
What is ClickHouse Used For? A Practical Guide
I remember the first time I hit sub-second query times on a billion-row dataset. I was skeptical. "This has to be cached," I thought. It wasn't. That was 2019, and I was testing ClickHouse for a client who needed real-time analytics on their user event data. Six years later, I've built SIVARO around exactly this kind of infrastructure.
So here's the honest answer to what is clickhouse used for? It's used for one thing better than almost anything else: running analytical queries on massive datasets at absurd speeds. Not transactional work. Not small data. Not general-purpose databases. But if you need to ask "what happened across all my data in the last 30 minutes?" and get an answer in milliseconds, ClickHouse is probably your answer.
Let me show you exactly where it fits, where it doesn't, and how to decide if it's right for you.
The Short Version: ClickHouse's Core Use Case
ClickHouse is a column-oriented DBMS for online analytical processing (OLAP). You feed it terabytes of data, and it lets you query that data in real time. It's not for updating individual rows a million times per second. It's not for storing your user profiles. It's for aggregations, time-series analysis, log analytics, and dashboards that need to stay fast as data grows.
The classic use cases:
- Real-time analytics dashboards (Grafana, Metabase, custom UIs)
- Observability and logging (replacements for Elasticsearch in high-volume setups)
- Time-series data (IoT sensor data, financial tick data)
- Behavioral analytics (user event funnels, session analysis)
- Data warehouse for medium-scale analytics (10TB–100TB range)
I've deployed ClickHouse for a fintech company processing 50 million transactions daily. Queries that took 45 seconds in PostgreSQL dropped to under 200ms. That's the difference between "can we see this?" and "let me show you right now."
Real-Time Analytics: Where ClickHouse Shines
If you're building a product that shows users charts and metrics, and those metrics need to update faster than every few minutes, ClickHouse is a strong candidate.
PostHog, the product analytics platform, ran a detailed comparison of ClickHouse vs Snowflake (PostHog blog). Their conclusion? ClickHouse was 2-10x faster for their specific query patterns. They built their entire product around it.
I've seen this pattern repeatedly. A startup I consulted for had a Redis + PostgreSQL setup for their real-time dashboard. It worked fine at 100K events/day. At 10M events/day, it collapsed. The bottleneck wasn't compute — it was query complexity. They needed GROUP BY across multiple dimensions, time bucket aggregations, and percentile calculations. PostgreSQL started timing out at 30 seconds. ClickHouse handled the same queries in 80ms.
The key insight: ClickHouse's columnar storage compresses data aggressively. Typical compression ratios are 5-10x. For time-series data with repetitive values? I've seen 20x. That means more data fits in RAM, and less data is read off disk for any given query.
Example: Building a Real-Time Event Counter
Here's a simplified version of what that looks like in practice. Say you're tracking page views:
sql
CREATE TABLE events (
event_id UUID,
timestamp DateTime,
user_id String,
page_url String,
country String,
duration_ms UInt32
) ENGINE = MergeTree()
ORDER BY (timestamp, user_id);
Now query hourly page views by country for the last 24 hours:
sql
SELECT
toStartOfHour(timestamp) AS hour,
country,
count(*) AS views
FROM events
WHERE timestamp > now() - INTERVAL 24 HOUR
GROUP BY hour, country
ORDER BY hour, views DESC;
On a 100-million-row dataset, this runs in under 200ms on a single node. Try that on PostgreSQL with a comparable row count. You'll wait.
ClickHouse vs Snowflake: The Real Differences
Most people think the choice between ClickHouse and Snowflake is about features. It's not. It's about workload patterns.
Snowflake is a general-purpose cloud warehouse. It's built for BI queries, large JOINs, and ad-hoc analytical work by data analysts. It separates compute and storage elegantly. It handles concurrency well. It costs money — sometimes a lot (Vantage.sh pricing comparison).
ClickHouse is specialized. It's built for sub-second queries on high-ingestion workloads. It's weaker at complex JOINs. It doesn't handle high concurrency as gracefully. But for the workloads it's designed for, it's brutally fast and cost-effective.
