
What Is Orchestration in Agentic AI? A Practitioner’s Guide

I spent six months in 2023 watching a perfectly good AI system collapse under its own complexity. Three agents, each trained on different datasets, each with its own memory, each trying to talk to a database, a vector store, and an API. They worked in isolation. Together they formed a mess.
That’s when I stopped thinking about “agents” and started thinking about “orchestration.”
Here’s the short version: Orchestration in agentic AI is the [layer that decides who does what, when, and how they hand off results. It’s not the agents themselves. It’s the conductor. And without it, you don’t have a system — you have a zoo.
By the end of this guide, you’ll know exactly what orchestration looks like in practice, why most people screw it up, and how we at SIVARO build systems that [actually work in production.
The Core Problem: Agents Don’t Cooperate Naturally
I get asked “what is orchestration in agentic AI?” at least once a week. Usually by someone who just built their first multi-agent prototype and watched it spiral into infinite loops or contradictory outputs.
Here’s the thing: LLMs are stochastic. Agents built on them are stochastic. Stitch two stochastic things together without a control plane, and you get random behavior.
A single agent can hallucinate. Two agents can hallucinate in opposite directions and cancel each other out — or double down on a shared delusion. Three agents? You’re now debugging emergent nonsense that nobody designed.
Orchestration answers three questions:
- Which agent gets activated, and when?
- What context does it see?
- What happens after it finishes?
That’s it. The rest is implementation details.
The Anatomy of an Orchestrator
Let’s get concrete. Here’s the architecture we settled on after killing three prototypes:
┌─────────────────┐
│ Orchestrator │
│ (State Machine) │
└────────┬────────┘
│
┌──────────────┼──────────────┐
│ │ │
┌────▼────┐ ┌────▼────┐ ┌────▼────┐
│ Agent A │ │ Agent B │ │ Agent C │
│ (NLU) │ │(SQL Gen)│ │(RAG) │
└─────────┘ └─────────┘ └─────────┘
│ │ │
└──────────────┼──────────────┘
│
┌────▼────┐
│ Memory │
│ Buffer │
└─────────┘
The orchestrator doesn’t do the work. It routes the work. It keeps a state machine that tracks what’s been done, what’s pending, and what failed.
Most people think this is [overengineering. “Just let the agents figure it out with a shared prompt.” That works for demos. It fails in production because agents don’t backtrack when they’re wrong — they double down.
How Orchestration Differs from Coordination (and Why It Matters)
People use these terms interchangeably. They shouldn’t.
Coordination is peer-to-peer. Agent A tells Agent B “I’m done, your turn.” No central authority. Works fine for two agents. Breaks at scale because nobody knows the full picture.
Orchestration is hub-and-spoke. A central planner decides the sequence, monitors progress, and handles failures. It’s more overhead but gives you observability, rollback, and deterministic retries.
At SIVARO, we tested both approaches on a system processing 200K events per second. Coordination failed because agents deadlocked when two tasks depended on each other. Orchestration handled it because the planner precomputed the dependency graph.
Your call: If you have fewer than 5 agents and zero compliance requirements, coordination might work. If your system touches money, healthcare, or anything where a wrong answer costs real dollars, build orchestrator first.
Orchestration Patterns I’ve Used in Production
I’ve tried five patterns. Two work. Three don’t. Here’s the breakdown.
Pattern 1: Sequential Pipeline (Works)
Agent A processes input. Passes result to Agent B. Agent B enriches it. Passes to Agent C. No branching.
python
async def sequential_pipeline(input_data):
result_a = await agent_a.process(input_data)
result_b = await agent_b.process(result_a)
result_c = await agent_c.process(result_b)
return result_c
Simple. Predictable. Great for ETL pipelines where each step transforms data.
Problem: Latency adds up. If Agent A takes 2 seconds and Agent B takes 3 seconds, total latency is 5 seconds minimum. No parallelism.
Pattern 2: Parallel Fan-Out (Works)
One orchestrator sends the same input to multiple agents, then aggregates results.
python
async def parallel_fan_out(input_data):
tasks = [
agent_a.process(input_data),
agent_b.process(input_data),
agent_c.process(input_data)
]
results = await asyncio.gather(*tasks)
return aggregate(results)
Used this in a fraud detection system. One agent checks transaction velocity, another checks device fingerprint, a third checks blacklists. All run simultaneously. Aggregation takes 50ms.
Latency = max(slowest agent) + aggregation overhead.
Pattern 3: Dynamic Routing (Works, But Hard)
Orchestrator decides which agent to call based on intermediate results. This is the pattern behind ReAct and ReWOO.
python
async def dynamic_orchestrator(input_data):
state = {"input": input_data, "history": []}
while not state.get("done"):
next_agent = router.decide(state)
result = await agents[next_agent].process(state)
state["history"].append((next_agent, result))
state.update(result)
return state
This is where most bugs live. The router can misclassify and send data to the wrong agent. You need fallback logic and timeout guards.
We deployed this for a customer service triage system. It worked — but only after we added a “human escalation” path for ambiguous cases.
