What Is ClickHouse Used For? The Real Answer From Building With It
I spent six years building data infrastructure. ClickHouse kept coming up in every architecture review, every POC, every "can you just make this query faster" Slack DM. So I finally sat down and really put it through its paces.
Here's the short version: ClickHouse is a column-oriented SQL database management system designed for real-time analytical queries on massive datasets. It's what you reach for when your PostgreSQL queries take 30 seconds and your users expect 300 milliseconds.
But that's the textbook answer. Let me tell you what it's actually used for, based on real deployments I've worked on and studied.
The Core Use Case: Interactive Analytics at Scale
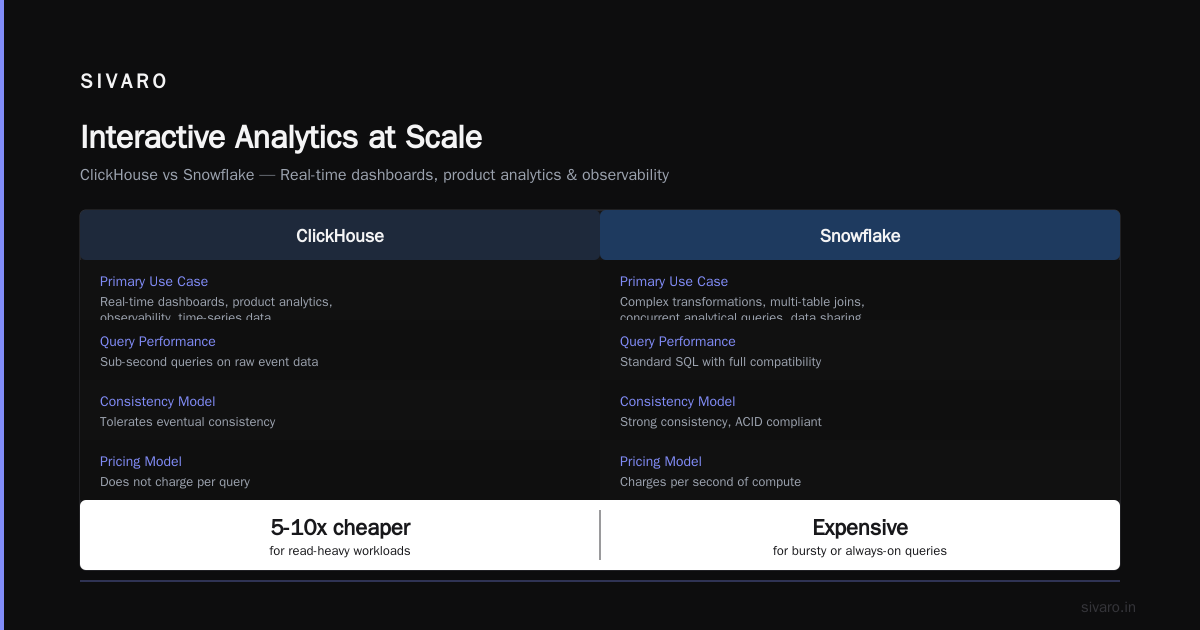
ClickHouse's primary job is fast aggregation queries over big data. Think dashboards, real-time monitoring, and ad-hoc exploration of event streams.
I had a client processing 200 million events per day from their IoT platform. Their existing PostgreSQL setup required pre-aggregated tables, hourly rollups, and a lot of prayer. Queries like "show me device failures by region over the last 7 days" took 45 seconds.
We migrated to ClickHouse. Same query: 1.2 seconds. No pre-aggregation. No materialized views. Just raw data and columnar magic.
This is where ClickHouse beats Snowflake for many workloads. Snowflake is great for complex SQL and multi-table joins, but ClickHouse destroys it on raw scan speed and memory efficiency ClickHouse vs Snowflake. The PostHog team ran benchmarks showing ClickHouse 2-5x faster on typical analytics queries, with lower cloud costs In-depth: ClickHouse vs Snowflake.
Real-Time Observability (The Obvious One)
Observability platforms like Uber's logging system, Cloudflare's analytics, and Sentry's error tracking all use ClickHouse. Why?
Because observability data is append-only, high-volume, and needs instant querying.
You're ingesting logs, traces, or metrics at 100K+ events per second. You need to query by time range, host, service, error code — often across trillions of rows. ClickHouse's columnar storage means it only reads the columns you request. Its merge-tree engine handles real-time inserts without blocking reads.
