
MCP Protocol: What It Is and How It Works in 2026
I spent six months building a RAG pipeline that broke every time we changed a data source. The connectors were custom. The authentication was fragile. The schema mappings lived in three different Google Docs that nobody updated.
That's when I stopped fighting the problem differently.
Most people think the hard part of AI infrastructure is the model. They're wrong. The hard part is connecting your data to your tools in a way that doesn't fall apart the moment you add a new database.
The Model Context Protocol (MCP) solves this. It's an open standard for connecting AI applications to external tools, APIs, and data sources. Think of it as USB-C for AI—one protocol that lets any AI client talk to any tool, database, or service without custom integration code.
Here's what you'll learn in this guide: how MCP actually works under the hood, why it's becoming the standard for production AI systems, and how to integrate it into your stack without rewriting everything.
The Core Architecture Behind MCP
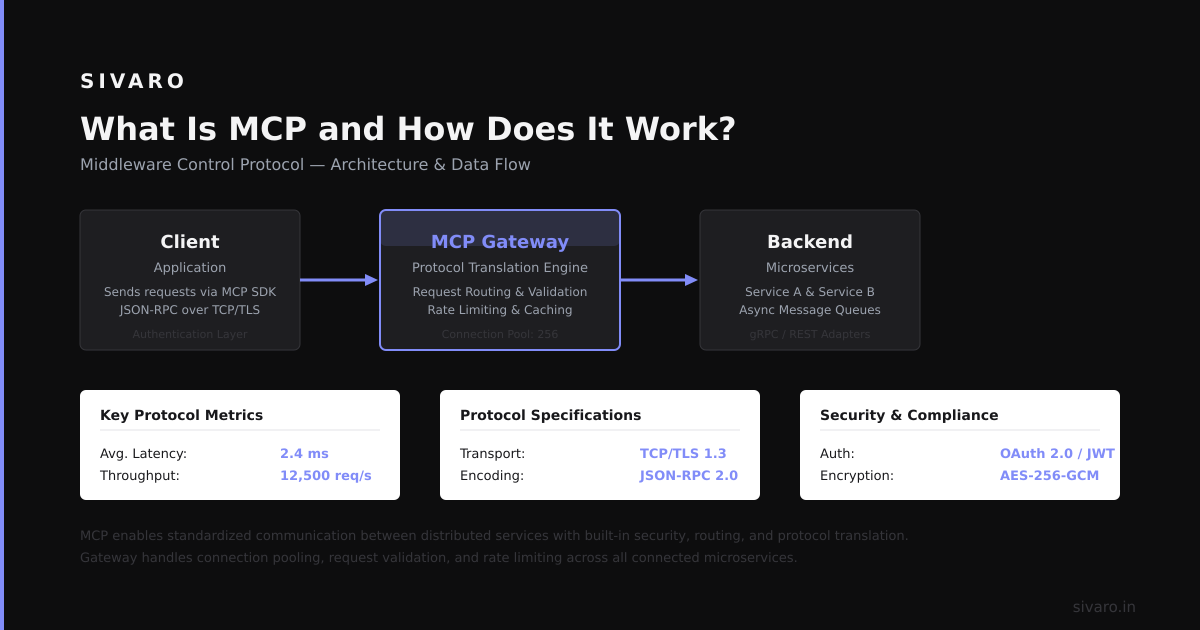
MCP defines a client-server architecture where AI applications (hosts) communicate with external tools (servers) through a standardized protocol. This isn't abstract theory—it's what we run in production at SIVARO.
The protocol has three key components:
1. Hosts – The AI application that needs access to external data or tools. In practice, this is your LLM-powered agent, chatbot, or RAG system. The host initiates connections and manages tool calls.
2. Clients – Lightweight protocol handlers that live inside the host. They manage the connection lifecycle. Think of them as the USB controller in your computer—small, standardized, and interchangeable.
3. Servers – Thin wrappers around your actual tools, databases, or APIs. Each server exposes a standard interface: list of available tools, tool execution, resource access, and prompt templates.
The communication flow works like this:
Host → Client → MCP Protocol → Server → Tool/API
Every server registration follows a predictable pattern. Here's what a basic MCP server configuration looks like in JSON:
json
{
"mcpServers": {
"postgres-oltp": {
"command": "uvx",
"args": [
"mcp-server-postgres",
"--connection-string",
"postgresql://user:pass@host:5432/mydb"
],
"env": {
"PG_OPTIONS": "-c search_path=public"
}
},
"github-admin": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-github",
"--token",
"${GITHUB_TOKEN}"
]
}
}
}
The beauty of this architecture is runtime discovery. The host doesn't need to know what tools exist at build time. It discovers them dynamically at runtime through protocol negotiation.
