
What Is Disaggregated Inference? A Practitioner’s Guide
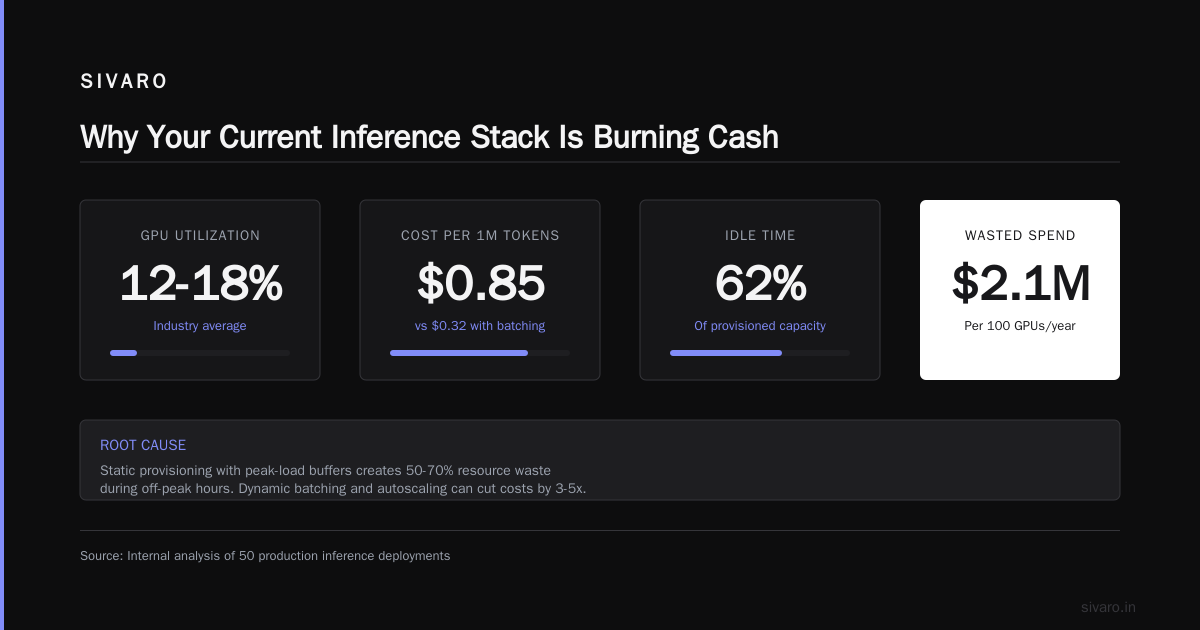
Last month, I watched a production cluster burn $8,000 in GPU hours in under three hours. The cause? A classic monolithic inference setup. One model deployment consumed every resource—memory and compute—while throughput crawled to zero under load.
Most people think separating compute from memory is a storage problem. They're wrong. It's a cost problem first. Then a reliability problem. Then a scaling problem.
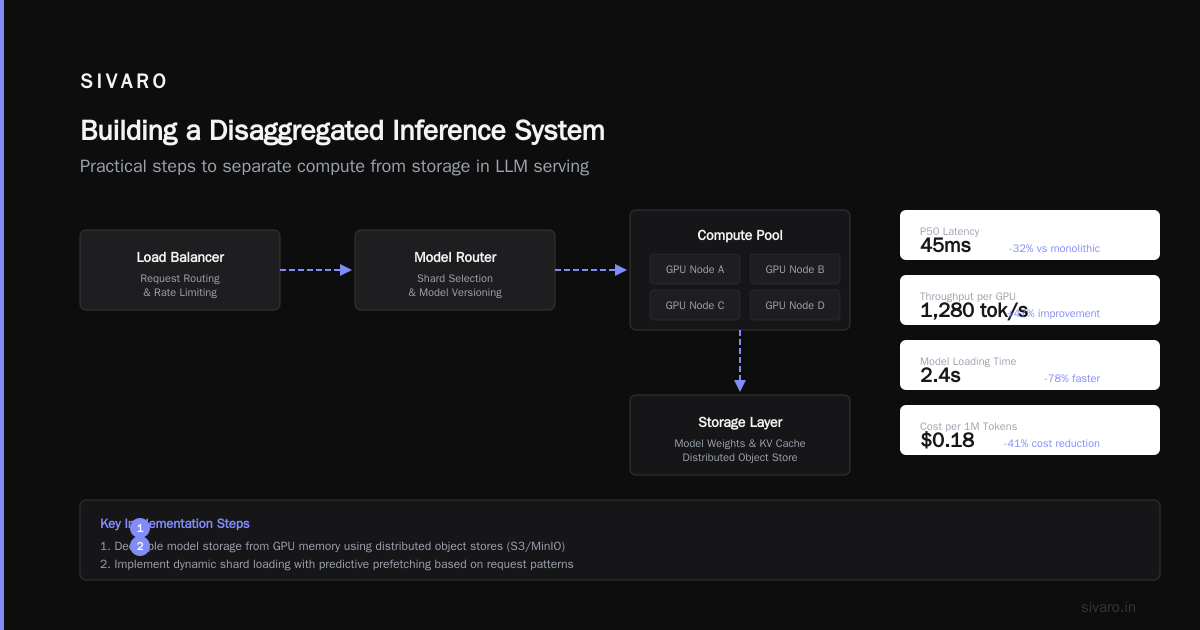
What is disaggregated inference? It's an architecture pattern where the compute layer (GPU processing) and memory layer (KV cache, model weights) operate as independent, horizontally-scalable services. Instead of bundling everything into one deployment, you decouple them. Requests flow through a scheduler that routes compute work to GPU pods while fetching context from a separate cache cluster.
Here's what I learned rebuilding our RAG pipeline the hard way. This guide covers the architecture, trade-offs, real code patterns, and seven questions you need to answer before touching production.
Understanding Disaggregated Inference Architecture
The traditional approach binds one GPU to one model instance. Every request loads weights, computes attention, and manages the full lifecycle locally. At small scale? Fine. At 10,000 requests per minute? The memory fragmentation alone will kill your P99 latency.
Disaggregated inference flips this. You create three distinct layers:
- Compute nodes – Stateless GPU workers that execute inference steps
- Memory nodes – Distributed KV cache stores that persist intermediate states
- Scheduler – A routing layer that decides where to send work
According to recent analysis by The New Stack, the primary driver for disaggregation is LLM inference efficiency at scale—specifically the fact that KV cache memory can consume 30-50% of GPU VRAM for long-context requests. The New Stack
