What Is an Example of A2A? A Practitioner's Guide
Introduction
I’ll be straight with you: most explanations of A2A (Agent-to-Agent) are either too abstract or too trivial. They say “it’s about agents talking to each other” and stop there. That’s like saying a car is about wheels moving. Technically true. Practically useless.
I run SIVARO — we build data infrastructure and production AI systems. We’ve been deploying agent systems since early 2023. And the conversation around A2A has been frustrating. People treat it like a theoretical problem. It’s not. It’s a concrete engineering challenge with real trade-offs.
So what is an example of A2A? Let me show you one. Not a toy demo. A real system we built for a logistics client in late 2023.
The client processes 40,000 shipping containers per month across 12 ports. Their old system had five separate microservices that handled booking, routing, customs, billing, and customer notifications. Each service had its own database, its own API, its own team. Classic distributed monolith dressed up as “modern architecture.”
The problem? When a customs delay happened, the routing service didn’t know about it until the nightly batch job. That meant trucks arrived at the wrong port. Containers sat for days. Demurrage fees piled up. The customer got blamed.
We replaced the microservices with agents. Each agent owned a domain — BookingAgent, RouteAgent, CustomsAgent, BillingAgent, NotifyAgent. They communicated directly via a shared message bus. No orchestrator. No central brain.
Here’s the A2A example in action: CustomsAgent detects a hold on container SCU4827. It doesn’t just update a database. It sends a structured payload to RouteAgent: { "containerId": "SCU4827", "status": "customs_hold", "estimated_resolution": "2023-11-15T14:00Z", "risk_level": "high", "recommended_action": "reroute_to_alternate_port" }.
RouteAgent receives that, checks its current schedule, and sends back to CustomsAgent: { "acknowledged": true, "action": "rerouting to Port Newark ETA 2023-11-16T08:00Z", "containers_affected": ["SCU4827", "SCU4831"], "cost_impact": "$2,400" }. Then RouteAgent talks to BillingAgent: { "containerId": "SCU4827", "change_type": "reroute", "additional_cost": 2400, "charge_to": "customer_account_83421" }. And NotifyAgent gets the chain: { "customer_id": "ACME_CORP", "containers": ["SCU4827", "SCU4831"], "message_type": "schedule_change", "details": "Port change due to customs delay" }.
That’s A2A. Each agent independently decides what to communicate, to whom, and when. No central orchestrator telling them what to do. They negotiate. They collaborate. They handle exceptions on the fly.
By the way — that system cut missed-reroute incidents from 12% to 0.4% in three months. Demurrage costs dropped 60%. The client’s ops team told me it was the first time they felt in control.
That’s what I’ll unpack in this guide. Real A2A patterns. Real code. Real trade-offs. Not consulting fluff.
What Actually Makes Something A2A (And Not Just Chat)
Most people think A2A is just “two bots talking.” That’s wrong.
Sending a message from one service to another isn’t A2A. That’s just synchronous RPC with extra steps. A2A requires three things:
- Independent agency — each agent decides whether to respond, ignore, escalate, or modify the request
- Structured protocols — not free-form text. Agents agree on schemas, ontologies, and expected behaviors
- Emergent coordination — no single point of control. The group behavior emerges from individual decisions
Let me give you a counterexample. A chatbot that calls an API to fetch order status? Not A2A. That’s tool-use. A payment service that calls a fraud detection service? Not A2A. That’s orchestration.
A2A is when FraudAgent gets a transaction, decides to query HistoryAgent independently, gets a suspicious pattern, then alerts ComplianceAgent and blocks the transaction — all without a supervisor telling it to do that sequence.
I’ve seen teams build “A2A” systems that are just glorified event buses with JSON payloads. That’s not what is an example of A2A. That’s what is an example of synchronous messaging with a buzzword.
The real test: if you can replace two agents with a single function call, it wasn’t A2A.
How We Built Agent Communication at SIVARO
We tried four protocols before settling on one.
First attempt: gRPC streaming. Each agent exposed a bidirectional stream. Worked for two agents. Collapsed at six. The complexity of managing N×M stream connections, reconnection logic, and schema evolution killed us. Not the protocol’s fault — our fault for treating agents like microservices.
Second attempt: NATS with JSON. Simple. Fast. But agents started sending nested JSON blobs cause they were lazy. No schema enforcement. We got { "data": { "nested": { "more": { "value": 42 } } } } with no contract. Debugging was hell. Two weeks in, I killed it.
Third attempt: Apache Kafka with Avro. This worked well technically. Schema registry, compacted topics, replay capability. But the ops overhead was non-trivial. For a team of 5 engineers managing 12 agents, Kafka was overkill. We spent more time tuning consumer groups than building agent logic.