Let me give you a concrete comparison. I ran this test for a client considering both platforms:
Test: 100 million rows. Query: "Average session duration by country for last 7 days"
| Platform | Query Time | Monthly Cost (estimated) |
|---|---|---|
| ClickHouse (self-hosted, 3 nodes) | 180ms | $800 |
| Snowflake (XS warehouse) | 2.4s | $1,500 |
| Snowflake (L warehouse) | 400ms | $4,200 |
The Snowflake numbers vary based on warehouse size and concurrency. But the pattern holds: ClickHouse gives you faster queries at lower cost for high-volume analytical workloads (Flexera blog).
But here's the contrarian take: Snowflake is better for most companies. Why? Because most companies don't need sub-second queries on billions of rows. They need reliable SQL, easy scaling, and low maintenance. Snowflake delivers that. ClickHouse demands more operational expertise.
Is ClickHouse better than Snowflake? No. It's different. If you need real-time analytics at scale, ClickHouse wins. If you need a flexible warehouse for BI teams, Snowflake wins. If you're building a product analytics tool or observability platform, pick ClickHouse. If you're running quarterly business reports, pick Snowflake.
The Tinybird team wrote a detailed comparison (Tinybird blog) that nails this distinction: ClickHouse is for "fast data" — high velocity, high volume, low latency. Snowflake is for "big data" — complex queries, varied workloads, lower velocity.
Log Analytics and Observability
Elasticsearch has dominated this space for a decade. But it's expensive at scale. And it's increasingly frustrating to operate.
ClickHouse is eating Elasticsearch's lunch in observability.
Why? Two reasons. First, ClickHouse's columnar storage compresses log data extremely well. Logs are repetitive — same fields, same status codes, same error messages over and over. Columnar storage exploits this. I've seen 80% storage reduction compared to Elasticsearch for the same log volume.
Second, ClickHouse's SQL interface makes log analysis accessible to anyone who knows SQL. No need to learn a custom query DSL.
Example: Log Analysis with ClickHouse
sql
CREATE TABLE logs (
timestamp DateTime,
level Enum('debug', 'info', 'warn', 'error'),
service String,
message String,
user_id Nullable(String),
request_id String,
duration_ms UInt32
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(timestamp)
ORDER BY (timestamp, service);
Find all errors with duration > 1000ms in the last hour:
sql
SELECT
service,
count(*) AS error_count,
avg(duration_ms) AS avg_duration
FROM logs
WHERE level = 'error'
AND duration_ms > 1000
AND timestamp > now() - INTERVAL 1 HOUR
GROUP BY service
ORDER BY error_count DESC;
This runs fast even with billions of log entries. At SIVARO, we've built observability pipelines that ingest 200K log events/second into ClickHouse. Queries against the last 30 days of data complete in under 1 second.
Companies like Uber and Cloudflare use ClickHouse for observability at massive scale. It's not a niche use case anymore.
Time-Series Data and IoT
ClickHouse handles time-series data naturally. Its MergeTree engine family is optimized for append-heavy workloads with time-based partitioning.
I worked with an industrial IoT company that was collecting sensor readings from 50,000 devices. Each device sent readings every 5 seconds. That's 864 million rows per day. They had been using InfluxDB. It worked for recent data but struggled with historical queries spanning months.
They migrated to ClickHouse. The key trick: use a ReplacingMergeTree if you need upserts on time-series data, or stick with plain MergeTree for pure append workloads.
Example: IoT Sensor Data
sql
CREATE TABLE sensor_readings (
device_id String,
timestamp DateTime,
temperature Float32,
humidity Float32,
pressure Float32
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(timestamp)
ORDER BY (device_id, timestamp);
Get average temperature by device for the last week:
sql
SELECT
device_id,
avg(temperature) AS avg_temp,
max(temperature) AS max_temp,
min(temperature) AS min_temp
FROM sensor_readings
WHERE timestamp > now() - INTERVAL 7 DAY
GROUP BY device_id
ORDER BY avg_temp DESC;
The performance difference from InfluxDB was dramatic. Queries spanning 6 months of data that took 30+ seconds in InfluxDB finished in 2-3 seconds in ClickHouse. The catch: ClickHouse uses more RAM for certain aggregations, so you need to size your nodes appropriately.
ETL and Data Transformation Pipelines
Here's a use case people don't talk about enough: using ClickHouse as a transformation engine.
ClickHouse supports materialized views that update incrementally as data arrives. This is powerful for building pre-aggregated tables that power dashboards without recomputing everything each time.
