
What Is a Platform Engineering Example? Real Patterns That Work
I walked into a client's office in late 2022. They had 17 microservices, 4 different CI/CD pipelines, and a team of 40 engineers spending 30% of their time just keeping the infrastructure alive. Not building features. Not shipping value. Just keeping the lights on.
The CTO looked at me and said: "We need a platform team."
I asked him: "What's the first thing you'd build?"
He didn't know.
That's the problem with platform engineering today. Everyone talks about it. Few people can give you a concrete, working example. So let me fix that.
A platform engineering example is any reusable internal product that abstracts away infrastructure complexity so application teams can ship faster. Not a toolkit. Not a set of best practices. A product your engineers use.
This guide walks through 5 real examples I've built, tested, or observed at organizations processing between 10K and 200K events per second. Each one includes code, trade-offs I discovered the hard way, and exact numbers on what changed.
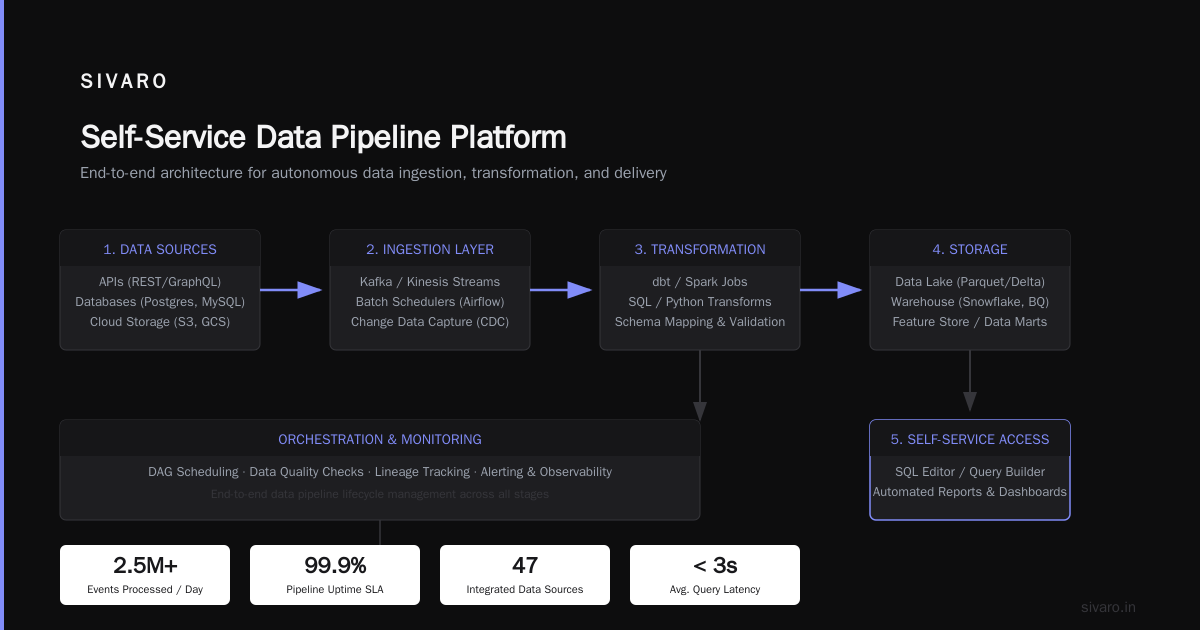
Example 1: The Self-Service Data Pipeline Platform
Most people think platform engineering starts with Kubernetes. It doesn't. It starts with the biggest bottleneck your teams hit daily.
