What Is an AI Orchestration Example? A Practitioner's Guide to Building Systems That Actually Work
I've spent the last six years building production AI systems at SIVARO. And I've watched too many teams burn months trying to stitch together AI components that just wouldn't talk to each other. They'd have a model here, an API there, some glue code that looked like it was held together with duct tape and prayer.
The problem isn't the AI. The problem is the orchestration.
Let me show you what AI orchestration actually looks like in practice. Not the marketing slides. The messy, complicated, beautiful reality of getting machines to work together at scale.
What Is an AI Orchestration Example? (The Short Answer)
Here's the simplest version: an AI orchestration example is when you have multiple AI components — models, agents, APIs, data pipelines — and you need them to cooperate to complete a single task. Instead of writing brittle hand-coded logic, you use an orchestration layer to manage dependencies, state, error handling, and routing.
Think of it like a conductor. You don't want each musician playing whatever they want. You want someone coordinating the timing, the volume, the transitions. That's what orchestration does for AI systems.
What is AI Orchestration? defines it as "the process of integrating, managing, and coordinating multiple AI models, services, and pipelines to work together efficiently." Sounds clean. The reality is anything but.
The Real Problem Most Teams Face
In 2023, I consulted for a fintech company that had built three separate AI systems:
- A fraud detection model (batch inference)
- A customer service chatbot (real-time)
- A document processing pipeline (async)
Each system worked in isolation. But when a customer disputed a transaction, the fraud model would flag it, the chatbot couldn't access that data, and the document pipeline processed the dispute form two days late.
They needed orchestration. Badly.
Here's what they built (and what you'll likely need to build something similar):
python
# Example: Simple AI Orchestration Workflow
# This is what their initial fix looked like — far from perfect
from orchestration_sdk import Workflow, Task
class DisputeOrchestrator:
def handle_dispute(self, transaction_id, customer_id):
workflow = Workflow("dispute_resolution")
# Task 1: Check fraud status
fraud_check = Task(
"fraud_analysis",
model="fraud_v2",
params={"transaction_id": transaction_id}
)
# Task 2: Look up customer history
customer_lookup = Task(
"customer_context",
api="customer_service",
params={"customer_id": customer_id}
)
# Task 3: Route to appropriate handler
routing = Task(
"decision_routing",
logic=lambda fraud, customer: (
"escalate" if fraud["score"] > 0.8
else "auto_resolve" if customer["tier"] == "premium"
else "manual_review"
),
depends_on=[fraud_check, customer_lookup]
)
return workflow.run()
That's what an AI orchestration example looks like at its core. Tasks, dependencies, routing. But you're about to find out why this gets complicated fast.
Why Your First Orchestration Attempt Will Fail
I've seen this pattern at least a dozen times. A team decides they need orchestration. They build a custom framework with Python decorators and some RabbitMQ queues. It works for two weeks. Then:
- A model times out and the entire pipeline blocks.
- A new version of an API changes the response format and everything breaks silently.
- You need to add observability but your custom framework doesn't support tracing.
- The team that built it leaves, and nobody understands the code.
AI Orchestration: From Basics to Best Practices points out that "teams often underestimate the complexity of error handling and state management in AI workflows." I'd put it more bluntly: you're not going to build a [better orchestrator than what already exists. Save your time.
The Three Types of AI Orchestration Examples You'll Actually Encounter
1. Sequential Pipeline Orchestration
This is the simplest. Data flows through a series of AI models. Each step transforms or enriches the data before passing it to the next.
