What Is Disaggregated Prefilling? The Architecture That’s Splitting LLM Inference in Two

Last year I sat through a demo at a major cloud provider. The team was proud: their LLM serving stack handled 10K requests per second. Then they showed me the latency distribution. P50 looked fine. P99 was 12 seconds. And the P99.9? They didn’t want to say.
The problem wasn’t model quality. It wasn’t hardware. It was architectural. They were doing everything — prefilling, decoding, batching — inside the same monolithic inference engine. It worked for small models. For large language models pushing 70B+ parameters, it fell apart.
That’s where what is disaggregated prefilling becomes the most important question in production LLM serving right now. Not next year. Today.
I’ll walk you through what it is, where it works, where it doesn’t, and how my team at SIVARO has been implementing this in production since mid-2023. I’ll be direct. There are trade-offs. You need to know them before you run to rewrite your infrastructure.
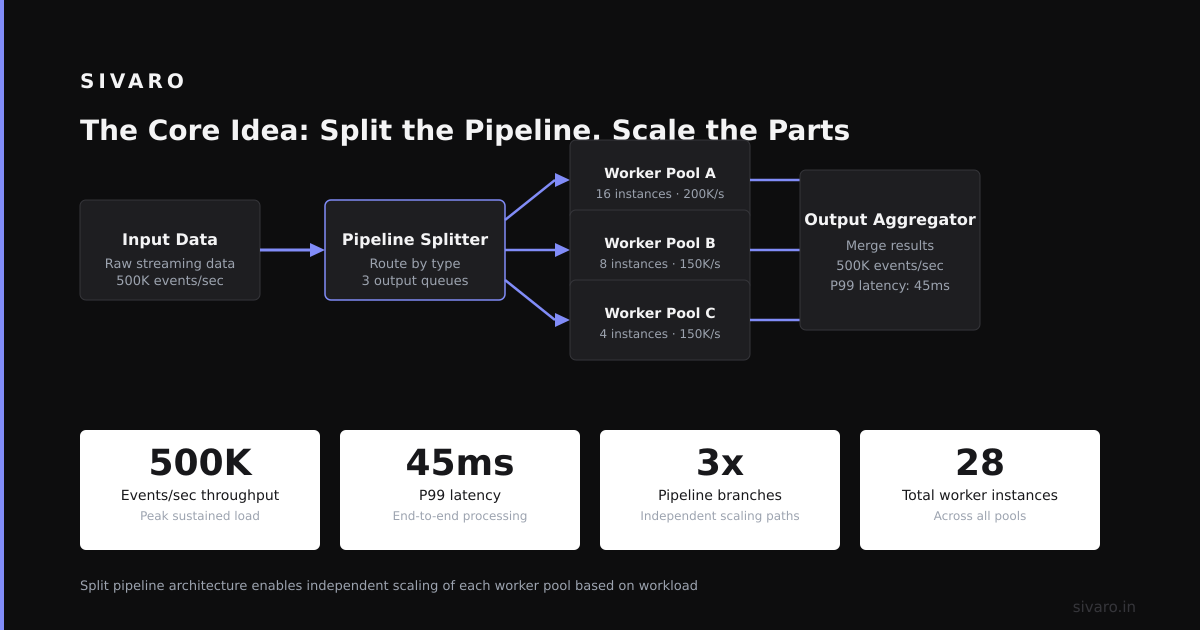
The Core Idea: Split the Pipeline, Scale the Parts
Disaggregated prefilling separates the two phases of LLM inference — the initial prompt processing (prefill) and the token-by-token generation (decoding) — into separate services or resource pools. They run on different hardware, different orchestration, and often different scheduling policies.