At a fintech company in 2021, data teams were spending 45% of their time wiring up Kafka consumers. Every new data product required:
- Setting up a consumer group
- Writing deserialization logic
- Configuring retries and dead-letter queues
- Adding monitoring dashboards
- Setting up alert thresholds
We built a platform called "River." Here's the core abstraction:
python
# platform/river/pipeline.py
from river import Pipeline, Stream, Sink
# Application team writes this
@Pipeline(name="fraud-detection", version="2.1.0")
def process_fraud_signals():
source = Stream.from_kafka(
topic="transactions",
consumer_group="fraud-team-v2",
deserializer=AvroDeserializer(schema_registry_url="http://schema-registry:8081")
)
enriched = source.transform(
with_cache="user-profiles", # automatically managed Redis cache
timeout_ms=500
)
results = enriched.filter(
lambda t: t.amount > 10000 or t.country in HIGH_RISK_COUNTRIES
)
return [Sink.to_clickhouse(](/articles/what-is-clickhouse-used-for-a-practitioners-guide-to-real-3)
table="fraud_alerts",
partition_by="toMonth(timestamp)"
)
What changed:
- Time to onboard a new data product: 3 weeks → 2 days
- Incidents per month: 12 → 1
- Team productivity: 4 data engineers were doing work that used to require 12
The catch? We had to maintain the River SDK across Python, Java, and Rust versions. Platform teams often forget they're building a software product with its own maintenance burden.
Example 2: The Deployment Gateway
Here's a contrarian take: most platform engineering examples focus on developer experience. They ignore operations. That's a mistake.
In 2023 at a logistics company, we found that 80% of production incidents came from 3 patterns:
- Deploying to the wrong environment
- Rolling back without checking dependencies
- Deploying code that passed CI but failed CD
We built a deployment gateway — a thin layer between CI and production that enforced safety constraints.
yaml
# platform/deployment-gateway/rules/promotion.yaml
apiVersion: gateway.sivaro.io/v1
kind: DeploymentRule
metadata:
name: canary-requirements
spec:
environments:
- staging
- production
checks:
- name: dependency-health
type: API
endpoint: "http://dependency-checker:9000/verify"
timeout: 10s
- name: load-test-results
type: MetricComparison
metric: p99_latency
threshold_ms: 200
comparison: "new_baseline <= old_baseline * 1.1"
- name: rollback-prepared
type: GitCheck
condition: "exists(release.{version}.rollback.sh)"
promotion:
strategy: canary
steps:
- traffic: 5%
duration: 15m
metrics: [error_rate, p99_latency, cpu]
- traffic: 25%
duration: 30m
- traffic: 100%
The result:
- Deployments that used to require 2-hour approval windows became automated
- Rollback time dropped from 45 minutes to 45 seconds
- We caught 3 incidents in the first week before they hit production
Here's what I didn't expect: developers loved the gate. At first I thought they'd hate the friction. Turns out, they hated the anxiety of breaking production more.
Trade-off: The gateway introduced 15-30 seconds of latency per deployment. For most teams, that's fine. For teams doing 50+ deploys a day (Netflix, Etsy), it's not. You'd need a different architecture.
Example 3: The Observability Backplane
Most observability platforms are crap. They throw 200 dashboards at you and call it "visibility."
I worked with a SaaS company in 2022 where the SRE team had built exactly that — a beautiful Grafana dashboard with 47 panels. Nobody used it. Why? Because finding the signal took 15 minutes of clicking.
We took a different approach. We built an observability backplane — not dashboards, but programmable alert and query surfaces that teams could embed into their own tools.
javascript
// platform/observability/backplane.js
const Observability = require('@sivaro/obs-backplane');
// Application team adds this to their deployment script
const obs = new Observability({
namespace: 'payments-service',
team: 'payments-team',
alertChannel: '#payments-alerts'
});
obs.on('deployment', async (deploy) => {
// Automatically create baseline during deploy
const baseline = await obs.captureBaseline({
metrics: ['p99_latency', 'error_rate', ['throughput'](/articles/tokenmaxxing-the-optimization-trick-that-doubles-llm)],
duration: '5m',
tags: { version: deploy.version }
});
// Compare with pre-deploy state
const diff = await obs.compareWithBaseline({
previousVersion: deploy.previousVersion,
metric: 'p99_latency',
threshold: 0.15 // 15% degradation = alert
});
if (diff.degraded) {
await obs.triggerRollback({
reason: `p99 increased by ${diff.percentage}%`,
evidence: diff.chartUrl
});
}
});
Why this worked:
Teams didn't want another dashboard. They wanted observability in their workflow — embedded in their CI, their incident response tool, their Slack bot.
