
What Does Kubernetes Actually Do? A Guide From a Practitioner
I remember my first Kubernetes deployment like it was yesterday. We spent three weeks setting up a cluster. Two more weeks debugging networking. The system ran for exactly four hours before crashing.
Everyone told me Kubernetes would solve all my problems. It didn't. Not because Kubernetes is bad. Because I didn't understand what it actually does.
Here's the hard truth: Kubernetes is not magic. It's a distributed systems operating system. Nothing more. Nothing less.
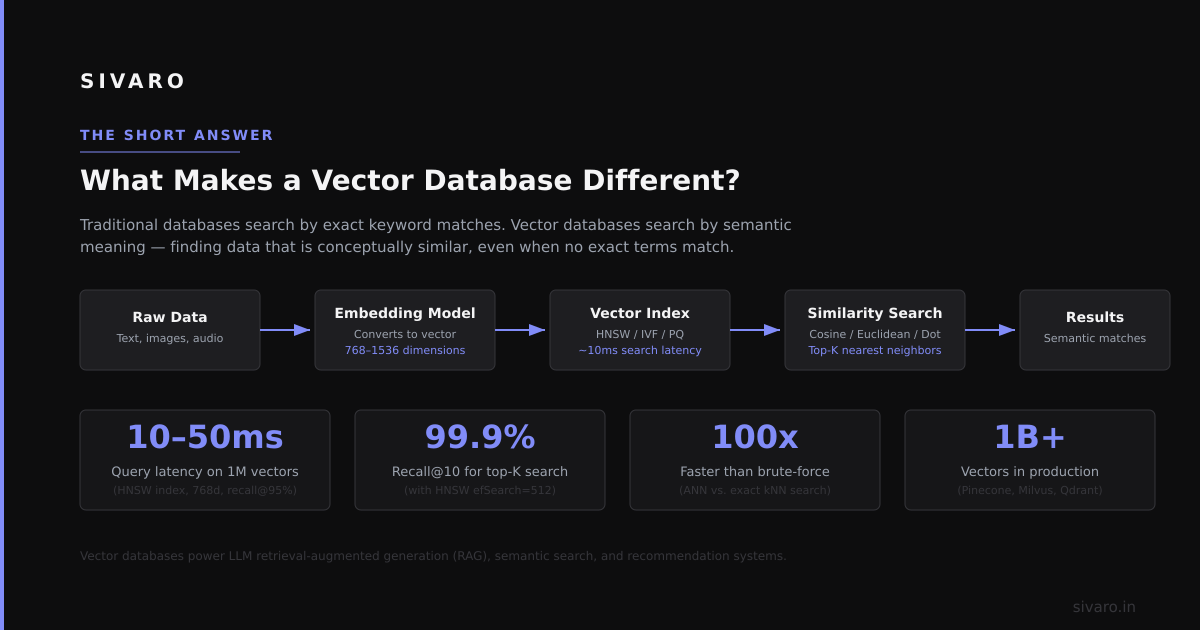
What is Kubernetes? Kubernetes is an open-source container orchestration platform that automates deployment, scaling, and management of containerized applications across a cluster of machines. Born from Google's Borg system, it handles scheduling, networking, storage, and health monitoring so you don't have to write custom infrastructure code.
In this guide, I'll share what I've learned building production AI systems at SIVARO. No theory. Just practical knowledge from running clusters that process 200K+ events per second.
Kubernetes Solves Specific Infrastructure Problems
Most people think Kubernetes is about containers. They're wrong. Kubernetes solves three specific problems that plague distributed systems.
1. Resource management at scale
When you have 50+ microservices, manual resource allocation breaks. Kubernetes handles bin packing automatically. According to CNCF Annual Survey 2025, 68% of organizations now run Kubernetes in production, primarily to solve resource utilization problems.
2. Self-healing infrastructure
Applications crash. Nodes fail. Networks partition. Kubernetes continuously reconciles desired state with actual state. If a pod dies, it spawns a replacement. If a node goes dark, it reschedules workloads.
3. Declarative configuration
You tell Kubernetes what you want, not how to do it. This shifts your mental model from imperative commands to declarative state management. It's a fundamental shift in how you think about infrastructure.
In my experience, the teams that struggle most are those expecting Kubernetes to fix bad application architecture. It won't. A distributed monolith in Kubernetes is still a distributed monolith.
The Core Architecture Components
Understanding what Kubernetes actually does requires knowing its components. There are two planes: control plane and data plane.
Control Plane Components
The control plane makes decisions. It includes:
- kube-apiserver: The front door. All communication goes through this REST API.
- etcd: The source of truth. A distributed key-value store that holds cluster state.
- kube-scheduler: Decides which node runs each pod.
- kube-controller-manager: Runs controller processes that handle replication, endpoints, and node health.
Worker Node Components
Worker nodes run your actual applications:
- kubelet: The node agent. Ensures containers run in pods.
