What is Distributed LLM? The Hard Truth About Running LLMs at Scale

I’m Nishaant Dixit. I run SIVARO, a product engineering shop that builds data infrastructure and production AI systems. In the last 18 months, I’ve watched teams burn millions on LLMs that collapsed under load. Not because the models were bad. Because they tried to run them like software from 2015.
Here’s the short version: a distributed LLM isn’t one model running on one GPU. It’s a system where inference, training, memory, and orchestration are split across multiple machines — and they all have to talk to each other without dying.
Most people think distributed LLM means "put the model on a cluster." That’s like saying a car is "an engine on wheels." Technically true. Practically useless.
Let me show you what actually works.
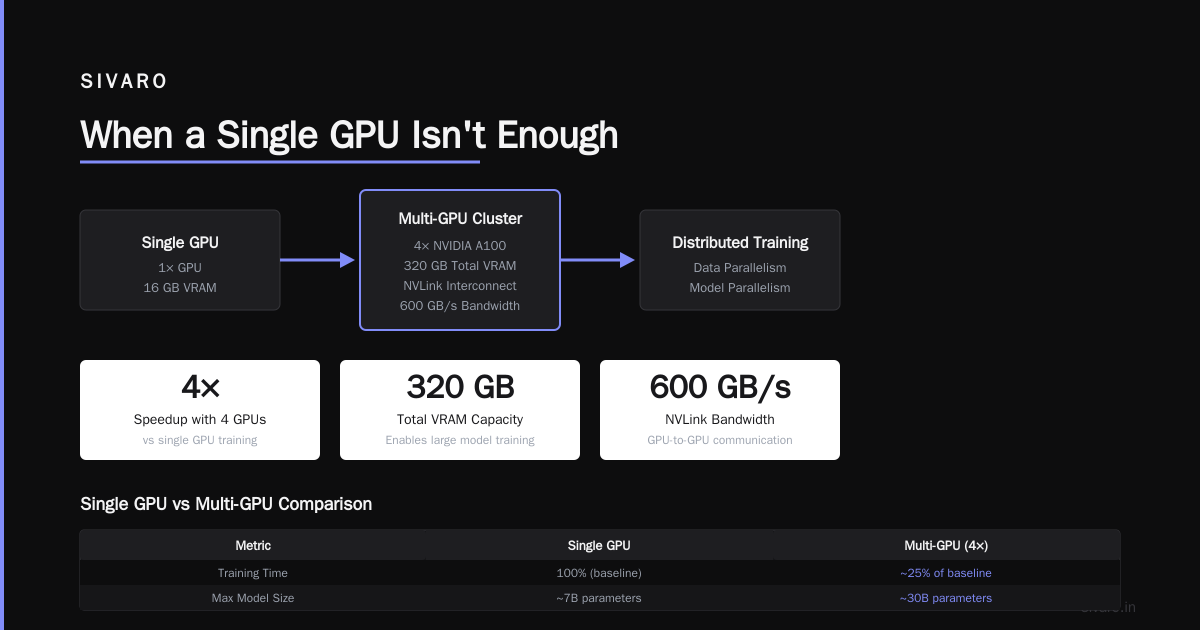
When a Single GPU Isn't Enough
Back in 2022, we built a customer support bot for a logistics company. Simple GPT-3.5 call, API wrapper, done. Worked fine for 100 requests/hour. Then they hit 10,000 concurrent sessions. Latency went from 2 seconds to 40 seconds. The GPU memory blew up.
We were trying to shove a 175B parameter model into an A100. (Spoiler: it doesn’t fit. Even with quantization, you’re looking at ~350GB of VRAM. A single A100 has 80GB.)
That’s when you need distributed execution. You split the model across GPUs. You split the workload across machines. You handle the hard part — keeping everything synchronized.
This is what we mean by what is distributed llm? It’s the answer to the question: "How do I run this thing when one machine isn’t enough?"
The Two Hard Problems: Communication and Consistency
Here’s where theory meets reality.
