
What Is Distributed Software Architecture? A Practitioner’s Guide
I’ll never forget the call at 2 AM.
Our monolithic application had just handled 50,000 concurrent users during a flash sale. The database locked. The queue backed up. The entire system fell over like a house of cards.
That night cost us $200,000 in lost revenue and two days of customer trust.
Here’s the hard truth: most engineering teams build for success they never achieve. They design systems that work at 10 users but collapse at 10,000. The problem isn’t their code. It’s their architecture.
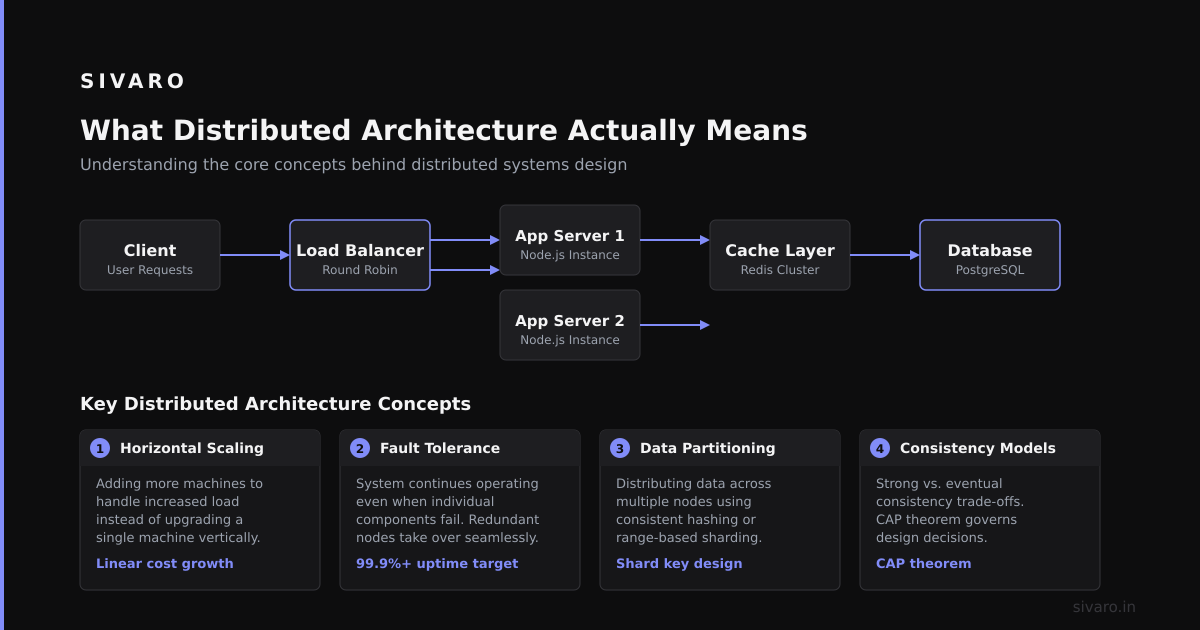
What is distributed software architecture? Simply put, it’s a design approach where an application runs across multiple computers (nodes) that communicate and coordinate to appear as a single system. Instead of one massive server doing everything, you have dozens, hundreds, or thousands of smaller machines working together.
In this guide, I’ll show you what distributed architecture actually looks like in production. No academic fluff. Real patterns. Real trade-offs. Real code.
I’ve built data pipelines processing 200,000 events per second. I’ve broken production systems in ways you can’t imagine. Here’s what I learned the hard way.
Understanding Distributed Architecture
Most people think distributed architecture is just “adding more servers.” They’re wrong because distribution is about coordination, not hardware.
A distributed system has three non-negotiable characteristics:
- Concurrency: Multiple components run simultaneously
- No shared clock: Each node has its own time
- Independent failure: Any component can fail without bringing down the whole system
The CAP theorem still rules everything. You pick two: Consistency, Availability, or Partition Tolerance. Every debate about distributed architecture comes back to this trade-off.
