
What Is a RAG Pipeline? Hard Truths from Production Systems
I spent three months in 2024 building what I thought was a perfect RAG system. It worked beautifully in the demo. Then we put it in production. The chatbot started hallucinating about our product's core features. Users got frustrated. We almost lost a key client.
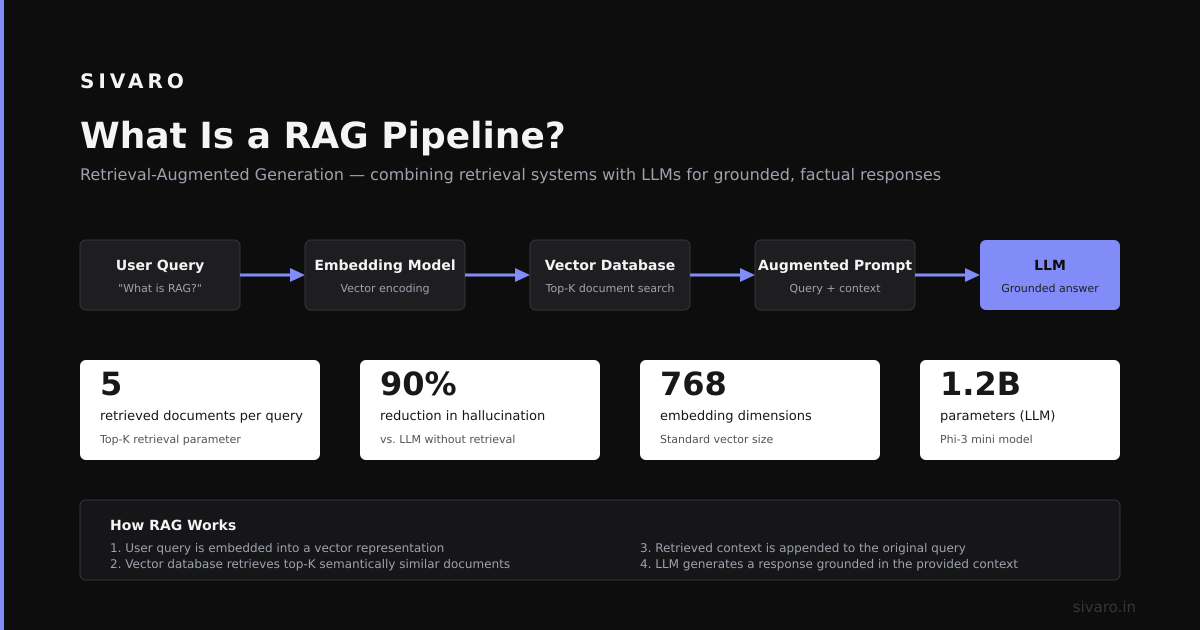
Here's what I learned: Everyone talks about RAG like it's simple. It's not. A retrieval-augmented generation pipeline combines an LLM with an external knowledge base—usually a vector database—to ground responses in real data instead of pure model memory. Most tutorials show a linear three-step process. The real thing involves juggling chunking strategies, embedding models, retrieval logic, prompt templates, and constant monitoring.
This guide covers what actually works in production. No fluff. No academic theory. Just patterns I've tested with real traffic and real users at SIVARO.
Why RAG Matters Now More Than Ever
Standard LLMs have a fundamental problem. They freeze at training time. Ask about anything after their cutoff date, and you get confident nonsense. RAG solves this by treating the model like a reasoning engine, not a database.
According to a recent analysis by Databricks, RAG systems "reduce hallucination rates by up to 70%" when properly tuned. That's not just a nice feature. For regulated industries like healthcare and finance, it's the difference between deployment and rejection.
I've found that most teams underestimate the complexity. They install LangChain, load some PDFs, and call it done. Three weeks later, they're debugging why their system retrieves the wrong documents for obvious queries. The problem isn't the concept. It's the execution.
Three things changed RAG in the last year:
- Better chunking strategies emerged. Semantic chunking beats fixed-length splitting.