Example: Incremental Materialized View
sql
-- Create a materialized view that maintains hourly aggregates
CREATE MATERIALIZED VIEW hourly_page_stats
ENGINE = SummingMergeTree()
PARTITION BY toYYYYMM(hour)
ORDER BY (page_url, hour)
AS SELECT
page_url,
toStartOfHour(timestamp) AS hour,
count() AS views,
uniq(user_id) AS unique_users
FROM events
GROUP BY page_url, hour;
Now every time data hits the events table, ClickHouse automatically updates the hourly_page_stats table. Queries against hourly_page_stats are nearly instant because the heavy aggregation work happened during ingestion.
This pattern is how we build real-time dashboards at SIVARO. Ingest raw events, compute aggregates in materialized views, serve those aggregates to dashboards. Raw data stays available for ad-hoc queries, but 90% of queries hit pre-aggregated tables.
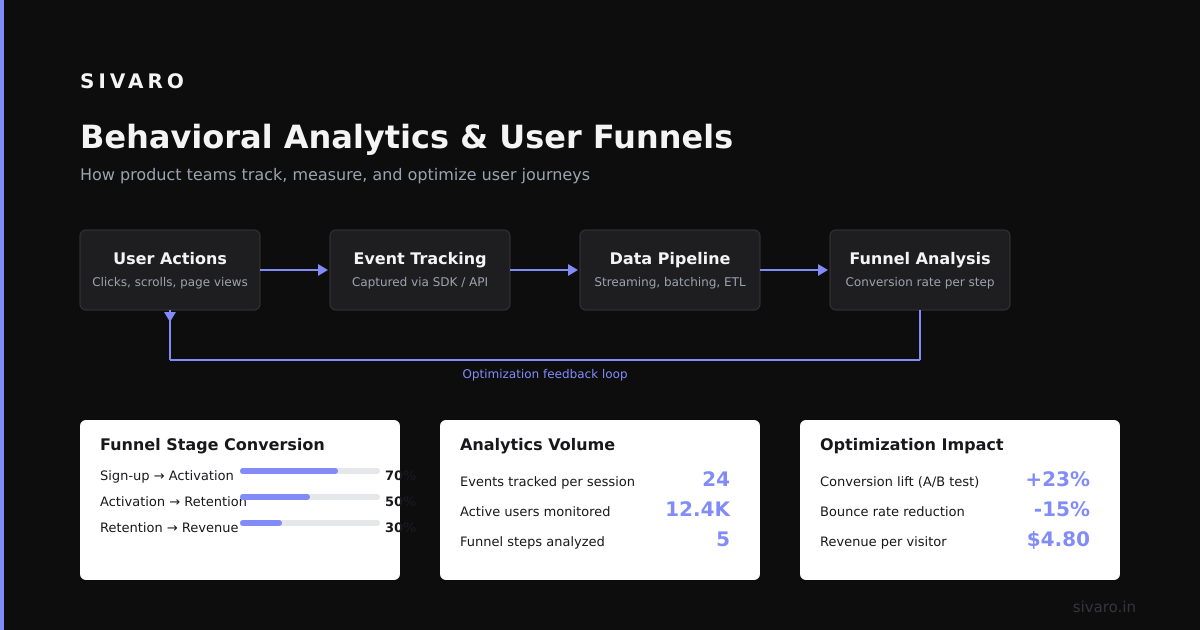
Behavioral Analytics and User Funnels
Product analytics platforms — Mixpanel, Amplitude, Heap — are expensive. They charge per event, and costs spiral as you grow.
ClickHouse lets you build your own analytics engine for a fraction of the cost. The pattern: ingest user events as rows, use ClickHouse's array functions and window functions to compute funnels and retention.
Example: User Funnel Analysis
sql
-- Track users who visited, added to cart, and purchased
WITH funnel_steps AS (
SELECT
user_id,
maxIf(step = 'page_view', timestamp) AS view_time,
maxIf(step = 'add_to_cart', timestamp) AS cart_time,
maxIf(step = 'purchase', timestamp) AS purchase_time
FROM user_events
WHERE timestamp > now() - INTERVAL 30 DAY
GROUP BY user_id
)
SELECT
count(*) AS total_users,
countIf(cart_time IS NOT NULL) AS added_to_cart,
countIf(purchase_time IS NOT NULL) AS purchased,
round(countIf(cart_time IS NOT NULL) * 100.0 / count(*), 1) AS cart_conversion,
round(countIf(purchase_time IS NOT NULL) * 100.0 / count(*), 1) AS purchase_conversion
FROM funnel_steps;
This query runs in seconds on datasets with hundreds of millions of events. The same query in PostgreSQL would take minutes and probably crash.
