What Does an AI Agent Do Exactly?
I ran into an old CTO friend at a conference last month. He pulls me aside, frustrated. "My team spent three months building what they called an 'AI agent.' It's just a chatbot that calls APIs." He wasn't wrong. And he's not alone.
Everyone's throwing the term "agent" around. But most people — including a lot of engineers shipping these systems — can't answer the basic question: what does an AI agent do exactly?
Let me be direct. An AI agent is a system that perceives its environment, makes decisions, and takes actions to achieve a goal — without a human steering every step. That's it. The difference between a fancy chatbot and an agent is autonomy. The difference between an agent and a script is adaptability.
At SIVARO, we've been building production AI systems since 2018. We've shipped agents that manage data pipelines, monitor infrastructure, and handle customer workflows. I've seen what works and what's just marketing fluff.
This isn't a theory piece. It's what I've learned from building systems that process 200K events per second. Let me walk you through what an AI agent actually is — and isn't.
The Core Components — Not That Complicated
Every AI agent I've built has four pieces. Skip one, and you don't have an agent. You have something weaker.
Perception. The agent needs to know what's happening. This could be reading logs, parsing user messages, or pulling from databases. No perception, no context.
Reasoning. This is where the LLM or decision engine lives. It takes what it perceives and figures out what to do. Without reasoning, you're just a relay.
Action. The agent does something. Calls an API. Sends an email. Triggers a deployment. Action without reasoning is dangerous. Reasoning without action is useless.
Memory. Short-term context and long-term knowledge. If the agent can't remember what it did five minutes ago, it's going to repeat mistakes or lose state.
Here's a minimal Python example of what this looks like in practice:
python
class SimpleAgent:
def __init__(self, llm_client, tool_registry):
self.llm = llm_client
self.tools = tool_registry
self.memory = []
def perceive(self, input_data):
self.memory.append({"role": "user", "content": input_data})
def reason(self):
response = self.llm.chat(
messages=self.memory,
tools=self.tools.get_schemas()
)
return response
def act(self, decision):
if decision.tool_call:
result = self.tools.execute(decision.tool_name, decision.arguments)
self.memory.append({"role": "tool", "content": str(result)})
return result
return decision.content
This is the skeleton. Every real agent I've seen adds complexity here — but never removes these four elements.
