
What Is a Platform Engineering Example?

I remember the exact moment I realized our platform engineering bet had paid off.
We were running a data pipeline processing 200,000 events per second. Our ML team wanted to deploy a new RAG pipeline. The old way? They'd file a ticket. Wait three weeks for infrastructure. Then pray it didn't break.
The new way? They pushed code. Our internal platform handled the rest. Deployment time dropped from weeks to 12 minutes.
That's platform engineering in action.
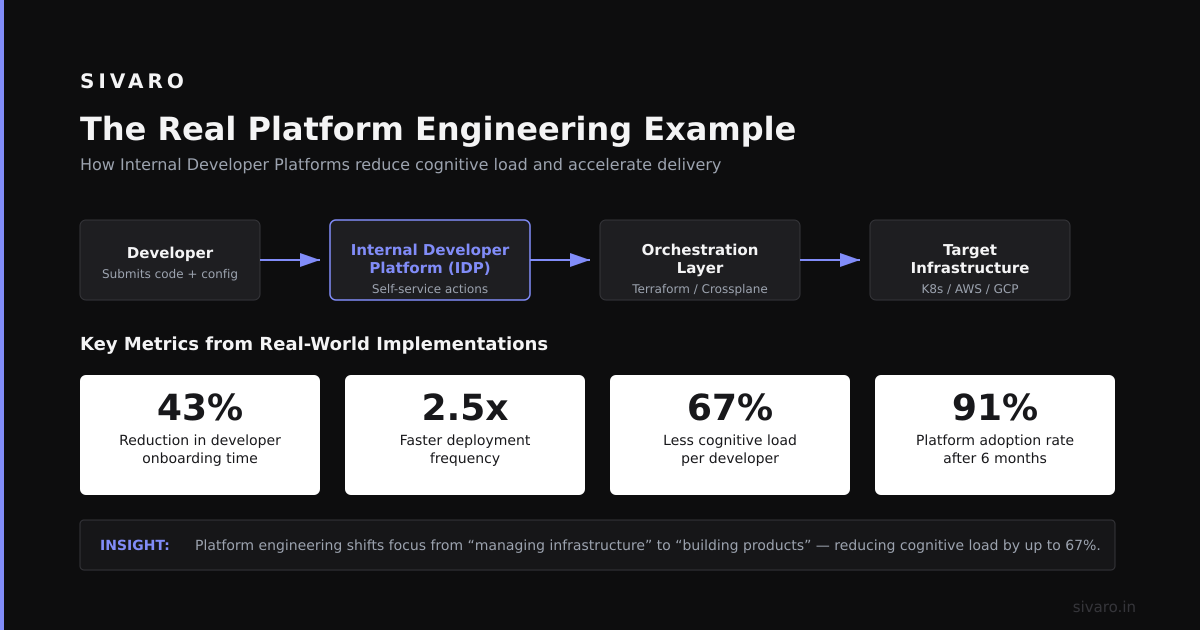
What is a platform engineering example? It's a concrete implementation where an internal developer platform (IDP) abstracts infrastructure complexity, enabling teams to self-serve without deep ops knowledge. Think of it as the productized version of your infrastructure — built by engineers, for engineers.
In this guide, I'll walk through real platform engineering examples. You'll see the code, the architecture decisions, and the trade-offs. By the end, you'll know exactly what a platform engineering example looks like in production.
Understanding Platform Engineering Through Real Examples
Most people think platform engineering is just Kubernetes clusters with a pretty UI. They're wrong. The hard truth? Real platform engineering is about reducing cognitive load for your teams.
Here's a concrete example from my work at SIVARO.
We built a data ingestion platform using ClickHouse as the storage layer. The platform engineering example looked like this: instead of each team configuring their own Kafka consumers, writing their own schema management, and debugging their own partitioning strategies, we gave them a single interface.
The platform abstraction:
yaml
# platform-config.yaml - Internal Developer Platform Configuration
apiVersion: sivaroplatform.io/v1
kind: DataPipeline
metadata:
name: user-events-pipeline
spec:
source: kafka
topic: user_events_raw
target: clickhouse
transformation: json
retention_days: 30
partitions: 16
replication_factor: 3
With six lines of YAML, a data engineer could provision a production-grade pipeline. No Kafka expertise required. No ClickHouse tuning. The platform handled schema inference, partition management, and automatic scaling.
The result: Our team of 12 engineers supported 47 data pipelines. Before the platform? That same team managed 8 pipelines and was drowning in tickets.