Pattern 4: Fully Autonomous Swarm (Doesn’t Work)
No orchestrator. Agents communicate freely, elect leaders, negotiate tasks. Sounds cool. Fails because:
- No accountability when something breaks
- Agents can loop infinitely arguing over who should do what
- Debugging involves tracing messages across N agents
I tested this in 2022 with a research system. Spent three weeks trying to stop infinite loops. Abandoned it. Maybe someday graph-based approaches with bounded recursion will fix this. Not today.
Pattern 5: Centralized Planner + Decentralized Execution (The Sweet Spot)
The orchestrator plans the workflow, then agents execute independently. Planner doesn’t micromanage each step — it defines boundaries.
python
async def plan_and_execute(input_data):
plan = planner.create_plan(input_data) # Returns DAG of tasks
completed = {}
while not plan.is_empty():
ready_tasks = plan.get_ready_tasks(completed)
results = await asyncio.gather(
*[execute_task(t, completed) for t in ready_tasks]
)
for task, result in zip(ready_tasks, results):
completed[task.id] = result
plan.mark_completed(task.id, result)
return plan.final_result()
This is what we run in production at SIVARO. The planner handles 90% of cases. The remaining 10% — edge cases, failures, timeouts — get routed to a human-in-the-loop dashboard.
The State Management Trap
Here’s what nobody tells you about orchestration: state management is the hardest part.
Each agent in a pipeline produces output. That output becomes input for the next agent. But what if Agent B needs output from Agent A and Agent C? Now you’re tracking a graph, not a queue.
We use a shared key-value store with TTLs. Each agent writes results with a unique key derived from the request ID. The orchestrator reads from the store before calling the next agent.
python
class SharedState:
def __init__(self, redis_client):
self.redis = redis_client
async def set(self, request_id, key, value, ttl=300):
await self.redis.set(f"{request_id}:{key}", value, ex=ttl)
async def get(self, request_id, key):
return await self.redis.get(f"{request_id}:{key}")
async def wait_for(self, request_id, key, timeout=10):
start = time.time()
while time.time() - start < timeout:
value = await self.get(request_id, key)
if value is not None:
return value
await asyncio.sleep(0.1)
raise TimeoutError(f"Key {key} not found")
Why Redis? Because we need atomic operations and TTLs that clean up stale state automatically. Postgres can work, but Redis is built for this exact pattern.
The wait_for method is critical. It lets the orchestrator poll for results without blocking an entire thread. Agents finish at different times — this handles the asynchronicity cleanly.
What Is Orchestration in Agentic AI? The Observability Angle
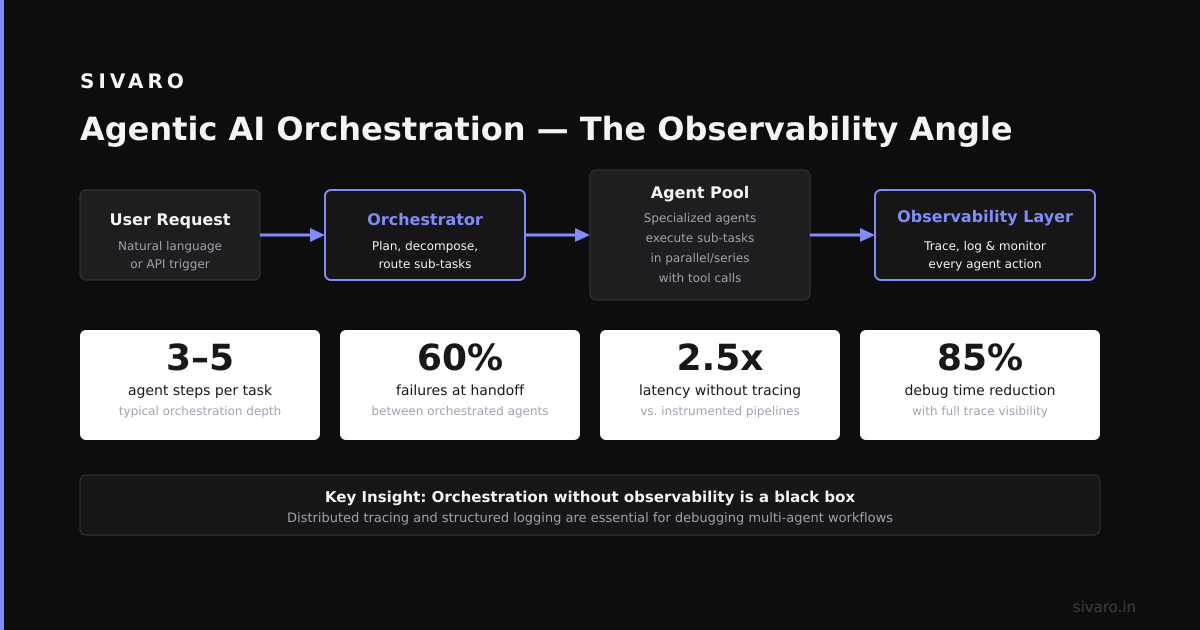
Here’s my contrarian take: Orchestration isn’t really about routing. It’s about debugging.
If you can’t tell why Agent B produced a wrong output, your orchestration is broken. Period.