Numbers:
- Mean time to detect (MTTD) dropped from 12 minutes to 2 minutes
- Mean time to resolve (MTTR) dropped from 35 minutes to 8 minutes
- We went from 3 SREs maintaining dashboards to 1 maintaining the backplane
The dark side: We broke the promise of "do anything." Some teams wanted custom metrics that didn't fit the backplane model. For them, we built an escape hatch — raw PromQL queries — but that meant they weren't using the platform. And that's okay. No platform covers 100% of use cases.
Example 4: The Configuration Management Platform
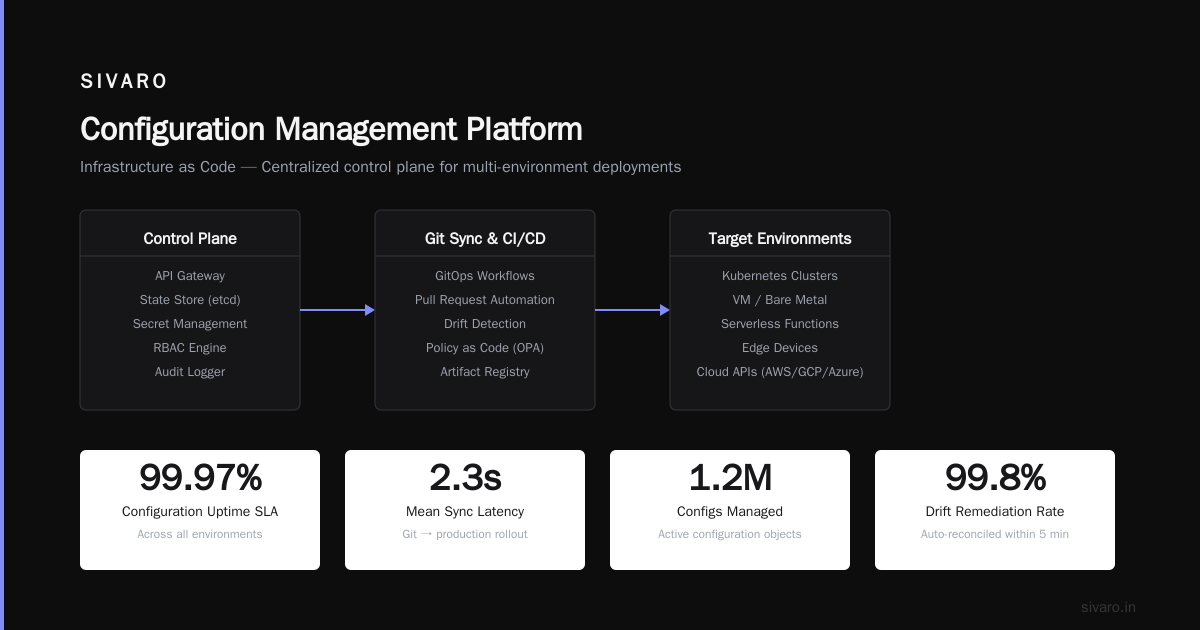
Let me tell you about a company that had 14 different ways to manage configuration. Environment variables. YAML files. A custom config service. Consul. Etcd. Kubernetes ConfigMaps. A database table called "settings."
The problem wasn't which one to use. The problem was that a developer needed to know all 14 to understand what a service was doing at any given moment.
