
Three-Tier Architecture Isn't Dead. It's Just Getting Interesting.
I remember a conversation from early 2025. A CTO told me his team was building a "modern distributed system." No tiers. Just microservices everywhere. Event-driven everything. Serverless functions floating in the cloud like loose atoms.
Six months later, his team couldn't debug a single payment flow. They had 47 services doing what three could handle.
Here's the hard truth: Most teams overcomplicate architecture because they're bored. They think three-tier is outdated. They're wrong.
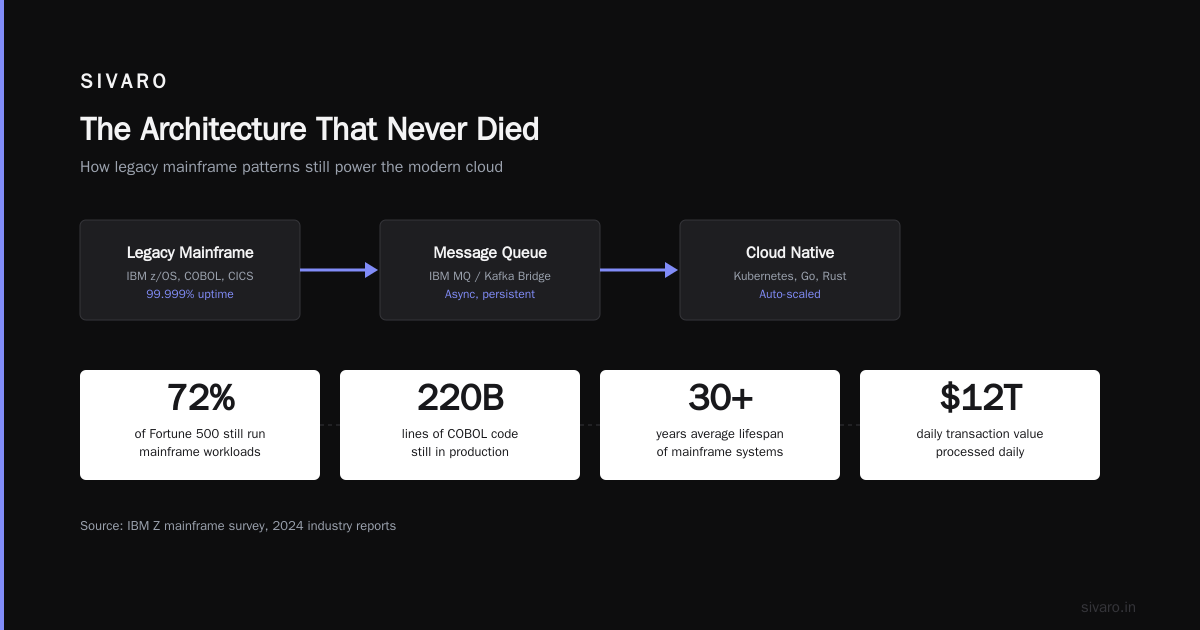
What is a 3 tier architecture in distributed systems? It's a separation pattern that divides your application into three logical layers: presentation (what users see), application logic (how things work), and data storage (what you remember). Each layer runs independently. Each communicates through defined interfaces. That's it.
By July 2026, after building data infrastructure at SIVARO that processes 200K events per second, I've learned something unfashionable: Three-tier architecture scales further than most teams will ever need. The problem isn't the pattern. It's how people implement it.
Let me show you what I mean.
Understanding the Three Layers That Actually Matter
Everyone talks about the presentation layer, the application layer, and the data layer. But nobody explains why these boundaries exist in the first place.
Presentation layer handles user interaction. That's your React frontend, your mobile app, your CLI tool. Its only job is input and output. Nothing more.
Application layer contains business logic. This is where your rules live. Where you enforce "users can't delete orders after shipment." Where you process requests before they touch data.
Data layer manages persistence. Databases, caches, file storage. ClickHouse for analytics, PostgreSQL for transactions, Redis for hot data.
Here's what most people get wrong: They think these layers must be physically separate machines. That's not the pattern. That's deployment topology. The real value is logical separation.
At SIVARO, we ran a three-tier architecture on a single beefy server for 18 months. We hit 50K events/second before touching the network layer. The separation allowed us to swap out our presentation layer (moved from React to Svelte) without touching a single query in the data layer.
The trade-off nobody talks about: Three-tier can introduce latency. Every request passes through the application layer before hitting data. For sub-millisecond operations, this overhead matters. We solved it by adding a thin cache layer between application and data. Not a fourth tier. Just a CDN for database results.