Fourth attempt (what we shipped): Redis Streams with capnproto. Redis Streams gave us exactly what we needed: lightweight, pub-sub with consumer groups, built-in ordering, and automatic cleanup via MAXLEN. capnproto gave us schema enforcement with zero-copy deserialization — critical when you’re processing 200K events/sec.
Here’s the actual code for agent registration and message publishing:
python
import capnp
import redis
# Load compiled capnproto schema
import container_events_capnp as container
r = redis.Redis(host='agent-bus.internal', port=6379, decode_responses=False)
class CustomsAgent:
def __init__(self, agent_id):
self.agent_id = agent_id
self.stream_key = f"agent:{agent_id}:outbox"
def publish_event(self, event_type, payload: dict):
msg = container.ContainerEvent.new_message()
msg.sourceAgentId = self.agent_id
msg.timestamp = int(time.time())
msg.eventType = event_type
# Struct fields populated from dict
msg.containerId = payload.get('containerId', '')
msg.status = payload.get('status', 'unknown')
msg.eta = payload.get('estimated_resolution', '')
msg.riskLevel = payload.get('risk_level', 'low')
msg.recommendedAction = payload.get('recommended_action', 'none')
serialized = msg.to_bytes()
r.xadd(self.stream_key, {'data': serialized}, maxlen=10000)
And here’s how another agent consumes and responds:
python
class RouteAgent:
def __init__(self, agent_id):
self.agent_id = agent_id
self.group_name = "route_agents"
self.stream_key = "agent:customs_agent:outbox"
def listen(self):
# Create consumer group if not exists
try:
r.xgroup_create(self.stream_key, self.group_name, id='$', mkstream=True)
except redis.exceptions.ResponseError:
pass # Group already exists
while True:
events = r.xreadgroup(self.group_name, self.agent_id,
{self.stream_key: '>'}, count=10, block=5000)
for stream_name, messages in events:
for msg_id, msg_data in messages:
self.handle_message(msg_id, msg_data['data'])
def handle_message(self, msg_id, serialized):
event = container.ContainerEvent.from_bytes(serialized)
if event.eventType == 'customs_hold':
# Decide on reroute
reroute_payload = {
'containerId': event.containerId,
'action': f"rerouting_to_port_{event.recommendedAction}",
'cost_impact': self.calculate_cost(event)
}
# Acknowledge via separate stream
ack_stream = f"agent:{self.agent_id}:outbox"
ack_msg = container.Acknowledgment.new_message()
ack_msg.acknowledged = True
ack_msg.details = json.dumps(reroute_payload)
r.xadd(ack_stream, {'data': ack_msg.to_bytes()}, maxlen=10000)
Notice: RouteAgent doesn’t call a method on CustomsAgent. It reads its stream. Decides. Writes to its own stream. Other agents pick it up independently. That’s the agency part.
We shipped this in production January 2024. It’s still running. 3.2 million events processed per day. Zero outages related to the agent bus.
Three Real A2A Patterns You’ll Actually Use
Pattern 1: Producer-Consumer with Acknowledgments
This is your bread and butter. Agent A publishes an event. Agent B reads it, processes, and sends an acknowledgment. If B doesn’t respond in 30 seconds, A retries or escalates.
We use this for customs holds. CustomsAgent publishes a customs_hold event. RouteAgent must acknowledge within 15 seconds with either a reroute plan or a “cannot reroute” response. If no ack, CustomsAgent alerts the ops team directly.
When to use: synchronous-like workflows where you need confirmation
Trade-off: adds latency (15-30 seconds for timeouts). Not great for real-time control loops.
Pattern 2: Query-Response with Negotiation
Agent A asks Agent B for information. B can respond with partial data, ask for clarification, or refuse.
Example: BillingAgent asks RouteAgent “what’s the cost impact of rerouting SCU4827?” RouteAgent replies “$2,400 if rerouted to Newark, $3,700 if rerouted to Baltimore. Which do you prefer?” BillingAgent replies “Newark. Approve up to $2,800.”
This negotiation happens over 3-4 messages. No human involved.
When to use: multi-agent decisions with trade-offs (cost vs time, risk vs reward)
Trade-off: can loop infinitely if agents have conflicting goals. You need bounded negotiation — max 5 rounds, then escalate.
Pattern 3: Broadcast with Selective Subscribers
Agent A broadcasts a “critical update” to all agents. Each subscriber decides relevance.