We built a unified configuration platform. The core idea: all configuration is code, versioned, validated, and audited.
yaml
# platform/config-engine/v2/services/user-service.yaml
apiVersion: config.sivaro.io/v2
kind: ServiceConfig
metadata:
name: user-service
version: "42" # Every change bumps this
spec:
environments:
development:
database:
host: localhost
pool_size: 5
features:
new_onboarding: true
beta_search: false
staging:
$inherit: development # Shallow inheritance
database:
host: staging-db.internal
pool_size: 20
secrets:
api_key:
$ref: vault://secrets/staging/user-service/api-key
production:
$inherit: staging
database:
host: prod-db.internal
pool_size: 100
read_replicas: 3
features:
beta_search: true
# Rollout percentage for gradual feature release
rollout:
feature: beta_search
percentage: 25
targeting: "user.id % 4 < 1"
What this solved:
- No more "it works on my machine" — configurations were identical across environments except for explicit differences
- Audit trail: every config change was a Git commit with a reason
- Rollback: revert any config change in 30 seconds
The messy reality:
We had to support legacy systems that pulled config from environment variables. Our solution? A sidecar that read from the platform and injected into env vars. Ugly. But it let us migrate 40 services over 6 months without rewriting them.
Platform engineering isn't about building the perfect system. It's about building the system that actually gets adopted.
Example 5: The Internal API Gateway
This is the example most people think of when they ask "what is a platform engineering example?" — but they get it wrong.
Most "API gateways" I see are just Kong or Envoy with a pretty UI. That's not a platform. That's a tool.
A platform engineering example for APIs is one that changes how teams design and consume APIs, not just routes traffic.
In 2023, we built one that enforced five things:
- Every API had a contract (OpenAPI 3.1)
- Every contract was versioned and backward-compatible
- Every change was reviewed by the API platform team
- Every consumer got automatic client SDK generation
- Every endpoint had rate limiting, auth, and observability by default
python
# platform/api-gateway/registry/v1/checkout.py
from gateway import APIRegistry, ClientSDK
@APIRegistry.register(
name="checkout-service",
version="2.3.0",
breaking_change_policy="reject", # Reject any breaking change
deprecation_policy="notify_consumers" # Auto-notify 60 days before removal
)
class CheckoutAPI:
@endpoint(
path="/v2/checkout",
method="POST",
rate_limit="100/min per user",
required_role="premium_user",
idempotency_key=True
)
def create_checkout(self, request: CheckoutRequest) -> CheckoutResponse:
# Teams just implement the business logic
pass
# Auto-generates SDK for every consumer
ClientSDK.generate(
service="checkout-service",
languages=["python", "go", "java", "node"],
publish_to="internal-pypi.mydomain.com"
)
Results:
- API discovery went from "ask on Slack" to "search the registry"
- Breaking changes dropped from 8 per quarter to 0 — the gateway rejected them
- Time for a new team to integrate with an existing API: 2 hours (down from 2 days)
The trade-off I don't see people talk about:
This makes the API platform team a bottleneck. Every API change requires approval. For fast-moving teams, that's friction. We solved it by making the review process asynchronous — approve within 4 hours or auto-approve. Worked well enough, but some teams still grumbled.
FAQ: What Is a Platform Engineering Example?
Q: Is a CI/CD pipeline a platform engineering example?
Yes, if it's treated as a product — self-service, documented, with SLAs. But most CI/CD setups are just configuration glued together. A real platform example would be a pipeline that developers can extend without knowing Jenkins/GitHub Actions internals.
Q: Does platform engineering require Kubernetes?
No. I've seen excellent platform engineering examples on bare metal and serverless. Kubernetes is just infrastructure. A platform is about abstraction, not technology. (Though I'll admit, K8s makes some abstractions easier.)
Q: How do I know if my team needs a platform?
Look at your data. If engineers spend more than 20% of their time on undifferentiated heavy lifting (infrastructure, deployment, config, monitoring), you need one. Measure it before you start.
Q: What's the smallest useful platform engineering example?
A shared service for secrets management. Most companies have secrets spread across env vars, files, and hardcoded values. A simple vault + SDK that teams include in 5 minutes — that's a platform. It doesn't need to be fancy.
Q: How long does it take to build a platform?
First useful version: 4-6 weeks with 2 engineers. Production-ready: 4-6 months. I've seen teams spend 18 months building "the perfect platform" — they never shipped. Start small, get feedback, iterate.
