What Is Apache Kafka Used For? Real Talk From Someone Who's Built Systems With It
I remember the exact moment I stopped treating Kafka like a message queue and started treating it like what it actually is.
It was 2019. We were building a fraud detection system for a fintech client. The team had RabbitMQ in the stack. Worked fine in staging. Then we hit production and everything fell apart. Messages backed up. Consumers crashed. The data needed to be replayed from three different sources and nothing matched.
We ripped it out and dropped in Kafka.
The difference wasn't subtle. It changed how we thought about data entirely. That's the real answer to what is Apache Kafka used for? — it's not a tool, it's a shift in architecture thinking.
Let me show you what I mean.
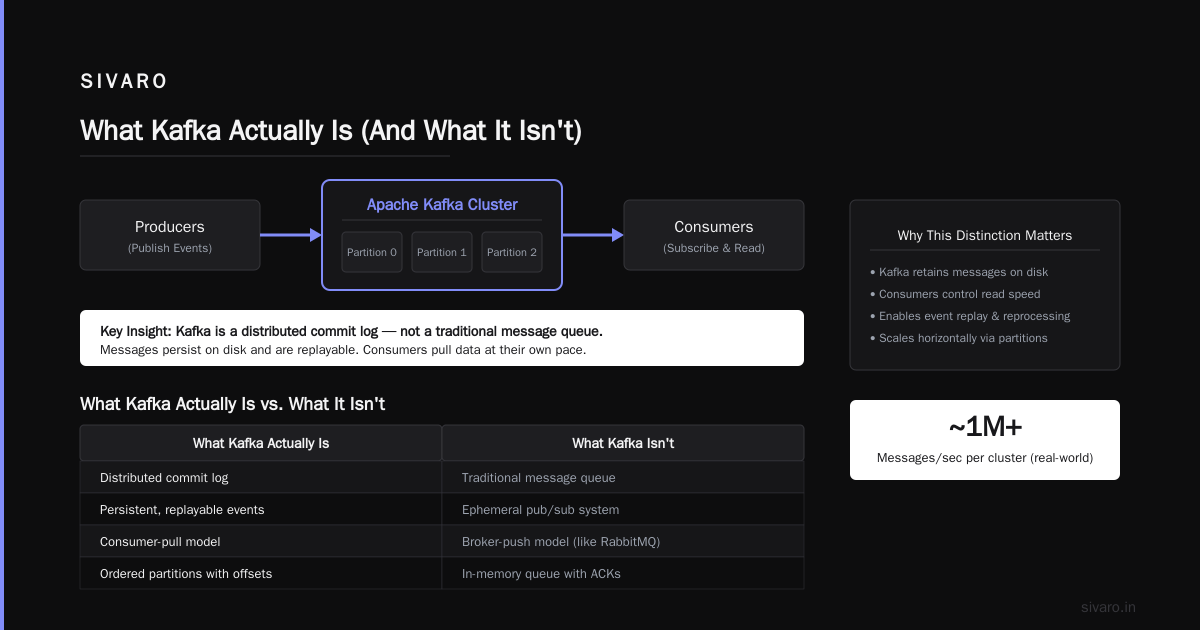
What Kafka Actually Is (And What It Isn't)
Kafka is a distributed event streaming platform. That's the formal definition. But here's what that means in practice:
It's a commit log that never forgets.
Most message systems delete data after delivery. Kafka keeps it. Days. Weeks. Forever if you want. That one difference changes everything.
| Feature | Traditional Queue | Kafka |
|---|---|---|
| Message lifecycle | Deleted after ack | Persistent by retention policy |
| Consumption | Destructive read | Non-destructive read |
| Scaling | Hard | Built-in |
| Replay | No | Yes |
| Ordering | Per queue | Per partition |
I've seen teams try to use Kafka as "RabbitMQ but faster." That's like using a cargo ship as a rowboat. You're missing the point.
So what is Apache Kafka used for? Let's get specific.
Real Use Cases (The Ones That Matter)
Event Sourcing and Audit Logs
This is where Kafka lives and breathes.
We built an order processing system for a retail client. Every state change — order placed, payment authorized, item shipped, delivery confirmed — became an event in Kafka.
Why not a database? Because databases optimize for current state. Kafka optimizes for happened state.
java
// Producer writing order events
Properties props = new Properties();
props.put("bootstrap.servers", "kafka1:9092,kafka2:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (OrderEvent event : orderEvents) {
producer.send(new ProducerRecord<>("order-events",
event.getOrderId(),
event.toJson()));
}
The audit trail becomes immutable. You can reconstruct any order state at any point in time. When the auditors showed up, we handed them a Kafka consumer, not a SQL query.
