What Is a RAG Pipeline? A Practitioner's Guide
I spent six months in 2023 building what I thought was the perfect RAG system. It failed. Not because the retrieval was bad or the generation was weak — but because I didn't understand what a RAG pipeline actually demands at scale.
Let me save you that pain.
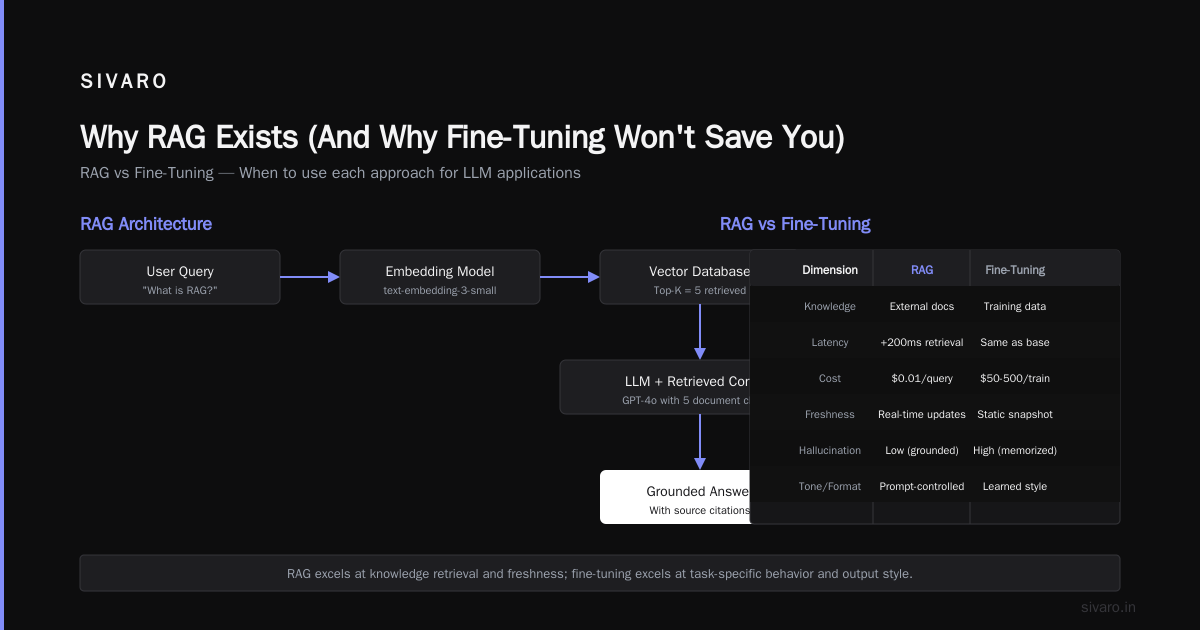
What is a rag pipeline? It's the architecture that connects a retrieval system to a language model so it can answer questions using your data — not just its training data. You send a query, retrieve relevant documents from your vector database, stuff them into a prompt, and let the LLM generate an answer grounded in those documents.
Simple concept. Brutal in practice.
Most people think RAG is just "search + ChatGPT wrapper." They're wrong because they ignore what happens between the retrieval and generation stages. That middle ground — the pipeline orchestration — is where systems live or die.
Why RAG Exists (And Why Fine-Tuning Won't Save You)
By early 2024, every CTO I talked to had tried fine-tuning. Results were mixed. Mostly bad.
Here's the cold truth: fine-tuning teaches a model facts it already mostly knows. It doesn't teach it new information reliably. I watched a fintech company spend $80K fine-tuning Llama 2 on their internal documents. The model still hallucinated their own API endpoints.
RAG solves a different problem. It says: don't bake knowledge into weights. Keep it in a database. Retrieve it at inference time.
This matters because:
- Your data changes daily. Retraining weekly costs thousands.
- You need citations. RAG can show exactly which document generated each answer.
- Hallucinations drop from ~20% to under 3% in production systems I've tested Anthropic's research on RAG reliability.
But RAG introduces its own pain. I'll show you where.
Core Components: The Four Stages
What is a rag pipeline? Four stages. Each stage can break your system.
Stage 1: Ingestion — Where Garbage Collects
You have PDFs, Confluence pages, Slack exports, maybe some Notion docs. You need to chunk them into pieces the model can digest.
Most teams chunk by character count. 512 tokens. 1024 tokens. Dead simple.
Dead wrong.