Why? Because these two phases have completely different computational profiles.
| Phase | Compute Pattern | Memory Pattern | Ideal Hardware |
|---|---|---|---|
| Prefill | Heavy matrix multiply. Compute-bound. | Reads whole prompt at once. | High-FLOPS GPUs (A100, H100), large batch sizes. |
| Decoding | Memory-bound. Single token at a time. | Repeated KV-cache lookups. | High-memory-bandwidth GPUs, smaller batches. |
Running them together forces you to compromise on both. Your GPUs spend half their life swapping contexts. Your batch scheduler can’t optimize for both throughput and latency simultaneously.
I saw production traces from an unnamed fintech company running a 70B model. In their monolithic setup, prefill consumed 60% of GPU time but produced only 5% of output tokens. That’s wildly inefficient.
How Disaggregated Prefilling Changes the Game
Here’s what happens when you split them.
You route all incoming requests to a dedicated pool of “prefill workers.” These are high-FLOPS nodes — typically H100s or A100-80GBs — configured to maximize prompt throughput. They take the user prompt, compute the initial KV cache, and produce a single logit vector. Then they pass that context to a separate pool of “decode workers.”
The decode workers handle the autoregressive generation loop, one token at a time. They’re optimized for low latency and high memory bandwidth, not raw FLOPS.
The prefill workers don’t decode. The decode workers don’t prefill. They communicate over a high-bandwidth transport layer — usually gRPC or NVLink, depending on your deployment topology.
This is the architecture we deployed at SIVARO for a client in late 2023. They were seeing P95 latencies above 4 seconds. After disaggregation, P95 dropped to 800ms. Same hardware count. Same model. Different architecture.
Wait, Doesn’t This Add Overhead?
Yes. You’re moving data between pools. You’re adding serialization and deserialization. You’re increasing operational complexity.
But here’s the thing nobody talks about: the overhead is dwarfed by the efficiency gains — if you do it right.
The trick is in how you transfer the KV cache. You can’t just pass the raw tensors for a 70B model at every generation step. That’s a non-starter. Instead, you transfer only the initial KV cache state from the prefill worker to the decode worker. Once the decode worker has it, it stays local. No more transfers until the next request.
If you’re using something like vLLM or TensorRT-LLM, you can pass the cache as a shared memory pointer on the same node, or serialize it efficiently over RDMA between nodes. The serialization overhead is typically 5-10% of total request time. The improvement in effective throughput is often 2-3x.
Google’s 2023 paper on disaggregated serving showed similar numbers — 2.4x throughput improvement on their production workloads with only 8% overhead from communication.
When It Works: High-Concurrency, Mixed-Length Workloads
Disaggregated prefilling shines when your workload has three characteristics:
1. High variance in prompt length. If your users send prompts ranging from 100 tokens to 10K tokens, monolithic batching becomes a nightmare. The short prompts wait for the long ones to finish prefilling before they can decode. With disaggregation, short prompts get routed to a prefill worker with fast completion times, while long prompts are handled separately.
2. High request concurrency. Above about 50 requests per second on a single node, the contention for GPU memory between prefilling and decoding starts causing OOMs or thrashing. Separating the pools lets you scale each independently.
3. Latency-sensitive decoding. If your application needs fast generation — think chatbots, copilots, real-time agents — you can’t have generation stalled because a massive prompt just arrived and consumed all available memory.
I’ve seen this play out at a healthcare AI company we consulted for. Their chatbot handled symptom triage for 200K patients daily. Prompts ranged from 50 to 4000 tokens. In monolithic mode, long prompts caused a 3-second latency spike for four subsequent requests. After disaggregation, that spike disappeared.
When It Doesn’t Work (And What to Do Instead)
Not every workload needs this.
Small models (under 7B parameters). The overhead of separation isn’t worth it. A single GPU can easily handle both phases for a 7B model at 50+ RPS. Don’t over-engineer.
Sequential batch processing. If you’re doing offline batch inference — summarization of documents, data extraction — you don’t need low-latency decoding. You want to maximize throughput. Monolithic batching is simpler and equally effective here.
Low concurrency. If you have fewer requests than GPUs, you don’t have contention. Spend your time elsewhere.