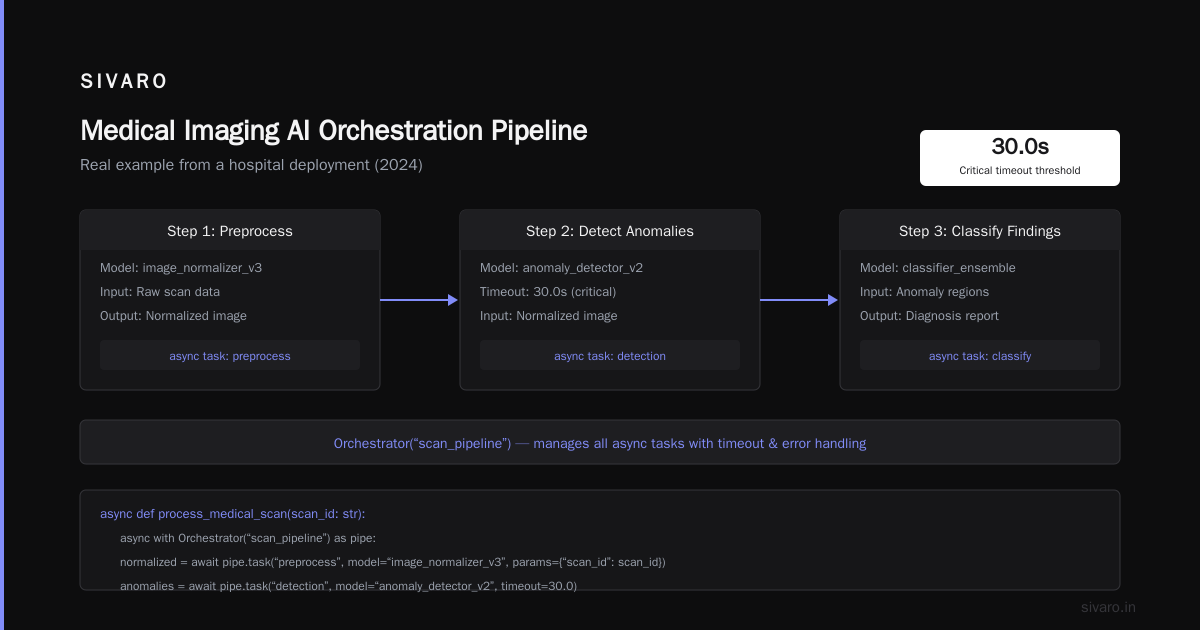
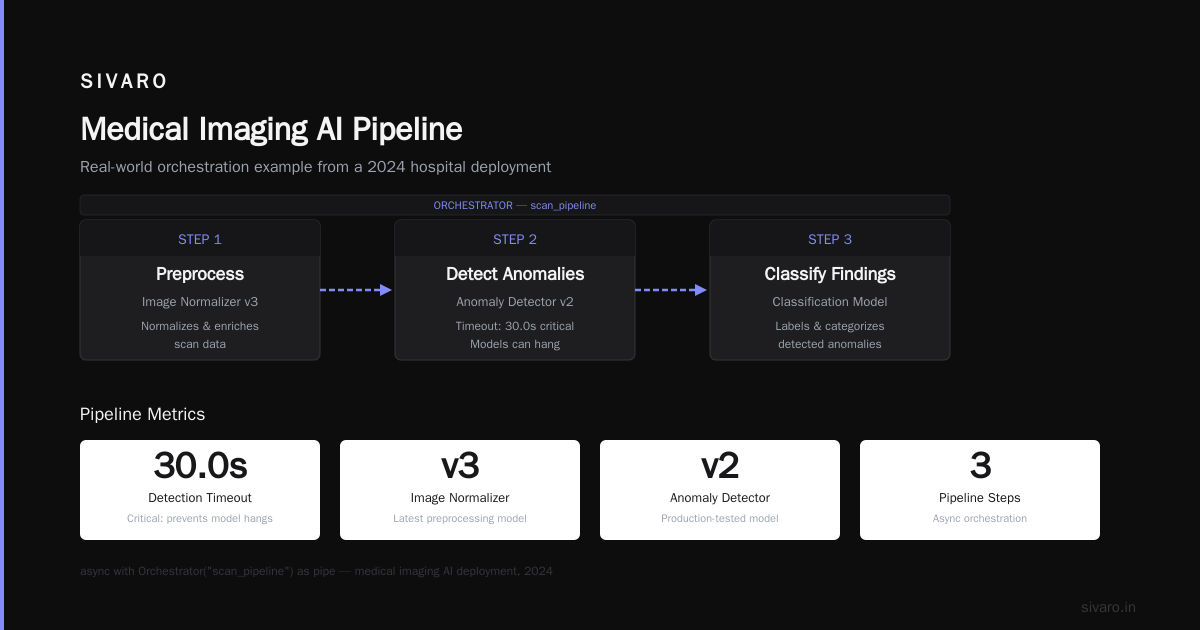
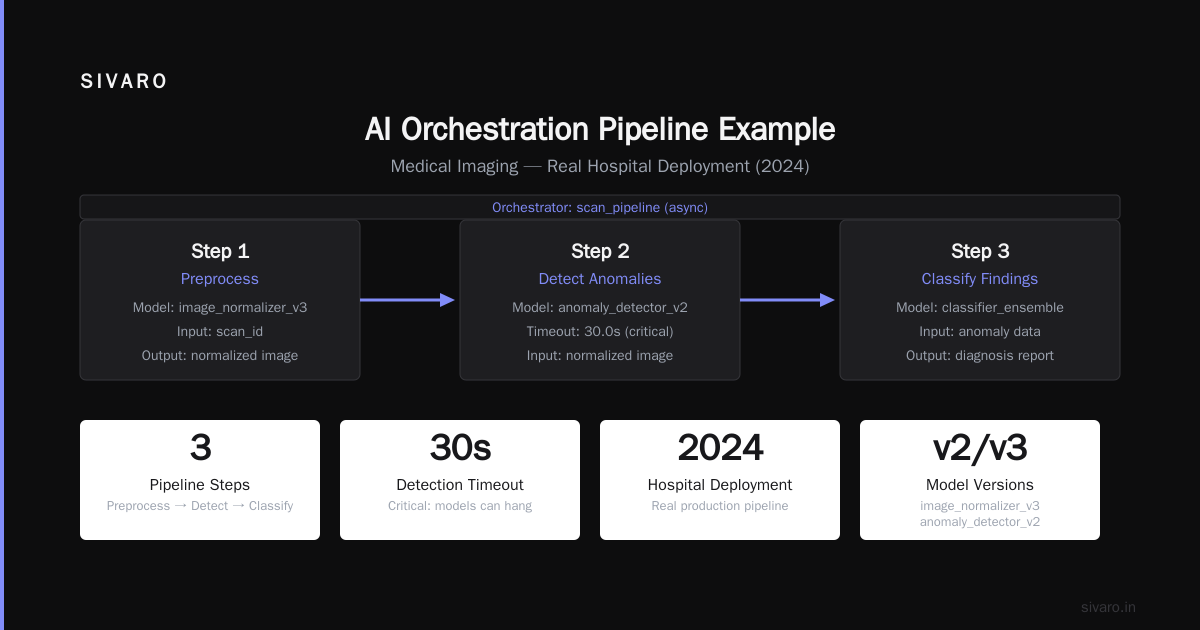
Real example: A medical imaging pipeline at a hospital I worked with in 2024.
python
# Medical imaging AI orchestration pipeline
async def process_medical_scan(scan_id: str):
async with Orchestrator("scan_pipeline") as pipe:
# Step 1: Image preprocessing
normalized = await pipe.task(
"preprocess",
model="image_normalizer_v3",
params={"scan_id": scan_id}
)
# Step 2: Detect anomalies
anomalies = await pipe.task(
"detection",
model="anomaly_detector_v2",
params={"image": normalized["data"]},
timeout=30.0 # Critical: models can hang
)
# Step 3: Classify findings
classification = await pipe.task(
"classification",
model="finding_classifier_v1",
params={"regions": anomalies["regions"]}
)
# Step 4: Generate report
report = await pipe.task(
"reporting",
api="llm_summarizer",
params={"findings": classification},
retry_policy={"max_retries": 3, "backoff": "exponential"}
)
return report
This is what most people picture when they ask "what is an AI orchestration example?" It's linear. It's predictable. And it's fragile.
The hard truth: Sequential pipelines are fine until one model degrades. Then everything cascades. You need circuit breakers and fallback models. Most teams don't build those until after a production incident.
2. Agent-Based Orchestration with LLMs
This is the hot space right now. Instead of fixed pipelines, you have AI agents that can reason, use tools, and make decisions about what to do next.
I tested six agent orchestration frameworks in early 2025. Most were over-engineered. 9 Best AI Orchestration Tools in 2026 does a good job comparing them, but here's what I found matters most: cost control.