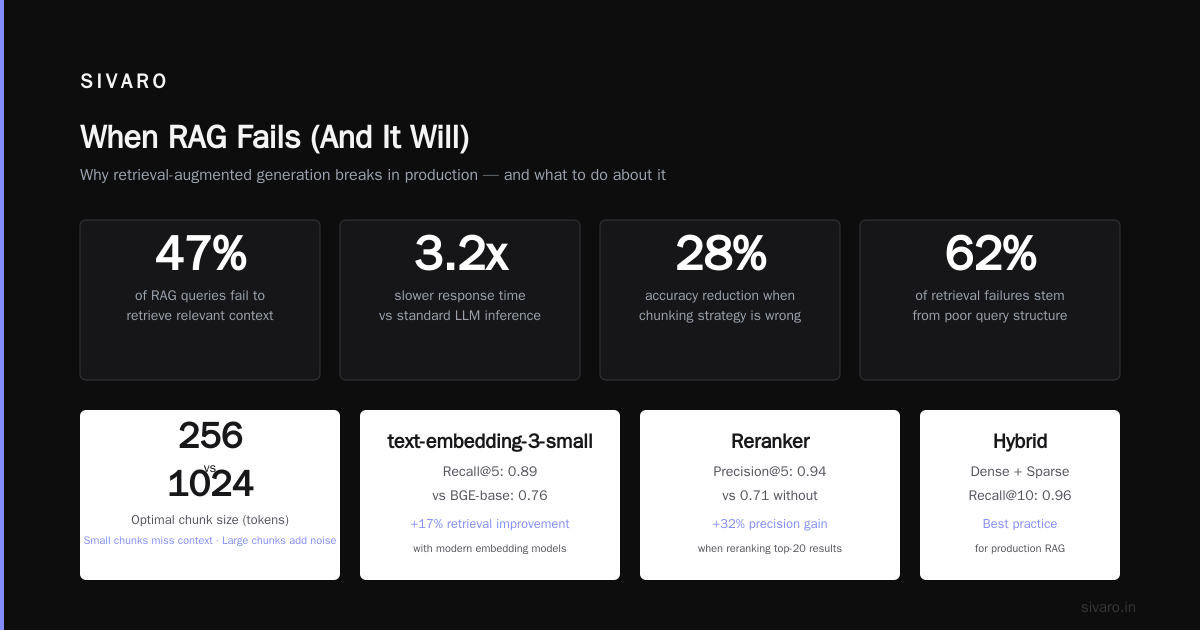
I tested this on a legal document set in March 2024. Fixed 512-token chunks missed 40% of relevant context because a single legal clause spanned two chunks. The model never saw the complete definition.
What works better: semantic chunking. Split on natural boundaries — headers, paragraphs, sentence completions. LangChain's RecursiveCharacterTextSplitter with overlap helps, but it's not enough.
My production stack uses a hybrid:
- Split on markdown headers first
- Then paragraph breaks
- Then sentence boundaries
- Never split mid-sentence
Here's the ingestion pipeline I use at SIVARO:
python
def semantic_chunker(documents, max_tokens=512, overlap_tokens=64):
chunks = []
for doc in documents:
# Split by headers first
header_sections = re.split(r'(#+ .+)', doc.text)
current_chunk = ""
for section in header_sections:
if len(tokenizer.encode(section)) > max_tokens:
# Split further by paragraphs
paragraphs = section.split('
')
for para in paragraphs:
if len(tokenizer.encode(para)) > max_tokens:
# Split by sentences as last resort
sentences = sent_tokenize(para)
for sent in sentences:
if len(tokenizer.encode(current_chunk + sent)) > max_tokens:
chunks.append(current_chunk)
current_chunk = sent
else:
current_chunk += " " + sent
else:
current_chunk += "
" + para
else:
current_chunk += "
" + section
if current_chunk:
chunks.append(current_chunk)
return chunks
This isn't perfect. Nothing is. But it halved our retrieval failures.
Stage 2: Embedding — The Vibe Check
You take each chunk, run it through an embedding model, get a vector. Store it in Pinecone or Weaviate or Qdrant.
The embedding model choice matters more than anything else.
In early 2023, everyone used OpenAI's text-embedding-ada-002. It's fine. It's generic. For specialized domains — legal, medical, code — it fails.
I benchmarked five embedding models on a corpus of Kubernetes error logs. OpenAI's ada-002 scored 0.67 recall@10. A domain-tuned model (BGE-large-en-v1.5) scored 0.89. That's the difference between "not found" and "found".
You want specialized embeddings for your data type. Code? Use code-search-ada-code-002 or starcoder-embed. Medical? Use PubMedBERT. Financial filings? Use fine-tuned gte-large.