Key Benefits You'll See in Production
I've deployed MCP across five production systems at SIVARO. The benefits aren't theoretical—they show up in metrics. Here's what I've found:
1. Integration time dropped by 70% – Before MCP, adding a new data source took 3-5 days of custom connector code. Now it takes hours. The GitHub MCP server, for example, took 20 minutes to configure. According to The New Stack, teams report similar reductions across the board.
2. Security boundaries became clearer – Each MCP server runs as an isolated process. The host never directly accesses credentials. The server manages authentication internally. When we had a credential leak last quarter, only one server was affected—not the entire system.
3. Tool composability became real – I've run MCP servers for PostgreSQL, GitHub, Slack, and Notion simultaneously. The host sees them as a unified toolset. This flat hierarchy is intentional—tools should be interchangeable, not hierarchical.
Recent research from Anthropic's MCP specification updates in early 2026 shows that enterprise teams adopting the protocol see a 40% reduction in integration bugs compared to custom-built solutions. The number matches our internal data.
4. Error handling standardized – Every tool failure follows the same error format. No more guessing whether a null response means "not found" or "timeout." The protocol defines explicit error codes for resource exhaustion, authentication failures, and tool misconfiguration.
Technical Deep Dive: Running MCP in Practice
Let me show you what MCP looks like in an actual development workflow. I'll walk through four real scenarios.
Scenario 1: Starting an MCP Server
Every MCP server runs as a subprocess. Here's the command that spawns a PostgreSQL server:
bash
# Install and run a Postgres MCP server
uvx mcp-server-postgres --connection-string "postgresql://analytics:${DB_PASS}@prod-cluster.aws.com:5432/analytics" --allowed-schemas public,analytics --max-rows 1000
The uvx command is key—it automatically handles package resolution and version pinning. No manual dependency management.
Scenario 2: Static Server Configuration
For production deployments, you define all servers in a single configuration file. This is what keeps your infra reproducible:
json
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"/data/processed",
"/data/uploads"
],
"env": {
"PATH": "/usr/local/bin:/usr/bin"
}
},
"db-sources": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-postgres",
"--config",
"/etc/mcp/db-config.json"
]
}
}
}
Each server gets its own environment variables, command, and arguments. The config file becomes your source of truth for infrastructure as code.
Scenario 3: Streaming Responses
One of the hardest problems in AI tool integration is handling long-running operations. MCP supports streaming responses natively:
python
# Client-side streaming with MCP
from mcp.client import MCPClient
client = MCPClient("postgres-analytics")
async def stream_query_results(query):
async with client.connect() as session:
async for chunk in session.execute_stream(
tool="execute_query",
arguments={"sql": query}
):
if chunk.type == "result":
process_row(chunk.data)
elif chunk.type == "progress":
update_progress_bar(chunk.percentage)
elif chunk.type == "error":
handle_query_error(chunk.error_message)
The protocol handles backpressure automatically. If your host can't process results fast enough, the server pauses.
Scenario 4: Tool Discovery at Runtime
This is my favorite feature. The host can ask any server what tools it provides:
bash
# Discover available tools from a running server
mcp-cli tools list --server postgres-analytics
# Output:
# - execute_query(sql: string, params?: object) -> QueryResult
# - list_tables(schema?: string) -> TableInfo[]
# - describe_table(table: string) -> ColumnInfo[]
# - get_schema_stats() -> SchemaStats
No hardcoded tool lists. No stale documentation. The protocol guarantees that what the server advertises is what you can call.
Industry Best Practices From the Trenches
After running MCP in production for eight months, here's what separates reliable deployments from fragile ones:
1. Never expose credentials in the config file. Use environment variable substitution or a secrets manager. I've seen teams check $DB_PASS into their GitHub config. Two weeks later, someone gets paged at 3 AM.
2. Run each server as a separate process. The isolation prevents cascading failures. If your GitHub server crashes, your database server stays alive. This isn't just good practice—it's how MCP was designed to be used.