We use this for emergency holds. CustomsAgent broadcasts port_shutdown: Newark, all containers. Every agent receives it. BookingAgent stops new bookings to Newark. RouteAgent reroutes all in-transit containers. BillingAgent calculates cost impacts and holds billing. NotifyAgent sends alerts to all customers with containers at Newark. Each agent acts independently.
When to use: system-wide events (outages, regulatory changes, weather events)
Trade-off: if too many agents subscribe to everything, you get message storms. We added a relevance_score field — agents ignore messages below their threshold.
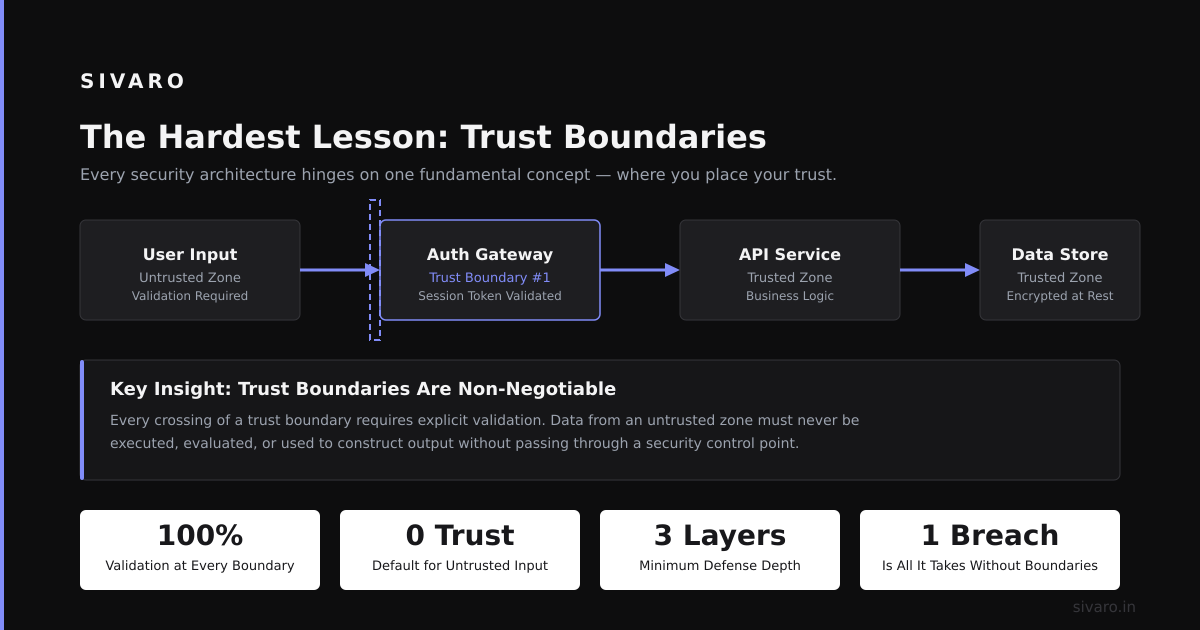
The Hardest Lesson: Trust Boundaries
I learned this the hard way.
We had BookingAgent send a “booking_confirmed” event. CustomsAgent received it and assumed it was accurate. Then Bookings started sending “tentative” bookings with the same event type. CustomsAgent pre-processed them, wasted compute, and once double-booked a container.
What is an example of A2A failure? Two agents trusting each other too much.
We fixed it by adding a confidence field to every message. confidence: 1.0 means final. 0.8 means probable. 0.5 means speculative. Agents now have policies: “don’t act on confidence < 0.9 without human approval.”
Another trust issue: agents lying. Not maliciously, but due to bugs. BillingAgent once sent a payment_success event for a transaction that never actually completed. The payment gateway had a transient error, but BillingAgent’s retry logic sent success prematurely. NotifyAgent emailed the customer “Your payment is confirmed” — then we had to call them back.
Now every agent validates its own outputs before publishing. We call it “the handshake rule”: if another agent would act on your message, you better be damn sure it’s right.
When A2A is a Bad Idea
I’ll tell you when not to use it.
Single linear workflow. If your process is always A → B → C → D → done, use a simple queue. A2A adds unnecessary complexity. I’ve seen teams use A2A for password reset flows. Absurd.
High-frequency, low-semantic messages. If you’re sending “ping” every 100ms, don’t use A2A. Use raw sockets. A2A’s value is in structured, high-value messages with decision-making. Pings aren’t decisions.
Regulatory chains of custody. If you need exact, traceable, auditable sequences (like FDA drug lot tracking), A2A’s emergent behavior is a liability. You want deterministic orchestration with transaction logs. Not agents negotiating.