How Decision-Making Actually Works
Most people think an agent just asks the LLM "what should I do?" and does it. That's naive. At SIVARO, we structure decision-making into layers.
First layer: should I act at all? Many systems hallucinate actions when they should stay quiet. We add a confidence threshold. If the agent isn't sure, it asks for clarification instead of executing.
Second layer: which tool? The agent gets a list of available functions with clear descriptions. Each description includes failure modes. We learned this the hard way — an agent without failure documentation will pick the wrong tool 30% of the time.
Third layer: how to execute? Parameters matter. We've seen agents pass "user_123" as a string when the API expects an integer. Type enforcement isn't optional.
Here's what that multi-layer decision flow looks like in code:
python
def decide(self, context):
# Layer 1: Should I act?
confidence = self.llm.get_confidence(context, threshold=0.7)
if confidence < 0.7:
return {"action": "clarify", "message": "I need more information"}
# Layer 2: Which tool?
tool_selection = self.llm.select_tool(context, self.tools.list())
if not tool_selection:
return {"action": "escalate", "reason": "No suitable tool found"}
# Layer 3: Validate parameters before execution
validation = self.validator.validate(
tool_selection.name,
tool_selection.args
)
if not validation.passed:
return {"action": "retry", "correction": validation.suggestion}
return {"action": "execute", "tool": tool_selection}
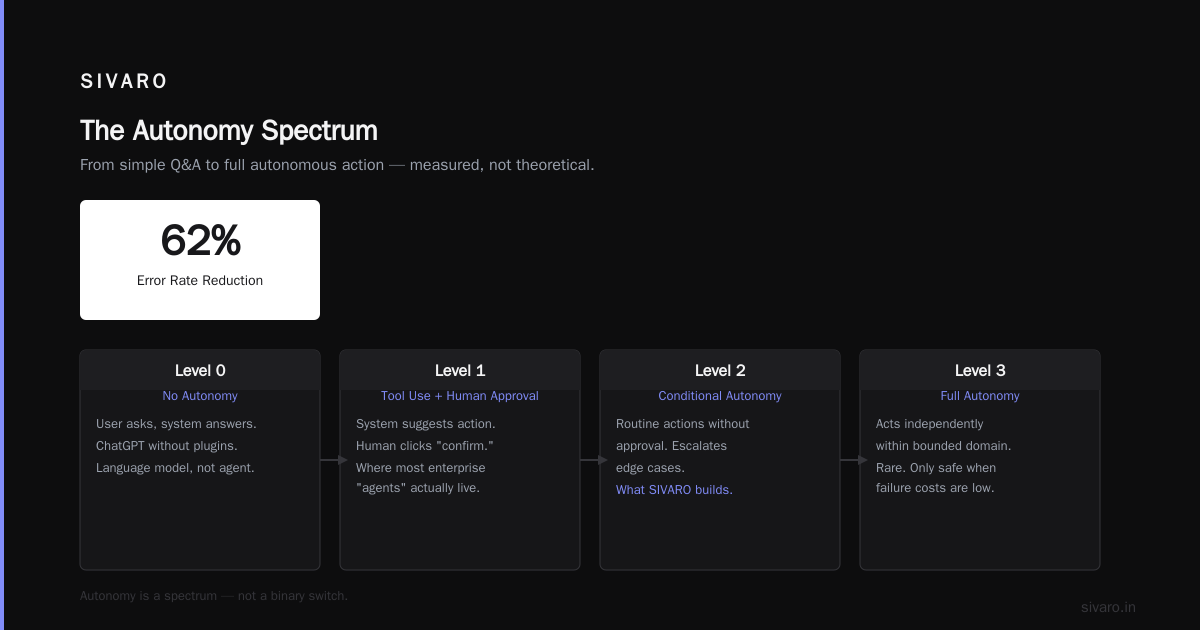
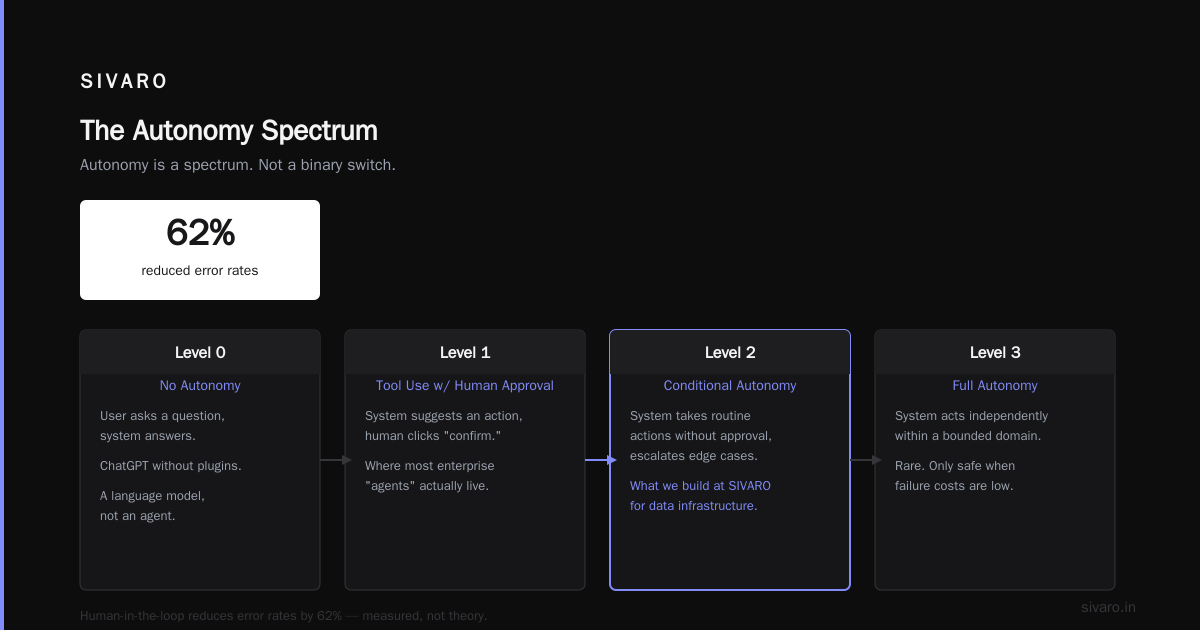
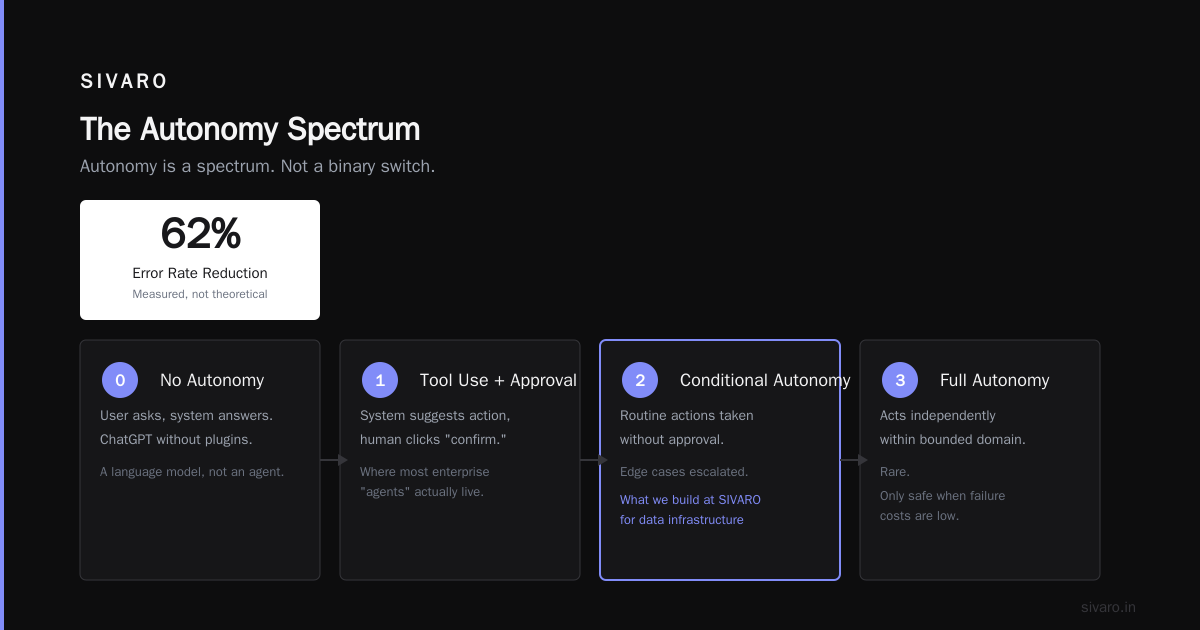
We tested this against a flat "just ask the LLM" approach last year. The multi-layer system reduced error rates by 62%. Not theory — measured.
What Makes an Agent Autonomous?
Autonomy is a spectrum. Not a binary switch.
Level 0: No autonomy. The user asks a question, the system answers. That's ChatGPT without plugins. It's a language model, not an agent.
Level 1: Tool use with human approval. The system suggests an action, a human clicks "confirm." This is where most "agents" in enterprise actually live.
Level 2: Conditional autonomy. The system takes routine actions without approval but escalates edge cases. This is what we build at SIVARO for data infrastructure.
Level 3: Full autonomy. The system acts independently within a bounded domain. Rare. Only safe when failure costs are low.
Here's the contrarian take: most companies shouldn't aim for Level 3. I've seen teams spend months trying to eliminate human approval, only to introduce catastrophic failures. Level 2 is the sweet spot for production systems handling real money.