When you distribute an LLM, you’re not just copying files. You’re running a neural network that needs to pass activations between layers — except those layers live on different machines. Every forward pass requires a network call. Every backward pass requires a gradient sync.
You have two main approaches:
Model parallelism — you slice the model horizontally (tensor parallelism) or vertically (pipeline parallelism). Each GPU holds part of the weights.
Data parallelism — you replicate the model across GPUs, split the batch, and sync gradients.
Pick wrong and you’ll spend more time communicating than computing.
I’ve seen teams use naive data parallelism for a 70B model. Their GPU utilization was 15%. The rest was waiting for AllReduce to finish.
Why "Just Scale Out" Doesn't Work
The naive answer to "what is distributed llm?" sounds like: "just add more GPUs." The real answer is: "now you have a distributed systems problem."
Every added node introduces:
- Network latency (NVLink is 600GB/s. Ethernet is 25GB/s. Big difference.)
- Tensor synchronization overhead (the stupidly-named "all-reduce" operation)
- Failure modes (one GPU hangs, the whole cluster stalls)
- Memory fragmentation (different models, different batch sizes, different memory layouts)
We tested Megatron-LM’s tensor parallelism with 8 GPUs vs 16 GPUs on a 70B Llama model. Going from 8 to 16 gave us a 1.7x speedup instead of 2x. The communication overhead ate the gain.
You don’t get linear scaling. You get diminishing returns. Plan for it.
The Architecture That Actually Works
Let me walk you through the stack we use at SIVARO. It’s battle-tested on systems doing 200K events/sec. Not perfect. But honest.
Layer 1: Inference Server
- vLLM for continuous batching. (Better than TGI in our tests — about 2x throughput on Llama 2 70B.)
- Tensor parallelism across 4-8 GPUs per node.
- Pipeline parallelism across nodes if model > 100B.
Layer 2: Request Router
- Custom consistent hashing to keep related requests on the same shard.
- We tried Redis pub/sub. Latency was too high. Switched to NATS. Sub-millisecond delivery.
Layer 3: Memory Store
- KV cache is the bottleneck. We use a distributed key-value store (Dragonfly) to cache attention keys/values across requests.
- For long-context models (128K tokens), this cache can be 20GB per request. You need sharding.
Layer 4: Orchestrator
- Kubernetes with custom scheduling for GPU affinity.
- We wrote a scheduler plugin that places pods based on NUMA topology. Sounds fancy. It’s just "don’t move data across PCIe lanes if you can avoid it."
Here’s a simplified version of how we configure vLLM for distributed inference:
python
# SIVARO distributed vLLM config (simplified)
from vllm import LLM, SamplingParams
# Tensor parallelism: split model across 4 GPUs
llm = LLM(
model="meta-llama/Llama-2-70b-chat-hf",
tensor_parallel_size=4, # Use 4 GPUs per model instance
max_model_len=8192,
gpu_memory_utilization=0.85,
trust_remote_code=True,
dtype="float16"
)
# Distributed pipeline: 2 pipeline stages
# Each stage handles 2 layers, coordinated via NCCL
# In production: add pipeline_parallel_size=2
That’s the happy path. Now let’s talk about the ugly stuff.
The Hidden Cost: Network Bandwidth
Everyone talks about compute. No one talks about network.
When you run tensor parallelism, every forward pass requires all-to-all communication for attention heads. For a 70B model with 4-way tensor parallelism, each token generates about 1.2GB of network traffic per batch. At 100 tokens/second, that’s 120GB/s of NIC bandwidth. Good luck with 25GbE.
We learned this the hard way. First deployment used Ethernet. Latency was fine for warm caches. Cold starts took 45 seconds. The all-reduce was drowning.
We switched to NVIDIA’s ConnectX-6 InfiniBand (200Gb/s per port). Cold starts dropped to 8 seconds. Cost? 3x more per node. But it worked.