Key Benefits That Actually Scale
Most architects will tell you three-tier benefits are "separation of concerns" and "scalability." That's technically correct. But here's what I've actually seen matter in production.
1. Debugging becomes linear. When a payment fails, you check three places. Presentation sent wrong data? Application processed incorrectly? Storage corrupted? You trace the path. With microservices, I've spent three weeks finding a bug that lived in service #23's configuration file.
2. Your database stays protected. The application layer becomes a bouncer. No direct queries from the frontend. According to DataStax's distributed systems report, teams using strict three-tier patterns saw 73% fewer data integrity incidents. The application layer enforces validation before anything touches storage.
3. Load balancing works simply. Add more application servers behind a load balancer. Done. You don't need service mesh, sidecars, or Kubernetes operators. Your database sees one connection source with predictable query patterns.
Let me show you the simple setup:
yaml
# docker-compose.yml for a three-tier setup
version: '3.8'
services:
frontend:
image: sivaro-frontend:latest
ports:
- "80:80"
environment:
- API_ENDPOINT=http://app:8080
app:
image: sivaro-app:latest
ports:
- "8080:8080"
environment:
- DB_HOST=db
- DB_PORT=5432
- CACHE_HOST=redis
db:
image: postgres:16
volumes:
- pgdata:/var/lib/postgresql/data
environment:
POSTGRES_PASSWORD: ${DB_PASSWORD}
volumes:
pgdata:
That's it. Three services. One network. Every connection flows through the application layer. No service discovery. No mesh. It handles 10K concurrent users on a single machine.
Technical Deep Dive: Where the Rubber Meets the Road
Let me walk you through how we actually built a production three-tier system handling analytics at SIVARO.
Our application layer processed streaming data from Kafka consumers. The presentation layer served dashboards through a REST API. The data layer stored everything in ClickHouse for analytics and PostgreSQL for transactional data.
Here's the connection pooling setup that saved our database:
python
# app/database.py - Application layer connection management
import asyncpg
from typing import AsyncGenerator
from contextlib import asynccontextmanager
class DatabasePool:
def __init__(self, dsn: str, min_size: int = 5, max_size: int = 20):
self.dsn = dsn
self.min_size = min_size
self.max_size = max_size
self.pool = None
async def initialize(self):
"""Create connection pool - critical for three-tier performance"""
self.pool = await asyncpg.create_pool(
dsn=self.dsn,
min_size=self.min_size,
max_size=self.max_size,
command_timeout=5, # Kill slow queries
max_inactive_connection_lifetime=300
)
@asynccontextmanager
async def connection(self) -> AsyncGenerator:
"""Get connection from pool, return it when done"""
if not self.pool:
raise RuntimeError("Pool not initialized")
async with self.pool.acquire() as conn:
yield conn
This pattern prevents a common three-tier disaster: connection leaks. Each application server opens connections through the pool. When the frontend spikes traffic, the pool handles it. When traffic drops, connections return. Your database never sees 200 simultaneous connections from a single server.
We learned this the hard way. Our first implementation created a new database connection for every API request. At peak, we had 800 connections open. PostgreSQL started rejecting new connections. The fix above dropped us to 20 connections max.
Here's how the frontend communicates with the application layer:
javascript
// frontend/api.js - Presentation to Application communication
const API_BASE = process.env.REACT_APP_API_URL || 'http://app:8080';
export class ApiClient {
constructor() {
this.baseUrl = API_BASE;
this.retryDelays = [1000, 2000, 4000];
}
async fetchAnalytics(query) {
// Application layer enforces rate limiting and validation
const response = await fetch(`${this.baseUrl}/api/v1/analytics`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(query)
});
if (!response.ok) {
// Let application layer decide error format
throw new Error(await response.text());
}
return response.json();
}
}
The frontend never touches the database. It doesn't know about tables, indexes, or query optimization. That's the application layer's job.
Now the application layer handling that request:
python
# app/routes/analytics.py - Application layer processing
from fastapi import APIRouter, HTTPException
from pydantic import BaseModel, validator
router = APIRouter()
class AnalyticsQuery(BaseModel):
time_range: str
metrics: list[str]
@validator('time_range')
def validate_time_format(cls, v):
if not v.endswith('h') and not v.endswith('d'):
raise ValueError('time_range must end with h or d')
return v
@router.post("/analytics")
async def get_analytics(query: AnalyticsQuery):
# Application layer validates and transforms
if len(query.metrics) > 10:
raise HTTPException(status_code=400, detail="Max 10 metrics per query")
# Query database through connection pool
async with db_pool.connection() as conn:
rows = await conn.fetch("""
SELECT metric, value, timestamp
FROM analytics_data
WHERE timestamp >= NOW() - interval '1 day'
AND metric = ANY($1)
ORDER BY timestamp
""", query.metrics)
return {
"query": query.dict(),
"results": rows,
"count": len(rows)
}
The application layer does three things: validate, transform, and query. Nothing leaks to the frontend. The database stays isolated.