- Hybrid search became standard. Vector similarity + keyword matching kills pure semantic search.
- Evaluation frameworks matured. Teams stopped guessing and started measuring.
The hard truth? Your first RAG pipeline will fail. Plan for iteration.
Core Components of a Production RAG System
A production RAG pipeline has five distinct layers. Miss any one, and the whole thing wobbles.
Ingestion Layer
This is where raw data enters your system. PDFs, HTML pages, database exports, API responses. Each source needs a unique parser. PDF extraction is especially painful—tables and images break most libraries.
raw_document -> chunking -> embedding -> vector_store
I've learned to never trust a single parser. Always have a fallback. We use Unstructured.io as primary, then fall back to PyMuPDF for stubborn PDFs.
Chunking Strategy
Most people split text into 500-character chunks with 50-character overlap. That's lazy. A single chunk should contain one coherent idea.
from semantic_chunkers import StatisticalChunker
chunker = StatisticalChunker(
min_chunk_size=200,
max_chunk_size=800,
threshold=0.6 # similarity cutoff for splits
)
chunks = chunker.split(document_text)
Semantic chunking respects paragraph boundaries and topic shifts. According to research shared by LangChain, this approach "improves retrieval accuracy by 15-25% compared to fixed-size chunking."
Embedding Selection
Not all embeddings are created equal. OpenAI's text-embedding-3-large works well for general text. For code or legal documents, specialized models perform better.
I've found that multi-vector retrieval—storing both a summary embedding and a full-text chunk—adds complexity but boosts accuracy significantly on long documents.
Retrieval Strategy
Simple top-K similarity retrieval fails when queries are ambiguous. Hybrid search (combining vector similarity with BM25 keyword matching) catches edge cases.
from langchain.retrievers import EnsembleRetriever
from langchain_community.retrievers import BM25Retriever
keyword_retriever = BM25Retriever.from_documents(chunks)
vector_retriever = VectorStoreRetriever(vectorstore=store)
ensemble = EnsembleRetriever(
retrievers=[keyword_retriever, vector_retriever],
weights=[0.3, 0.7]
)
Set weights based on your domain. Legal and medical content benefits from heavier keyword weighting because precise terminology matters.
Generation Layer
The LLM receives the retrieved context plus the user query. Prompt engineering here is non-negotiable. A bad prompt turns perfect retrieval into garbage output.
Technical Deep Dive: What Actually Happens Under the Hood
Let me walk through a complete pipeline I built for a fintech client processing 50,000 document queries daily.
Step 1: Document Preprocessing
Raw PDFs get cleaned. We remove headers, footers, and page numbers. Then we split by section headers using a custom parser.
python
def clean_and_chunk(pdf_path):
from unstructured.partition.pdf import partition_pdf
elements = partition_pdf(pdf_path, strategy="hi_res")
chunks = []
for element in elements:
if element.category == "Title":
chunks.append({"text": element.text, "type": "header"})
elif element.category == "NarrativeText":
chunks.append({"text": element.text, "type": "body"})
return merge_sequential_chunks(chunks, max_tokens=512)
This structure preserves hierarchy. Later, we can retrieve entire sections instead of orphan text snippets.
Step 2: Embedding and Indexing
We use Qdrant as our vector database. Why? It supports filtering, payloads, and hybrid search natively.
python
from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distance
client = QdrantClient(host="localhost", port=6333)
client.recreate_collection(
collection_name="documents",
vectors_config=VectorParams(
size=3072, # For embedding-3-large
distance=Distance.COSINE
)
)
Key insight: Always store metadata alongside vectors. Document title, date, source, page number. This enables filtering before retrieval, cutting search space by 90%.