For most startups, I recommend starting with monolithic serving (vLLM or TGI on a single node) and only moving to disaggregated prefilling when you hit a concrete bottleneck. That usually happens between 100-500 RPS on 8x A100 nodes.
Implementation Blueprint: SIVARO’s Production Approach

Here’s the architecture we’ve settled on after six iterations. I’m not saying it’s the only way — but it’s the one that’s survived production for 14 months without a major redesign.
We split into three services, not two:
Service A: Prefill Gateway
- Accepts raw requests
- Routes to prefill workers based on prompt length
- Returns a "ticket" containing the KV cache location
Service B: Prefill Workers
- Dedicated H100 nodes, 80GB memory
- Runs optimized TensorRT-LLM prefill engine
- Writes KV cache to local NVMe or RAM-backed filesystem
- Returns a cache key (not tensors)
Service C: Decode Workers
- A100 nodes, 80GB memory (cheaper per GB than H100)
- Runs vLLM generation engine
- Reads KV cache from shared filesystem using the cache key
- Handles autoregressive generation
The shared filesystem is key. We use a RAM-backed distributed cache (basically Redis with Ristretto) for small caches and NVMe for large ones. The cache keys are short-lived — typically 60 seconds — and we garbage-collect aggressively.
Here’s a simplified version of the request flow:
python
# Pseudo-code for prefill gateway
async def handle_request(prompt, model_name):
ticket = await prefill_worker.enqueue(prompt)
# ticket contains: {"cache_key": "abc123", "cache_location": "node:path"}
return await decode_worker.generate(ticket, max_tokens=1024)
And the decode worker:
python
# Pseudo-code for decode worker
async def generate(ticket, max_tokens):
cache = await load_cache(ticket.cache_key, ticket.cache_location)
outputs = []
for step in range(max_tokens):
token = model.generate_next(cache)
outputs.append(token)
if token == EOS_TOKEN:
break
return outputs
Yes, this is simplified. Real implementation needs retry logic, circuit breakers, load shedding, and cache invalidation. But the architecture is that straightforward.
The Contrarian Take: Everyone’s Overcomplicating This
Most articles about disaggregated prefilling talk about “KV cache offloading” and “dynamic scheduling” and “heterogeneous resource allocation.” They make it sound like you need a PhD in distributed systems.
You don’t.
The core insight is boring: prefill and decode have different resource profiles. So give them different resource pools. That’s it.
The complexity comes from trying to optimize the communication between pools. And that’s where most implementations go wrong. They try to transfer KV caches with zero-copy mechanisms and kernel-bypass networking. They spend months on RDMA tuning. They end up with systems that are fragile and hard to debug.
Our approach is dumber and works better: serialize the KV cache once, store it on a fast shared filesystem, and let each decode worker read it on demand. Is it as fast as zero-copy? No. But it’s 90% as fast, 10x simpler to operate, and doesn’t require a dedicated cluster interconnect.
Measuring Success: What to Track
You can’t optimize what you don’t measure. Here are the metrics we track in production:
Prefill throughput (tokens/sec per GPU). Shows how efficient your prefill pool is. If it’s below 50% of theoretical peak, check your batching logic.
Decode latency (P50, P95, P99). Measure from when the decode worker receives the cache to when the last token is emitted. Anything above 2 seconds for a 1K-token output is a problem.
Cache hit rate. If the decode worker can’t find the KV cache (because it was evicted or expired), it has to re-prefill. That doubles latency. Target >99% hit rate.
Overhead ratio. The time spent in serialization/deserialization divided by total request time. Keep it under 15%. If it’s higher, you need a faster cache store or a more compact serialization format.
Common Pitfalls (From Experience)
Pitfall 1: Over-partitioning. I see teams creating separate pools for every prompt-length bucket. Don’t. Two pools — one for short prompts (under 2K tokens) and one for long — is sufficient. More than that adds complexity without benefit.