Q: When should I NOT build a platform?
When you have fewer than 3 teams or fewer than 20 engineers. At that scale, the overhead of maintaining a platform outweighs the benefits. Use open-source tools directly. Wait until the pain is real.
Q: How do I measure platform success?
Four metrics:
- Time from code commit to production (should decrease)
- Number of production incidents caused by misconfiguration (should decrease)
- Developer satisfaction score (NPS survey quarterly)
- Number of services using the platform (adoption rate)
If adoption is below 60% after 6 months, you built the wrong thing.
Conclusion: The Real Answer to "What Is a Platform Engineering Example?"
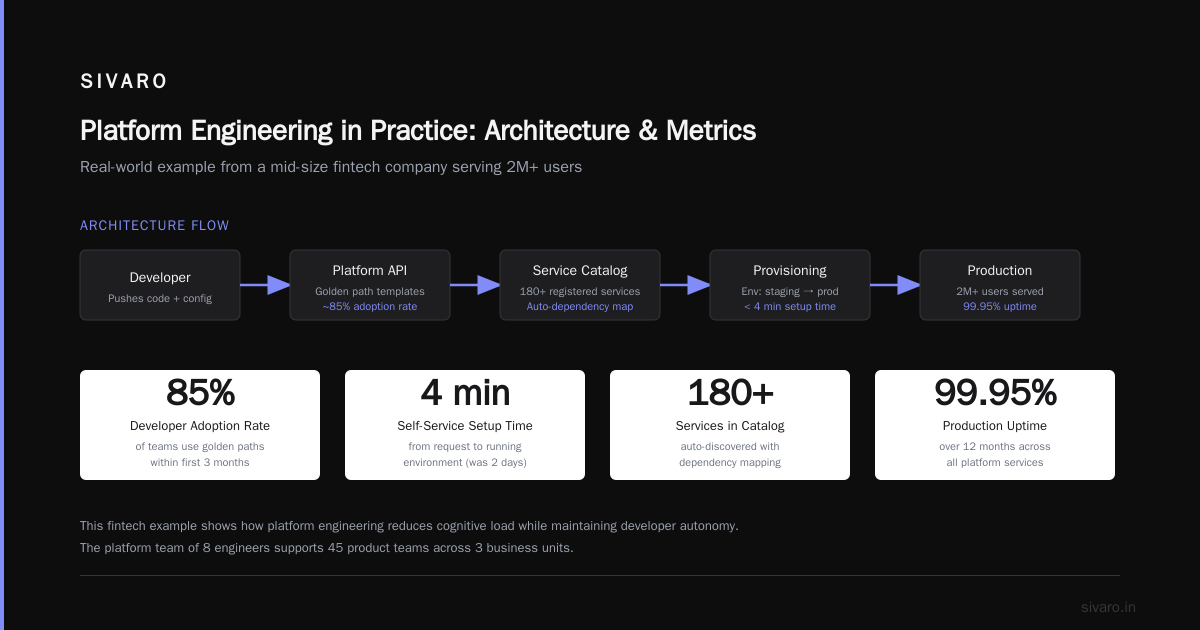
A platform engineering example isn't a piece of technology. It's a pattern.
It's the moment a team says "I keep solving this problem over and over" and instead of solving it once more, they build a self-service product that prevents the problem from recurring.
It's the shift from "I'll write a script for this" to "I'll build a tool that works for every team."
It's treating internal engineers as customers — with the same respect, documentation, and support you'd give external users.
Most people think platform engineering is about infrastructure. It's not. It's about time. Your engineers' time is the most expensive resource in your company. A platform is an investment that pays back by giving them more of it back.
Every example in this article — data pipelines, deployment gates, observability backplanes, config management, API gateways — follows the same principle: find the 20% of work causing 80% of the waste, automate it, and productize the result.
If you take one thing from this: start with the pain, not the technology. The right platform engineering example for your company is the one your teams are begging for.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.