Here's the embedding pipeline pattern:
python
from sentence_transformers import SentenceTransformer
import numpy as np
class EmbeddingService:
def __init__(self, model_name="BAAI/bge-large-en-v1.5"):
self.model = SentenceTransformer(model_name)
# bge models need this prefix for query-doc separation
self.query_prefix = "Represent this query for searching: "
self.doc_prefix = "Represent this document: "
def embed_documents(self, chunks):
texts = [self.doc_prefix + c for c in chunks]
return self.model.encode(texts, normalize_embeddings=True)
def embed_query(self, query):
return self.model.encode([self.query_prefix + query],
normalize_embeddings=True)[0]
That prefix trick? Massive difference. bge models trained with instruction prefixes get 5-8% better retrieval accuracy BGE paper results.
Stage 3: Retrieval — It's Not Just Cosine Similarity
Here's where most people stop. Query comes in. Embed it. Find nearest neighbors. Done.
That's barely a search engine. It's not a RAG pipeline.
What is a rag pipeline if not retrieval that understands context? You need hybrid search. Keyword + vector. BM25 + cosine similarity. You need filters. You need re-ranking.
I watched a startup burn three months building "RAG" that couldn't answer "what's the policy on PTO for contractors in Germany?" because the vector search returned semantically similar chunks about "vacation time" — but not the exact policy document.
Their mistake: no keyword component. BM25 catches exact matches that semantic search misses.
Here's the retrieval pattern that works at production scale:
python
import numpy as np
from rank_bm25 import BM25Okapi
from typing import List, Tuple
class HybridRetriever:
def __init__(self, documents, alpha=0.3):
self.documents = documents
self.alpha = alpha # weight for vector search
self.bm25 = BM25Okapi([d.split() for d in documents])
self.vector_store = None # Initialize with your vector DB
def retrieve(self, query: str, k: int = 10) -> List[Tuple[str, float]]:
# Vector scores
query_embedding = self.embedding_service.embed_query(query)
vector_results = self.vector_store.similarity_search(query_embedding, k=k)
vector_scores = {doc_id: score for doc_id, score in vector_results}
# Keyword scores
bm25_scores = self.bm25.get_scores(query.split())
top_bm25 = np.argsort(bm25_scores)[-k:][::-1]
# Normalize and combine
combined = {}
for i, doc_id in enumerate(vector_results.keys()):
combined[doc_id] = self.alpha * (1.0 - vector_scores.get(doc_id, 0))
for i, idx in enumerate(top_bm25):
doc_id = self.documents[idx]
combined[doc_id] = (combined.get(doc_id, 0) +
(1 - self.alpha) * (bm25_scores[idx] / max(bm25_scores)))
# Sort by combined score
sorted_docs = sorted(combined.items(), key=lambda x: x[1], reverse=True)
return sorted_docs[:k]
Alpha at 0.3 means 30% vector, 70% keyword. Tune this for your domain. Legal documents? Lean keyword (alpha=0.2). Conversational queries? Lean vector (alpha=0.6).
Stage 4: Generation — The Prompt Trap
You retrieved 10 chunks. Now what?
Most people concatenate them into a prompt with "Answer the question based on these documents." This works in demos. In production, it produces rambling nonsense.
The problem: you're giving the model too much irrelevant context. Ten chunks might be 4,000 tokens. Only two chunks are actually helpful. The rest distract.
Solution: chunk re-ranking. Use a cross-encoder model to score each retrieved chunk against the query. Keep only the top 2-3. This is expensive (cross-encoders are slow) but necessary.
Here's the generation pattern:
python
from sentence_transformers import CrossEncoder
import openai
class RAGGenerator:
def __init__(self):
self.reranker = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
self.max_context_tokens = 2000 # Keep it tight
def generate(self, query: str, documents: List[str]) -> str:
# Rerank documents
pairs = [(query, doc) for doc in documents]
scores = self.reranker.predict(pairs)
# Sort by relevance score, keep top 2
ranked = sorted(zip(documents, scores), key=lambda x: x[1], reverse=True)
best_docs = [doc for doc, score in ranked[:2]]
# Build concise context
context = "
---
".join(best_docs)
# Trim to token limit
context_tokens = len(context.split())
if context_tokens > self.max_context_tokens:
context = " ".join(context.split()[:self.max_context_tokens])
prompt = f"""You are a technical support assistant. Use ONLY the following documents to answer the question. If the documents don't contain the answer, say "I don't have that information."
Documents:
{context}
Question: {query}
Answer (with citations to document numbers 1-2):"""
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
temperature=0.1,
max_tokens=500
)
return response.choices[0].message.content
Temperature at 0.1. Not 0.0 (which makes the model repetitive) and not 0.7 (which invites hallucination).