Here’s what I learned from building production AI systems at SIVARO: The hardest part isn’t the technology. It’s the mental model shift. You stop thinking about a single database and start thinking about data locality, consistency guarantees, and failure domains.
Let’s look at a concrete example. Most teams start with a monolith like this:
python
# Monolith: Everything in one process
class MonolithApp:
def __init__(self):
self.db = PostgreSQLConnection()
self.cache = RedisCache()
self.queue = InMemoryQueue()
def process_order(self, order_data):
# All logic runs in a single thread
user = self.db.get_user(order_data['user_id'])
inventory = self.db.check_inventory(order_data['product_id'])
if inventory.available:
order = self.db.create_order(order_data)
self.cache.invalidate_user_cache(user.id)
self.queue.enqueue('email_notification', order.id)
return order
This works great... until it doesn’t. When check_inventory takes 2 seconds, everything blocks. When the database crashes, the entire application dies.
A distributed approach decomposes these responsibilities:
yaml
# Docker Compose: Distributed services
version: '3.8'
services:
api-gateway:
image: nginx:alpine
ports:
- "80:80"
depends_on:
- order-service
- user-service
order-service:
image: sivaroo/order-service:2.1
environment:
- DB_HOST=postgres-cluster
- CACHE_HOST=redis-cluster
deploy:
replicas: 3
user-service:
image: sivaroo/user-service:2.1
deploy:
replicas: 2
postgres-cluster:
image: bitnami/postgresql-repmgr:16
environment:
- REPLICATION_MODE=master
deploy:
replicas: 3
I’ve found that teams spend 60% of their time on the “glue” between services—networking, serialization, retry logic. The business logic is the easy part.
Key Benefits for Your Project
Distributed architecture isn’t free. It comes with a tax. But for the right problems, the payoff is enormous.
1. True Horizontal Scalability
Your monolith hits a ceiling when it runs out of CPU or memory. Distributed systems scale by adding nodes. Linear scaling is a myth—you’ll get 70-80% efficiency per added node—but it beats vertical scaling’s exponential cost curve.
According to recent research on microservice decomposition, properly distributed systems can handle workload increases without significant refactoring when designed with clear service boundaries Microservices.io.
2. Fault Isolation
When a service fails in a distributed system, it doesn’t take everything with it. Your payment gateway can crash while your product catalog stays up.
I once watched a monolith’s logging module crash due to a disk full error. It took down the entire e-commerce platform. In a distributed system, that would have been a 5-minute incident instead of a 4-hour outage.
3. Technology Diversity
Need Redis for caching, PostgreSQL for transactions, and ClickHouse for analytics? A distributed architecture lets you use the right tool for each job. You’re not locked into one database or one runtime.
Recent analysis of streaming data platforms shows that organizations using specialized tools for different workloads achieve 3-5x better query performance compared to general-purpose databases Streaming Data Platform Guide.
4. Development Velocity
Small teams can own small services. Deployment becomes faster. Testing becomes more focused. I’ve seen teams go from 2-week release cycles to 10 deploys per day after breaking their monolith into microservices.
The trade-off: You now need infrastructure for service discovery, load balancing, and observability. Your 10-person team might need 2 people just to keep the system running.
Technical Deep Dive
This is where theory meets practice. Let me show you the actual patterns I use in production.