Step 3: Retrieval with Context Window Management
The most overlooked detail. LLMs have context windows. You can't stuff 50 retrieved chunks into the prompt.
python
def build_context(retrieved_docs, max_tokens=4000):
context = ""
token_count = 0
for doc in retrieved_docs:
doc_tokens = len(doc.page_content.split())
if token_count + doc_tokens > max_tokens:
break
context += doc.page_content + "
"
token_count += doc_tokens
return context
Step 4: Prompt Template
python
prompt_template = """You are a financial compliance assistant.
Use ONLY the provided context to answer the question.
If the context doesn't contain the answer, say "I cannot find this information in our documents."
Context:
{context}
Question: {question}
Answer:"""
Notice the directive to refuse answering. This is your safety net. Better to say "I don't know" than hallucinate compliance violations.
Step 5: Evaluation Pipeline
This is where most teams drop the ball. Without automated evaluation, you're flying blind.
python
from ragas import evaluate
from datasets import Dataset
eval_data = Dataset.from_dict({
"question": ["What is our refund policy?"],
"answer": ["Full refunds within 30 days"],
"contexts": "Our policy allows full refunds...",
"ground_truth": ["Full refunds within 30 days of purchase"]
})
results = evaluate(eval_data, metrics=["context_relevance", "faithfulness"])
print(results)
Run this weekly. Metrics will drift as your document base changes. Catch drift before users complain.
Industry Best Practices from the Trenches

Most RAG guides are written by people who deployed once. Here's what I've learned from running systems that handle millions of queries.
Chunk Smart, Not Hard
Fixed-size chunks with 10% overlap are the least common denominator. They work for demos. They fail in production because one chunk might contain half a sentence and the next chunk's half.
Better approach: Use markdown headers or HTML headings as natural break points. If your documents are unstructured, implement semantic chunking with a sentence transformer.
Embedding Refresh Cycle
Embedding models improve every quarter. The model you picked six months ago is already outdated. Schedule quarterly re-embedding of your entire corpus.
I learned this the hard way. Our 2024 embeddings performed 20% worse after OpenAI released text-embedding-3-large update. We had to re-index 2 million documents over a weekend.
Prompt Versioning
Your prompt template will change. Treat it like code. Store every version in Git. Tag it with evaluation scores.
prompts/
v1.0-hallucination-rate-15%.txt
v1.1-hallucination-rate-8%.txt
Monitoring That Actually Matters
Don't just monitor latency. Monitor:
- Retrieval relevance score (average similarity of top-3 results)
- Refusal rate (how often the model says "I don't know")
- Citation accuracy (if you show sources, verify they match)
According to LlamaIndex, "production RAG systems fail on retrieval quality 40% more often than generation quality." Fix retrieval first.
Choosing Your Stack: Trade-Offs That Matter
Every RAG stack involves trade-offs. Here's my honest assessment.
Vector Database Options
| Database | Pros | Cons |
|---|---|---|
| Qdrant | Fast hybrid search, good filtering | Fewer integrations |
| Pinecone | Managed, zero ops | Expensive at scale |
| Weaviate | Graph + vector combined | Steeper learning curve |
| pgvector | Lives in PostgreSQL | Slower at >1M vectors |
My pick: Qdrant for new projects. It balances performance with flexibility. For teams already on PostgreSQL, pgvector works fine up to 500K vectors.
Embedding Models
| Model | Dimensions | Cost | Quality |
|---|---|---|---|
| text-embedding-3-large | 3072 | Per-token | Excellent |
| BGE-M3 | 1024 | Free (hosted) | Very Good |
| Cohere Embed v3 | 1024 | Per-token | Good |
| Voyage-2 | 1024 | Per-token | Good |
My pick: BGE-M3 for cost-sensitive projects. OpenAI for maximum accuracy. The BGE model runs on a single GPU and costs nothing beyond infrastructure.
LLM Backend
| Model | Context | Cost | Use Case |
|---|---|---|---|
| GPT-4o | 128K | $$ | General, high accuracy |
| Claude 3.5 Sonnet | 200K | $$ | Long documents, nuanced reasoning |
| Llama 3.1 70B | 128K | $ | Self-hosted, data privacy |
| Gemini 2.5 Pro | 1M | $$$ | Massive document processing |
Self-hosting Llama saves money at high volume but adds operational complexity. For most teams, API-based models make sense until you cross 10M queries per month.