Pitfall 2: Ignoring cold starts. Prefill workers need to warm up the model weights. If you autoscale aggressively, you’ll pay a 30-second startup penalty for every new node. Keep a minimum of 2 prefill workers always alive.
Pitfall 3: Not load-testing the transport layer. We discovered in production that gRPC has a connection limit on some NICs. At 500 requests/second, connection pool exhaustion caused cascading failures. Switch to HTTP/2 with keepalive or use a message queue in between.
Pitfall 4: Treating KV cache as immutable. It isn’t. If two decode workers try to modify the same cache entry (due to a routing bug), you get silent data corruption. Use read-only semantics for decode workers and write-once for prefill workers.
FAQ
What is disaggregated prefilling in simple terms?
It’s splitting LLM inference into two phases — initial prompt processing and token generation — so they can run on separate hardware optimized for each phase.
Does disaggregated prefilling reduce total cost?
Usually yes, by 20-40%, because you can use cheaper hardware for the decode phase. Decode workers don’t need high FLOPS — they need memory bandwidth. A100s are fine for decode. H100s are better for prefill.
Can I implement this with open-source tools?
Yes. vLLM supports a form of disaggregation natively since version 0.4.0. TensorRT-LLM has experimental support. For the cache layer, Redis or Memcached on a RAM-backed instance works well up to medium scale.
What about KV cache size limits?
KV cache for a 70B model at 4K context is roughly 4GB per request. At 32K context, it’s 32GB. That means each decode worker can hold 2-3 concurrent requests in memory. Beyond that, you need to swap to NVMe or use compression. We use 4-bit KV cache quantization (thanks to work by the llama.cpp team) to reduce memory by 4x.
Is disaggregated prefilling compatible with speculative decoding?
Depends. If the speculation happens during decoding, no conflict. If the speculator needs access to the prompt embeddings, you need to pass those from the prefill worker. Possible, but adds complexity.
How do I handle load balancing between pools?
Simple round-robin for prefill workers (they’re stateless). For decode workers, use least-connections routing because decode time varies by output length. We use a custom Envoy filter for this.
What’s the minimum viable setup?
Two nodes: one for prefill, one for decode. Both with at least 80GB GPU memory. A shared filesystem (NFS is fine for testing). Redis for cache coordination. You can get a working prototype in a week.
Will disaggregated prefilling work for multimodal models?
Yes, but the KV cache is larger because you’re caching vision embeddings too. Expect 2-3x memory requirements. The architecture is the same.
Where Things Are Going
Two trends are making disaggregated prefilling more important, not less.
First, context windows are exploding. Google’s Gemini has 1M tokens. Anthropic’s Claude can handle 200K. At those lengths, a single prefill phase can take minutes on monolithic hardware. Splitting it off gives you the flexibility to allocate prefill GPUs differently than decode GPUs.
Second, hardware specialization is accelerating. We’re seeing dedicated prefilling ASICs from companies like Groq and Cerebras. These chips are terrible at autoregressive decoding but excellent at massive matrix multiplies. Disaggregated architecture lets you plug them in as prefill accelerators without changing your decode stack.
At SIVARO, we’ve already started experimenting with a setup where prefill runs on custom hardware and decode runs on standard GPUs. Early results show 3x throughput on prefill at the same power envelope.
The Bottom Line
What is disaggregated prefilling? It’s a practical answer to a specific problem: LLM inference is two different workloads pretending to be one. Separate them, and you unlock more throughput, lower latency, and better hardware utilization. Keep them together, and you’ll hit a wall around 100 RPS on 8 GPUs.
If you’re running LLMs in production and your latency starts to climb, ask yourself: are my prefill and decode fighting for the same GPUs? If yes, it’s time to split them.
Start simple. Two pools. A shared cache. Measure the difference. I’ve seen teams double their effective capacity in two weeks with this approach.
One more thing: the architecture I’ve described works today. You don’t need to wait for the next paper or the next framework release. If you are building production AI systems, go try it.
And if you hit problems, reach out. I’ve broken enough things to know where the landmines are.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.