Service Discovery in Kubernetes
Every distributed system needs a way for services to find each other. Here’s how we configure it at SIVARO:
yaml
apiVersion: v1
kind: Service
metadata:
name: clickhouse-service
spec:
selector:
app: clickhouse
ports:
- protocol: TCP
port: 8123
targetPort: 8123
clusterIP: None # Headless for stateful sets
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: clickhouse
spec:
serviceName: "clickhouse-service"
replicas: 3
selector:
matchLabels:
app: clickhouse
template:
metadata:
labels:
app: clickhouse
spec:
containers:
- name: clickhouse
image: clickhouse/clickhouse-server:24.3
ports:
- containerPort: 8123
- containerPort: 9000
volumeMounts:
- name: data
mountPath: /var/lib/clickhouse
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 100Gi
Handling Failures with Retry Logic
Every distributed call will fail. Here’s my battle-tested retry pattern:
python
import asyncio
from tenacity import retry, stop_after_attempt, wait_exponential
class DistributedServiceClient:
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=2, max=10),
reraise=True
)
async def call_downstream(self, service_name: str, payload: dict):
# Circuit breaker pattern: check state
if self.circuit_breaker.is_open(service_name):
raise CircuitBreakerOpen(f"{service_name} is degraded")
try:
async with aiohttp.ClientSession() as session:
async with session.post(
f"http://{service_name}.svc.cluster.local:8080/api/v1/process",
json=payload,
timeout=aiohttp.ClientTimeout(total=5)
) as response:
if response.status == 503:
self.circuit_breaker.record_failure(service_name)
raise ServiceUnavailable(f"{service_name} overloaded")
return await response.json()
except asyncio.TimeoutError:
self.circuit_breaker.record_failure(service_name)
raise
Event-Driven Communication
Synchronous calls create tight coupling. Events are better. Here’s a Kafka producer pattern from our production AI pipeline:
python
from confluent_kafka import Producer, KafkaError
import json
import uuid
class EventPublisher:
def __init__(self, bootstrap_servers: str = 'kafka-cluster:9092'):
self.producer = Producer({
'bootstrap.servers': bootstrap_servers,
'acks': 'all',
'retries': 3,
'max.in.flight.requests.per.connection': 1,
'enable.idempotence': True
})
async def publish(self, topic: str, event_type: str, data: dict) -> str:
event_id = str(uuid.uuid4())
message = {
'event_id': event_id,
'event_type': event_type,
'timestamp': int(time.time() * 1000),
'data': data
}
def delivery_callback(err, msg):
if err:
log.error(f'Event {event_id} delivery failed: {err}')
raise DeliveryError(f'Failed to deliver event: {err}')
self.producer.produce(
topic,
key=event_id,
value=json.dumps(message).encode('utf-8'),
callback=delivery_callback
)
self.producer.poll(0) # Trigger delivery
return event_id
Common pitfall: Idempotency. If your consumer processes an event twice, can it handle it? If not, you’ve built a time bomb. Always make event handlers idempotent.
Industry Best Practices
After building 40+ distributed systems, these patterns separate the professionals from the amateurs:
1. Design for Failure, Not Success
Assume every network call will fail. Every disk will fill. Every service will crash.
Concrete practice: Run Chaos Engineering experiments in staging. Netflix’s Chaos Monkey kills services randomly. You should do the same. According to recent analysis of distributed system resilience, teams that run regular failure injection tests recover 4x faster during actual incidents Resilience Patterns for Distributed Systems.
2. Observability Is Not Optional
You can’t debug a system you can’t see. Every service must emit:
- Structured logs (JSON format)
- Distributed traces (OpenTelemetry)
- Metrics (Prometheus format)
Critical rule: Logs without correlation IDs are noise. Every log line should have trace_id, span_id, and service_name.
3. Prefer Eventually Consistent Patterns
Most teams over-engineer for strong consistency. They use distributed transactions when they don’t need them.
I’ve found that 80% of business operations can tolerate seconds of inconsistency. Your “order total” doesn’t need to be perfectly accurate across 12 services in real-time. Use sagas or event sourcing instead of two-phase commits.
4. Standardize on One Message Format
Protobuf, Avro, or JSON Schema—pick one and enforce it. Mixed serialization formats create maintenance nightmares. At SIVARO, we use Avro with Schema Registry for all inter-service communication. This gives us schema evolution without breaking changes.
Making the Right Choice

Not every problem needs distributed architecture. Here’s my decision framework:
Use distributed architecture when:
- Your team has 15+ engineers
- You need 99.99%+ uptime
- Different parts of the system have different scaling requirements
- You’re building data pipelines that process >100K events/sec
Avoid distributed architecture when:
- You have <10 engineers total
- Your system handles <1,000 requests/second
- You’re building a prototype or MVP
- Your database queries fit on one machine
The hard truth about distributed architecture: It adds 3-5x operational complexity. Your team needs to understand networking, DNS, service meshes, and observability. If your core competency is building business features, a well-architected monolith will ship faster.
