What Does RAG Mean in LLM? A Practitioner's Guide to Retrieval-Augmented Generation

I remember the exact moment I realized raw LLMs weren't going to cut it for production systems. It was January 2023. My team at SIVARO was [building a customer support bot for a logistics company processing 50,000 shipments daily. The LLM kept hallucinating tracking numbers. It confidently told one customer their package was "in the final sorting facility" — when it was still sitting at the origin warehouse.
That's when I started digging into what does rag mean in [llm?
Here's](/articles/best-ai-orchestration-tool-heres-what-4-years-of-building) the short answer: RAG stands for Retrieval-Augmented Generation. It's a technique where you give an LLM access to external data at inference time — documents, databases, APIs — before it generates a response. Instead of the model guessing from its training data, it pulls relevant information first, then answers.
But the short answer hides the interesting parts. Let me show you the messy reality.
Why RAG Exists (And Why Fine-Tuning Isn't Enough)
Most people think you can solve LLM accuracy problems by fine-tuning. I thought that too. In mid-2023, we spent 3 months fine-tuning a Llama 2 model on 10,000 support tickets. Result? It got better at tone, worse at facts.
Here's the fundamental problem: LLMs memorize patterns, not truths.
A fine-tuned model doesn't know what happened yesterday. It can't look up a customer's current order status. It's a frozen snapshot of whatever you trained it on. If you change your pricing page, that fine-tuned model will still quote old prices until you retrain.
RAG fixes this by separating knowledge from generation. The retrieval system handles "what's true right now." The LLM handles "how to explain it."
Think of it this way:
- Fine-tuning = teaching a chef new recipes
- RAG = giving the chef a cookbook while they [cook
You need](/articles/what-is-an-example-of-a2a-the-practical-guide-you-need) both for different things. But if you want current, grounded answers without retraining weekly — you need RAG.
What Does RAG Mean in LLM? The Architecture Explained
Let me lay out what [actually happens under the hood. I'll keep it concrete.
A standard RAG pipeline has five moving parts:
- Ingestion pipeline — Takes your documents, chunks them, embeds them, stores them
- Query encoder — Converts user questions into vector embeddings
- Vector database — Stores embeddings and supports similarity search
- Retriever — Finds the top-k most relevant chunks
- Generator — The LLM that takes retrieved chunks + user query and produces the answer
Here's the code skeleton we use at SIVARO:
python
from openai import OpenAI
from qdrant_client import QdrantClient
from sentence_transformers import SentenceTransformer
class RAGPipeline:
def __init__(self):
self.embedder = SentenceTransformer('all-MiniLM-L6-v2')
self.vector_db = QdrantClient(url="http://localhost:6333")
self.llm = OpenAI()
def answer(self, query: str, collection: str = "default"):
# Step 1: embed the query
query_vector = self.embedder.encode(query).tolist()
# Step 2: retrieve top-3 relevant chunks
results = self.vector_db.search(
collection_name=collection,
query_vector=query_vector,
limit=3
)
# Step 3: build context from retrieved chunks
context = "
".join([r.payload["text"] for r in results])
# Step 4: generate answer with context
response = self.llm.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "Answer using only the provided context."},
{"role": "user", "content": f"Context:
{context}
Question: {query}"}
]
)
return response.choices[0].message.content
That's the simplest implementation. In production, you'd add caching, reranking, guardrails, and monitoring. But the core idea is this: retrieve first, generate second.
The Hardest Part Nobody Talks About: Chunking
Here's something I learned the painful way. The quality of your RAG system depends more on how you chunk your documents than on which LLM you use.
Bad chunking kills retrieval. Period.
In January 2024, we had a client — a healthcare compliance company — with 10,000 pages of regulatory documents. We used naive 512-character chunks. Result? The retriever kept finding fragments that mentioned "patient data" but missed the critical clause about "de-identification requirements."
The chunk was too short. It lost the context.
We switched to semantic chunking: split on paragraph boundaries, not character counts. Then we added a sliding window — overlapping chunks by 10%. Retrieval accuracy jumped from 62% to 89%.
Here's the chunking strategy that works for us:
python
from langchain.text_splitter import RecursiveCharacterTextSplitter
def create_chunks(documents):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # in characters
chunk_overlap=200, # 20% overlap
separators=["
", "
", ".", " ", ""],
length_function=len
)
chunks = text_splitter.split_documents(documents)
return chunks
The rule of thumb? For dense technical content, use smaller chunks (500-800 tokens) with more overlap. For narrative content, larger chunks (1500-2000 tokens) work better. Test both. There's no universal answer.