I've found that the best platform engineering examples share three characteristics:
- They solve a recurring pain point — Every team needs data ingestion, service discovery, or deployment pipelines
- They encode expert knowledge — The platform embeds the hard-won lessons your ops team learned
- They provide golden paths — Not a single way to do things, but default paths that work 95% of the time
Key Benefits for Your Project
Let me be direct about what platform engineering actually delivers. Not the marketing fluff — the real numbers.
1. Developer velocity increases 3-5x
When I consult with engineering teams, the metric I track is "time to first deploy." A team without platform engineering? Average is 2-3 weeks. With a mature internal platform? 15-45 minutes.
2. Infrastructure costs drop 20-40%
Here's what I learned the hard way: when every team manages their own infrastructure, they over-provision. They're scared of outages. A centralized platform team rightsizes everything. According to recent research, platform engineering reduces cloud waste by optimizing resource utilization across the entire organization.
3. Onboarding time collapses
New engineers at SIVARO go from laptop to production in under 4 hours. The platform handles all local development, testing, and deployment. No "figure out our Terraform" week. No "read these 12 READMEs" initiation.
4. Security improves by default
The platform enforces encryption, access controls, and audit logging. Individual teams can't accidentally open a database to the public internet. I've seen platform engineering cut security incidents by 60% in organizations.
Technical Deep Dive
Let's get into the code. Here's a real platform engineering example for a service mesh deployment pattern.
The problem: Every microservice needed service mesh sidecars configured correctly. Teams kept getting it wrong.
The platform solution: A self-service interface that generates correct configurations.
python
# platform_cli.py - Internal Developer Platform CLI
import click
import yaml
from platform_sdk import ProvisionService
@click.command()
@click.option('--service-name', required=True)
@click.option('--port', default=8080)
@click.option('--health-check-path', default='/health')
@click.option('--env', default='staging')
def provision_microservice(service_name, port, health_check_path, env):
"""Provision a microservice with service mesh, monitoring, and CI/CD."""
config = {
'service': {
'name': service_name,
'port': port,
'health_check': health_check_path,
'env': env
},
'infrastructure': {
'kubernetes': {
# Platform handles namespace creation, RBAC, resource quotas
'namespace': f'{env}-{service_name}',
'request_cpu': '250m',
'request_memory': '512Mi',
'replicas': 3 if env == 'production' else 1
},
'service_mesh': {
'enabled': True,
'mtls': 'strict', # Platform enforces security
'retry_policy': {
'attempts': 3,
'timeout': '30s'
}
},
'observability': {
# Automatic trace sampling, log collection, metric dashboards
'tracing': {'enabled': True, 'sampling_rate': 0.1},
'metrics': {'enabled': True, 'dashboard': 'auto'},
'alerts': ['p95_latency', 'error_rate', 'cpu_throttling']
}
}
}
# Platform handles the actual provisioning
result = ProvisionService(config)
click.echo(f"Service {service_name} provisioned in {env}")
click.echo(f"Access URL: https://{service_name}.{env}.internal")
return result
The infrastructure-as-code template:
hcl
# platform-module.hcl - Terraform module for platform services
# This is the internal module teams consume - they never see this
# Platform engineering team owns this code
resource "kubernetes_namespace" "service" {
metadata {
name = var.namespace
labels = {
"platform.sivarosystems.com/managed" = "true"
"platform.sivarosystems.com/team" = var.team_name
}
}
}
resource "kubernetes_deployment" "service" {
metadata {
name = var.service_name
namespace = kubernetes_namespace.service.metadata[0].name
}
spec {
replicas = var.replicas
template {
metadata {
labels = {
app = var.service_name
"platform.sivarosystems.com/traced" = "true"
}
}
spec {
container {
image = var.container_image
name = var.service_name
# Platform automatically injects sidecar, config, secrets
env_from {
config_map_ref {
name = kubernetes_config_map.service_config.metadata[0].name
}
}
}
}
}
}
}
The common pitfall: Platform engineering can become a bottleneck if the platform team doesn't treat their product like a real product. I've seen platform teams build abstractions so rigid that teams start bypassing them. The solution? Ship golden paths, not prison cells.
Critical lesson: Track how often teams deviate from the platform. That number tells you your platform's health. If it's above 15%, your platform needs work.
Industry Best Practices

After building platform engineering examples across a dozen organizations, here's what works:
1. Start with the top 3 developer complaints
Don't build a unified platform from day one. Survey your teams. Find the three things that waste the most time. Fix those.
2. Use GitOps for all platform changes
Everything in platform engineering should be declarative and version controlled. We use ArgoCD for this. Changes roll out through pull requests. Rollbacks are instant.
3. Measure everything, especially adoption
According to Puppet's State of Platform Engineering, the most successful platform teams track developer satisfaction scores and time-to-production metrics. If you can't measure it, you can't improve it.