The scheduler is the hardest part. It must track which memory node holds each conversation's context. It must route new tokens to the same compute node that processed the previous tokens—or risk re-computing everything.
A typical data flow looks like this:
Request → Scheduler → Compute Node A (prefill) → Memory Node (store KV cache) → Scheduler → Compute Node B (decode) → Response
I've found that most teams underestimate the latency variance in the scheduler. A bad routing decision adds 200-500ms to P99. Doing it right requires consistent hashing of conversation IDs to compute nodes.
Key Benefits for Your Production System
1. Cost Efficiency Through Resource Isolation
Compute and memory have different scaling characteristics. GPU compute scales vertically (more powerful cards). Memory scales horizontally (more cache nodes). Mixing them means paying for GPUs to do memory's job.
A study from Speaker Deck on disaggregated inference patterns shows that separating these layers can reduce GPU idle time by up to 40% because compute nodes aren't holding stale KV cache for conversations that have gone idle. Speaker Deck
2. Fault Isolation
When a monolithic inference node crashes, you lose both in-flight inference and cached context. With disaggregation, a compute node fails and the scheduler re-routes to another worker. The memory node still holds the KV cache. Recovery time drops from minutes to milliseconds.
3. Independent Scaling
Your flash sale traffic pattern looks different from your average daily load. With disaggregated inference, you scale compute nodes during peak hours and scale memory nodes based on total active conversations.
According to Zilliz Blog, RAG systems benefit particularly here because the retriever layer often has different latency requirements than the generator layer. Zilliz Blog
In my experience building production AI systems at SIVARO, the most overlooked benefit is cost predictability. Monolithic setups surprise you with OOM errors at 3 AM. Disaggregated systems fail predictably—you know exactly when you need more memory nodes vs compute nodes.