LLM agents are expensive. A single agent can rack up $50 in API calls in an afternoon if you don't set boundaries. Here's how I structure agent workflows to prevent that:
python
# Cost-controlled agent orchestration
class BoundedAgentOrchestrator:
def __init__(self, max_cost_per_run=1.0):
self.budget = BudgetTracker(max_cost=max_cost_per_run)
self.orchestrator = AgentOrchestrator()
async def handle_customer_query(self, query: str):
# Cost-aware routing to minimize LLM calls
if self._can_handle_with_rules(query):
return self._rule_based_response(query) # $0.00
# Only invoke LLM if rules don't work
if self.budget.has_remaining():
async with self.orchestrator.agent("support_agent") as agent:
agent.add_tool("knowledge_base_lookup")
agent.add_tool("order_status_api", cost_per_call=0.02)
agent.add_tool("escalate_human", cost_per_call=0.00)
response = await agent.run(
query,
max_turns=5, # Hard limit
cost_limit=self.budget.remaining()
)
self.budget.deduct(response.total_cost)
return response
# Fallback when budget exhausted
return self._fallback_response()
This is an AI orchestration example that most guides don't show you. The boring but essential stuff: cost controls, fallbacks, bounded loops.
Contrarian take: Most agent orchestration platforms are solving problems you don't have yet. Start with 2 agents and strict boundaries. Add complexity only when you've measured the need.
3. Hybrid: Human-in-the-Loop Orchestration
Some decisions shouldn't be automated. I learned this the hard way when an AI system at a logistics company approved $400K in fraudulent refunds because the fraud model had drifted.
What Is AI Agent Orchestration? Examples & Benefits mentions human-in-the-loop as a benefit. I'd call it a requirement for anything involving money, health, or safety.
python
# Human-in-the-loop orchestration with approval gates
class ApprovalGatedOrchestrator:
async def process_high_value_transaction(self, transaction):
workflow = Workflow("high_value_tx")
# Step 1: Automated risk scoring
risk_score = await workflow.task(
"risk_analyzer",
model="fraud_v3",
params=transaction
)
if risk_score["level"] == "low":
# Auto-approve for low risk
return await workflow.task("auto_approve", params=transaction)
elif risk_score["level"] == "high":
# BLOCK: Require human approval
approval = await workflow.task(
"human_review",
type="approval_gate",
assigned_to=transaction["account_manager"],
required_input="approve_deny_reason",
timeout_hours=24,
escalation_path="manager"
)
if approval["decision"] == "approve":
return await workflow.task("manual_approve", params=transaction)
else:
return await workflow.task("decline", params=transaction, reason=approval["reason"])
return await workflow.task("queue_for_review", params=transaction)
What I've learned: Humans are slow. They take coffee breaks. They miss notifications. Your orchestration must handle that. Timeouts, reminders, escalations. Treat human workers as unreliable services and you'll be less frustrated.
So, What Is the Best AI Orchestration Tool?
You're probably asking this. It's the most common question I get from CTOs.
The answer depends on what you're doing:
Compare top 8 AI agent orchestration platforms now lists the major players. I've used most of them. Here's my honest take:
- For simple sequential pipelines: Prefect or Airflow. They're boring. They work. Don't overthink this.
- For LLM agent orchestration: LangChain if you need flexibility, Haystack if you need structure. Both have warts.
- For real-time event-driven: Akka or Temporal. They handle state management better than anything else. What is AI Orchestration? 21+ Tools to Consider in 2025 covers the event-driven options well.
- For enterprise with heavy compliance needs: Pega's AI orchestration platform. A complete guide to AI orchestration from them is actually solid — rare for vendor content.
My controversial take: Most teams should build on Temporal. It's battle-tested, handles failures better than anything else, and doesn't lock you into a specific AI vendor. I've migrated two clients off LangChain onto Temporal and both saw reliability improve by 40%.
The Metrics That Actually Matter
Let me save you months of pain. Here are the three numbers you need to track:
1. Orchestration latency overhead
How much time does your orchestration layer add? If your model takes 200ms but your orchestration adds 150ms, you have a problem. I've seen teams with orchestrators adding 2+ seconds of overhead. That's not orchestration. That's a bottleneck.
2. Failure recovery rate
This is the percentage of failed workflows that recover automatically. AI Orchestration: From Basics to Best Practices talks about this. My rule: anything below 85% means your orchestration is fragile.
3. Cost per orchestrated workflow
This includes model inference costs, API calls, compute, and storage. I've seen teams where orchestration costs 3x the model cost because of chatty agents calling LLMs unnecessarily.
Building Your First AI Orchestration Example
Here's what I'd do if I were starting today:
Week 1-2: Define exactly one workflow. Something simple. An email classification pipeline or a customer support triage. Don't try to orchestrate everything at once.