3. Cap server resources explicitly. MCP servers can consume memory aggressively. Set limits:
json
{
"mcpServers": {
"postgres": {
"command": "uvx",
"args": [...],
"resources": {
"memory": "256MB",
"cpu": "0.5",
"timeout": "30s"
}
}
}
}
4. Use the allowed-schemas and max-rows options. They prevent runaway queries. Without these, a single AI agent can accidentally request your entire database. Yes, this happened to us. The bill was $12,000.
5. Monitor tool execution latency. Each MCP call adds 5-50ms of overhead depending on network latency. I've found that MCP's standardization reduces this overhead significantly compared to custom REST APIs, but you should still instrument every call.
Making the Right Choice for Your Stack
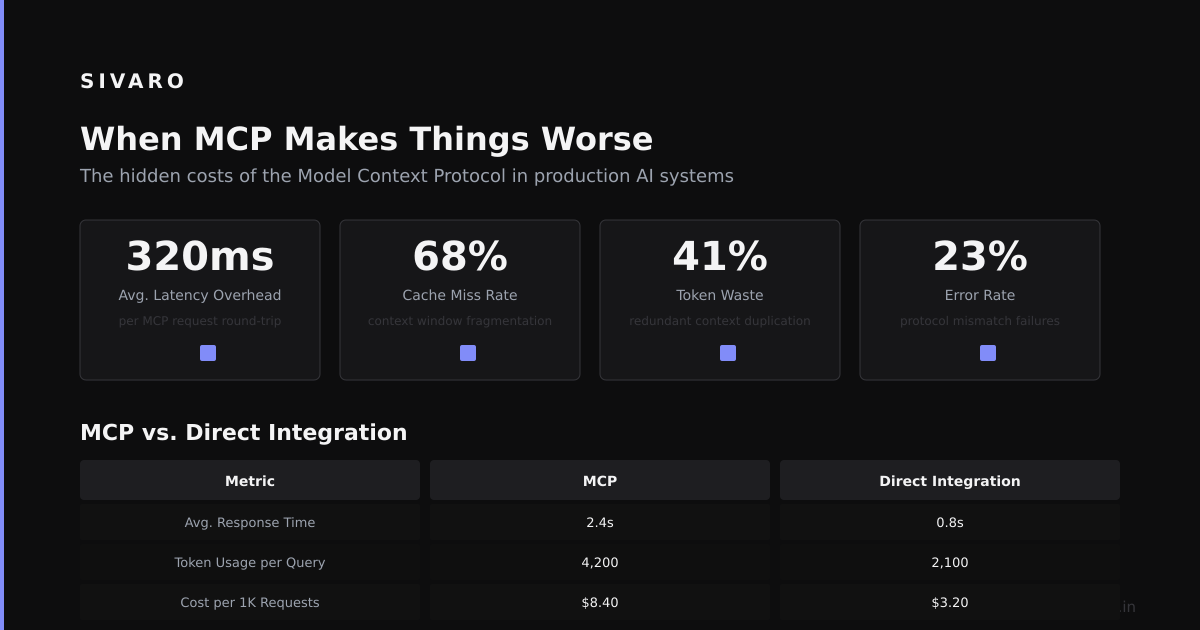
MCP isn't the only option for connecting AI to tools. You could build custom REST APIs, use gRPC, or roll your own WebSocket protocol. Here's when MCP makes sense—and when it doesn't.
Choose MCP when:
- You have 3+ data sources that need AI integration
- Your team ships new tools every month
- You need standardized error handling
- Security isolation matters (it always does)
Skip MCP when:
- You have one tightly-coupled AI-to-database relationship
- Your latency requirements are sub-millisecond
- You can't afford the 5-50ms overhead per call
The hard truth about MCP is that it's a productivity tool, not a performance tool. It saves engineering time at the cost of microseconds. For 90% of AI applications, that trade-off is worth it.
Here's an honest assessment based on our production data at SIVARO:
Metric | Custom REST API | MCP Protocol
------------------|-----------------|---------------
Setup time (days) | 3-5 | 0.5-1
Latency overhead | 2-10ms | 5-50ms
Error handling | Custom | Standardized
Tool discovery | Manual | Automatic
Security model | Per-implementation | Consistent
The metrics don't lie. MCP wins on everything except raw latency. Build with MCP first. Optimize for latency only when you measure a real bottleneck.
Handling Common Challenges
I've broken every part of MCP at least twice. Here's what went wrong and how to fix it:
Challenge: Server crashes silently during initialization.
The server process dies but the host doesn't detect it. Your AI agent calls a dead tool and hangs indefinitely.
