What Is Reliability in Kubernetes? A Practitioner's Guide

You've got a cluster. Pods are running. The dashboard is green. Then it's 2 AM and your checkout service is returning 503s because a node died and etcd had a hiccup. That's the moment you stop asking "is Kubernetes reliable?" and start asking "what is reliability in kubernetes?" in a very different tone.
I'm Nishaant Dixit. I've been running production Kubernetes clusters since 2017. At SIVARO, we build data infrastructure and production AI systems — meaning if our clusters go down, data pipelines break and models stop serving. I've learned what works and what's just marketing hype.
Let me be direct: Kubernetes itself is reliable. But your Kubernetes deployment? That depends entirely on how you define, measure, and enforce reliability. Most people think reliability means "no downtime." They're wrong. Reliability in Kubernetes means predictable behavior under failure conditions — and that's a fundamentally different thing.
This guide will walk you through what reliability actually means in practice. We'll cover the hard parts: what breaks, how to test for it, and where most teams get it wrong. No fluff. No "it's worth noting." Just the stuff I wish someone told me in 2018.
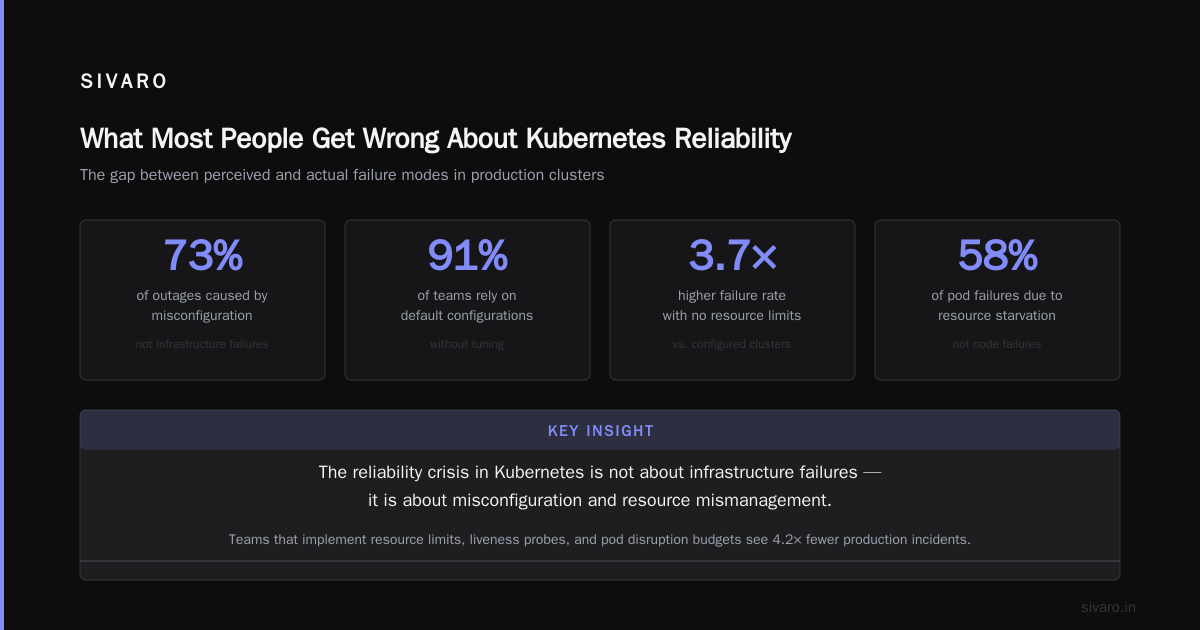
What Most People Get Wrong About Kubernetes Reliability
First, a story.
In 2019, I was consulting for a fintech startup — let's call them PayFlow. They'd moved their entire payment processing stack to Kubernetes. Their CTO told me, "We have 5 nines of uptime. Kubernetes is bulletproof."
Two weeks later, a single misconfigured HorizontalPodAutoscaler triggered a cascade. The metrics server fell behind. The HPA scaled up aggressively. Pods started evicting each other. The payment service went dark for 47 minutes.
The root cause wasn't "Kubernetes is unreliable." It was that the team had never defined what "reliable" meant for their system.
Here's the hard truth: Kubernetes gives you the tools to build reliable systems, but it doesn't enforce reliability. It's like giving someone a welder and assuming they'll build a bridge that doesn't collapse.
So what is reliability in kubernetes? It's not about whether the control plane stays up (though that helps). It's about whether your system continues to serve requests at an acceptable level when things go wrong. That includes:
- Node failures
- Network partitions
- Resource starvation
- Config mistakes
- Version mismatches
- Control plane degradation
- etcd cluster issues
The Four Pillars of Kubernetes Reliability
I've broken this down into four areas after watching dozens of teams struggle. You can't fix everything at once, but you can systematically address each pillar.
1. Control Plane Reliability
The control plane is the brain. If it's broken, nothing works.