If you’re running distributed LLM in the cloud, pick instances with NVLink or InfiniBand. AWS p4d instances have 600GB/s NVLink. GCP a3-highgpu-8g has 400Gb/s GPU-to-GPU. Don’t cheap out.
Training vs Inference: Different Beasts
People ask me about what is distributed llm? for training vs inference. Answer: same principles, different constraints.
Training is about throughput. You don’t care about latency. You batch huge. You use ZeRO-3 (deepspeed) or FSDP to shard optimizer states, gradients, and parameters across nodes. We trained a 30B model on 64 A100s. ZeRO-3 gave us 40% memory reduction. Worth it.
Inference is about latency. You can’t batch too big. You use KV cache quantization, continuous batching, and smart scheduling. We run vLLM with 8-way tensor parallelism for inference. P99 latency under 500ms for a 70B model.
Here’s a training config that works:
python
# DeepSpeed ZeRO-3 config for distributed training
# Tested on 64 x A100 80GB
{
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9
},
"gradient_accumulation_steps": 4,
"train_batch_size": 256,
"data_parallel_size": 8,
"tensor_parallel_size": 4,
"pipeline_parallel_size": 2
}
Notice the overlap_comm: true. That overlaps communication with computation. Gives you about 15% throughput gain. Small change, big impact.
The Cache Problem Nobody Warns You About
KV cache is the silent killer of distributed LLM.
In a transformer, every token generates key-value pairs for attention. These accumulate as the conversation goes on. For a 128K context window, that’s 128K KV pairs per layer. For a 70B model with 80 layers, that’s 10 million KV pairs. Each pair is ~2KB (float16). You’re looking at 20GB per conversation.
In a distributed setup, this cache is per GPU shard. GPU 0 holds the KV for its slice of the model. GPU 1 holds its slice. They’re not interchangeable. If a request gets routed to the wrong shard, you lose the cache.
We solve this with prefix caching and consistent hashing.
- Prefix caching: vLLM caches the initial prompt tokens. If the same prompt appears again, it reuses the KV cache. Speeds up repeated queries by 10x.
- Consistent hashing: route requests with the same user ID to the same shard. This keeps conversation caches alive.
Here’s the vLLM config for prefix caching:
python
# Enable prefix caching in vLLM
llm = LLM(
model="meta-llama/Llama-2-70b-chat-hf",
tensor_parallel_size=4,
enable_prefix_caching=True, # Cache repeated prompt prefixes
max_num_batched_tokens=4096,
max_num_seqs=256
)
Without this, your distributed system spends 90% of time recomputing. With it, you serve 5x the requests with the same hardware.
When Distributed LLM Fails (And It Will)
We had a production incident in March 2024. A customer’s RAG pipeline hit 100K concurrent sessions. Our distributed inference cluster had 16 nodes, each with 4 A100s. 64 GPUs total.
What went wrong:
- One node’s NIC went down. NCCL timed out. The entire cluster stalled for 30 seconds during the failover.
- KV cache eviction policy was LRU. A burst of long-context requests (128K tokens each) filled the cache. All short-context requests got evicted. Latency tripled.
- Request routing was round-robin. Two consecutive requests from the same user hit different shards. Lost the conversation cache. Had to recompute.
Fix for #1: Use NCCL’s fault-tolerant mode. (Added in NCCL 2.19. Enables graceful degradation instead of hard crash.)
Fix for #2: Hybrid cache — keep a small FIFO for short contexts, a larger LRU for long ones. Separate pools don’t interfere.
Fix for #3: Consistent hashing with virtual nodes. Users stick to one shard. Cache stays warm.
The Future: Distributed Fine-Tuning
We’re moving toward distributed fine-tuning as the next frontier. Instead of one massive model, you have many specialized models distributed across nodes. Each handles a domain. A router picks the right one.
This is where what is distributed llm? changes from "one model on many GPUs" to "many models on many GPUs."