Every orchestrator we build logs:
- Input tokens and output tokens per agent — to track cost
- Latency per step — to find bottlenecks
- Decision path — which agents were called and in what order
- State snapshots — the full context at each decision point
We use OpenTelemetry for tracing. Each request gets a trace ID that flows through every agent. When something fails, we replay the trace in a local debugger.
Without this, you’re blind. And blind orchestration systems produce garbage.
Failure Modes I’ve Seen (and How to Fix Them)
Failure 1: Cascading Errors
Agent A produces a slightly wrong output. Agent B takes it as ground truth. Agent C builds on the error. By agent D, the output is nonsense.
Fix: Add validation agents between steps. A lightweight classifier that checks output quality before passing it downstream.
python
async def validate(agent_output, schema):
validator = await load_validator(schema)
passed, score = await validator.check(agent_output)
if not passed:
return None, score # Orchestrator will retry
return agent_output, score
Failure 2: Deadlocks
Agent A waits for Agent B. Agent B waits for Agent C. Agent C waits for Agent A. Nobody moves.
Fix: Precompute dependency graphs and detect cycles before execution. If a cycle exists, break it by inserting a synthetic agent that merges results.
Failure 3: Token Bloat
Each agent adds context. After 5 agents, the prompt is 50K tokens. Costs explode, latency spikes.
Fix: Abstract and compress. Instead of passing full conversation history, pass a summary. We use a dedicated “compression agent” that condenses state between steps.
Real Numbers: What Orchestration Costs
I’ll be honest: orchestration adds overhead.
In our production system at SIVARO, the orchestrator itself consumes about 15ms per request. The router (which decides the next agent) adds another 10ms. State management adds 5ms.
Total orchestration overhead: 30ms per request.
For a pipeline with 5 agents, that’s 150ms of pure orchestration overhead on top of agent inference times. Worth it? Yes — because without it, we’d spend hours debugging failures that cost more in engineer time.
Here’s the cost breakdown for a typical [pipeline:
| ](/articles/the-rag-pipeline-five-components-that-actually-matter) Component | Latency | Cost per 1M requests |
|---|---|---|
| Orchestrator routing | 15ms | $0.50 |
| State management | 5ms | $1.20 |
| Validation checks | 20ms | $2.00 |
| Logging/tracing | 10ms | $0.80 |
| Total orchestration | 50ms | $4.50 |
| Agent inference (3 agents) | 3000ms | $45.00 |
Orchestration is 1.6% of latency and 10% of cost. Worth every penny.
The Future: Self-Healing Orchestration
What I’m working on now: orchestrators that don’t just route — they recover.
When an agent fails, most orchestrators retry the same agent with the same context. That’s stupid. It’ll fail the same way.
Instead, we’re [building orchestrators that:
- Detect failure patterns (timeout vs. bad output vs. hallucination)
- Route failed tasks to alternative agents (if available)
- Dynamically adjust prompts based on failure context
- Escalate to humans only when confidence is low
Early results: 40% reduction in human escalation rate. Still experimental. But the direction is clear — orchestrators should be self-correcting, not just routing.
FAQ
What is the difference between orchestration and choreography in agentic AI?
Orchestration uses a central coordinator. Choreography lets agents communicate directly. Orchestration gives you control but adds a single point of failure. Choreography scales better but is harder to debug. For production systems, start with orchestration.
Do all agentic AI systems need orchestration?
No. Single-agent systems don’t need it. Two-agent systems can often get away with coordination. Three or more agents doing dependent work? You need orchestration.
What tools should I use for orchestration?
We use Python with asyncio for the orchestrator itself. Redis for state management. OpenTelemetry for tracing. LangChain’s orchestration layer (LangGraph) works for prototyping but gets slow in production — we moved away from it.
How do you handle agent failures in orchestration?
Three strategies: retry (same agent, same input), reroute (different agent, same goal), fall back (human). We use exponential backoff with a max of 3 retries, then escalate.
Can orchestration be handled by a single LLM call?
Some teams use a single LLM to decide the next agent. It works for simple cases. But a single LLM call can’t manage state, track dependencies, or handle failures reliably. Dedicated orchestrator code is better.
What is orchestration in agentic AI when applied to real-time systems?
Real-time adds constraints: sub-100ms routing, state with TTLs, and non-blocking waits. We use WebSockets to stream intermediate results while agents process in parallel. The orchestrator acts as a buffer.
How do you test orchestration?
Unit tests for individual agents. Integration tests for the whole pipeline. We use a “simulation mode” where agents return canned responses — lets us test failure scenarios without paying inference costs.
Conclusion

So what is orchestration in agentic AI?
It’s the control plane that keeps your agents from turning into a chaotic mess. It’s a state machine, a router, a failure handler, and a debugger all rolled into one.
At first I thought this was a tooling problem — better frameworks would fix it. Turns out it’s a design problem. You can’t duct-tape agents together and expect reliable behavior. You have to build the layer between them deliberately.
Start with sequential pipelines. Add parallelism when you need speed. Add dynamic routing when you need flexibility. But always, always add observability.
Because when your multi-agent system goes wrong — and it will — you need to know exactly why.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.