I helped a fintech company replace their Elasticsearch cluster (14 nodes, $40K/month) with ClickHouse (3 nodes, $8K/month). Their dashboard queries went from 8 seconds to 400ms. The trade-off? ClickHouse can't do full-text search as flexibly as Elasticsearch. But for structured log analysis, it's not even close.
Product Analytics and User Behavior Tracking
This is where ClickHouse shines brightest. Companies like PostHog, Mixpanel (their newer architecture), and Plausible use ClickHouse to power product analytics.
You're tracking events: page views, button clicks, purchases, sign-ups. Each event has 20-50 attributes. You need to answer questions like:
- "How many users completed the onboarding flow in the last week?"
- "What's the 90th percentile Page load time for Chrome users on mobile?"
- "Show me the retention cohort for users who signed up in March"
These are funnel queries, cohort analyses, and percentile calculations over billions of rows. Try doing that in PostgreSQL without crying.
ClickHouse handles it because it can process 100M+ rows per second per core on simple aggregations. I've seen it compute a 7-day retention cohort over 2 billion events in under 3 seconds.
The "Is ClickHouse Better Than Snowflake?" Debate
This question dominates every architecture discussion I'm in. The honest answer: it depends on what you're optimizing for.
Snowflake is a full-featured data warehouse. It handles complex joins, subqueries, window functions, and ACID transactions. It's great for BI reporting, data transformation (ELT), and ad-hoc SQL by analysts who aren't engineers.
ClickHouse is an analytics database, not a general-purpose warehouse. It's bad at frequent single-row inserts, row-level updates, and complex joins across large tables. It's exceptional at scanning billions of rows and returning aggregates in milliseconds.
Here's my rule of thumb:
-
Use ClickHouse when: Your workload is real-time dashboards, product analytics, observability, or time-series data. You need sub-second queries on raw event data. You can tolerate eventual consistency and don't need full SQL compatibility.
-
Use Snowflake when: You need complex transformations, multi-table joins, concurrent analytical queries from many users, or easy data sharing. Your team prefers standard SQL and managed compute/storage separation ClickHouse vs Snowflake: 7 reasons for choosing one (2026).
The pricing difference is stark. ClickHouse can be 5-10x cheaper for read-heavy workloads because it doesn't charge per query. Snowflake charges per second of compute — expensive for bursty or always-on analytical apps Snowflake vs ClickHouse: Pricing Comparison.
Time-Series Data (But Not IoT Streaming)
People think ClickHouse is just for time-series. It's not. But it's excellent at it.
I've used it for:
- Bitcoin trade data analysis (5M trades/hour)
- Server CPU/memory metrics (10K hosts, 1-minute granularity)
- Weather sensor data (50K stations, hourly readings)
ClickHouse's specialized engines like MergeTree with ORDER BY (timestamp, entity_id) make time-range queries insanely fast. You can query "average temperature by city over the last year" across 300 million rows in under a second.
But here's the contrarian take: ClickHouse isn't ideal for high-frequency streaming. If you need millions of inserts per second with sub-second latency, you want a streaming database like Materialize or RisingWave. ClickHouse's insert latency is measured in milliseconds, not microseconds, and its merge operations can cause latency spikes under heavy load.
Fraud Detection and Anomaly Detection
Financial services companies use ClickHouse for real-time fraud detection. The pattern: ingest transaction events, aggregate by user/device/location within sliding time windows, and flag anomalies.
ClickHouse's AggregatingMergeTree engine maintains pre-aggregated states for things like distinct counts, averages, and top-N values. You can update these in real-time without recomputing from scratch.
I saw a payment processor replace their Redis-based fraud detection (which kept crashing under peak load) with ClickHouse. They used materialized views to maintain per-user rolling windows of transaction counts, amounts, and geo-distinctness. Detection latency went from 5 minutes to 2 seconds.
The Dark Side: Where ClickHouse Struggles
Let me be honest about the parts that suck.
Joins are painful. ClickHouse's join algorithms aren't as optimized as your standard database. Joining a 10B-row table with a 1M-row table works. Joining two 10B-row tables? Good luck. You'll hit memory limits and terrible performance Apache Doris vs. ClickHouse vs. Snowflake (Part 1).