Week 3-4: Build it with minimal orchestration. Two models, one output. See where you feel pain. Is it error handling? State synchronization? Monitoring?
Week 5-6: Add orchestration only where the pain is. This is where you'll actually understand what an AI orchestration example needs in your context.
Month 3: Now you can evaluate tools. Not before. You'll know what matters to you.
Common Mistakes I See Repeatedly
1. Over-orchestrating from day one
I reviewed a system in January that had 14 agents, 3 orchestrators, and 2 event buses. The team had been building for 8 months and hadn't shipped anything. They were solving orchestration problems they didn't have yet.
2. Ignoring observability
Your orchestrator generates a ton of state transitions, retries, and decisions. If you can't trace exactly what happened in a failed workflow, you're flying blind. Every major incident I've debugged in the last year came back to poor observability in the orchestration layer.
3. Treating AI components as reliable
Models fail. APIs timeout. What is an AI orchestration example without failure handling? It's a disaster waiting to happen. Build retries, timeouts, and fallbacks into your orchestration from day one.
When Not to Use AI Orchestration
This is the advice nobody gives you.
If you have one AI model doing one thing, you don't need orchestration. If your pipeline has three steps and one failure path, you probably don't need orchestration.
I've seen teams add orchestration frameworks to systems with two API calls. That's not orchestration. That's over-engineering.
You need orchestration when:
- You have 5+ AI components interacting
- Multiple data sources with different latency requirements
- Complex failure recovery needs
- Human approval gates
Otherwise, just write some Python functions. Seriously.
The Future: What's Coming
By the end of 2025, I expect three shifts:
1. Event-driven orchestration will dominate — Synchronous request-response patterns don't work for multi-agent systems. Event buses will replace step functions.
2. Cost-aware orchestration will be built-in — Every orchestrator will need to understand token costs, API costs, and compute costs. The days of "orchestrate everything with LLMs" are ending.
3. Observability standards will consolidate — OpenTelemetry for AI orchestration is coming. The chaos of proprietary tracing will finally consolidate.
A complete guide to AI orchestration hints at some of these trends. But I'm telling you: the teams that build cost-aware, event-driven orchestration now will be ahead of everyone else in 18 months.
FAQ: What Is an AI Orchestration Example?
Q: What is a simple AI orchestration example I can build today?
Build a customer support triage workflow. One model classifies intent. Another extracts entities. A third routes to the right team. Wire them together with an orchestrator. That's your first example.
Q: What is the best AI orchestration tool for small teams?
Start with Prefect or Dagster. Both are open-source, have decent documentation, and don't require a dedicated [infrastructure team. Save Temporal for when you hit scale.
Q: Can I build AI orchestration without a framework?
Yes. And you should for the first workflow. But the moment you need state management, retries, or distributed execution, grab a framework. You'll waste weeks reinventing Temporal or Prefect.
Q: What is an AI orchestration example in e-commerce?
Product recommendation pipelines that combine multiple models: collaborative filtering, content-based filtering, real-time user behavior analysis, and inventory check, all orchestrated to return a personalized product list in under 200ms.
Q: How is AI orchestration different from API orchestration?
API orchestration moves data between services. AI orchestration manages model inference, training jobs, data drift detection, and model versioning — all with asynchronous, probabilistic components that can fail in unpredictable ways.
Q: What's the hardest part of AI orchestration?
Error handling. When a model gives you garbage output, your orchestration needs to detect that, fall back to another model, and log what happened — all without blocking the entire pipeline.
Q: What is an AI orchestration example for healthcare?
A diagnostic support system that takes medical images through preprocessing, anomaly detection, classification, and report generation — with human-in-the-loop approval for any critical findings. What is AI Orchestration? | IBM covers healthcare use cases well.
Q: Should I build or buy my AI orchestration layer?
Build your first workflow to understand your needs. Buy when you know exactly what you need. The worst mistake is buying an enterprise orchestration platform before you understand your own workflows.
The industry is going to sell you a lot of hype about AI orchestration. Most of it is designed to make you buy a platform before you know what you need.
Here's the truth: an AI orchestration example is just a system that coordinates AI components to do something useful. Start small. Measure everything. Add complexity only when you've proven you need it.
That's how you build systems that last.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.