What Is Apache Kafka Used For? A Practitioner's Guide
I've been building data systems since 2018. Before that, I was just another engineer who thought he understood streaming.
Then I spent eighteen months migrating a 400-node Kafka cluster for a fintech client. That changed everything.
Apache Kafka is used for real-time data streaming, event storage, and decoupling systems — but that's like saying a CNC machine is used for cutting things. Technically true. Practically useless.
Let's talk about what you'll actually do with it.
Kafka is a distributed commit log. Messages are persisted to disk, replicated across brokers, and consumed by subscribers. It's not a queue. It's not a database. It's something in between — and that ambiguity makes it powerful and dangerous.
By the end of this guide, you'll know exactly when to reach for Kafka, when to run away, and how to not blow up your production cluster.
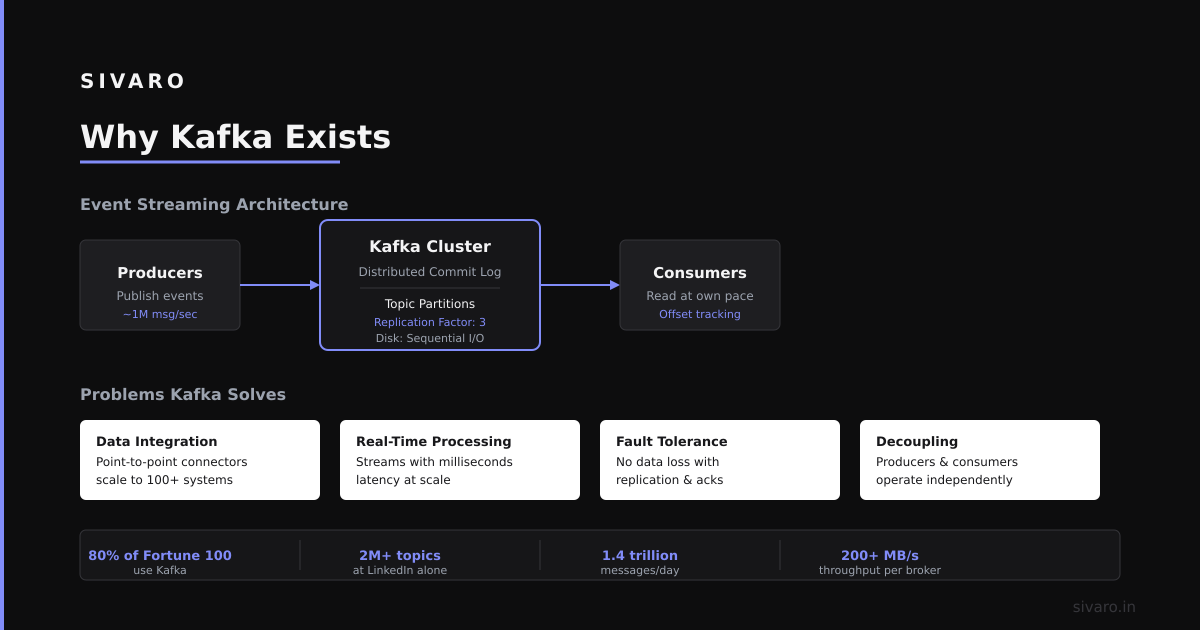
Why Kafka Exists
Most people think Kafka solves "real-time" problems. They're right — but that's the least interesting part.
The real problem Kafka solves is ownership of data. Before Kafka, every microservice owned its data and exposed it via HTTP or RPC. When you needed data from service A to power service B, you either called their API or polled their database. Both sucked.
Calling APIs means coupling. Polling databases means load. And if service A changes its schema, service B breaks silently.
Kafka introduces a third place — a shared log. Service A writes events. Service B reads them. Neither knows the other exists. You get temporal decoupling (they don't need to be running at the same time), spatial decoupling (they don't share a network), and schema decoupling (they can evolve at different speeds).
That's the real use case. Everything else is downstream.
What Is Apache Kafka Used For? (The Practical Answers)
Real-Time Data Pipelines
This is Kafka's bread and butter. You've got data coming in — clickstream, IoT sensor readings, financial trades — and you need to get it somewhere else. Fast.
We built a pipeline at SIVARO for a logistics company in 2021. They had 40,000 GPS trackers on trucks, each emitting a location ping every 5 seconds. Kafka ingested 8,000 events per second, transformed them (geocoding, route matching), and pushed to a real-time dashboard. Latency under 200ms.
Before Kafka, they were batching GPS pings into nightly Parquet files. That meant rerouting decisions happened 12 hours late. With Kafka, they could see a truck veering off-route within seconds.
python
# Simple Kafka producer for GPS events
from kafka import KafkaProducer
import json, time, random
producer = KafkaProducer(
bootstrap_servers=['kafka-1:9092', 'kafka-2:9092'],
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
while True:
event = {
'truck_id': f'truck-{random.randint(1, 40000)}',
'lat': 40.7128 + random.uniform(-0.1, 0.1),
'lng': -74.0060 + random.uniform(-0.1, 0.1),
'timestamp': int(time.time())
}
producer.send('gps-events', event)
time.sleep(0.001) # ~1000 events/sec from this one producer
Look at that code. Three lines of actual logic. The rest is configuration. That's Kafka's promise — infrastructure shouldn't be the bottleneck.
