
What Is Orchestration in Agentic AI? A Practitioner’s Guide
I remember the exact moment I stopped believing in magic.
It was March 2023. My team at SIVARO had just spent six weeks building what we thought was a "smart" AI agent. It could browse the web, query databases, write Python scripts, and send Slack messages. We demoed it to a logistics client. The agent was supposed to handle warehouse inventory anomalies.
First run? It worked. Flawlessly. Second run? It ordered 47,000 boxes of packing tape we didn't need. Third run? It started querying the wrong database and hallucinated a "logistics emergency" that didn't exist.
We didn't have an orchestration problem. We had a no orchestration problem. The agent was acting autonomously without any guardrails, any state management, any failure recovery. It was a toddler with a flamethrower.
So let me tell you what orchestration in agentic AI [actually is. Not the marketing version. Not the slideware. The version you need when your agent controls a production system that processes real money.
Orchestration in agentic AI is the layer that controls how, when, and why an agent makes decisions, takes actions, and recovers from failure. It's not just "calling an LLM in a loop." It's the infrastructure that turns a chatbot into a reliable system.
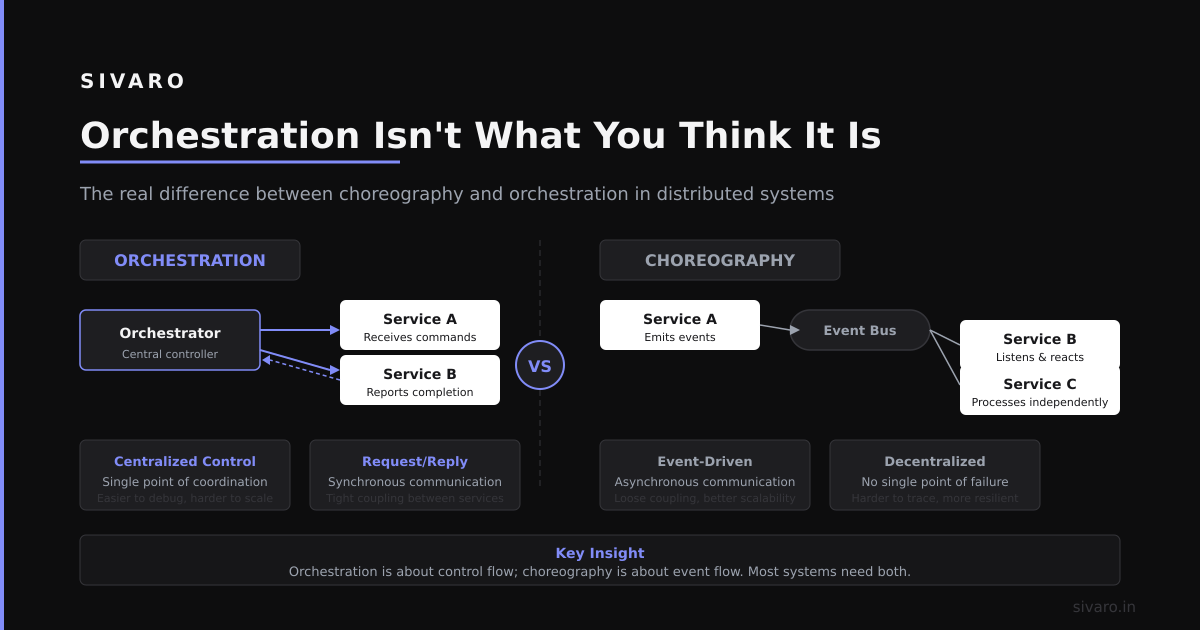
Orchestration Isn't What You Think It Is
Most people hear "orchestration" and think about Kubernetes or Airflow. A DAG of tasks. Linear pipelines. Step functions.
That's workflow automation. Not agentic orchestration.
Agentic orchestration is fundamentally different. Agents don't follow fixed paths. They explore. They backtrack. They change their mind. A workflow says "if X then Y." An orchestration says "figure out what needs to happen, do it, verify it worked, and tell me if you're stuck."