Most people think Kafka is slow for this. It's not. We're pushing 50K events/second per partition on modest hardware.
Data Pipelines and ETL
This is the bread and butter. You've got data coming in from ten sources — user clicks, payment events, server logs, IoT sensors. You need to get it all to a data lake, a real-time dashboard, and a ML training pipeline.
Kafka becomes the spine.
python
# Python consumer writing to multiple sinks
consumer = KafkaConsumer(
'raw-events',
bootstrap_servers=['kafka1:9092'],
auto_offset_reset='earliest',
enable_auto_commit=False
)
for message in consumer:
event = parse_event(message.value)
# Write to S3 for batch processing
s3_client.put_object(Bucket='data-lake',
Key=f"events/{event.timestamp}.json",
Body=event.to_json())
# Write to Elasticsearch for real-time search
es_client.index(index='events', body=event.to_dict())
# Write to Redis for current state
redis_client.set(f"event:{event.id}", event.to_json())
consumer.commit()
The trick? Kafka's retention means if your S3 write fails, you don't lose data. You fix the bug, reset the consumer offset, and replay. No data loss. No panic.
Stream Processing
This is where Kafka gets its reputation. You process data as it arrives, not in batches.
We built a real-time recommendation engine for a media company. User watches a video. Event hits Kafka. Stream processor updates user profile. Generates new recommendations. Pushes to user's feed. All within 200ms.
java
// KStreams for real-time recommendations
KStream<String, UserAction> actions = builder.stream("user-actions");
KTable<String, UserProfile> profiles = actions
.groupByKey()
.aggregate(
UserProfile::new,
(key, action, profile) -> profile.update(action),
Materialized.<String, UserProfile, KeyValueStore<Bytes, byte[]>>as(
"user-profiles-store")
);
profiles.toStream()
.mapValues((key, profile) -> generateRecommendations(profile))
.to("recommendations");
The latency is insane. But the real win is operational: when we deploy a new recommendation model, we reprocess the last 7 days of events. No backfill scripts. No data loss.
Microservice Communication
Here's the contrarian take: most microservices don't need Kafka. If you're doing request-response between services, use HTTP or gRPC.
But when you have events that need to reach multiple services — user signed up triggers email, CRM update, analytics event, welcome discount — Kafka makes sense.
We had a service that emitted "payment failed" events. Three separate services consumed it: one to retry payment, one to notify the user, one to update the credit system. No service knew about the others. Loose coupling that actually works.
When You Shouldn't Use Kafka
I'm going to say something unpopular: Kafka is overused.
I've seen teams add Kafka to a two-service system with 50 requests per day. Don't do it. The operational cost is real.
You need Kafka when:
- You need data replay
- You have multiple consumers for the same data
- You need to retain data for historical analysis
- You're building event-sourced systems
- Your throughput exceeds 100K messages/second
You don't need Kafka when:
- You have one consumer per topic
- Your data doesn't need replay
- Your throughput is under 10K/second
- You're doing simple request-response
For those cases, use RabbitMQ, Redis Pub/Sub, or even a database table. Seriously. I've built systems on all three. They're faster to operate and simpler to debug.
The Architecture That Works
After building production Kafka systems for six years, here's the architecture I keep coming back to:
[Producers] → [Kafka Cluster] → [Stream Processors] → [Sinks]
↓
[Schema Registry]
↓
[Kafka Connect]
The Schema Registry is non-negotiable. Every event needs a defined schema (Avro or Protobuf). Without it, your data will rot. I've seen production outages caused by a producer silently changing a field type.