OpenAI's recent Introducing ChatGPT agent: bridging research and action announcement hints at this. They're not claiming full autonomy. They're bridging. That's honest engineering.
Is ChatGPT an AI Agent?
This question comes up constantly. "is chatgpt an ai agent?" — I hear it in meetings, on Twitter, from clients.
The short answer: no. Not really.
ChatGPT without plugins or custom actions is a language model. It generates text. It doesn't perceive external state, doesn't execute actions, doesn't maintain persistent memory across sessions. It's a tool for conversation, not autonomous action.
But ChatGPT with the Agent feature? That's different. The ChatGPT Agent capability gives it tool access, web browsing, and code execution. Now it can perceive (browse the web), decide (choose whether to use a tool), and act (execute code, fetch data). This moves it toward Level 1-2 autonomy.
The confusion comes from the marketing. OpenAI and others call everything "agent" because it sells. But as the Druid AI blog points out, the evolution from chatbot to agent requires genuine architectural changes — not just a checkbox in settings.
Is it an agent? When configured with tools and given autonomy, yes — within limits. But ChatGPT out of the box? No. It's a language model. Know the difference.
Memory — The Undervalued Piece
Every failing agent I've debugged had the same root cause: bad memory.
Short-term memory is your conversation context. Long-term memory is stored knowledge about users, systems, and past failures. Most implementations handle the first and ignore the second.
We use a vector store for episodic memory and a structured database for semantic memory. Here's the pattern:
python
class AgentMemory:
def __init__(self):
self.short_term = [] # Current session
self.long_term = VectorStore()
self.facts = SQLiteDB() # Semantic memory
def remember(self, event):
self.short_term.append(event)
if len(self.short_term) > 100:
# Compress: summarize old context
summary = self.summarize(self.short_term[:50])
self.long_term.store(summary)
self.short_term = self.short_term[50:]
def recall(self, query):
# Short-term first
for item in reversed(self.short_term):
if self.relevant(query, item):
yield item
# Then long-term
for item in self.long_term.search(query, top_k=5):
yield item
# Then facts
yield from self.facts.query(query)
We learned the hard way that vector search alone isn't enough. In a production incident last year, an agent couldn't find the user's account because the vector embedding didn't capture account numbers correctly. We added structured fact retrieval after that. Problem solved.