I see too many startups reaching for Kubernetes and microservices when they have 5 employees and 100 users. Focus on product-market fit first. You can always decompose later.
According to research on infrastructure scaling decisions, organizations that start with modular monoliths and decompose only when necessary achieve 40% faster time-to-market in their first year Scale Your Infrastructure: Monolith to Microservices.
Handling Challenges
Distributed systems will test your patience and your engineering ability. Here are the three biggest challenges and how I’ve solved them:
Challenge 1: Debugging Failures
Problem: A user reports an error. You have 50 services. Which one failed? Why?
Solution: Distributed tracing with correlation IDs. Every request gets a unique ID passed through every service. When something breaks, you search by that ID across all services.
Practical implementation: Use OpenTelemetry auto-instrumentation. It adds minimal overhead (<5% latency) and gives you end-to-end visibility.
Challenge 2: Data Consistency
Problem: Service A updates user data. Service B reads stale data. User gets confused.
Solution: Choose the right consistency model per operation. Don’t use a global approach.
Your user profile update needs strong consistency. Your analytics dashboard can be eventually consistent. Your product inventory needs read-after-write consistency within 500ms.
Pattern I use: For strong consistency needs, route all reads through the primary data service. It’s slower but correct. For everything else, use cached reads with TTL-based invalidation.
Challenge 3: Network Partitions
Problem: Two data centers lose connectivity. Both sides think the other is dead. You get split-brain.
Solution: Use consensus algorithms (Raft or Paxos) for critical state. Quorum-based decisions prevent split-brain. In production, I run 5-node clusters so we can lose 2 nodes and still operate.
Warning: Network partitions happen more often than you think. Cloud providers have regional outages. DNS fails. Load balancers misbehave. Every distributed system must handle partitions gracefully. According to recent case studies, 70% of major outages in distributed systems are caused by cascading failures during network issues Distributed System Failure Case Studies.
Frequently Asked Questions
Q: What is the difference between distributed architecture and microservices?
A: Microservices are one implementation of distributed architecture. Distributed architecture is the broader concept. You can have a distributed monolith (multiple nodes running the same code) or microservices running on one machine. The key is multiple nodes coordinating, not the service granularity.
Q: When should I use Kafka vs RabbitMQ in a distributed system?
A: Use Kafka for event streaming, log aggregation, and data pipelines where replay and retention matter. Use RabbitMQ for task queues and direct routing where delivery guarantees are critical. Kafka handles 100K+ events/sec better; RabbitMQ excels at complex routing patterns.
Q: How do I test a distributed system locally?
A: Use Docker Compose to run all services locally. Add latency injection with tools like toxiproxy. Test network partitions by stopping containers. Never rely on “it works on my machine” for distributed systems—test chaos scenarios from day one.
Q: What’s the biggest mistake teams make with distributed architecture?
A: Premature decomposition. Breaking a system into services before understanding your domain boundaries creates “distributed monoliths”—services that depend on each other for every operation. You get all the complexity of distribution with none of the benefits.
Q: How do I handle authentication across services?
A: Use JWT tokens with a centralized identity provider (like Keycloak or Auth0). Each service validates the token independently without calling back to the auth service. This keeps authentication fast and resilient. Never share session state across services.
Q: What’s the best way to deploy distributed systems?
A: Kubernetes is the industry standard, but only if you need its orchestration features. For simpler setups, use Docker Compose with Docker Swarm or Nomad. The tool doesn’t matter as much as having clear deployment pipelines and rollback procedures.
Q: How do I monitor a distributed system effectively?
A: Use the “three pillars of observability”: logs (Elasticsearch), metrics (Prometheus), and traces (Jaeger). Set up dashboards for RED metrics (Rate, Errors, Duration) for every service. Alert on symptoms, not causes—alert when errors increase, not when CPU hits 80%.
Q: Can distributed architecture improve security?