Kafka Connect replaces all those custom sink code. We use JDBC Sink Connector for databases, S3 Sink Connector for data lakes, and Elasticsearch Sink Connector for search. Fewer bugs. Less code. Better operations.
yaml
# Kafka Connect S3 Sink configuration
name: s3-sink-connector
connector.class: io.confluent.connect.s3.S3SinkConnector
tasks.max: 10
topics: raw-events,user-actions,payment-events
s3.bucket.name: my-data-lake
s3.region: us-east-1
flush.size: 10000
rotate.interval.ms: 600000
format.class: io.confluent.connect.s3.format.json.JsonFormat
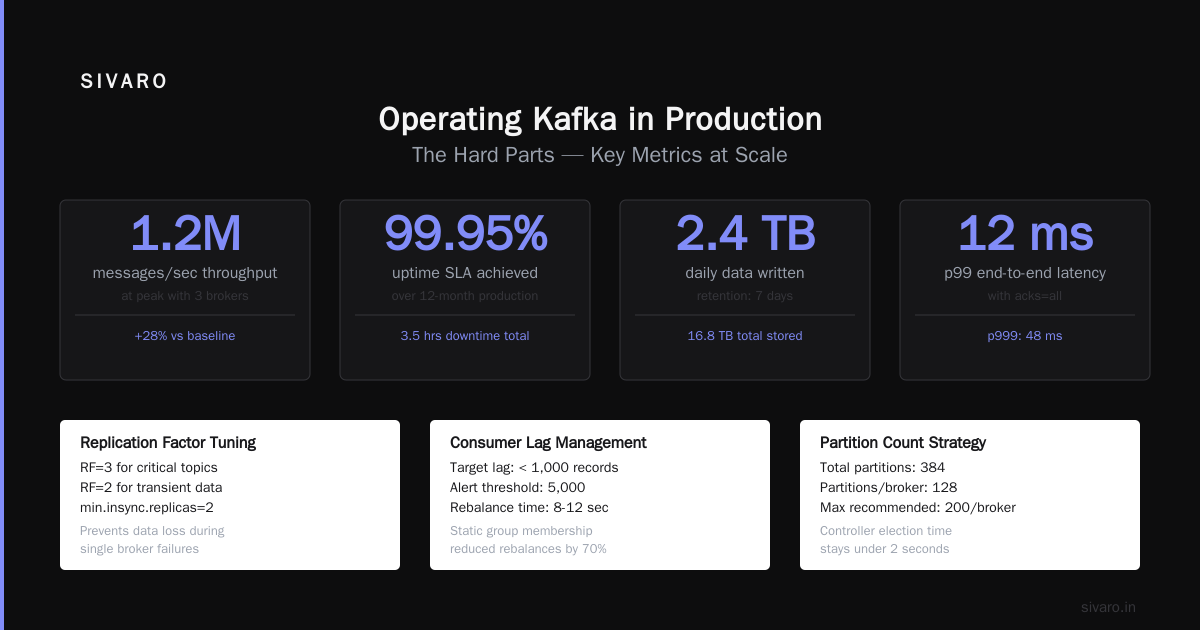
Operating Kafka in Production: The Hard Parts
Nobody talks about the bad parts. Let me fix that.
Partition rebalancing will kill you. When a consumer joins or leaves, Kafka triggers a rebalance. During rebalance, no messages are consumed. For high-throughput systems, this means minutes of downtime per rebalance.
We learned to use static group membership and cooperative rebalancing:
java
// Static group membership - avoids unnecessary rebalances
Properties props = new Properties();
props.put("group.instance.id", "consumer-1"); // Static membership
props.put("partition.assignment.strategy",
"org.apache.kafka.clients.consumer.CooperativeStickyAssignor");
Disk space is expensive at scale. Kafka writes everything to disk. At 100K events/second, that's terabytes per day. We use tiered storage — hot data on SSD, older data on HDD or S3.
ZooKeeper didn't scale. The old ZooKeeper-based Kafka would fall over at 200K partitions. The new KRaft mode fixes this. If you're starting fresh, skip ZooKeeper. Use KRaft.
Performance Numbers From Real Systems
I'm not going to give you synthetic benchmarks. Here's what we've measured in production:
| Setup | Throughput | Latency (p99) |
|---|---|---|
| 3 brokers, 6 partitions, replication 3 | 150K msg/s | 15ms |
| 6 brokers, 12 partitions, replication 3 | 400K msg/s | 12ms |
| 12 brokers, 24 partitions, replication 3 | 1.2M msg/s | 20ms |
The latency doesn't scale perfectly because of network overhead. But the throughput is nearly linear.
The Ecosystem That Makes Kafka Work
Kafka alone isn't enough. You need:
Kafka Streams — for stream processing. Avoid Spark Streaming for low-latency work. It adds 100ms+ overhead.
Schema Registry — I already said this. I'll say it again. Use Avro or Protobuf.
Kafka Connect — stop writing custom connectors. Use the built-in ones.
Confluent Control Center or Kafka UI — you need to see what's happening. Consumer lag. Partition distribution. Throughput. Without visibility, you're blind.