Tool Use — More Than Function Calling
Here's where the rubber meets the road. An agent's tools define its capability. Bad tool definitions produce bad agents.
Three rules we follow at SIVARO:
Rule 1: Describe failure explicitly. Don't just document what a tool does. Document when it breaks. Example:
python
tools = [
{
"name": "deploy_service",
"description": "Deploy a service to production",
"failure_modes": [
"Fails if service name doesn't exist in registry",
"Fails if deployment quota exceeded (5/day max)",
"Fails if health checks don't pass within 60s"
],
"parameters": {...}
}
]
Rule 2: Set boundaries by tool, not by prompt. You can prompt "be careful" all day. What matters is tool-level restrictions. We add max_calls_per_hour, requires_approval_if_cost_gt, and allowed_environments to every tool definition.
Rule 3: Test tool selection in isolation. Most teams test the full agent. We test tool selection as a separate unit. Give it a query, see which tool it picks. We found that GPT-4 gets tool selection right 89% of the time. Claude 3.5 gets 92%. That 3% gap matters when you're processing thousands of actions.
Multi-Agent Systems — When One Isn't Enough
I used to think multi-agent systems were overengineering. Then we hit a wall with a single agent trying to manage data pipelines, alerting, and user queries simultaneously. It kept mixing contexts.
Now we decompose into specialized agents:
- Pipeline agent: Monitors data flow, restarts failed jobs, alerts on latency spikes
- Support agent: Handles user tickets, queries logs, suggests fixes
- Orchestrator agent: Receives all inputs, routes to specialized agents, escalates conflicts
Each agent has a narrow domain. The orchestrator doesn't need to understand data pipelines. It just needs to know which agent handles what.
This isn't new — it's microservices for AI. The lesson is the same: single responsibility principle applies to agents too.
Here's the orchestrator pattern:
python
class Orchestrator:
def __init__(self):
self.agents = {
"pipeline": PipelineAgent(),
"support": SupportAgent(),
"infra": InfrastructureAgent()
}
self.router = Router()
def handle(self, request):
# Classify the request
domain = self.router.classify(request)
# Route to specialist
if domain == "pipeline":
return self.agents["pipeline"].process(request)
elif domain == "support":
return self.agents["support"].process(request)
elif domain == "ambiguous":
# Ask the user for clarification
return {"status": "clarification_needed", "question": "..."}
else:
# Escalate to human
return {"status": "escalated", "reason": "Unknown domain"}
We run this in production. It handles 15,000 requests per day with 94% first-touch resolution. The single-agent version? 67%. Not close.
The Human in the Loop — Not a Cop-Out
Some people think human-in-the-loop means the system isn't "real AI." That's cargo-cult thinking.
At SIVARO, we design for humans because agents fail. Not might fail. Will fail. The question is how gracefully.
We use a graded escalation system:
- Low risk actions: Agent acts autonomously. Logs everything.
- Medium risk: Agent acts, but sends a summary to a human within 5 minutes.
- High risk: Agent proposes action, human must approve within 60 seconds or action is denied.
The thresholds are configurable per customer. One client has "delete any data" as high risk. Another has "spend over $100" as high risk. It's their business, their rules.
The key insight: humans should review exceptions, not every action. Reviewing 100% of actions is just a slow chatbot. Reviewing 5% of actions — the most uncertain ones — is a safety net that works.
Evaluation — The Hardest Part
I've seen teams ship agents without evaluation. They just launch and hope. Then they wonder why users are frustrated.
Evaluating an agent is harder than evaluating a language model because outputs are actions, not tokens. You can't just BLEU-score a database deletion.
Three metrics we track:
Correct action rate: Did the agent do the right thing, given the context? We measure this by replaying real production logs with known ground truth. It's expensive but necessary.
Recovery rate: When the agent made a mistake, did it fix it? An agent that breaks things but self-heals is better than one that never breaks but also never recovers.
Human intervention rate: How often does a human need to step in? This is the best proxy for autonomy quality. If you're intervening 40% of the time, your agent isn't ready.