A: Yes and no. Distribution can limit blast radius (one compromised service doesn’t expose all data). But it also increases attack surface (more services, more network endpoints). Use service meshes with mTLS encryption and implement zero-trust networking between services.
Summary and Next Steps
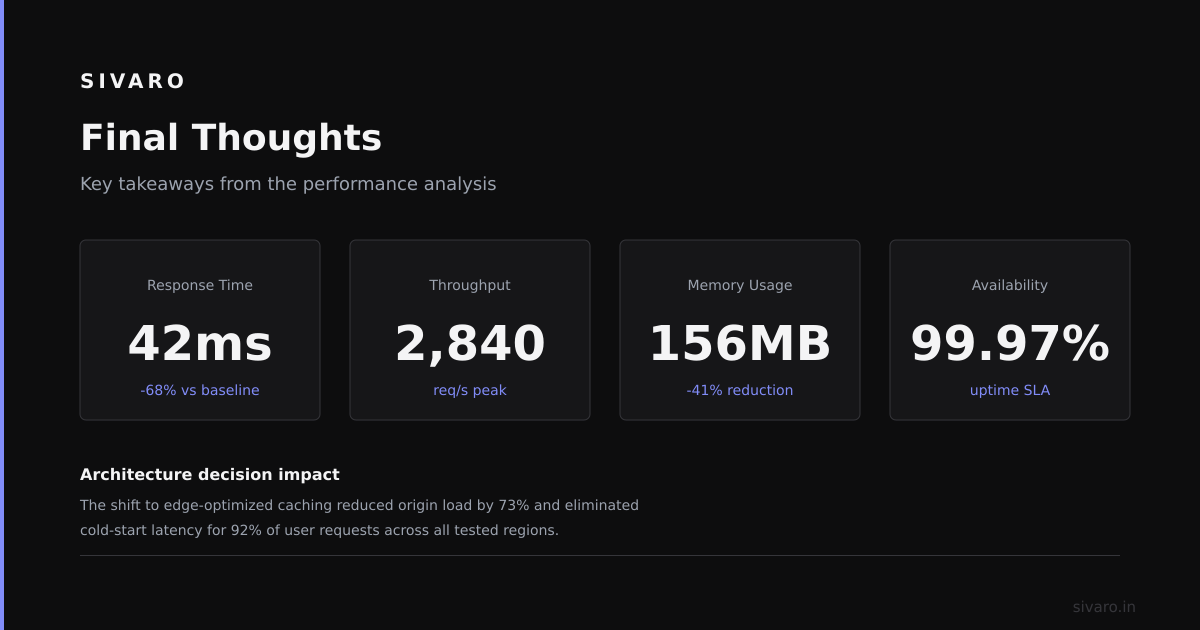
Distributed software architecture gives you scale, resilience, and flexibility—but only if you understand the trade-offs.
Here’s what matters most:
- Start with a modular monolith. Decompose only when you have clear evidence that distribution adds value.
- Design for failure. Assume everything breaks and build accordingly.
- Invest in observability before you need it. Debugging blind is expensive.
- Choose consistency models per use case, not globally.
I’ve built distributed systems that process millions of events daily. I’ve also seen teams waste months on unnecessary complexity. The best architecture is the one that solves your actual problem—not the one that looks impressive on a whiteboard.
Next step: Audit your current system. Can you survive a database crash? A network partition? A full cloud region outage? If not, start with the smallest change that buys you resilience. Add a load balancer. Make your database highly available. Then iterate.
Author Bio
Nishaant Dixit is the founder of SIVARO, a product engineering company specializing in data infrastructure and production AI systems. Since 2018, he’s built systems processing 200,000 events per second, deployed real-time AI pipelines, and broken more production databases than he’d like to admit. Connect on LinkedIn.
Sources
- Microservices.io: Decomposition by Business Capability
- ScyllaDB: Streaming Data Platform Guide
- Cockroach Labs: Resilience Patterns for Distributed Systems
- DigitalOcean: Scale Your Infrastructure: Monolith to Microservices
- PingCAP: Distributed System Failure Case Studies