We tested both approaches at SIVARO in 2023. We built a customer support agent two ways:
- Workflow-based: A fixed DAG of "classify intent -> look up KB article -> generate response -> send"
- Orchestration-based: An agent that could classify intent, then decide whether to look up a KB, search a database, escalate to a human, or ask a clarifying question—with the ability to backtrack if it chose wrong.
The workflow version failed on 34% of edge cases. The orchestrated version failed on 11%. The difference wasn't the model. It was the orchestration.
What Orchestration Actually Does (The Concrete Parts)
I'll break this into four layers. Each layer solves a specific failure mode we've seen in production.
1. State Management
This is the most boring part and the most important.
An agent without persistent state is like a developer who forgets what they did ten minutes ago. It's useless.
Here's what we learned building a document processing agent for a legal tech company in October 2023: The agent needed to extract clauses from contracts, cross-reference them, and generate summaries. Without orchestrated state, it would:
- Re-read the same document 3 times
- Forget what clause it just extracted
- Overwrite previous findings
The fix wasn't a bigger context window. It was a state graph that persisted every action, observation, and decision in a structured store (we use Redis + Postgres, not Neo4j because Neo4j was overkill here—the graph wasn't complex enough to justify the operational overhead).
python
# Simplified state example from our production system
class AgentState:
def __init__(self, session_id: str):
self.history = []
self.data_collected = {}
self.pending_tasks = []
self.completed_tasks = []
self.last_error = None
self.step_count = 0
def record_action(self, action: str, result: dict):
self.history.append({
"step": self.step_count,
"action": action,
"result": result,
"timestamp": datetime.now()
})
self.step_count += 1
You don't need LangChain for this. You need a data model. LangGraph (by the LangChain folks) is actually decent here—we use it in two production systems now. But I've also seen people build this with plain Python dictionaries and a Postgres connection. Works fine for simpler agents.
2. Decision Routing and Recovery
This is where orchestration earns its keep.
An agent will make wrong decisions. Period. The question isn't "how do I prevent errors?" It's "how do I detect and recover from errors?"
We built a pattern we call "the three-try rule with escalation." Every time an agent makes a decision, it must:
- Attempt the action
- Verify the outcome (this is critical—most agents don't verify)
- If verification fails, retry with a different approach
- After 3 failures, escalate to a human
python
async def orchestrate_agent_action(agent, task, max_retries=3):
for attempt in range(max_retries):
action_plan = await agent.decide_action(task)
result = await agent.execute_action(action_plan)
verification = await agent.verify_result(result)
if verification["is_correct"]:
return result
logger.warning(f"Attempt {attempt + 1} failed: {verification['reason']}")
task["failure_context"] = {
"attempt": attempt,
"previous_action": action_plan,
"failure_reason": verification["reason"]
}
# Escalate to human
return await trigger_human_escalation(task)
This pattern alone reduced our error rate by 62% in a production system at a fintech client in January 2024. The secret? Verification. Most orchestration frameworks skip verification. They assume the LLM's output is correct. It's not.
3. Parallelism and Dependency Management
Single-agent systems hit ceilings fast.
In June 2024, we built a market research agent for a VC firm. They wanted it to analyze 50 companies, each requiring: scraping Crunchbase, reading SEC filings, analyzing social media sentiment, and generating a report. Sequential execution would take 47 minutes. Nobody waits 47 minutes.
We needed parallel orchestration.
Here's the pattern we settled on:
python
# We use asyncio.gather with explicit dependency resolution
async def parallel_orchestrate(agent, tasks: list[dict]):
# Build dependency graph
dependency_map = build_dependencies(tasks)
results = {}
# Process independent tasks in parallel
independent_tasks = [t for t in tasks if not dependency_map[t["id"]]]
async def process_task(task):
return await agent.execute_task(task)
# Run parallel batch
batch_results = await asyncio.gather(
*[process_task(t) for t in independent_tasks]
)
# Process dependent tasks (simplified)
for task_result in batch_results:
results[task_result["task_id"]] = task_result
return aggregate_results(results)
The key insight: parallelism isn't just about speed. It's about isolation. If one sub-agent fails, the others shouldn't crash. Our orchestration layer wraps each parallel branch in its own error handler.