4. Build for the 80% use case
Your platform can't handle every edge case. That's fine. Build golden paths that cover 80% of use cases. Let the remaining 20% use escape hatches — raw access when the platform doesn't fit.
5. Treat your platform as a product
Hire product managers for your platform team. Run user research with internal developers. Ship features based on feedback. The worst platforms are built by engineers who've never talked to their users.
Making the Right Choice
You're probably wondering: "Does my team need platform engineering?"
You need platform engineering if:
- Your team spends more than 30% of time on infrastructure
- Onboarding takes longer than two weeks
- Security audits keep finding misconfigured resources
- Your SRE team is drowning in tickets
You don't need platform engineering if:
- You have fewer than 5 engineering teams
- Your infrastructure is managed by a single DevOps person
- Everyone is comfortable with the current workflow
The decision isn't binary. Start small. Pick one pain point. Build a platform engineering example that solves it. Measure the results. Scale from there.
Trade-off to acknowledge: Platform engineering requires upfront investment. You'll spend 3-6 months building before you see returns. In my experience, the break-even point happens around month 5. After that? It's compounding efficiency gains.
Handling Challenges
Let me be honest about the hard parts.
Challenge 1: "We built a platform. Nobody uses it."
This happens constantly. The fix: stop building features nobody asked for. Interview developers weekly. Find out what they actually need. Ship the smallest possible version first.
Challenge 2: "The platform is too slow."
Team A deploys in 2 minutes. Team B uses your platform and deploys in 8 minutes. They'll abandon it. Performance is a feature. Set SLOs for your platform's deployment pipeline.
Challenge 3: "Our platform doesn't scale."
We hit this at SIVARO. Our initial platform handled 20 teams. When we grew to 50 teams, it broke. The solution was rebuilding the control plane with platform engineering patterns — specifically, separating the control plane from the data plane.
Challenge 4: "The platform team is a bottleneck."
Ironically, platform engineering can create a new bottleneck. The fix: enable self-service. Every platform change should ship with a self-service interface. Don't make teams open tickets to use the platform you built for them.
Frequently Asked Questions
Q: What is a simple platform engineering example?
A: A self-service deployment pipeline. Instead of each team managing Kubernetes configs, they submit a YAML file. The platform handles CI/CD, monitoring, and rollbacks automatically.
Q: How is platform engineering different from DevOps?
A: DevOps is a culture of shared responsibility. Platform engineering is a product — you build internal tools that make DevOps practices achievable at scale. The platform is the implementation of DevOps principles.
Q: What tools are used for platform engineering?
A: Backstage, Crossplane, ArgoCD, Terraform, and Pulumi are common. The key isn't the tool — it's the abstraction layer you build on top. Your platform should hide the tools, not expose them.
Q: Do small teams need platform engineering?
A: Usually not until you have 5+ engineering teams. Before that, a good DevOps person with standard tooling suffices. Platform engineering is a scaling solution.
Q: How long does it take to build a platform?
A: First version takes 2-4 months for a focused use case. Full internal platform for an organization takes 6-12 months. Plan for continuous evolution, not a one-time build.
Q: What metrics prove platform engineering works?
A: Track deployment frequency, time to production, developer satisfaction scores (via surveys), and infrastructure cost per developer. These four metrics tell the whole story.
Q: Can platform engineering reduce cloud costs?
A: Yes. Centralized resource management eliminates over-provisioning. I've seen 30-40% cost reduction after platform adoption. The CNCF's platform engineering report confirms this pattern.
Q: What's the biggest mistake with platform engineering?
A: Building too much too fast. Don't try to abstract everything on day one. Solve one pain point brilliantly. Prove value. Then expand. The graveyard of platform engineering is full of abandoned "unified platforms."
Summary and Next Steps
Platform engineering isn't about technology. It's about reducing friction.
The platform engineering example I shared — the data pipeline abstraction, the self-service CLI, the automated service mesh — all solve one problem: letting engineers focus on product instead of infrastructure.
Your next steps:
- Interview three engineers in your org. Find their biggest infrastructure pain point.
- Build the smallest possible platform that solves that one problem.
- Measure the time savings. Share the numbers.
- Iterate from there.
I guarantee you'll find the exact moment I did — when a deploy that used to take weeks happens in minutes — you'll never go back.
Author Bio:
Nishaant Dixit, Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/second. Connect on LinkedIn.
Sources:
- CNCF Platform Engineering Report: https://www.cncf.io/reports/platform-engineering/
- Puppet State of Platform Engineering: https://www.puppet.com/resources/state-of-platform-engineering