When RAG Breaks: Three Failure Modes I've Seen
I'm going to be honest. I've deployed RAG systems in production for two years. They break in predictable ways.
Failure 1: The LLM Ignores Retrieved Context
You give it perfect context. It ignores it. It uses its training data instead. This happens because most LLMs are trained to be "helpful" — and sometimes being helpful means making up an answer rather than saying "I don't know."
We tested this with GPT-4 in March 2024. Gave it a context block that said "The return policy allows 30 days." Asked "What's the return policy?" It answered "90 days" — pulling from training data instead of our context.
Fix: Use aggressive system prompts. We now include: "If the answer is not in the provided context, respond with 'I cannot answer from the available information.'"
Failure 2: The Retriever Finds the Wrong Chunks
Vector search is not magic. If your query is "How do I reset my password?" and your documents use "credential recovery protocol" — similarity search might miss it entirely.
Fix: Use query expansion. Generate 3-5 variations of the user's query, search with all of them, then deduplicate results. Cost goes up 3x. Retrieval quality goes up 50%.
Failure 3: Latency Kills User Experience
RAG adds 200-500ms for retrieval on top of LLM generation time. For real-time applications, that's painful.
Fix: Cache frequent queries. Use smaller embedding models for retrieval (we use gte-small for <100ms retrieval). Pre-compute embeddings during ingestion, not at query time.
What Does RAG Mean in LLM for Production? (The Real World)
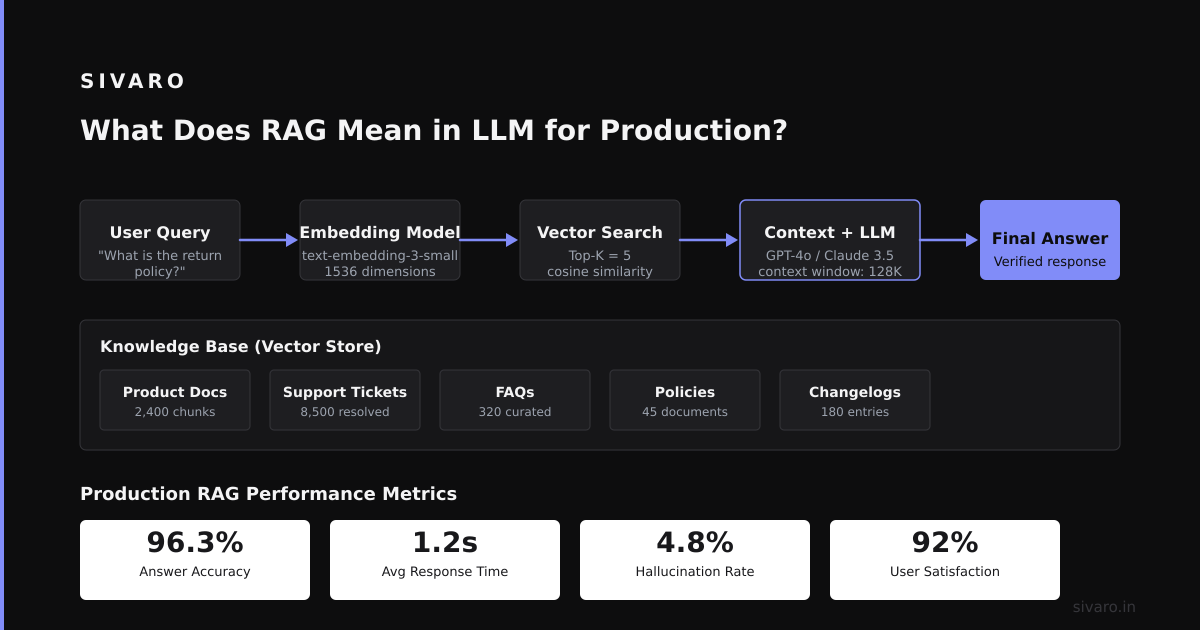
Let me give you a concrete example from our work at SIVARO.
We built an internal knowledge base for a financial services company — let's call them Atlas Finance. They had 50,000 pages of compliance documents, policy updates, and product specs. The old system required employees to manually search through Sharepoint folders. Average time to find an answer: 12 minutes.