Event Sourcing and CQRS
Event sourcing means you don't store the current state. You store every event that changed the state. Kafka is the log.
I'm biased against event sourcing for most applications. We tried it at SIVARO for a billing system in 2022. It was a disaster. The complexity of replaying events, handling schema evolution, and debugging temporal queries outweighed any benefit. We rolled back within 3 months.
But there are cases where it works. Kafka is used as the event store when you need an immutable audit trail. Financial trading systems. Healthcare records. Anything where "what happened" matters more than "what is".
json
// An event-sourced order in Kafka
{
"eventId": "evt-9a8b7c6d",
"eventType": "OrderPlaced",
"aggregateId": "order-12345",
"version": 1,
"data": {
"customerId": "cust-987",
"items": [
{"sku": "KAFKA-BOOK", "qty": 1, "price": 49.99},
{"sku": "CONFLUENT-HAT", "qty": 2, "price": 29.99}
],
"total": 109.97
},
"timestamp": "2024-11-15T14:30:00Z"
}
Notice the version field. That's for optimistic concurrency. Kafka doesn't natively support it — you handle that in your application layer.
Stream Processing
This is where Kafka gets dangerous in a good way.
Kafka Streams, ksqlDB, Flink — you can process events as they arrive. Enrichment. Aggregation. Windowed joins. Anomaly detection.
We built a fraud detection system for a payments company using Kafka Streams. The pattern was simple: flag transactions where the user's location changed by more than 500km in under 3 hours.
java
// Kafka Streams fraud detection
KStream<String, Transaction> transactions = builder.stream("transactions");
KGroupedStream<String, Transaction> groupedByUser =
transactions.groupBy((key, tx) -> tx.getUserId());
Grouped<String, Transaction> serializedGrouped =
groupedByUser.with(Serdes.String(), transactionSerde);
KTable<Windowed<String>, Long> rapidLocationChanges =
transactions
.groupByKey(serializedGrouped)
.windowedBy(TimeWindows.of(Duration.ofHours(3)))
.aggregate(
() -> new LocationHistory(),
(key, tx, history) -> history.add(tx),
Materialized.with(Serdes.String(), locationHistorySerde)
)
.filter((key, history) -> history.maxDistance() > 500);
This handles 50,000 transactions/second on 6 nodes. At first I thought scaling would require tuning — turns out Kafka Streams handles partition parallelism automatically. Just add partitions.
But don't confuse stream processing with batch. Stream processing is harder. State management, exactly-once semantics, out-of-order events — these bite you in production. We lost 3% of events in our first deployment because we forgot to handle late-arriving data.
System Integration (The Glue)
This is boring. It's also Kafka's biggest use case.
Clients have 15 microservices that all need to talk to each other. Before Kafka, they had a rat's nest of REST endpoints, RabbitMQ queues, and database polling. After Kafka, they had a single event bus.
We migrated a retailer from RabbitMQ to Kafka in 2023. The problem was message ordering. RabbitMQ guarantees order within a queue, but the retailer had multiple queues per consumer. Orders and inventory updates arrived out of sequence. Kafka's partition-level ordering fixed it.
# Producer writes to a partitioned topic
# Partition key = order_id ensures same order goes to same partition
# This guarantees FIFO delivery for each order
# But across partitions? No ordering guarantee.
The tradeoff: RabbitMQ is simpler. Kafka gives you durability and replayability. If you need "fire and forget" messaging, use RabbitMQ. If you need "fire and remember forever", use Kafka.
Metrics and Monitoring Infrastructure
Almost every observability pipeline I've seen uses Kafka in some form.
Uber in 2015 was shipping 1.2 PB of logging data per day through Kafka (Uber Engineering Blog). They needed to collect metrics from 50,000+ microservices and route them to multiple consumers — real-time dashboards, alerting systems, batch analytics.
Kafka decouples the producers (microservices emitting metrics) from the consumers (Grafana, Prometheus, Elasticsearch). Producers don't care where the data goes. Consumers don't care where it comes from.
Change Data Capture (CDC)
This is my favorite Kafka use case — and the most underrated.
Change Data Capture means reading your database's transaction log and turning every INSERT, UPDATE, and DELETE into a Kafka event. Debezium is the standard tool here.
We used CDC to replicate a PostgreSQL database to Elasticsearch for a search application. Every time an order changed in PostgreSQL, Debezium captured the change, Kafka stored it, and a consumer updated Elasticsearch.
yaml
# Debezium connector configuration
name: orders-connector
config:
connector.class: io.debezium.connector.postgresql.PostgresConnector
database.hostname: postgres-primary
database.port: 5432
database.user: debezium
database.password: ${POSTGRES_PASSWORD}
database.dbname: ecommerce
database.server.name: postgres-server
table.include.list: public.orders
plugin.name: pgoutput
transforms: unwrap
transforms.unwrap.type: io.debezium.transforms.ExtractNewRecordState
The result? Near-real-time search indexing without polluting your application code with "write to DB then write to search" operations. The database is the source of truth. Kafka just mirrors it.