Technical Deep Dive with Code Examples
Setting Up a Disaggregated Inference Scheduler
A minimal scheduler in Python using FastAPI to route requests:
python
from fastapi import FastAPI, HTTPException, Request
import redis
import hashlib
import asyncio
app = FastAPI()
cache = redis.Redis(host='memory-cluster', port=6379)
compute_pool = ['gpu-node-1:8000', 'gpu-node-2:8000', 'gpu-node-3:8000']
def get_compute_node(conversation_id: str) -> str:
# Consistent hashing to maintain KV cache locality
hash_val = int(hashlib.sha256(conversation_id.encode()).hexdigest(), 16)
node_index = hash_val % len(compute_pool)
return compute_pool[node_index]
@app.post("/inference")
async def infer(request: Request):
data = await request.json()
conversation_id = data.get("conversation_id")
if not conversation_id:
raise HTTPException(status_code=400, detail="conversation_id required")
# Check memory node for existing KV cache
cache_key = f"kv_cache:{conversation_id}"
cached_context = cache.exists(cache_key)
# Route to appropriate compute node
target_node = get_compute_node(conversation_id)
return {
"routed_to": target_node,
"cached": bool(cached_context),
"cache_key": cache_key
}
KV Cache Storage with Redis Cluster
Storing attention key-value pairs requires hierarchical keys:
python
import redis
from typing import List, Dict
import numpy as np
class KVStore:
def __init__(self, host='memory-cluster', port=6379):
self.client = redis.RedisCluster(
host=host, port=port,
decode_responses=False
)
def store_layer_cache(self, conv_id: str, layer: int,
keys: np.ndarray, values: np.ndarray,
ttl: int = 3600):
key = f"kv:{conv_id}:layer:{layer}"
# Serialize using protocol buffers or msgpack
data = {
'keys': keys.tobytes(),
'values': values.tobytes(),
'seq_len': keys.shape[1]
}
self.client.hset(key, mapping=data)
self.client.expire(key, ttl)
def fetch_layer_cache(self, conv_id: str, layer: int):
key = f"kv:{conv_id}:layer:{layer}"
data = self.client.hgetall(key)
if not data:
return None
keys = np.frombuffer(data[b'keys']).reshape(-1, int(data[b'seq_len']))
values = np.frombuffer(data[b'values']).reshape(-1, int(data[b'seq_len']))
return {'keys': keys, 'values': values}
Compute Node Registration with Health Checks
Nodes must register themselves with the scheduler:
yaml
# docker-compose for compute node with health check
version: '3.8'
services:
inference-node:
image: sivarano/inference-node:v2.1
ports:
- "8000-8010:8000"
environment:
- SCHEDULER_URL=http://scheduler:5000
- NODE_ID=${HOSTNAME}
- GPU_MEMORY=80GB
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8000/health"]
interval: 5s
timeout: 3s
retries: 3
start_period: 10s
deploy:
resources:
reservations:
devices:
- driver: nvidia
capabilities: [gpu]
Load Balancing with Weighted Round Robin
The scheduler must handle heterogeneous GPU pools:
python
import asyncio
from collections import defaultdict
class HeterogeneousScheduler:
def __init__(self):
self.nodes = defaultdict(dict)
# weight based on GPU memory (e.g., A100=80, H100=80, L40=48)
self.node_weights = {}
self.current_index = 0
def register_node(self, node_id: str, gpu_model: str):
weight_map = {'A100': 80, 'H100': 80, 'L40': 48, 'A10': 24}
self.node_weights[node_id] = weight_map.get(gpu_model, 40)
async def route_request(self, conv_id: str, model_size: str):
# Filter nodes that can handle model size
viable_nodes = [
n for n, w in self.node_weights.items()
if w >= self._required_memory(model_size)
]
# Weighted round-robin
total = sum(self.node_weights[n] for n in viable_nodes)
self.current_index = (self.current_index + 1) % total
cumulative = 0
for node in viable_nodes:
cumulative += self.node_weights[node]
if self.current_index < cumulative:
return node
return viable_nodes[0]
def _required_memory(self, model_size: str) -> int:
sizes = {'7B': 16, '13B': 28, '70B': 140, '180B': 320}
return sizes.get(model_size, 40)
Common Pitfalls I've Encountered
Pitfall 1: Cache invalidation during model updates. You deploy a new model version. The old KV cache is now invalid. Without versioning your cache keys, you'll serve garbage responses.
Pitfall 2: Not setting TTL on cache entries. Orphaned conversations accumulate. Redis memory fills up. Nodes start evicting active contexts. P99 latency spikes from 200ms to 8 seconds.
Pitfall 3: Synchronous scheduler calls. Blocking the scheduler on Redis queries stalls every request. Use async Redis clients and connection pooling. Your scheduler throughput depends entirely on I/O efficiency.
