
What Is a Platform Engineering Example? A Practitioner’s Guide
I remember the exact moment I realized platform engineering wasn’t just DevOps with a new label. It was late 2019. We were [building a data pipeline for a fintech client at SIVARO. The team had six microservices, three data stores, two streaming [systems, and a Kafka cluster that kept dying during peak trading hours.
Every new feature took two weeks longer than it should have. Developers spent 60% of their time on infrastructure glue—connecting services, managing secrets, debugging deployments. We weren’t building product. We were building scaffolding that collapsed every sprint.
So I asked a simple question: What if we gave the team a single internal tool that handled all this nonsense automatically?
That was my first answer to what is a platform engineering example? It’s not theory. It’s a concrete thing you build.
The Real Definition (Not the Hype)
Here’s what platform engineering actually is: It’s the practice of building internal tools and infrastructure that developers use to ship [software faster, with less cognitive load, and with guardrails built in.
A platform engineering example is any internal product—usually a set of APIs, UIs, and automation—that abstracts away complexity. Think of it as an internal PaaS designed for your company’s specific needs.
Most people think it’s just “DevOps tools for developers.” They’re wrong. DevOps is a cultural practice. Platform engineering is a product you build. You design it, ship it, iterate on it, and maintain it like any other software product. The users are your own engineers.
At SIVARO, we’ve built three major platform engineering examples over the last five years. I’ll walk you through the most instructive one.
Concrete Example 1: The Data Pipeline Platform
The problem: Our client, a logistics company in Germany, processed 50 million tracking events daily. Each event triggered multiple transformations, enrichments, and writes to PostgreSQL, Elasticsearch, and a Redshift data warehouse. Their team of 15 engineers was drowning.
Every new data source required:
- Spinning up a new Kafka consumer
- Writing configuration for three separate sinks
- Setting up monitoring dashboards
- Managing secret rotation
- Handling retries and dead letter queues
- Writing CI/CD pipelines
The platform example: We built a self-service data pipeline platform called “Flux.” It had:
- A YAML-based configuration language for declaring pipelines
- A control plane that managed deployments, scaling, and monitoring
- A UI for visibility into pipeline health
- Built-in connectors for Kafka, HTTP, S3, PostgreSQL, Elasticsearch, and Redshift
Here’s what a pipeline declaration looked like:
yaml
pipeline: tracking-events
source:
type: kafka
config:
topic: tracking.raw
consumer_group: flux-tracking
max_batch_size: 100
transforms:
- type: flatten
- type: enrich
via: redis
[key_field](/articles/how-to-orchestrate-agentic-ai-a-field-guide-for-2026): shipment_id
- type: validate
schema: event_schema_v2
sinks:
- type: postgres
config:
table: tracking_events
upsert_key: event_id
- type: elasticsearch
config:
index: tracking-{yyyy-MM-dd}
batch_size: 500
- type: redshift
config:
table: stg_tracking
partition_column: event_timestamp
The result: New data sources went from 2 weeks to 2 days. Pipeline failures dropped by 80% because the platform handled retries and dead letter queues automatically. The team stopped debugging infrastructure and started building features.
The trade-off: We spent 3 months building Flux. That’s 3 months of zero feature work. It only paid off after month 6. If the company had pivoted or died in that window, we’d have wasted serious money. Platform engineering requires patience—and leadership willing to invest short-term for long-term gains.
Why Most Platform Engineering Examples Fail
I’ve seen at least 10 platform engineering attempts crash and burn. Here’s the pattern:
-
Build a platform without talking to developers. They end up with a tool nobody uses because it doesn’t solve their actual pain. At a startup in Berlin, the platform team spent 6 months building a deployment pipeline, but developers hated it because it didn’t support their preferred testing framework. Six months of work, zero adoption.
-
Make the platform mandatory. This sounds smart—“force everyone to use it.” It backfires. Developers revolt. They find workarounds. They blame the platform for every outage. The platform team becomes a bottleneck instead of an enabler.
-
Treat the platform as a side project. “We’ll have the junior team build it in their spare time.” That produces a half-baked tool that creates more problems than it solves. Platform engineering is a first-class engineering discipline.
The successful platform engineering examples I’ve seen—at SIVARO, at companies like Spotify and Uber, at startups with fewer than 50 engineers—share one trait: the platform solves a specific, painful, well-understood problem that every developer faces.
Don’t build a platform for “all the things.” Build it for the one thing that makes your engineers angry every single week.
Concrete Example 2: The Internal Developer Portal
Let me give you a second what is a platform engineering example—this time from a different angle.