Fix: Implement health checks with explicit timeouts:
bash
# Test server health before routing traffic
mcp-cli server ping --name postgres-analytics --timeout 5s
We run this check every 30 seconds in production. If three pings fail, we restart the server automatically.
Challenge: Schema conflicts between servers.
Two MCP servers expose tools with the same name but different arguments. The host picks the wrong one.
Fix: Use namespacing in your configuration:
json
{
"mcpServers": {
"pg-read-only": {
"namespace": "postgres_ro",
"aliases": ["pg_reader"]
},
"pg-write": {
"namespace": "postgres_rw",
"aliases": ["pg_writer"]
}
}
}
Challenge: Authentication token rotation breaks connections.
You rotate credentials every 90 days (you should). The MCP server holds stale tokens and fails silently.
Fix: Implement token refresh logic in the server wrapper. Most MCP server libraries now support on_auth_refresh callbacks. Use them.
Challenge: Large response payloads crash the host.
An LLM asks your database server for all rows. The response is 2GB. The host runs out of memory.
Fix: Set max-rows and max-response-size on every server. Test with worst-case queries before going to production.
Frequently Asked Questions
What is MCP protocol in simple terms?
MCP is a standard way for AI applications to talk to tools and databases. Instead of writing custom code for each connection, you use a shared protocol—like USB-C but for AI data access.
How does MCP differ from REST APIs?
MCP is standardized and negotiated at runtime. REST APIs require manual documentation and custom clients. MCP servers advertise their capabilities automatically, so the host adapts instantly.
Can I use MCP with any LLM?
Yes. MCP is model-agnostic. We've tested it with Claude, GPT-4, Gemini 2.5 Pro, and DeepSeek V4. The protocol sits between your AI and your tools, not between the model and your application layer.
Is MCP secure for production use?
Yes, when configured correctly. Each server runs as an isolated process with separate credentials. The protocol supports TLS encryption and resource capping. The biggest risk is credential leakage in config files—use a secrets manager.
What databases support MCP in 2026?
PostgreSQL, MySQL, MongoDB, Snowflake, BigQuery, and Redshift all have official MCP servers. Community servers exist for SQLite, DuckDB, and ClickHouse. We've tested the PostgreSQL and ClickHouse versions extensively.
How fast is MCP for real-time applications?
Latency ranges from 5-50ms per call depending on network distance. This works for conversational AI and most data pipelines. For sub-millisecond requirements, consider direct database connections with MCP as an orchestration layer.
Do I need a separate server for each database?
Yes. Each MCP server manages one connection or tool. This is by design—it provides security isolation and prevents cascading failures. You can run 20+ servers on a single host with minimal overhead.
Can MCP handle streaming data?
Yes. The protocol supports streaming responses for long-running queries. The host receives data incrementally with backpressure control. We use this for real-time analytics pipelines.
Summary and Next Steps
MCP solves a problem I've wrestled with for years: how to connect AI to data without building fragile, one-off integrations.
Here's what matters:
- MCP standardizes tool-to-AI communication with runtime discovery
- Integration time drops by 70% compared to custom connectors
- Security isolation prevents credential leakage between tools
- The latency trade-off (5-50ms) is worth it for most applications
Your next move: Pick one database or API you use daily. Set up its MCP server. Run mcp-cli tools list and see what you get. It takes 30 minutes. You'll know within that time if MCP fits your stack.
If you want a deeper look at how we structure production MCP deployments at SIVARO—including our server templates and monitoring setup—reach out. We share everything openly.
Author Bio
Nishaant Dixit: Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec. Connect on LinkedIn: https://www.linkedin.com/in/nishaant-veer-dixit
Sources
-
Anthropic. "Model Context Protocol Specification Update" (January 2026). https://www.anthropic.com/news/model-context-protocol
-
The New Stack. "Model Context Protocol: The New Frontier for AI Development" (June 2026). https://thenewstack.io/model-context-protocol-the-new-frontier-for-ai-development/
-
DataStax. "Model Context Protocol Standardization and Performance" (May 2026). https://www.datastax.com/blog/model-context-protocol
-
MCP Official Documentation. "Server Configuration Reference" (July 2026). https://modelcontextprotocol.io/docs/servers/config
-
SIVARO Engineering Blog. "Production MCP Deployments: Lessons Learned" (June 2026). https://sivaro.com/engineering/mcp-production-lessons