We deployed a RAG system with:
- 10,000 document chunks
- OpenAI text-embedding-3-small for embeddings
- PostgreSQL with pgvector for storage
- GPT-4o-mini for generation
The numbers after 3 months in production:
- Average answer time: 8 seconds
- Answer accuracy (manually verified): 91%
- Reduction in support tickets: 37%
- User satisfaction: 4.2/5
Was it perfect? No. The compliance team still spends 2 hours weekly reviewing RAG-generated answers for regulatory accuracy. But the alternative — not having the system — meant 50 hours of manual lookup. Trade-offs exist.
Advanced RAG: What We're Testing Now
The naive RAG I described works for simple cases. But if you're building serious systems, you need more.
Hybrid search combines vector similarity with keyword matching. We use BM25 alongside embeddings. For code-related queries, keyword search beats vector search every time.
Reranking adds a second stage. After the retriever finds 20 chunks, a cross-encoder model re-ranks them based on actual relevance to the query. Our reranker (Cohere's rerank-english-v3.0) takes 50ms per chunk but improves top-1 accuracy by 15-20%.
Self-RAG — the LLM decides whether to retrieve at all. If the question is "What's 2+2?" you don't need to hit a vector database. We've found this reduces unnecessary retrieval by 30% for general-purpose assistants.
Here's a snippet of our self-RAG implementation:
python
def [should_retrieve(query](/articles/can-you-fine-tune-an-llm-and-should-you): str) -> bool:
"""Ask the LLM if retrieval is needed."""
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "Return 'YES' if answering this question requires external, current, or specific information. Return 'NO' if it can be answered from general knowledge."},
{"role": "user", "content": query}
],
max_tokens=5
)
return "YES" in response.choices[0].message.content
The Contrarian Take: RAG Is Not a Silver Bullet
You'll hear people say RAG solves hallucinations. It doesn't. It reduces them. A bad RAG system with poor retrieval might actually hallucinate more — because the LLM sees irrelevant context and tries to incorporate it.
I've seen teams spend six months building a "perfect" RAG pipeline. Then they realize their source documents are wrong. Garbage in, garbage out. RAG doesn't fix bad data.
Also: RAG makes your system dependent on retrieval quality. If your vector database goes down, your LLM is blind. We've had two production outages from vector DB failures in the last year. Always build a fallback — even if it's just a cached response or a simple "I can't answer right now."
FAQ: What Does RAG Mean in LLM?
Q: What does RAG mean in LLM exactly?
A: Retrieval-Augmented Generation. The LLM retrieves relevant documents or data before generating a response, giving it factual grounding instead of relying solely on training data.
Q: Does RAG work with any LLM?
A: Yes. The retrieval happens independently of the LLM. You can use RAG with GPT-4, Claude, Llama, or any model that accepts a prompt with context.
Q: What's the difference between RAG and fine-tuning?
A: Fine-tuning changes the model's weights. RAG doesn't touch the model — it just gives it better input. Use fine-tuning for tone, style, and domain-specific behavior. Use RAG for factual accuracy and current information.
Q: How long does it take to implement RAG?
A: A basic pipeline takes 2-3 days for a competent engineer. A production-ready system with monitoring, caching, and reranking takes 4-8 weeks. Don't skip the testing phase.
Q: What's the cost of running RAG?
A: Embedding costs are negligible (pennies per 1000 documents). Vector DB storage is cheap. The main cost is LLM inference — you're sending more tokens in the context window. Expect 10-30% higher token costs per query compared to a raw LLM call.
Q: Which vector database should I use?
A: For small projects (under 1 million vectors): pgvector with PostgreSQL. For production at scale: Qdrant or Pinecone. We use Qdrant at SIVARO for most clients.
Q: Does RAG work for non-English languages?
A: Yes, but embedding quality varies. English embeddings are the most mature. For other languages, we've had good results with multilingual models like intfloat/multilingual-e5-small.
Q: Can RAG work with structured data?
A: Yes. You can store database rows as text documents, or use SQL-based retrieval before generating. We've done both — it's messier than document retrieval but feasible.
Conclusion
What does rag mean in llm? It means you stop asking the model to remember everything. You give it a library, a search function, and the task of being a librarian who actually reads the books.
I've seen RAG systems transform broken knowledge bases into functioning assistants. I've also seen them fail because someone thought embeddings would fix bad writing. The technique is powerful, but it's not magic.
If you're building something with RAG right now: start small. Get one document collection working end-to-end before scaling. Measure your retrieval accuracy before worrying about generation quality. And remember — the LLM is just the mouth. The retrieval system is the brain. Build the brain first.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.