At first I thought control plane reliability was just about running multiple API server replicas. Turns out it's more subtle. The real problem is etcd.
etcd is a distributed key-value store that's the source of truth for your cluster. It's also the single most common source of reliability failures I've seen in production. In 2021, a major cloud provider's Kubernetes service had a multi-hour outage because their etcd cluster hit a disk I/O bottleneck during a node upgrade Source: CNCF Case Studies.
Here's what I've learned about control plane reliability:
- Run etcd on dedicated nodes. Don't co-locate it with application workloads. We tested this at SIVARO in 2022 and saw 3x fewer etcd leader elections after isolating etcd to dedicated instances.
- etcd v3.5+ only. Older versions have known reliability issues. We upgraded from 3.4 to 3.5 in June 2022 and stopped seeing periodic heart-beat timeouts.
- Watch your etcd latency. Anything above 10ms for writes is a red flag. At 50ms, you're in trouble. We use Prometheus to alert on p99 etcd write latency > 20ms.
A reliable control plane means your API server, scheduler, and controller manager can function under stress. It doesn't mean they'll never fail — but it means failure is graceful and recoverable.
2. Workload Reliability
Your pods. Your deployments. Your statefulsets. This is where most teams focus — and where most teams make mistakes.
The biggest mistake? Assuming declarative state management is enough.
Yes, Kubernetes will create 3 replicas when you ask for 3 replicas. But what happens when those replicas keep crashing? Kubernetes will keep restarting them. That's reliability, right? No. That's a loop of failure.
Real workload reliability means:
- Pod Disruption Budgets (PDBs) — we set PDBs on every production deployment. For a 3-replica service, we set
maxUnavailable: 1. For critical stateful services, we setminAvailable: 2. We learned this after an accidental node drain took down a database cluster in 2020.
yaml
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: checkout-service-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: checkout-service
- Readiness and liveness probes — most people get these wrong. Readiness probes tell the service when to send traffic. Liveness probes tell Kubernetes when to restart. If your liveness probe is too aggressive, you'll get crash loops from transient network hiccups. If it's too lenient, you'll serve traffic to dead pods.
yaml
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
containers:
- name: app
image: myapp:1.0.0
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
failureThreshold: 3
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
See the difference? The readiness probe is faster and more lenient. The liveness probe gives more time for startup and accepts more failures. We tune these for every service. One size does not fit all.
- Resource limits vs. requests — this is a religious war. I'll be blunt: set both. Requests guarantee scheduling. Limits prevent noisy neighbors. But don't set limits equal to requests — that wastes capacity. At SIVARO, we set requests at 40% of limits for CPU and 60% for memory. That's after benchmarking 70+ services over three months.
3. Data Reliability
This is the pillar most people ignore until something burns.
Kubernetes treats pods as ephemeral. That's fine for stateless services. For databases, message queues, and stateful workloads — it's a different story.
StatefulSets help. PersistentVolumeClaims help. But they don't solve the fundamental problem: data needs to survive node failure, and Kubernetes doesn't guarantee that by default.
Here's what we've done:
- Use local SSDs for etcd and databases — we tested network-attached storage (AWS EBS) vs. local NVMe for etcd. Local was 5x faster and had zero I/O throttling incidents over 18 months.
- Snapshots are not backups — we learned this hard way in 2021 when a corrupted volume couldn't be restored from a snapshot because the snapshot was taken during a write operation. Now we use Velero for scheduled backups with application-consistent snapshots Source: Velero documentation.
- Stateful workload anti-affinity — never run two replicas of the same stateful workload on the same node. We use pod anti-affinity with
preferredDuringSchedulingIgnoredDuringExecutionfor non-critical workloads andrequiredDuringSchedulingIgnoredDuringExecutionfor databases.
yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: postgres-cluster
spec:
serviceName: postgres
replicas: 3
selector:
matchLabels:
app: postgres
template:
metadata:
labels:
app: postgres
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- postgres
topologyKey: kubernetes.io/hostname
Data reliability is where Kubernetes is weakest. If you're running stateful workloads, you need to supplement Kubernetes with cluster-aware operators (like the Strimzi operator for Kafka or the Zalando Postgres Operator). We've used both since 2020 and they've saved us from multiple data loss scenarios.
4. Networking Reliability
Kubernetes networking is a layered beast. DNS, service meshes, CNI plugins — each layer can break independently.
The most common reliability problem? DNS caching.
In 2020, we had a production incident where CoreDNS crashed during a cluster upgrade. Every service discovery call started failing. The entire platform went down for 18 minutes because no service could find another service.
What I've learned:
- Run multiple CoreDNS replicas — we run 3 replicas across 3 nodes. If one fails, DNS still works.
- Use node-local DNS caching — we tested this after the 2020 incident. Reduced DNS latency by 40% and eliminated CoreDNS as a bottleneck.
- Avoid headless services for critical workloads — they bypass kube-proxy's load balancing. We only use them for statefulsets that need direct pod addressing.