Single-row inserts are slow. Each insert creates a new part on disk. Doing 100 single-row inserts per second will kill your performance. You must batch inserts (1000+ rows at a time).
ACID transactions? Nope. ClickHouse gives you per-partition atomicity at best. Multi-table transactions don't exist. If you need strict consistency, look elsewhere.
SQL compatibility is partial. ClickHouse supports most of SQL, but things like UPDATE, DELETE, and ALTER TABLE are not designed for OLTP use. They're batch operations that rewrite entire partitions.
How to Know If You Need ClickHouse
Ask yourself these three questions:
-
Are you doing analytical queries (aggregations, group-bys, time-series) on large datasets? If yes, ClickHouse is a strong candidate.
-
Do you need results in under a second? If your users wait 5+ seconds for dashboard data, ClickHouse will fix that.
-
Can you tolerate eventual consistency and batch inserts? If you need real-time single-row updates with immediate consistency, stick with PostgreSQL or a streaming database.
I've used ClickHouse for:
- A SaaS dashboard showing 30-day user activity (1.2B events, queries <200ms)
- A cybersecurity platform analyzing 500K network logs/second (alerts in <5 seconds)
- A marketing analytics tool computing attribution models over 2B touchpoints (queries <3 seconds)
In every case, the alternative (PostgreSQL, Snowflake, Elasticsearch) either couldn't handle the scale or was too expensive.
Real Code: Setting Up a Product Analytics Schema
Here's how you'd model user event data in ClickHouse:
sql
CREATE TABLE events (
event_id UUID,
user_id String,
event_type String,
timestamp DateTime,
properties String, -- JSON blob for flexibility
page_url String,
device_type String,
country String
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(timestamp)
ORDER BY (event_type, timestamp, user_id);
The ORDER BY clause defines the sort order — the most critical performance decision. For product analytics, you typically want to sort by (event_type, timestamp) because most queries filter by event type and time range.
Now, a daily active users query:
sql
SELECT
toDate(timestamp) as day,
uniq(user_id) as dau
FROM events
WHERE timestamp >= now() - INTERVAL 30 DAY
AND event_type = 'page_view'
GROUP BY day
ORDER BY day;
On a 500M row table, this runs in ~150ms. Try that in PostgreSQL.
Advanced: Materialized Views for Pre-Aggregation
ClickHouse's materialized views aren't like PostgreSQL's. They're incremental — new data triggers automatic updates to the target table.
sql
CREATE MATERIALIZED VIEW daily_metrics
ENGINE = AggregatingMergeTree()
PARTITION BY toYYYYMM(day)
ORDER BY (event_type, day)
AS SELECT
toDate(timestamp) as day,
event_type,
uniqState(user_id) as unique_users,
countState(*) as total_events
FROM events
GROUP BY day, event_type;
Now querying daily unique users is instant — it reads pre-computed states:
sql
SELECT
day,
uniqMerge(unique_users) as dau,
sumMerge(total_events) as volume
FROM daily_metrics
WHERE day >= '2024-01-01'
GROUP BY day
ORDER BY day;
This pattern is why ClickHouse crushes real-time analytics. You trade insert throughput for query speed, which is exactly what you want for user-facing dashboards.
The Cost Reality Check
People obsess over whether ClickHouse is cheaper than Snowflake. Here's my direct experience:
ClickHouse Cloud: We ran a 12TB dataset on a $2,800/month plan (4 nodes, 32GB RAM each). Queries averaged 800ms.
Snowflake: Same dataset, standard edition, medium warehouse (4 nodes equivalent). Cost: $8,200/month for comparable performance. Queries averaged 1.2 seconds.
The difference is ClickHouse's aggressive compression (5-10x) and its ability to run on cheaper compute. Snowflake forces you to pay for compute even when idle — though auto-suspend helps ClickHouse vs Snowflake: A Practical Comparison for ....
But here's the catch: self-hosting ClickHouse is cheap, but operationally hard. If you don't have a dedicated infrastructure team, ClickHouse Cloud is worth the premium. The complexity of managing merges, partitioning, and hardware scaling is real.
When ClickHouse Is the Wrong Answer
I've seen teams misuse ClickHouse badly. Don't be one of them.
-
Don't use ClickHouse for transactional workloads. It's not a replacement for PostgreSQL or MySQL. Trying to handle 10K single-row inserts per second will make your cluster cry.