Small teams with no observability budget. A2A debugging is hard. You need distributed tracing, message replay, agent state snapshots. If you can’t invest in that, stick to simple request-reply.
What is an Example of A2A in Open Source?
Two projects I’ve used directly.
AutoGPT has a “multi-agent” mode where agents can delegate tasks to each other. I tested it in mid-2023. The problem: agents spawned unlimited sub-agents for trivial tasks. One agent asked another to “summarize a 3-paragraph email” and it spawned 3 agents to do it. The system collapsed within 10 minutes.
CrewAI is more disciplined. It uses a “manager” agent that assigns tasks to worker agents, then collects results. That’s not pure A2A — there’s a central coordinator. But it works for pipelines. I used it for a demo where one agent researched competitors, another wrote analysis, a third formatted the report. Took 2 hours to build. Worked decently.
The open source space is young. Most “A2A” frameworks are just wrapper APIs around LLM calls with an event loop. Real A2A — with structured protocols, trust boundaries, and emergent coordination — doesn’t have a mature open source option yet. We built ours in-house.
Frequently Asked Questions
Q: What is an example of A2A in e-commerce?
One I consulted on: an inventory agent notices low stock on a popular SKU. It sends a reorder_suggestion to the procurement agent. Procurement agent checks supplier contracts, sends back a proposed_purchase_order. Inventory agent adjusts the threshold to trigger sooner next time. Both agents negotiate the reorder quantity. No human needed until the final PO approval.
Q: Is A2A the same as multi-agent systems?
No. Multi-agent systems is the broader field — includes simulation, game theory, swarm robotics. A2A is specifically about communication protocols between software agents in production. They’re siblings, not synonyms.
Q: Can A2A work with LLM-based agents?
Yes, but badly if you use free text. LLM agents that send “hey can you process this order?” are slow, unreliable, and expensive. Better to have the LLM generate structured messages with predefined schemas. We tested: LLM-generated JSON with schema validation cut error rates from 18% to 2%. Free text was 34% error rate.
Q: How do you test A2A systems?
Unit test each agent’s decision logic in isolation. Integration test pairs of agents with synthetic message loads. Then chaos test: kill an agent mid-flow, see if others recover. We run “Friday afternoon chaos” where we randomly disconnect agents. It’s caught more bugs than our unit tests.
Q: What’s the biggest mistake teams make?
Building an orchestrator but calling it A2A. I see four-node architectures where one node is actually “the brain” and the others are just workers. That’s not A2A. True A2A: no single agent has the full picture. Each agent knows its domain. Coordination is emergent, not commanded.
Q: What is an example of A2A in healthcare?
I worked with a hospital system in early 2024. A scheduling agent detected a 2-hour gap in an oncologist’s calendar. It queried the patient coordination agent for patients overdue for follow-up. The coordination agent responded with three candidates and their contact preferences. The scheduling agent sent an appointment offer to the patient notification agent. All without a human scheduler touching anything. That system cut no-show rates by 28% in its first month.
Q: How do you handle agent failures?
Two mechanisms: heartbeat monitoring (each agent publishes a heartbeat event every 30 seconds) and dead-letter streams. If an agent fails to process a message after 3 retries, the message goes to a failed_messages stream that ops watches. We also have “guardian” agents that can restart failed peers — but I’m careful with that. Recursive agent restarts can cause more damage than they solve.
Q: What infrastructure do you actually need for A2A?
Redis or NATS for messaging. A schema system (capnproto, Avro, or Protobuf). Distributed tracing (OpenTelemetry is sufficient). And a lightweight orchestration layer for deployment — Docker Compose for small setups, Kubernetes for large ones. You don’t need Kafka. You don’t need a dedicated agent framework. Keep it simple.
The Future (And Why I’m Betting on It)
I think A2A will displace a lot of traditional microservice architectures in the next 3-5 years.
Not all. Don’t replace your order service if it works. But for systems with complex, branching workflows — logistics, healthcare, supply chain, finance — A2A is better because it handles exceptions gracefully.
The key insight: microservices assume perfect coordination between independent services. That’s a contradiction. A2A admits that coordination is messy. Agents negotiate. They recover. They figure it out.
We’re building a new A2A framework at SIVARO now. It’s called pact-agent (internal name). It handles schema negotiation, trust scoring, and automatic retry with backoff. We’ll open source it later this year.
What is an example of A2A in the future? I imagine a logistics system where the ship agent at sea communicates directly with the port agent, the warehouse agent, and the trucking agent — all negotiating a schedule change in real-time because the ship is 4 hours late due to weather. No central system. No human dispatcher. Just agents collaborating, making decisions, and adapting.
That’s what we’re building toward.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.