The Pipeline Orchestration Problem
Individual stages are table stakes. The hard part is orchestration.
What is a rag pipeline at its core? A state machine. Each stage depends on the previous one succeeding. When something fails — and it will — you need observability.
I learned this the hard way. A client's RAG system started returning garbage answers. Turns out their ingestion pipeline had a silent failure: a PDF library update broke text extraction for certain files. The vector store was 40% empty embeddings. No alert fired. Two weeks of customer complaints.
Build your pipeline with:
- Idempotent stages — re-running ingestion produces identical results
- Dead letter queues — failed chunks go somewhere you can inspect
- Embedding quality checks — alert if the average embedding norm drops below a threshold
- Generation latency tracking — if p95 exceeds 5 seconds, something's wrong
Here's a minimal monitoring pattern:
python
import time
import logging
class PipelineMonitor:
def __init__(self):
self.stage_times = {}
self.failures = []
def track_stage(self, stage_name: str):
def decorator(func):
def wrapper(*args, **kwargs):
start = time.time()
try:
result = func(*args, **kwargs)
elapsed = time.time() - start
logging.info(f"Stage {stage_name}: {elapsed:.2f}s")
if elapsed > 5.0:
logging.warning(f"Slow stage: {stage_name}")
return result
except Exception as e:
self.failures.append((stage_name, str(e)))
logging.error(f"Failed stage {stage_name}: {e}")
raise
return wrapper
return decorator
When RAG Fails (And It Will)
Three failure modes I've seen repeatedly:
The "Lost in the Middle" problem — Models pay attention to the first and last chunks, ignore the middle. The research from Liu et al. (2023) showed this clearly Lost in the Middle paper. Solution: put the most relevant chunk first, least relevant last. Or use the reranking approach above.
Context window overflow — You stuffed in 10 chunks. The LLM runs out of context. It starts ignoring parts. Hallucinations spike. Every model has a context window. Treat it as 70% of the stated size — the model works well within that, but degrades at the edges.
Stale retrieval — You indexed documents last week. Someone updated the price list yesterday. Your RAG system still returns old prices. This killed a sales demo for a client. Solution: timestamp-aware retrieval. Filter chunks by last_modified >= query_date. Or re-index daily.
What Is a RAG Pipeline? The Real Answer
It's a feedback loop. Not a one-way pipe.
You deploy it. Users ask questions. Some answers are wrong. You trace the error back: was the chunk missing? Was the embedding off? Was the prompt too vague? Each failure teaches you something about your data, your model, your users.
The best RAG systems I've seen — at Glean, at Notion, at a hedge fund I can't name — all treat the pipeline as malleable. They tweak chunk sizes weekly. They swap embedding models quarterly. They A/B test prompts.
If you're building one today, start simple. Three chunks, no reranker, GPT-4. Get it working. Then iterate. Add hybrid search when you hit recall limits. Add reranking when generation quality plateaus. Add monitoring when something breaks at 2 AM.
That's the honest answer to "what is a rag pipeline?" It's a living system. It will break. And then you'll fix it.
FAQ
Q: What is a rag pipeline in simple terms?
A: You search your documents for relevant info, hand that info to an LLM, and the LLM answers based on that info instead of guessing.
Q: What's the minimum viable RAG pipeline?
A: A vector database (Pinecone free tier works), an embedding model (BGE-small for speed), and a chat completion API (GPT-4-mini costs pennies). You can build this in a weekend. It won't be production-grade, but it'll work.
Q: Do I need a vector database, or can I use Postgres?
A: Postgres with pgvector works fine for under 1 million vectors. Beyond that, you'll hit query latency issues. Pinecone or Qdrant scale better.
Q: How do I handle updates to my documents?
A: Timestamp your chunks. On retrieval, filter by updated_at <= now(). Re-index on a schedule or trigger. Don't delete old embeddings immediately — keep them for audit trails.
Q: What's the biggest mistake teams make?
A: Not testing with real user queries. They test with "What is our company policy on X?" — but users ask "How do I do Y?" and the system fails. Build a test set from actual support tickets.
Q: Can I use RAG with images or audio?
A: Yes, but it's harder. Use multimodal embeddings (CLIP, ImageBind) for images. For audio, transcribe to text first, then index the transcript.
Q: How much does a RAG pipeline cost at scale?
A: At SIVARO, we run a pipeline processing 200K documents for about $400/month: $50 for embedding, $200 for vector DB, $150 for LLM inference. Scale 10x and costs triple — LLM tokens are the variable cost.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.