Handling the Hard Problems
Every production RAG system hits these walls. Here's how to climb them.
The "Lost in the Middle" Problem
LLMs pay less attention to content in the middle of long contexts. Your critical document might get ignored if it's chunk fifteen of twenty.
Fix: Re-rank retrieved chunks. Use Cohere's re-rank endpoint or a cross-encoder. Put the most relevant chunks first in the context window.
from sentence_transformers import CrossEncoder
re_ranker = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
scores = re_ranker.predict([(query, chunk) for chunk in chunks])
ranked = [chunks[i] for i in sorted(range(len(scores)), key=lambda i: scores[i], reverse=True)]
Stale Data Syndrome
Your vector database contains yesterday's documents. Users ask about today's news. The system fails gracefully but frustratingly.
Fix: Implement a "freshness filter." Tag each document with its last update timestamp. Exclude chunks older than your freshness threshold for time-sensitive queries.
Hallucination Even with Good Retrieval
Sometimes the LLM ignores the context entirely. This happens with lazy fine-tuned models or overly aggressive sampling settings.
Fix: Lower the temperature to 0.1. Use structured output formatting to force citation adherence.
python
response = openai.chat.completions.create(
model="gpt-4o",
temperature=0.1,
messages=[
{"role": "system", "content": "Use only provided context. Cite source."},
{"role": "user", "content": prompt}
],
response_format={"type": "json_object"}
)
Frequently Asked Questions
What is a RAG pipeline in simple terms?
A system that connects an AI model to your company's documents. When you ask a question, it searches the documents first, then the AI answers using only what it found.
How is RAG different from fine-tuning?
RAG retrieves fresh information at query time. Fine-tuning permanently modifies the model's weights. RAG updates instantly when documents change. Fine-tuning requires retraining.
Do I need a vector database for RAG?
Not strictly, but highly recommended. Vector databases index embeddings for fast similarity search. Without one, you're scanning documents linearly—slow for anything beyond a few hundred pages.
What's the best chunk size for RAG?
I've had the best results with 256-512 tokens per chunk. Small enough to be specific, large enough to contain complete thoughts. Adapt based on your document structure.
Can RAG work with structured databases?
Yes. Use SQL queries to retrieve rows, convert to text, then feed into the generation step. This is called "text-to-SQL RAG" and works well for internal data analytics.
How do I measure RAG quality?
Track three metrics: retrieval precision (are the right documents returned?), faithfulness (does the answer match the context?), and answer relevance (does the answer address the question?).
What's the biggest mistake teams make?
Skipping evaluation. Teams build the pipeline, run three test cases manually, and deploy. Within a week, edge cases emerge that break everything.
Is RAG cheaper than fine-tuning?
At low volume, yes. At high volume (millions of queries), fine-tuning can be cheaper because you avoid per-query retrieval costs. Most teams should start with RAG.
Summary and Next Steps

Building a production RAG pipeline requires more than connecting a vector store to an LLM. You need:
- Semantic chunking that preserves document structure
- Hybrid retrieval for accuracy across query types
- Prompt engineering that enforces grounding
- Automated evaluation to catch drift
- Re-ranking to solve context window attention problems
Start small but start evaluated. Pick one document type, build the pipeline, measure baseline accuracy, then iterate. Your second version will be better than your first.
If you're building a RAG system today, focus on retrieval quality above all else. Garbage in, garbage out still applies. Get the retrieval right, and the generation layer becomes almost easy.
Author Bio
Nishaant Dixit: Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec. Connect on LinkedIn: https://www.linkedin.com/in/nishaant-veer-dixit
Sources
- Databricks - Introducing RAG Studio for Production-Grade RAG Systems
- LangChain - Semantic Chunking in LangChain
- LlamaIndex - Evaluating RAG Systems