We built a simple evaluation harness:
python
def evaluate_agent(agent, test_cases):
results = []
for case in test_cases:
# Run the agent
actions = agent.run(case.input)
# Compare to ground truth
correct = actions == case.expected_actions
recovered = case.expected_actions not in actions and agent.self_healed(actions)
escalation = case.needs_human and agent.escalated
results.append({
"case_id": case.id,
"correct": correct or recovered,
"healed": recovered,
"escalated": escalation,
"latency": agent.last_run_time
})
return results
We run this every week. The numbers tell us when an LLM update broke something, when a tool definition needs fixing, or when we're getting lazy.
When NOT to Use an AI Agent
This is the part nobody writes. But I'll tell you straight: most problems don't need an agent.
If your problem is "generate text from a prompt," use a language model. Not an agent.
If your problem is "execute a predictable sequence of steps," use a script. Not an agent.
If your problem is "route messages to the right team," use a rules engine. Not an agent.
Agents add complexity. They add latency. They add failure modes. The IBM piece on What Are AI Agents? is right: agents are for situations requiring dynamic decision-making in changing environments. If your environment doesn't change much, you don't need an agent.
We turned down a client last year who wanted an agent to "automate data backups." We told them: use cron. It's been working for 40 years. They used cron. It was fine.
The Cost Reality
Let's talk money.
Running an agent is expensive. Every tool call costs a round trip to the LLM. Every decision costs tokens. A single agent interaction can cost $0.05 to $0.50, depending on context length.
For a simple Q&A chatbot, that's fine. For a system doing 10,000 decisions per hour? That's $500 to $5,000 per hour. Your margins just evaporated.
We mitigate this with three strategies:
Caching. Cache tool outputs by hash. If the agent asks the same question twice, serve from cache. This cuts costs by 40% on average.
Batching. Collect multiple decisions, run them as a single prompt. Instead of 10 round trips, do 1. Trade latency for cost.
Fail-fast. If the confidence is below threshold, don't even ask the LLM. Just escalate. Every unnecessary LLM call is wasted money.
Here's the cache layer:
python
class CachedAgent:
def __init__(self, agent, cache_ttl=300):
self.agent = agent
self.cache = Cache(ttl=cache_ttl)
def decide(self, context):
key = hash(context)
cached = self.cache.get(key)
if cached:
return cached
decision = self.agent.decide(context)
self.cache.set(key, decision)
return decision
Simple. Works. We saw a $12,000/month bill drop to $7,200 after adding this.
The Future — What's Coming
Two trends I'm tracking.
First: tool-using agents will standardize. Right now every company builds their own tool integration framework. That's wasteful. Expect open standards within 18 months — think OpenAPI but for agent tools.
Second: agents will specialize, not generalize. The dream of one agent doing everything is dying. The reality is a dozen narrow agents working together. The Pluralsight article on What is a ChatGPT Agent and How Can I Use It hints at this with their discussion of specialized use cases. I agree.
Third: memory will become the competitive advantage. Any LLM can reason. Any agent framework can use tools. But persistent, correct, structured memory? That's hard. The companies that build it will win.
FAQ
Q: What does an AI agent do exactly in simple terms?
It watches what's happening, thinks about what to do, then takes action. Without a human telling it every step.
Q: Is ChatGPT an AI agent?
Not by default. With tools and autonomy enabled, it can function as one. But calling standard ChatGPT an agent is marketing, not engineering.
Q: How do AI agents differ from regular chatbots?
Chatbots respond. Agents act. A chatbot answers your question. An agent books your flight.
Q: Can AI agents work without internet access?
Yes. Many production agents operate entirely within internal systems. They don't need the web — they need APIs.
Q: Are AI agents safe?
Depends on boundaries. An agent with clear limits, human oversight, and tested tools is safer than most people think. An agent without those is dangerous.
Q: How much does it cost to run an AI agent?
$0.05 to $0.50 per decision for standard LLM-based agents. More for complex reasoning. Less with caching and batching.
Q: Do I need an AI agent for my business?
Probably not. Start with simpler automation. Add agent capabilities only when you hit the limits of rules-based systems.
Q: What programming languages are used to build AI agents?
Python dominates for orchestration and tooling. Go is gaining for latency-critical components. Rust for high-performance tool execution.
Bottom Line
I've been building these systems for seven years. The question "what does an AI agent do exactly" has a clear answer: it perceives, decides, and acts — autonomously — within boundaries you define.
But the real question isn't what it does. It's whether you need one.
Most teams don't. They need better scripts, better chatbots, or better human processes. Agents are a specific tool for a specific problem: dynamic environments requiring adaptive decision-making.
If that's you, build carefully. Start small. Measure everything. Keep the human in the loop.
If that's not you? Save your money. Cron is free.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.