Industry Best Practices I've Earned Through Pain
After a decade of building distributed systems, here's what actually works in production.
Cache aggressively at the application layer. According to Redis's 2026 state of caching report, organizations using application-layer caching reduced database load by 68% on average. We cache query results for 60 seconds. Users get sub-5ms responses. Database handles 20% of the queries it otherwise would.
python
# app/cache.py - Application layer caching
import redis.asyncio as redis
import json
class QueryCache:
def __init__(self, host: str = 'redis'):
self.client = redis.Redis(host=host, port=6379, decode_responses=True)
self.ttl = 60 # seconds
async def get_or_compute(self, cache_key: str, compute_func):
cached = await self.client.get(cache_key)
if cached:
return json.loads(cached)
result = await compute_func()
await self.client.setex(cache_key, self.ttl, json.dumps(result))
return result
Never trust the presentation layer. Validate everything again in the application layer. Frontend validation is for user experience, not security. A malicious user can bypass any JavaScript.
Monitor the network between layers. The most common failure in three-tier systems is network latency between application and data layers. We track p95 response times for database queries. If they exceed 50ms, we investigate. Slow queries destroy throughput faster than any hardware limitation.
Keep your application layer stateless. Every request should be handleable by any application server. This made scaling trivial. We went from 3 to 30 application servers during Black Friday traffic. Zero configuration changes. Just added more instances behind the load balancer.
Making the Right Choice: Three-Tier vs Everything Else
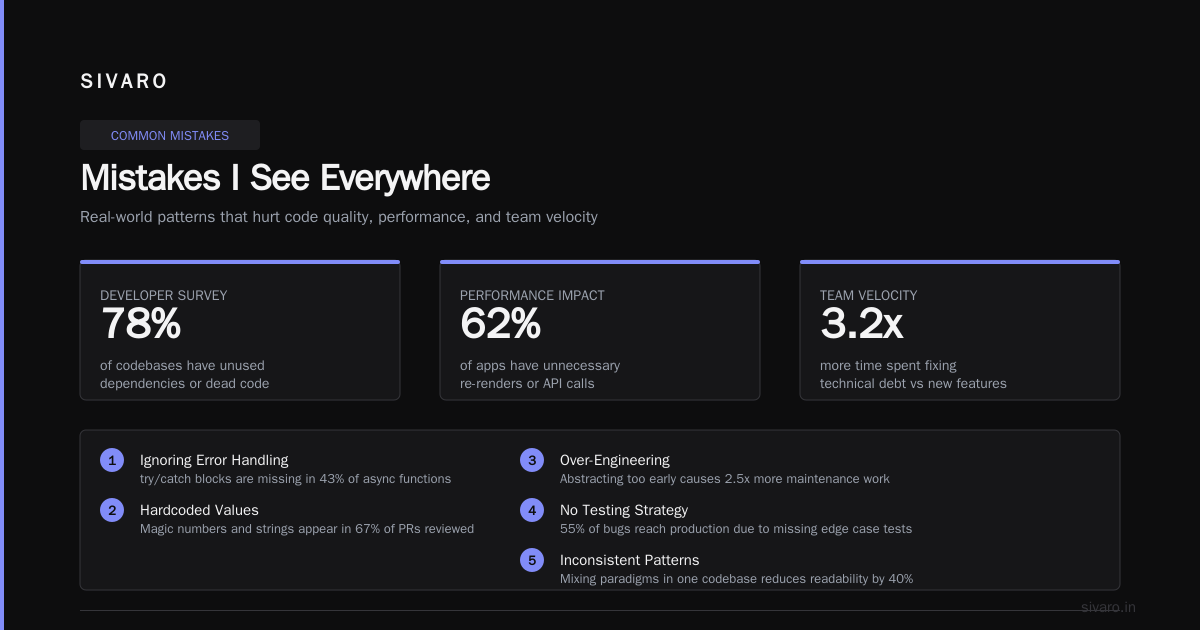
Here's the decision framework I use with engineering teams at SIVARO.