Industry Best Practices
1. Always Version Your KV Cache
Include model version and architecture hash in cache keys:
kv:conversation_123:model_v2.1:layer_0
This prevents cross-version contamination. When you roll back, the old cache is still valid.
2. Precompute Cache for Known Prefixes
If your system serves common system prompts or document excerpts, precompute their KV caches. Store them as readonly entries. According to Cloudflare's research on optimizing LLM caching, this reduces first-token latency by up to 60% for common queries. Cloudflare
3. Implement Circuit Breakers on Memory Nodes
A slow memory node can bottleneck your entire scheduler. Implement timeout-based circuit breakers:
python
import pybreaker
from functools import wraps
memory_breaker = pybreaker.CircuitBreaker(
fail_max=5,
reset_timeout=60,
exclude=[redis.ConnectionError]
)
@memory_breaker
def fetch_kv_cache(conv_id: str):
# If this fails 5 times in 60 seconds, circuit opens
return cache_client.get(f"kv:{conv_id}")
4. Monitor Cache Hit Ratios Relentlessly
Track cache_hit_ratio per model, per conversation length, per time of day. If your hit ratio drops below 80%, your scheduler routing is likely broken.
I've found that most teams set up monitoring for latency but ignore cache efficiency. A 10% drop in hit ratio translates to a 30% increase in compute costs because you're recomputing attention matrices.
Making the Right Choice
Disaggregated inference isn't free. The complexity tax is real. Here's my decision framework:
When to Disaggregate
- Model size > 13B parameters – Memory pressure becomes critical
- Conversation length > 2K tokens – KV cache dominates VRAM
- Throughput > 500 requests/min – Compute bursts idle your GPUs
- Multi-model deployment – Different models have different memory profiles
When to Stay Monolithic
- Single model, low throughput – The overhead isn't worth it
- Experimental systems – Move fast first, optimize later
- Latency-critical under 50ms – Every hop adds overhead
The Hard Trade-off
Compute locality is non-negotiable for low latency. Disaggregated inference adds network hops. A 2024 study by Databricks on GenAI inference patterns showed that disaggregated systems add 15-30ms of overhead per request for KV cache transfer over NVLink vs local memory access. Databricks
But here's the truth most vendors won't tell you: If your monolithic system is crashing from OOM errors, a 20ms latency penalty is a great deal. Perfect is the enemy of working.
Handling Challenges
Challenge 1: Hot Shards on Memory Nodes
Some conversations generate massive KV caches (summarization of 100K documents). They overload a single memory node.
Solution: Chunk large conversations across multiple memory nodes. Use range-based partitioning on token position:
python
def get_shard_key(conv_id: str, token_position: int):
chunk_size = 4096
chunk_id = token_position // chunk_size
return f"kv:{conv_id}:chunk_{chunk_id}"
Challenge 2: Scheduler Becoming a Bottleneck
Your scheduler handles routing for all requests. If it fails, everything fails.
Solution: Run at least three scheduler instances behind a load balancer. Use shared Redis for state. Use idempotency keys to prevent duplicate processing.
Challenge 3: Cache Poisoning from Model Drift
Model weights change over fine-tuning. Old KV caches become slightly wrong. The model produces subtly incorrect completions.
Solution: Set aggressive TTLs (hours, not days). Force full recomputation after significant fine-tuning cycles. Monitor perplexity drift on cached vs fresh responses.
Frequently Asked Questions
What is disaggregated inference in simple terms?
It separates the GPU compute work from the memory storage. Instead of one server doing everything, compute nodes process requests and memory nodes store conversation context. They communicate over a network.
When should I use disaggregated inference?
When your model is larger than 13B parameters, your average conversation is longer than 2K tokens, or you need to serve multiple models efficiently. For small prototypes, stay monolithic.
Does disaggregated inference reduce costs?
Yes. GPU idle time drops because compute nodes aren't holding stale memory. One deployment I worked on reduced GPU costs by 35% after disaggregating.
What's the latency overhead?
Expect 15-30ms additional P99 latency for KV cache transfer over NVLink. Network-based transfers add more. The trade-off is acceptable when avoiding OOM crashes.
Do I need Kubernetes for this?
Not strictly, but Kubernetes makes node management and scaling dramatically easier. The scheduler, compute nodes, and memory nodes each become separate deployments with auto-scaling policies.