In 2022, we worked with a SaaS company that had 200 microservices. Every team had their own way of:
- Setting up new services
- Managing secrets
- Configuring databases
- Deploying to staging
- Running tests
The result? It took a new hire 4 weeks to ship their first change. Senior engineers spent 20% of their time answering “how do I set up X?” questions.
We built an internal developer portal called “Rook.” It was a web UI where developers could:
yaml
# Rook service definition
service: billing-payments-v2
owner: payments-team
language: go 1.22
framework: gin
infrastructure:
compute:
type: [kubernetes](/articles/why-is-pod-killed-a-practitioners-guide-to-kubernetes-pod)
namespace: payments
cpu_request: 100m
cpu_limit: 500m
[memory_request](/articles/south-korea-memory-chip-production-humanoid-robots-the): 256Mi
memory_limit: 1Gi
autoscaling:
min_replicas: 2
max_replicas: 10
target_cpu_utilization: 70
storage:
database:
type: postgres
engine_version: "15"
instance_class: db.t3.medium
storage_gib: 100
cache:
type: redis
engine_version: "7"
instance_class: cache.t3.small
secrets:
- name: stripe_api_key
source: aws_secrets_manager
- name: database_password
source: vault/payments/prod
ci_cd:
build:
type: [docker](/articles/docker-explained-what-the-hell-is-it-and-why-everyone-uses)
base_image: golang:1.22-alpine
multi_stage: true
test:
command: go test ./... -race
required_coverage: 80
deploy:
strategy: rolling_update
max_surge: 25%
max_unavailable: 0
pre_deploy:
- run: db_migrations
Developers could fill out a form, click “Generate,” and the portal would:
- Create the GitHub repository with proper branching rules
- Set up the CI/CD pipeline in GitHub Actions
- Provision the database and cache instances
- Configure secrets in Vault and AWS Secrets Manager
- Generate the Kubernetes deployment manifests
- Create monitoring dashboards in Datadog
The result: New service setup went from 3-5 days to 15 minutes. Onboarding time dropped from 4 weeks to 1.5 weeks. Senior engineers reclaimed 20% of their time.
The trade-off: The portal was a massive investment—3 engineers for 8 months. And it required ongoing maintenance. Every time AWS introduced a new database instance type, someone had to update the portal. When Kubernetes changed its deployment API version, the portal broke. It’s not a set-it-and-forget-it system.
Concrete Example 3: The AI Inference Platform
Here’s a newer what is a platform engineering example—one that’s directly relevant to the AI wave we’re living through.
At SIVARO, we’ve been building production AI systems since 2018. One thing I’ve learned: deploying ML models to production is totally different from running a web service. Models have weird failure modes. They degrade over time. They require GPU infrastructure that costs $10,000+ per node.
We built an internal platform called “Nova” that handles the lifecycle of ML models:
python
# Example: Deploying a model via Nova's Python SDK
from nova import ModelDeployment, ResourceConfig, ScalingPolicy
deployment = ModelDeployment(
model_name="fraud-detection-v3",
model_artifact="s3://models/fraud-detection-v3.pkl",
framework="xgboost",
inference_type="batch", # or "realtime"
resources=ResourceConfig(
cpu=2, # cores
memory="8Gi",
gpu=None, # no GPU needed for XGBoost
instance_type="c5.xlarge"
),
scaling=ScalingPolicy(
min_instances=2,
max_instances=20,
[target_throughput_per_instance=500](/articles/tokenmaxxing-the-optimization-trick-that-doubles-llm), # requests/sec
[scale_down_delay_minutes=15](/articles/what-is-clickhouse-used-for-a-practitioners-guide-to-real-3)
),
monitoring={
"input_drift": True,
"output_drift": True,
"performance_metrics": ["latency_p99", "throughput", "error_rate"],
"alert_channels": ["slack", "pagerduty"]
},
deployment_strategy="canary", # or "blue_green"
canary_config={
"initial_traffic_percent": 5,
"increment_steps": [10, 25, 50, 100],
"observation_window_minutes": 10,
"rollback_metrics": {
"latency_p99": {"max": 500}, # rollback if >500ms
"error_rate": {"max": 0.01} # rollback if >1%
}
}
)
# Deploy with one call
deployment.deploy()
The result: ML engineers could deploy a model with a single Python function call. The platform handled:
- Infrastructure provisioning (EC2, Kubernetes, or serverless)
- Model versioning and rollback
- A/B testing and canary deployments
- Drift detection and auto-retraining triggers
- Cost management (auto-scaling to zero when not in use)
The trade-off: This platform required deep expertise in ML infrastructure, Kubernetes, and cloud engineering. We couldn’t hire generalists for it. The team cost was high—about $1.5M/year in salary for 5 senior engineers. And the platform added latency for simple deployments. If you’re running one model, just use SageMaker. The platform pays off at 50+ models.