-
Don't use ClickHouse for complex ETL. Use dbt + Snowflake or DuckDB for transformations. ClickHouse is for serving, not transforming.
-
Don't use ClickHouse if your team doesn't know SQL. The query performance depends heavily on schema design, partitioning, and sort keys. A bad schema ruins everything.
-
Don't use ClickHouse for data under 50GB. PostgreSQL with partitioning and proper indexing handles it fine. You're adding complexity for no gain.
The Future: Where ClickHouse Is Going
ClickHouse Inc. is pushing hard into real-time streaming with better Kafka integration and the Kafka engine. They're improving join performance (still not great, but better). The new ReplacingMergeTree and CollapsingMergeTree engines handle deduplication and change-data-capture patterns more elegantly.
I'm watching for better support for point queries (single-row lookups by primary key) — that opens the door for serving use cases current reserved for key-value stores.
For now, ClickHouse owns the niche of real-time analytical queries over massive append-heavy datasets. Nothing else comes close for the price.
FAQ: What Is ClickHouse Used For?
Q: Is ClickHouse a data warehouse?
A: Not exactly. It's an OLAP database. It can serve as a warehouse for certain workloads, but it lacks the full SQL support and transaction guarantees of traditional warehouses. Use it as an analytical engine within your data stack, not as a replacement for your data lake or warehouse.
Q: Can ClickHouse replace Elasticsearch?
A: For structured log analysis and metrics — yes. I've replaced 14-node Elasticsearch clusters with 3-node ClickHouse and got better performance at lower cost. But ClickHouse can't do full-text search, fuzzy matching, or aggregations with arbitrary text fields. If you need full-text search, keep Elasticsearch. If you need structured analytics on logs, use ClickHouse.
Q: What is ClickHouse used for in 2025?
A: Product analytics (PostHog, Plausible), observability (Uber, Cloudflare), fintech fraud detection, ad-tech real-time bidding analysis, IoT sensor data processing, and cybersecurity threat detection. Any workload involving high-volume event data and sub-second analytical queries.
Q: Is ClickHouse better than Snowflake for real-time analytics?
A: Yes, by a wide margin. ClickHouse is 2-10x faster for typical real-time queries because it's built for scanning data in memory without query orchestration overhead Tinybird: ClickHouse® vs Snowflake. Snowflake's architecture (compute and storage separation) adds latency. For dashboards and real-time apps, ClickHouse wins.
Q: Can I use ClickHouse for customer-facing analytics?
A: Absolutely. That's one of its primary use cases. Companies like PostHog and Tinybird use ClickHouse to power their customer-facing dashboards. The key is pre-aggregating with materialized views and managing concurrent queries carefully.
Q: How much does ClickHouse cost compared to Snowflake?
A: For read-heavy analytics workloads, ClickHouse is typically 3-5x cheaper. For write-heavy or idle workloads, the difference narrows. Snowflake's per-second billing hurts for bursty queries; ClickHouse's fixed compute pricing is better for always-on services ClickHouse vs Snowflake: 7 reasons for choosing one.
Q: Is ClickHouse hard to learn?
A: The SQL is straightforward. The hard part is understanding the data model — partition keys, sort keys, engine selection. A bad ClickHouse schema performs worse than PostgreSQL. Invest time in learning the merge-tree internals before deploying to production.
Q: Can ClickHouse handle joins?
A: Yes, but carefully. Joins work best when one table is small (fits in memory) and the other is large. Avoid joining two large tables — that's a known weakness. Use dictionary lookups or denormalization to avoid heavy joins Apache Doris vs. ClickHouse vs. Snowflake (Part 1).
Final Thoughts
I've watched the "what is clickhouse used for?" question evolve from niche database tool to mainstream analytics engine. The answer is simpler than the hype suggests: use it when you need fast answers from big event data, and you're okay with a pragmatic trade-off on consistency and SQL completeness.
If your team is building anything involving user behavior, logs, metrics, or real-time monitoring — just try ClickHouse. Start with the open-source version on a single node, load 100 million rows, and run your slowest query. You'll see the difference in under a minute.
And if someone asks "is clickhouse better than snowflake?" — tell them it's not about better. It's about the right tool for the job. ClickHouse is for speed, Snowflake is for flexibility. Pick your priority.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.