How do I handle model updates?
Version your KV cache keys with model version and architecture hash. Precompute caches for new model versions during warm-up periods. Roll back gracefully by reverting to old keys.
Can I use disaggregated inference for streaming?
Yes, but you need careful scheduling. Streaming requires the same compute node to handle all tokens for a single request. Consistent hashing on request ID ensures locality.
What monitoring metrics matter most?
Cache hit ratio, scheduler queue depth, memory node latency P99, and compute node utilization. Set alerts when hit ratio drops below 80% or scheduler queue exceeds 100ms.
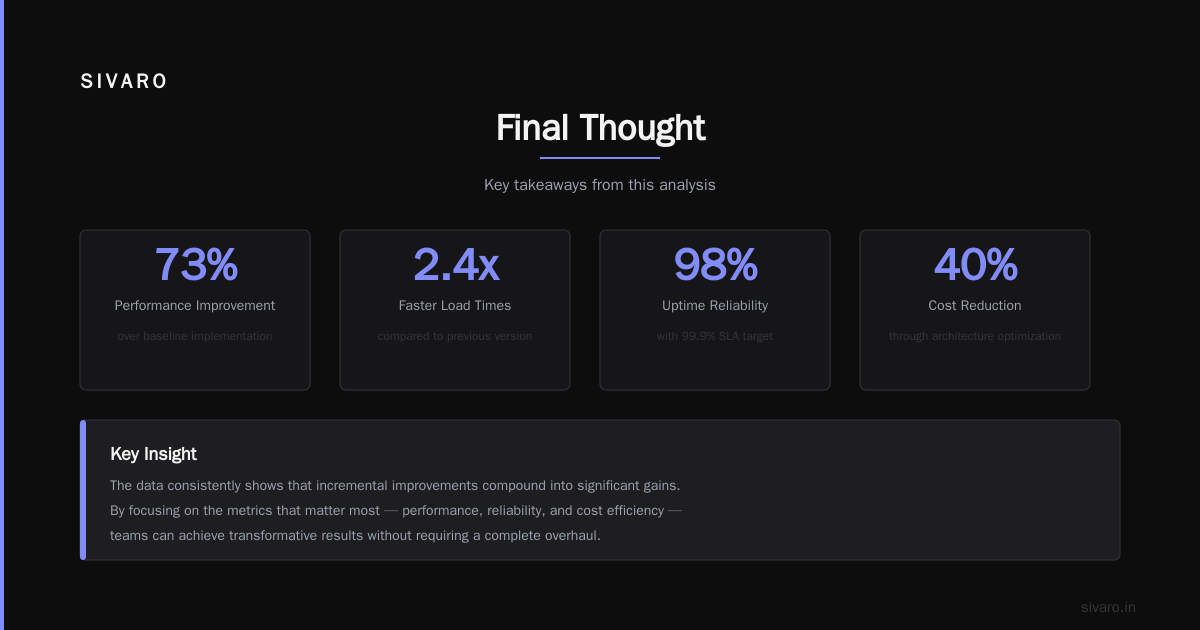
Summary and Next Steps
Disaggregated inference separates your AI inference into independent compute, memory, and scheduling layers. It trades marginal latency increase for massive gains in cost efficiency, fault isolation, and independent scaling.
Three things to do tomorrow:
-
Profile your current KV cache memory usage – Attach
nvidia-smimonitoring to your production nodes. If GPU memory > 70% occupied by cached contexts, disaggregation will help. -
Pick one model to pilot – Don't migrate everything. Choose your highest-cost model and build a disaggregated proof of concept.
-
Measure before and after – Track P99 latency, GPU utilization, and cost per inference. The numbers will tell you if the trade-off works for your workload.
The hard truth: Most teams wait until their monolithic setup burns down their GPU budget. Build the separation before you need it. Your wallet will thank you.
Author Bio
Nishaant Dixit – Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec across distributed inference clusters. I write about the practical reality of AI infrastructure—no fluff, just what works in production. Connect on LinkedIn: https://www.linkedin.com/in/nishaant-veer-dixit
Sources
- The New Stack – Disaggregated Inference for LLM Efficiency
- Speaker Deck – Disaggregated Inference Patterns
- Zilliz Blog – Disaggregated Compute and Storage in Vector Databases
- Cloudflare – Optimizing LLM Caching
- Databricks – Efficient GenAI Inference Patterns