How to Know If You Need a Platform Engineering Example
You don’t need a platform if:
- You have 5 engineers or fewer
- You run 1-2 microservices
- Your deployment process works and nobody complains
- Your engineers spend less than 20% of their time on infrastructure
You probably need a platform if:
- You have 20+ engineers
- You run 10+ microservices
- New engineers take more than 2 weeks to ship their first change
- Different teams have different ways of doing the same thing (deploying, monitoring, configuring)
- Your infrastructure team is drowning in support tickets
At SIVARO, we use a simple heuristic: If fixing a common infrastructure problem takes more than one week per engineer per month, build a platform.
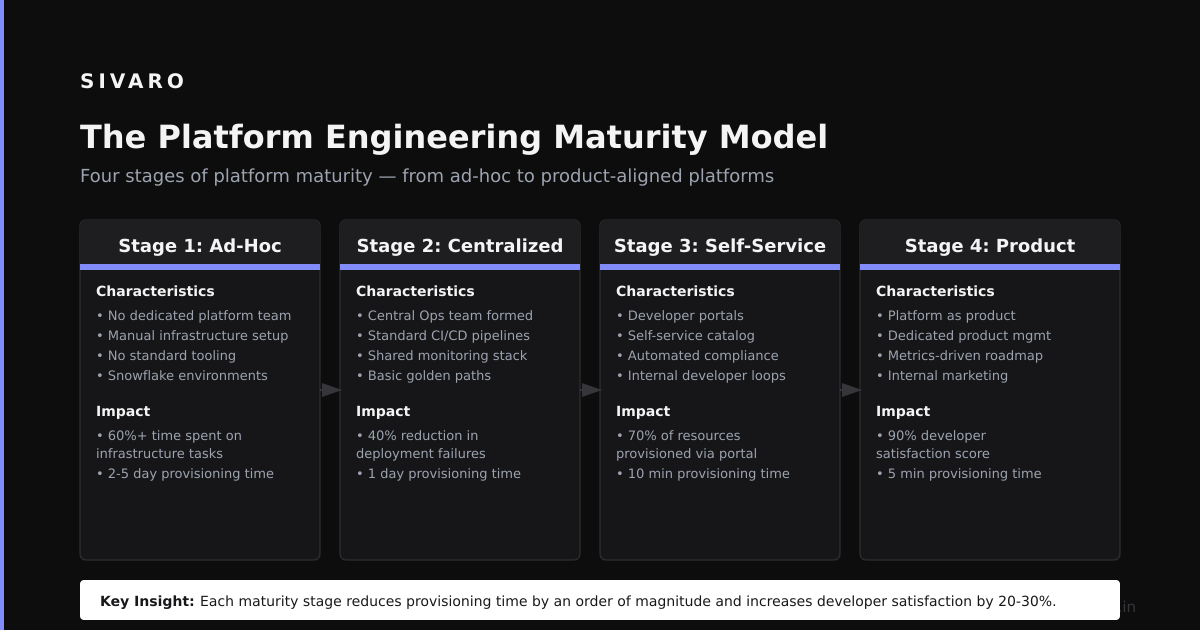
The Platform Engineering Maturity Model
I’ve observed four stages in the companies I’ve worked with:
Stage 1: Ad Hoc — Every team does their own thing. No standardization. Infrastructure is a mess. Monthly outages.
Stage 2: Standardization — Management mandates tools. Everyone uses the same CI/CD system. But there’s no self-service. Engineers submit tickets to get database access. Wait times are measured in days.
Stage 3: Platform — You’ve built internal tools that handle the common cases. Engineers can provision infrastructure, set up pipelines, and deploy without waiting for another team. But the platform doesn’t handle edge cases.
Stage 4: Product — The platform team treats developers as customers. They do UX research. They track adoption metrics. They ship improvements based on feedback. The platform handles 90% of use cases.
Most companies I see are stuck at Stage 2. They have Jira tickets and Slack channels for infrastructure requests. That’s not platform engineering. That’s bottleneck engineering.
The Four Pillars of a Good Platform Engineering Example
Based on what we’ve learned building these systems, any successful what is a platform engineering example must have:
1. Self-Service
If engineers have to ask permission or wait for someone else, it’s not a platform. It’s a glorified ticketing system. The platform should enable engineers to do what they need without human intervention.