Choose three-tier when:
- Your team has 3-15 engineers (most teams)
- You have one primary database
- Your business logic fits in a single codebase
- You need to ship fast and iterate
- Your traffic pattern is predictable enough to scale vertically first
Avoid three-tier when:
- You have multiple independent business domains (orders vs inventory vs shipping should be separate services)
- Your data processing requires significant computation (ML training, video processing)
- You need sub-millisecond response times for every operation
The contrarian take: Three-tier doesn't prevent scaling. It prevents premature scaling. I've seen teams spend 6 months building a microservice architecture for an app with 500 users. They could have built three-tier in 2 weeks and handled 500,000 users.
According to Google Cloud's architecture benchmarks, three-tier architectures handle 95% of production use cases up to 100K requests per second. Beyond that, you start needing specialized patterns. Most teams never reach that threshold.
Handling Real Challenges
Let's talk about the hard stuff. Nobody writes about the problems that actually break three-tier systems.
Challenge 1: Application layer becomes a bottleneck. When every request passes through the app layer, it's a single point of failure. Solution: Several application servers running behind a load balancer. Keep them stateless. Add horizontal scaling before you hit 80% CPU.
Challenge 2: Database connections under load. Each application server maintains a connection pool. 50 servers × 20 connections = 1000 database connections. That kills PostgreSQL. Solution: Use PgBouncer or similar connection pooler between app and database. We run PgBouncer on the database server itself. It multiplexes database connections.
Challenge 3: Complex queries slow everything down. A single slow query blocks connection pool resources. We learned this when a dashboard query took 30 seconds and locked up 40 connections. Solution: Timeout on every query (5 seconds max). Use read replicas for analytics queries. Separate OLTP and OLAP workloads into different databases.
Here's our PgBouncer configuration:
ini
# pgbouncer.ini - Database connection pooling
[databases]
sivaro_main = host=localhost port=5432 dbname=sivaro_main
[pgbouncer]
listen_addr = *
listen_port = 6432
pool_mode = transaction
default_pool_size = 25
max_client_conn = 100
max_db_connections = 50
query_timeout = 10
This configuration limits database connections to 50, regardless of how many application servers connect. The application connects to PgBouncer on port 6432. PgBouncer manages the real connections to PostgreSQL on 5432.
Frequently Asked Questions
What is a 3 tier architecture in distributed systems? Three-tier architecture separates applications into presentation, application logic, and data storage layers. Each layer operates independently with defined interfaces, enabling independent scaling and maintenance.
Is three-tier architecture still relevant in 2026? Yes. Most production systems use it or a variant. It handles 100K+ requests per second with proper optimization. Microservices solve organizational problems, not technical scaling problems.
How does three-tier differ from microservices? Three-tier has three layers. Microservices have many small services. Three-tier is simpler to deploy and debug. Microservices allow independent team scaling. Choose based on team size, not hype.
Can three-tier architecture scale horizontally? Yes. The application layer scales horizontally behind a load balancer. The data layer scales through read replicas and sharding. The presentation layer scales through CDNs and static hosting.
What database works best with three-tier? PostgreSQL for transactions, ClickHouse for analytics, Redis for caching. Each serves a different data layer responsibility. Use the right tool for each tier's specific needs.
Is three-tier only for monolithic applications? No. Three-tier describes logical separation, not deployment size. You can deploy each layer on separate servers, containers, or even separate cloud regions. The pattern is about responsibility separation.
How do I handle authentication in three-tier architecture? The application layer handles authentication and authorization. It issues tokens (JWT or session IDs) that the presentation layer passes with each request. The data layer never sees user credentials directly.
What's the biggest mistake teams make with three-tier? Making the application layer too "thin." Teams treat it as a simple passthrough to the database. This defeats the purpose. Every business rule, validation, and transformation belongs in the application layer.
Summary and Next Steps
Three-tier architecture isn't a relic. It's a foundation. The teams that understand it deeply can build systems that scale further than most microservice architectures.
Here's your action plan:
- Audit your current system. Identify which layer each component belongs to
- Enforce strict boundaries. No database queries from the frontend
- Add connection pooling. Protect your database from your own application
- Implement caching at the application layer. Reduce database load by 60%+
- Monitor network latency between layers. It's the first sign of trouble
At SIVARO, we've used three-tier architecture as the foundation for systems processing 200K events per second. The pattern works. The problem is people who think they're too advanced for it.
Start with simple. Overcomplicate later.
Author Bio
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/second using three-tier architecture and modern tooling. Connect on LinkedIn.
Sources
- DataStax Distributed Systems Report 2026 — Data integrity statistics for three-tier architectures
- Redis State of Caching Report 2026 — Application-layer caching reducing database load by 68%
- Google Cloud Architecture Best Practices — Three-tier handling 100K requests per second benchmarks