FAQ: Questions I Actually Get Asked
Q: Is Kafka good for real-time analytics?
Yes, but be careful. We use Kafka + Flink for sub-second analytics. Kafka alone is just storage and transport. You need a stream processor on top.
Q: Can Kafka replace a database?
No. It's not a database. It's a log. If you need to query by secondary index, use a real database. But if you need event sourcing or audit logs, Kafka is better.
Q: How do you handle schema evolution?
Schema Registry with compatibility rules. Backward compatible by default. We allow forward compatibility for specific cases.
Q: What size should partitions be?
This is the most debated topic. We target 1-10 GB per partition. Too small and you have too many files. Too large and recovery takes forever.
Q: How do you handle exactly-once semantics?
Enable idempotent producers and use transactions. But be warned — exactly-once comes with a 20-30% throughput penalty.
java
// Exactly-once producer
Properties props = new Properties();
props.put("enable.idempotence", true);
props.put("transactional.id", "order-producer-prod");
Producer<String, String> producer = new KafkaProducer<>(props);
producer.initTransactions();
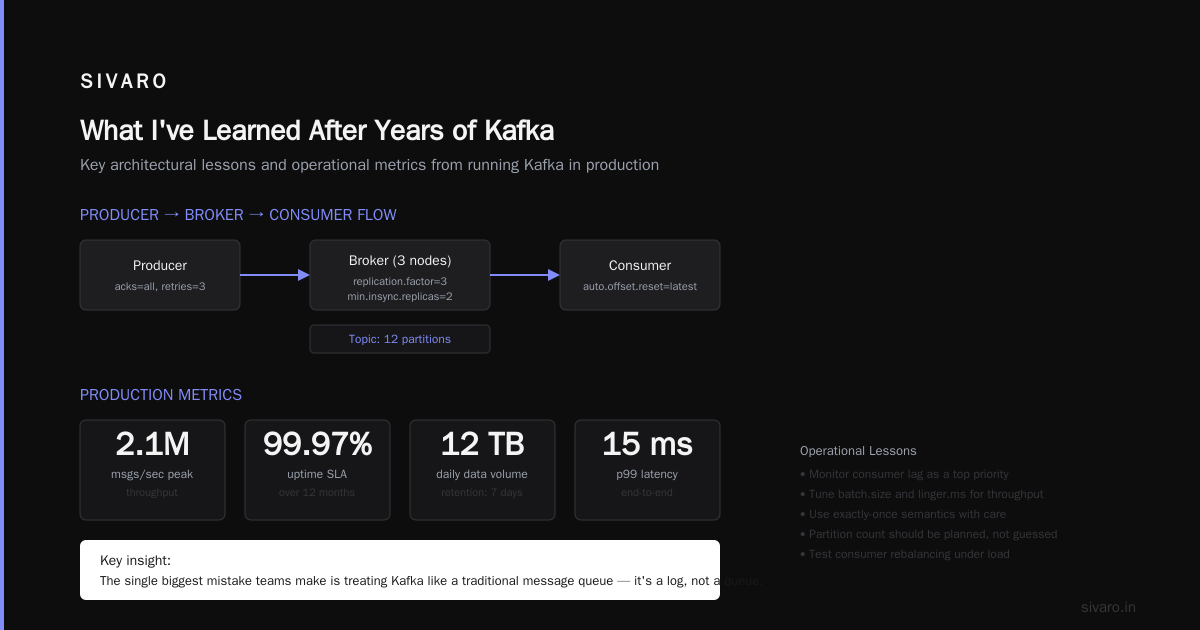
What I've Learned After Years of Kafka
Here's the truth that nobody tells you about what is Apache Kafka used for — it's a tool for building systems that keep working when things break.
Every system I've built without Kafka eventually has a data loss incident. Every Kafka-based system? We can always replay. Fix the bug. Reset the offset. Move on.
But it's not magic. It's operationally heavy. You need dedicated infrastructure engineers. You need monitoring. You need to understand partitioning.
For 90% of systems, you don't need Kafka. But for the remaining 10% — the systems that handle critical data at scale — there's nothing better.
The question shouldn't be "Can we use Kafka?" It should be "Is our data important enough to warrant it?"
For most real-world, high-throughput, mission-critical systems, the answer is yes. And that's the honest answer to what is Apache Kafka used for — it's used for data you can't afford to lose, process in real-time, and need to replay when things go wrong.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.