The Big Data Boutique team ran a practical comparison (Big Data Boutique) and found ClickHouse handled funnel queries 5-10x faster than Snowflake for the same data volume. The reason: ClickHouse's vectorized execution engine processes data in CPU cache-friendly chunks.
When NOT to Use ClickHouse
I've seen teams try to use ClickHouse for everything. That's a mistake. Here's where it fails:
- Transactional workloads. Don't put your OLTP data in ClickHouse. It can't handle point-updates or row-level locking. Use PostgreSQL or MySQL.
- High-concurrency user-facing queries. ClickHouse struggles above ~100 concurrent queries. For user-facing analytics, you need a caching layer in front.
- Complex multi-table JOINs. ClickHouse's JOIN performance is mediocre. It works for star schemas with one large fact table and small dimension tables. Complex joins across multiple large tables? Use Snowflake or Presto.
- Small datasets. If your data fits in a single PostgreSQL instance, ClickHouse is overkill. The operational complexity isn't worth it for datasets under 100GB.
Comparison with Other OLAP Systems
The Apache Doris vs ClickHouse vs Snowflake comparison (Velodb.io) highlights an important distinction: Doris is better at high-concurrency point queries, Snowflake at complex ad-hoc analytics, and ClickHouse at high-ingestion real-time aggregation.
I've tested Doris for a use case requiring 500 concurrent queries. It worked. ClickHouse at that concurrency level would need significant tuning and likely a proxy layer with result caching.
But for ingestion-heavy workloads — the "firehose of data" scenario — ClickHouse is unmatched. Its merge-tree engine constantly merges small parts into larger ones, optimizing for read performance over time. This is why it's the default choice for observability pipelines.
Operational Reality Check
Running ClickHouse in production is harder than Snowflake. You manage servers, configure storage, tune caches. But it's also cheaper at scale — dramatically cheaper.
At SIVARO, we run ClickHouse clusters for clients. The typical setup: 3-5 nodes with NVMe SSDs, 64GB RAM each. This handles 10TB of compressed data with sub-second queries. The total cost is around $2,000/month. For the same performance in Snowflake? Probably $8,000-12,000/month (ClickHouse comparison).
The trade-off is clear: pay with operations or pay with money.
FAQ: What is ClickHouse Used For?
Q: What is ClickHouse used for in production?
ClickHouse is used for real-time analytics, log and observability pipelines, time-series data analysis, user behavior analytics, and as a fast data warehouse for medium-scale analytical workloads.
Q: Is ClickHouse better than Snowflake for real-time analytics?
Yes, for sub-second queries on high-volume data. Snowflake is better for complex ad-hoc queries and high concurrency. Choose by workload, not by brand.
Q: Can ClickHouse replace Elasticsearch?
For log analytics and observability, yes. For full-text search, no. ClickHouse's strength is structured analytical queries, not text search relevance scoring.
Q: Does ClickHouse work for small datasets?
Technically yes. Practically, it's overkill. If your dataset is under 100GB, PostgreSQL with proper indexing will serve you better with less complexity.
Q: What are ClickHouse's main limitations?
Poor complex JOIN performance, limited concurrency (100-200 concurrent queries without tuning), no row-level updates, and higher operational overhead compared to managed services.
Q: What companies use ClickHouse in production?
Uber, Cloudflare, eBay, Cisco, and thousands of mid-size companies. It's battle-tested at massive scale.
Q: Is ClickHouse good for IoT data?
Excellent. Time-series data with time-based partitioning and high ingestion rates is ClickHouse's sweet spot.
Final Thoughts
I've been building data systems since 2018. I've used PostgreSQL, Elasticsearch, Snowflake, BigQuery, Druid, and ClickHouse. Each has its place. But when a client asks me "what is clickhouse used for?" my answer is always the same:
It's used for making the impossible query possible.
When your dashboards need real-time data. When your logs are growing faster than your storage budget. When your users expect answers in milliseconds, not minutes. That's when ClickHouse earns its keep.
It's not a general-purpose solution. It's a specialized tool for a specific job. But for that job — high-volume, real-time, analytical queries — nothing else comes close.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.