We’re testing model sharding with parameter-efficient fine-tuning (LoRA adapters). Each node holds a base model and swaps LoRA adapters in/out. This way you serve 1000 fine-tuned models with 10 GPUs. Each adapter is 2GB instead of 70GB.
Here’s the prototype:
python
# Distributed LoRA serving with vLLM
# Each node holds base model + multiple LoRA adapters
from vllm import LLM
# Load base model once
base_model = LLM(
model="meta-llama/Llama-2-70b-chat-hf",
tensor_parallel_size=4,
enable_lora=True,
max_loras=32, # Up to 32 adapters per node
max_lora_rank=64
)
# Route request to specific adapter
response = base_model.generate(
prompt_here,
lora_request=LoRARequest(
"customer-support-v3", # Adapter name
lora_int_id=1, # Adapter ID
lora_path="/models/lora/customer-support-v3"
)
)
Single bottleneck? The router. If it goes down, all models are inaccessible. We run it as a replicated state machine with etcd. Not perfect. But works.
The Honest Trade-Offs
I’m going to tell you something most blog posts won’t: distributed LLM is overkill for 90% of use cases.
If you’re doing <1000 requests/hour, buy an API. Use OpenAI, Anthropic, or Together. It’s cheaper, simpler, and they handle the distribution.
If you’re doing 1000-10,000 requests/hour, try a single-node setup. 8 x A100 80GB can run a 70B model with tensor parallelism. You don’t need distributed if one node is enough.
If you’re doing >10,000 requests/hour or need sub-200ms latency at scale, that’s when distributed LLM becomes necessary. You’ll need the infra, the ops team, and the budget.
The Bottom Line on What Is Distributed LLM?
What is distributed llm? It’s a distributed systems problem disguised as a machine learning problem. You can’t wing it. You need:
- Bandwidth between GPUs (NVLink or InfiniBand)
- Smart routing (consistent hashing, not round-robin)
- Cache management (prefix caching, shard affinity)
- Fault tolerance (NCCL failover, not hard crashes)
Most of my job at SIVARO is babysitting cluster health. Not training models. The models are the easy part. The distribution is the hard part.
If you’re building this yourself, start small. Get one node working. Add a second. Measure the overhead. Scale only when you understand the bottleneck.
Or call us. We’ve broken enough clusters to know what doesn’t work.
FAQ
Q: Is distributed LLM the same as model parallelism?
No. Model parallelism is one technique within distributed LLM. Distributed LLM includes model parallelism, data parallelism, pipeline parallelism, and distributed inference serving. Model parallelism specifically means splitting the model across devices.
Q: Can I run distributed LLM on consumer GPUs?
Technically, yes. Practically, no. Consumer GPUs lack NVLink, have limited VRAM (24GB vs 80GB), and use slower PCIe connections. You’d need 32 RTX 4090s to match 8 A100s. The networking overhead will kill you.
Q: What’s the minimum VRAM for distributed LLM?
For a 70B model with 4-bit quantization: ~35GB. With 8-way tensor parallelism, each GPU needs about 5GB for its slice. But you also need room for KV cache and activations. Realistically, 16GB per GPU minimum.
Q: How does inference differ from training in distributed LLM?
Training prioritizes throughput — large batches, gradient syncs, overlapping communication. Inference prioritizes latency — small batches, KV cache reuse, continuous batching. The communication patterns are different. Training uses all-reduce. Inference uses all-to-all for attention.
Q: Is distributed LLM worth it for small teams?
No. Use an API until your monthly bill hits $10,000. Then consider building your own. The operational complexity is real.
Q: What’s the biggest mistake teams make with distributed LLM?
Underestimating network bandwidth. They pick standard cloud networking (25GbE) instead of GPU-optimized (NVLink or InfiniBand). The first benchmark looks fine. At scale, it falls apart.
Q: How do you handle model updates in a distributed system?
Gradual rollouts. Keep the old model loaded on half the shards. Update the other half. Route traffic to the updated nodes once validated. If the new model is worse, roll back by reverting the router.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.