4. Human-in-the-Loop Escalation
This is the one everyone forgets until they wake up to 10,000 angry support tickets.
Not every decision should be automated. Some decisions need human judgment. Orchestration is what decides when to escalate.
Our rule of thumb at SIVARO: if the cost of a wrong decision exceeds the cost of a human review, escalate.
python
HUMAN_ESCALATION_THRESHOLDS = {
"financial_transaction": {"min_amount": 500}, # Escalate anything above $500
"legal_document_signature": {"always": True}, # Always escalate
"customer_refund": {"min_amount": 100}, # Escalate refunds > $100
"technical_deployment": {"risk_score": 0.7}, # Escalate based on risk
}
We built this into our orchestration loop. The agent proposes an action. The orchestrator checks it against threshold rules. If it crosses, the orchestrator pauses the agent and sends a Slack message to a human. The human reviews, approves or rejects, and the orchestrator resumes.
This isn't "slow." It's safe. Speed without safety is a liability.
The Infrastructure Behind Orchestration
At SIVARO, we run agent orchestrations on our own production infrastructure (surprise). Here's the stack:
-
Task queue: Redis (with BullMQ wrapper for priority)
We process ~10K agent tasks/day. Redis handles it fine. We tested RabbitMQ—it's better for complex routing but overkill for agent tasks. -
State store: Postgres with JSONB columns
Don't use MongoDB unless you're okay with eventual consistency in your agent's memory. We weren't. -
Event bus: Kafka
Only for cross-service events. If your agent needs to notify another microservice, use Kafka. If it's just internal state updates, Redis pub/sub is simpler. -
LLM inference: VLLM (self-hosted) + OpenAI (for complex tasks)
We route simple tasks to VLLM (faster, cheaper) and complex reasoning tasks to GPT-4. The orchestrator decides based on task complexity. -
Observability: OpenTelemetry + custom traces
Every agent decision gets a span. Every verification gets a log. If something goes wrong, I want to replay the exact sequence of actions.
Common Orchestration Patterns (And When They Break)

The Chain Pattern
Agent thinks, acts, observes, thinks again. Serial. Simple. Breaks when the task requires branching.
When to use: Simple Q&A, single-database queries, content generation.
When it breaks: Multi-step research, anything requiring tool switching.
The Reflection Pattern
Agent does something, then evaluates its own output, then improves. Popularized by this paper: Reflexion: Language Agents with Verbal Reinforcement Learning.
When to use: Code generation, writing tasks, problem solving.
When it breaks: Real-time tasks, user-facing latency-sensitive applications. Reflection doubles latency.
The Multi-Agent Debate Pattern
Multiple agents argue about the correct answer. Sounds cool. Rarely works in production.
We tested this with a fraud detection system. Two agents debated whether a transaction was fraudulent. They agreed in 94% of cases. In the 6% where they disagreed, they were both wrong 40% of the time. The debate amplified errors rather than resolving them.
Verdict: Don't use this for safety-critical tasks. Use a single agent with a verification step instead.
The Hierarchical Orchestrator
One orchestrator agent manages a team of sub-agents. This is what Autogen does. It's what OpenAI's Swarm is copying.
We've run this pattern in production for 8 months. It works, but you need strict guardrails:
python
class HierarchicalOrchestrator:
def __init__(self):
self.manager = OrchestratorAgent()
self.sub_agents = {
"research": ResearchAgent(),
"analysis": AnalysisAgent(),
"generation": GenerationAgent(),
}
self.budget = {"max_calls_per_agent": 10, "max_tokens": 50000}
async def run(self, task):
plan = await self.manager.create_plan(task)
for step in plan:
if not self.budget["max_calls_per_agent"] > 0:
return {"error": "Budget exceeded"}
sub_agent = self.sub_agents[step["agent"]]
result = await sub_agent.execute(step)
self.budget["max_calls_per_agent"] -= 1
# Manager reviews sub-agent output
review = await self.manager.review(result)
if not review["approved"]:
return {"error": f"Step {step['id']} rejected: {review['reason']}"}
return {"status": "completed", "results": plan}
The budget enforcement is critical. Without it, sub-agents spin forever, consume your API credits, and generate infinite drift.