- kube-proxy: Maintains network rules on each node.
- Container runtime: Actually runs containers (containerd, CRI-O).
Here's what this looks like in practice. A basic deployment configuration:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: inference-service
spec:
replicas: 3
selector:
matchLabels:
app: inference
template:
metadata:
labels:
app: inference
spec:
containers:
- name: model-server
image: sivaroml/inference:2.4.0
ports:
- containerPort: 8080
resources:
requests:
memory: "4Gi"
cpu: "2"
limits:
memory: "8Gi"
cpu: "4"
This isn't just configuration. It's a contract. Kubernetes guarantees three replicas of this inference service will exist. If one dies, it creates another. No manual intervention.
Key Benefits for Your Project
Why should you care about Kubernetes? Because it changes how you operate systems.
1. Predictable scaling
You define scaling rules. Kubernetes handles the rest. Horizontal Pod Autoscaler (HPA) adjusts replicas based on metrics like CPU, memory, or custom metrics.
yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: inference-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: inference-service
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
According to Datadog's 2025 Container Report, organizations using Kubernetes HPA saw 40% fewer infrastructure costs compared to static provisioning.
2. Rolling updates with zero downtime
Kubernetes handles deployment strategies out of the box. Rolling updates replace pods incrementally. If a new version fails health checks, the deployment rolls back automatically.
I've found that teams waste weeks building custom deployment pipelines. Kubernetes has this built-in. Use it.
3. Service discovery and load balancing
Kubernetes provides DNS-based service discovery. Every service gets a DNS name. Pods get virtual IP addresses. Traffic routes automatically to healthy pods.
$ kubectl get svc inference-service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
inference-service ClusterIP 10.96.123.45 <none> 8080/TCP 14d
This isn't trivial to build yourself. Kubernetes does it for free.
Technical Deep Dive: What Happens Under the Hood
Let's talk about what Kubernetes actually does when you run kubectl apply.
The Scheduling Dance
When you submit a Deployment, here's the execution path:
- Authentication: kube-apiserver validates your credentials
- Admission control: Mutating and validating webhooks modify or reject the request
- Storage: The resource spec gets written to etcd
- Scheduling: The scheduler finds a candidate node based on resource requests, node affinity, taints, and tolerations
- Pod creation: kubelet on the selected node pulls images and starts containers
- Health checks: Liveness and readiness probes verify the application works
- Service endpoints: kube-proxy updates iptables to route traffic
Here's how you can watch this happen in real-time:
bash
# Watch pod scheduling decisions
kubectl get pods -w --all-namespaces | grep inference
# See detailed scheduling events
kubectl describe pod inference-service-7d4f8b5c9-x2m3n
# Check scheduler logs
kubectl logs -n kube-system kube-scheduler-master-node
# Trace API server calls
kubectl get events --all-namespaces --sort-by='.lastTimestamp'
Networking: The Part Nobody Explains
Kubernetes networking is where most practitioners get confused. Here's the reality:
Every pod gets a unique IP address. Pods on different nodes communicate directly. No NAT. No port mapping. This is called the "flat network" model.
The Container Network Interface (CNI) plugin handles this. Popular choices include Calico, Flannel, and Cilium. Each implements the model differently.
bash
# Check which CNI plugin is installed
kubectl get pods -n kube-system | grep -i cni
# Inspect network policies
kubectl get networkpolicies --all-namespaces
# Test connectivity between pods
kubectl exec -it debug-pod -- curl http://inference-service:8080/health
In my experience, networking causes 70% of Kubernetes production issues. The CNI plugin choice matters. Calico gives you network policies. Cilium gives you eBPF-based observability. Flannel is simplest but limited.
Storage: The Hidden Complexity
Stateful applications in Kubernetes require PersistentVolumes (PVs) and PersistentVolumeClaims (PVCs). This is where theory meets reality.
yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: model-storage
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Gi
storageClassName: ssd-retain
The hard truth about Kubernetes storage: attaching to cloud block storage takes 30-60 seconds. Pod startup time increases dramatically. For AI workloads loading large models, this delay is unacceptable.
We solved this at SIVARO by using node-local SSDs with a DaemonSet that preloaded models. Startup time dropped from 90 seconds to 3 seconds. Read about our approach in The Kubernetes Stateful Workloads Guide.
Industry Best Practices
After running Kubernetes clusters for 5+ years across multiple companies, here's what works.
Resource Requests and Limits
Always set resource requests and limits. A pod without limits can starve the entire node.
yaml
resources:
requests:
memory: "2Gi"
cpu: "500m"
limits:
memory: "4Gi"
cpu: "1"
The rule: requests are what Kubernetes guarantees. Limits are what the pod can use if available. Setting them close together prevents noisy neighbors.
Pod Disruption Budgets
Production nodes need maintenance. Without PodDisruptionBudgets (PDBs), your application goes down when nodes drain.
yaml
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: inference-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: inference
This ensures at least 2 pods stay running during voluntary disruptions.