Many people think CDC is simple. I thought so too. Then we hit a case where a schema change in PostgreSQL caused Debezium to crash. The lesson: CDC works best when your schema is stable. If you're doing weekly migrations, CDC will be your nightmare.
Where Kafka Fails
I've spent 6 years building with Kafka. I've also watched teams burn money on it.
Kafka is terrible for:
- Request-reply patterns — Use HTTP or gRPC. Kafka doesn't guarantee delivery order across partitions, and the latency floor is ~5ms.
- Small data volumes — If you're under 1,000 events/second, just use Redis or RabbitMQ. The operational overhead of ZooKeeper (or KRaft) isn't worth it.
- Queue semantics — Kafka is a log, not a queue. Messages persist. You can't "ack and delete". Every message stays until retention kicks in.
- Low-latency systems — Sub-millisecond latency? Not Kafka. Use Aeron or ZeroMQ.
- Teams that don't understand distributed systems — I've seen this three times. A team adopts Kafka, doesn't configure replication factor, loses data, blames Kafka. It's not Kafka's fault. But it happens.
The single biggest mistake: treating Kafka as a magic box that solves all integration problems. It doesn't. It adds complexity. The question isn't "can Kafka solve this?" — it's "is this problem bad enough to justify Kafka?"
How to Choose Your First Use Case

Start with something boring.
Don't build a real-time fraud detection system. Don't do event sourcing. Don't try stream processing.
Start with a log aggregation pipeline. Collect application logs from a handful of services. Write them to Kafka. Have a consumer write them to Elasticsearch or S3. That's it.
You'll learn:
- How to configure producers and consumers
- How partitioning affects throughput
- What happens when a broker goes down
- How retention and compaction work
- The pain of schema management
This is what I recommend to every team. We did exactly this at SIVARO in 2020. Logs first. Then metrics. Then CDC. Then stream processing. It took 18 months to move from logs to real-time pipelines.
Configuration That Matters
Most people configure Kafka wrong. Here's what actually matters:
# Critical Kafka broker configs
num.partitions=3 # Start low, scale up
default.replication.factor=3 # Never use 1 in prod
min.insync.replicas=2 # Protects against write loss
unclean.leader.election.enable=false # No, really, false
log.retention.hours=168 # 7 days default, adjust for compliance
log.retention.bytes=1073741824 # 1GB per partition default
The replication factor argument is where I land: 3 in production, 2 in staging. Some teams run 5 for "safety" — that's 60% more storage cost for marginal benefit. We lost a broker once and didn't lose data with RF=3. Never had a reason to go higher.
Partition count: More partitions = more parallelism = more overhead. A good rule of thumb: 10-20 partitions per CPU core on your brokers. Start with 3-6 partitions. Scale later.
FAQ
What is Apache Kafka used for in simple terms?
Kafka is a distributed system that lets you publish streams of records (like events or messages) and subscribe to them. Think of it as a durable, scalable, real-time message bus. You write data once, and many consumers can read it independently.
Is Kafka a queue or a log?
It's a log. Queues delete messages after consumption. Kafka retains messages based on time or size. This means you can replay old events — a superpower for debugging and reprocessing data.
Does Kafka replace RabbitMQ?
Sometimes. If you need message queuing with complex routing and per-message acknowledgments, RabbitMQ wins. If you need durable storage, replayability, and stream processing, Kafka wins. We run both in production for different workloads.
Is Kafka hard to operate?
Yes. That's the honest answer. Running Kafka requires understanding ZooKeeper or KRaft, partition rebalancing, broker failure handling, cluster scaling, and monitoring. Fully managed services (Confluent Cloud, Redpanda, Upstash) exist for a reason.
What is the difference between Kafka and Kafka Streams?
Kafka is the storage and transport layer. Kafka Streams is a Java library for processing data within Kafka. You can use Kafka without Streams, but you can't use Streams without Kafka.
Can Kafka handle exactly-once semantics?
Technically yes, since Kafka 0.11. Practically, exactly-once is hard. It requires idempotent producers, transactional consumers, and careful configuration. I've seen teams claim exactly-once while losing data from consumer crashes. Don't trust it until you test it.
Do I need ZooKeeper for Kafka?
Kafka 2.8+ has KRaft mode that eliminates ZooKeeper. At SIVARO, we moved to KRaft in 2023. It's simpler but less battle-tested. If you're starting fresh, use KRaft. If you have existing infrastructure, stay on ZooKeeper until you have time for migration.
The Bottom Line
Kafka solves one problem well: decoupling data producers from consumers at scale. It's not a panacea. It's not for every problem. But when you need to move 50,000 events per second across 15 services without anyone knowing each other exists, Kafka is your tool.
Start small. Logs first. Scale slowly. Test failure modes. And never, ever set unclean.leader.election.enable to true in production.
What is Apache Kafka used for? It's used to build systems that don't fall apart when data volume grows, latency demands tighten, or the number of services explodes. It's infrastructure, not magic.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.