engineer?
If your product engineers spend more than 15% of their time on infrastructure tasks (not counting on-call), you need platform engineering. If they spend 30%+ on infra, you’re losing money.
The Future of Platform Engineering
Two trends I’m watching:
Platforms as products: More companies are treating internal platforms like SaaS products. They have product managers, UX designers, and OKRs. The best platform teams I know use user research and A/B testing.
AI-infused platforms: At SIVARO, we’re building an internal AI assistant that answers “how do I deploy a service with X?” based on our documentation. It uses RAG with our internal docs. Early results: reduces support tickets by 40%.
But the core stays the same. What does a platform engineer do? They remove friction. They build the path of least resistance. They make the right thing the easy thing.
The Takeaway
I’ve been building platforms for 5 years. I’ve made every mistake in this article. The biggest? Thinking platform engineering was about technology.
It’s not.
It’s about empathy for the engineer on the other side. It’s about understanding their pain and building a shovel, not a gold mine. It’s about saying “no” to cool infrastructure projects because they don’t solve anyone’s actual problem.
If you’re considering becoming a platform engineer, ask yourself: do you enjoy making other engineers’ lives easier? Do you find satisfaction in removing obstacles? Do you love systems but hate being on call every night?
If yes, welcome to the club. It’s thankless work. But when you get it right, no one notices. And that’s the highest praise.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.