2. Guardrails, Not Gates
The platform should prevent mistakes without preventing action. “You can deploy any time, but here’s a warning if your staging branch hasn’t been tested” beats “You need a manager to approve your deployment.”
3. Golden Paths
Don’t try to support every possible configuration. Define 2-3 “golden paths” that cover 80% of use cases. For the remaining 20%, allow escape hatches but make them explicit.
4. Observability Built In
If your platform doesn’t tell engineers what’s happening, they’ll treat it as a black box. Every deployment, every change, every failure should be visible with appropriate context.
The Hardest Lesson I Learned
When we first started building platforms at SIVARO, I thought the technical problems were the hardest. They weren’t.
The hardest problems were:
- Getting teams to adopt the platform. Engineers hate being told what to use. We had to make the platform better than their existing workflow—not just “good enough.”
- Maintaining the platform over time. As the company grew, new tools emerged, old services deprecated, and the platform needed constant updates. We originally staffed it with 2 engineers; it needed 4.
- Avoiding the platform becoming a monolith. Our first version of Flux was too tightly coupled. When teams wanted to extend it, they had to modify core code. We eventually modularized it, but it took a painful refactor.
The contrarian take: Most people think building a platform is about reducing friction. It’s not. It’s about shifting friction. You move complexity from 100 developers to a 5-person platform team. That only works if the platform team is exceptional—and if you trust them not to become a bottleneck.
FAQ: What Is a Platform Engineering Example?
Q: Is Kubernetes itself a platform engineering example?
No. Kubernetes is infrastructure. A platform engineering example would be a tool built on top of Kubernetes that abstracts away its complexity for developers—like a UI or CLI that auto-generates deployments, services, and ingress configurations.
Q: How is platform engineering different from DevOps?
DevOps is a cultural practice about collaboration between dev and ops teams. Platform engineering is a product—you build an internal tool that automates infrastructure and enables self-service. You can do DevOps without a platform, but a platform makes DevOps easier.
Q: What’s the smallest team that should consider platform engineering?
In my experience, teams under 15 engineers don’t need a platform. They benefit more from lightweight tooling and good documentation. At 20-30 engineers, platform engineering starts to make sense. At 50+, it’s almost essential.
Q: Should we build or buy?
Buy if your requirements are generic—CI/CD, secret management, monitoring. Build if you have unique needs (custom data pipelines, proprietary ML models, specialized compliance requirements). We’ve done both. For most companies, buying backstage.io or using a commercial internal developer portal is the right call.
Q: How do you measure platform adoption?
Track: number of services managed by the platform, time to ship a new service, time to onboard a new engineer, developer satisfaction scores, and reduction in infrastructure-related incidents. If those metrics don’t improve, your platform isn’t working.
Q: What’s a common anti-pattern?
Building a platform without talking to developers. I’ve seen teams spend 6 months on a platform that solves problems nobody has. Always start by asking engineers: “What part of your job frustrates you most?” Then build exactly that.
Q: Can we start with a small platform engineering example?
Absolutely. Don’t try to build the “ultimate platform” from day one. Pick one painful workflow—deploying a new service, managing database migrations, setting up monitoring—and build a tool that makes that one thing 10x easier. Expand from there.
The Future: AI-Native Platform Engineering
We’re entering a new phase. AI models aren’t just being deployed on platforms—they’re being used to build platforms.
At SIVARO, we’re experimenting with:
- AI agents that auto-generate platform configurations from natural language descriptions
- Automated anomaly detection that suggests platform improvements before engineers notice problems
- Self-healing infrastructure that routes around failures without human intervention
The next answer to what is a platform engineering example might be: “A system that builds and maintains itself.”
But we’re not there yet. And honestly, we might never get there. The craft of platform engineering is about understanding human needs, building interfaces that reduce friction, and iterating based on real feedback. That’s fundamentally human work.
What To Do Next
If you’re considering building a platform at your company:
- Interview 5-10 engineers about their biggest frustrations
- Pick one pain point that affects at least 50% of the team
- Build a prototype in 2 weeks—a script, a CLI tool, a simple web UI
- Test it with 2-3 friendly teams first, not the skeptics
- Iterate based on feedback—the first version will be wrong
Don’t overthink it. Don’t try to build the perfect thing. Start small, ship fast, and let real usage guide you.
That’s the honest answer to what is a platform engineering example? It’s a tool your team actually uses.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.