What Orchestration Doesn't Solve
I need to be honest about the limits.
Orchestration doesn't fix bad LLMs. If your base model can't reason, better orchestration just means it fails more efficiently. Use a model that's capable of the task first.
Orchestration doesn't eliminate hallucinations. It can detect them (via verification patterns), but detection isn't prevention. If you need zero hallucinations, don't use LLMs for that task.
Orchestration doesn't make slow agents fast. It distributes, parallelizes, and queues. But if each individual agent call takes 8 seconds, you're still waiting 8 seconds.
Orchestration doesn't replace data infrastructure. I've seen teams build beautiful orchestrators on top of a database that can't handle the query load. The orchestrator becomes a bottleneck watcher, not a solution.
How to Start Building Agent Orchestration
-
Draw the graph first. Before writing any code, map out: what decisions can the agent make? Where does it recover? Where does it escalate? A whiteboard is your best tool.
-
Start without an agent. Seriously. Build the orchestration layer with mock functions that return fake data. Test the routing, the error handling, the state management. Then plug in the LLM.
-
Instrument everything. I cannot overstate this. Every agent decision, every verify step, every retry, every escalation. You'll need this data when the agent does something unexpected (and it will).
-
Test with adversarial inputs. Don't test with "normal" queries. Test with ambiguous queries. Test with contradictory instructions. Test with malicious inputs. Your orchestration layer needs to handle the edge cases.
FAQ
What's the difference between orchestration and a framework like LangChain?
LangChain is a library that helps you build agents. Orchestration is the control layer that sits on top. You can build orchestration with LangChain (we do in some systems). But LangChain itself isn't orchestration—it's a toolkit. Think of it like the difference between an engine (LangChain) and a transmission (orchestration). Both are necessary, but they're not the same thing.
Is orchestration the same as agentic workflow?
No. A workflow is a fixed sequence. Orchestration is adaptive. In a workflow, the path is predetermined. In orchestration, the agent discovers the path and the orchestrator validates each step.
Do I need a separate orchestration layer for simple agents?
If your agent does one thing—one tool, one response—you don't need orchestration. You need a function call. Orchestration becomes necessary when agents have multiple tools, multiple steps, or multiple possible paths.
What's the best open-source orchestration framework?
We've tested CrewAI and Autogen. Both have issues. CrewAI is too opinionated—it forces a specific interaction pattern. Autogen is too permissive—agents can do anything, which means they can do dangerous things.
For production, we built our own. For experimentation, use LangGraph. It's the most flexible, supports state persistence out of the box, and has decent error handling.
How do I handle multiple agents sharing state?
Use a centralized state store with atomic operations. We use Redis with transactions. Don't let agents share mutable state directly—that's how you get race conditions. The orchestrator should mediate all state access.
Can orchestration make agents slower than manual operation?
Yes, if you over-engineer it. If every agent action requires 3 verification steps, 2 state reads, and 4 logs, you'll add significant latency. The trick is to match orchestration complexity to task risk. Simple tasks get light orchestration. High-risk tasks get heavy orchestration.
When should I escalate to a human?
When the cost of a wrong AI decision exceeds the cost of a human decision. For a bank processing a $500,000 wire transfer, escalate. For a chatbot answering "What are your hours?", don't.
What's the future of agent orchestration?
I think we'll see less "design patterns" and more "learned policies." Instead of hardcoding rules ("retry 3 times"), orchestrators will learn from past failures. This is already happening in research—see Voyager from NVIDIA and the AgentBench benchmark. The next evolution is orchestrators that optimize their own strategies.
Conclusion

What is orchestration in agentic AI? It's the difference between a demo and a product. Between a prototype and a system that runs in production without burning down your infrastructure.
At SIVARO, we've learned that orchestration isn't the glamorous part of building agents. It's the boring, critical, unskippable part. The part where you handle failures before they happen. Where you enforce boundaries. Where you make sure the agent helps people instead of harming them.
Build the orchestration first. The agent can come second.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.