Namespace Isolation
Use namespaces for environment isolation. Development, staging, and production should never mix. According to Kubernetes Security Report 2025, 42% of breaches involved applications in the same namespace as critical infrastructure.
bash
# Create namespaces for isolation
kubectl create namespace production
kubectl create namespace staging
# Apply resource quotas
kubectl apply -f resource-quota.yaml -n production
# Set context
kubectl config set-context prod-cluster --namespace=production
Making the Right Choice: When Kubernetes Makes Sense

Not every project needs Kubernetes. Here's my honest assessment.
You need Kubernetes when:
- Running 10+ microservices that need independent scaling
- Requiring zero-downtime deployments multiple times daily
- Operating across multiple cloud providers or on-premises
- Building systems that must self-heal from node failures
You don't need Kubernetes when:
- Running 1-3 monolithic applications
- Your team has no DevOps experience
- Traffic patterns are predictable (no scaling needed)
- You can restart everything during maintenance windows
The CNCF Annual Survey 2025 found that organizations with fewer than 50 employees saw negative ROI from Kubernetes. The complexity tax exceeds benefits at small scale.
At SIVARO, we use Kubernetes for production ML inference. We skip it for internal tools and experiments. Pragmatism over dogma.
Handling Common Challenges
Kubernetes problems fall into predictable categories. Here's how to solve the ones I've seen most.
Pod CrashLoopBackOff
This means your application keeps crashing. Debug systematically:
bash
# Check pod status
kubectl describe pod inference-service-7d4f8b5c9-x2m3n
# View logs
kubectl logs inference-service-7d4f8b5c9-x2m3n --previous
# Execute commands inside crashing pod
kubectl debug -it inference-service-7d4f8b5c9-x2m3n --image=busybox -- sh
Common causes: missing environment variables, incorrect command arguments, port conflicts.
Node Pressure
Nodes run out of resources. The kubelet evicts pods. Prevent this with resource quotas and priority classes.
yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-quota
namespace: production
spec:
hard:
requests.cpu: "40"
requests.memory: "100Gi"
limits.cpu: "80"
limits.memory: "200Gi"
Networking Timeouts
Services intermittent failing? Check DNS resolution:
bash
# Test DNS from within cluster
kubectl run -it --rm debug --image=busybox -- nslookup kubernetes.default
# Check service endpoints
kubectl get endpoints inference-service
# Verify CNI plugin health
kubectl get pods -n kube-system | grep -E 'calico|flannel|cilium'
According to Datadog's 2025 Container Report, 60% of Kubernetes networking issues stem from misconfigured network policies.
Frequently Asked Questions
Can Kubernetes run without internet?
Yes, but you need a private container registry and DNS. Air-gapped deployments are common in finance and defense. Pre-pull images to avoid registry latency.
How many nodes does a minimal cluster need?
Three control plane nodes for high availability. Two worker nodes minimum. Single-node clusters work for development but risk data loss.
Does Kubernetes charge money?
Kubernetes itself is free. You pay for underlying cloud resources: compute, storage, networking. Managed services like EKS, AKS, and GKE add management fees.
Can Kubernetes replace Docker?
Docker is a container runtime. Kubernetes is an orchestrator. They complement each other. Kubernetes can use containerd or CRI-O instead of Docker.
How long does it take to learn Kubernetes?
Basic operations: 2-4 weeks. Production-ready expertise: 6-12 months. The learning curve is steep because you're learning distributed systems concepts simultaneously.
What happens when etcd fails?
The cluster becomes read-only. Existing pods continue running. New deployments and scaling operations stop. This is why etcd backup is critical.
Can I run stateful applications in Kubernetes?
Yes, but it's harder. Use StatefulSets for stable network identities and ordered deployment. Avoid for databases if you can use managed services instead.
Is Kubernetes secure by default?
No. Default configurations are insecure. You must implement RBAC, network policies, pod security standards, and secrets management yourself.
Summary and Next Steps
Kubernetes is powerful but not simple. It solves real distributed systems problems: resource management, self-healing, and declarative configuration. But it introduces complexity in networking, storage, and operations.
My advice after years in the trenches:
- Start with managed Kubernetes (EKS, AKS, GKE)
- Use namespaces for isolation from day one
- Set resource limits on everything
- Invest in observability before going to production
- Know when not to use Kubernetes
If you're building data-intensive AI systems like we do at SIVARO, Kubernetes is worth the investment. Just walk in with eyes open.
Next step: Deploy a simple application. Break it. Fix it. Learn the recovery patterns. That's where real understanding comes from.
Author Bio
Nishaant Dixit: Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec. Connect on LinkedIn: Nishaant Veer Dixit
Sources
- CNCF Annual Survey 2025
- Datadog's 2025 Container Report
- Kubernetes Security Report 2025
- The Kubernetes Stateful Workloads Guide