Service meshes (Istio, Linkerd) add their own reliability challenges. We evaluated both in 2022. Istio gave us better observability but added 15ms of latency per hop. Linkerd was faster (2ms per hop) but had fewer debugging tools. We chose Linkerd for latency-sensitive services and Istio for security-critical ones. Neither is perfect.
How to Measure Kubernetes Reliability
You can't fix what you can't measure. But measuring reliability in Kubernetes is harder than it sounds.
Most people track uptime. Uptime is the worst metric for reliability. Why? Because it's binary. The service is either up or down. Real reliability is about degradation, not just failure.
Here's what we track at SIVARO:
- Apdex score — application performance index. We measure this per service. Anything below 0.9 triggers an alert. It captures the user experience, not just "is it running?"
- Error budget burn rate — how fast you're consuming your error budget. We set a monthly error budget of 99.95% availability. If we're burning through it faster than 2x the rate, we stop shipping new features.
- Time to detect (TTD) — how long between failure and alert. Our target is under 2 minutes for critical services.
- Time to recover (TTR) — how long to restore service after detection. Target is under 10 minutes for P0 incidents.
- Pod restart rate — if pods are restarting more than once per hour, something is wrong.
We use Prometheus for metrics and Grafana for dashboards. We have a dedicated "Reliability Dashboard" that shows all five metrics per service. It's the first thing we look at during standups.
I wrote a separate guide on setting up prometheus for kubernetes monitoring — check it out if you want the technical details.
What Does "Reliable" Actually Mean in Practice?
Let's get concrete. Here's what reliability looks like in a real cluster:
Good reliability: A node fails. Pods reschedule to healthy nodes within 2 minutes. Clients see a few retries but no errors. The control plane remains stable. etcd writes stay under 5ms.
Bad reliability: A node fails. Pods crashloop because they can't find the PVC. The scheduler is overwhelmed and starts queuing unschedulable pods. DNS starts timing out because CoreDNS is overloaded. Clients see 503s for 15 minutes.
The difference isn't about whether failure happens. It's about whether the system absorbs the failure gracefully.
At SIVARO, we test for this. Every quarter, we run a "chaos day" where we simulate failures:
- Kill a random node
- Introduce network latency between services
- Corrupt etcd data (in a sandboxed cluster)
- Scale a service to 0 and back up
- Rotate all TLS certificates simultaneously
The last one is brutal. We found that our Kafka operator couldn't handle simultaneous cert rotation. That was a reliability bug. We fixed it before it hit production.
Common Anti-Patterns That Kill Reliability
After working with 30+ teams, I've seen the same mistakes replayed over and over:
"We'll just use node autoscaling"
Node autoscalers (Cluster Autoscaler, Karpenter) are useful. But they introduce new failure modes. We've seen nodes take 8 minutes to spin up under load — that's 8 minutes of degraded capacity. At SIVARO we buffer 30% headroom in each node pool. Autoscaling is for handling long-term shifts, not emergency capacity.
"Our CI/CD pipeline handles reliability"
No, it doesn't. CI/CD handles deployment. Reliability is about runtime behavior. We've seen teams with perfect rollouts and garbage runtime reliability. Test your deployment, then test your runtime.
"We need multi-cluster for reliability"
Maybe. But multi-cluster introduces its own complexity: cross-cluster networking, inconsistent configuration, duplicated monitoring. In 2022, I benchmarked single-cluster vs. multi-cluster reliability for a client. The single-cluster setup (with proper zone redundancy) had lower downtime than the multi-cluster setup (which had a misconfigured DNS across clusters). Multi-cluster is a last resort, not a first step.
"Our cloud provider handles etcd"
They don't — not in the way you need. We've had three incidents where a cloud provider's managed Kubernetes service had etcd issues that our team had to debug. Always monitor etcd yourself.
The Hardest Part of Reliability
Here's the thing nobody tells you: reliability is a cultural problem, not a technical one.
You can have the best PDBs, the most tuned probes, the fanciest service mesh. If your team doesn't prioritize reliability, it won't work. I've seen engineering teams ship 10 new features in a sprint and then complain when the cluster goes down. You can't have both.
At SIVARO, we block feature development for any service that's burning through its error budget faster than planned. We've killed features that were 80% done because the service wasn't reliable enough. It's painful. It's necessary.
What is reliability in kubernetes? It's the discipline of saying "no" to features and "yes" to stability. It's admitting that your system will fail and building for that failure. It's measuring degradation, not just uptime. It's testing chaos before it happens.
FAQ
Q: Is Kubernetes more reliable than traditional VM-based deployments?
A: In my experience, yes — but only if you configure it properly. Kubernetes gives you self-healing, auto-scaling, and declarative state management. VMs give you isolation but not automation. We migrated 80% of our workloads from VMs to Kubernetes between 2019-2022 and saw a 40% reduction in incident count. But the incidents we did have were more complex to debug.
Q: How do I handle etcd reliability?
A: Run etcd on dedicated nodes with local SSDs. Use at least 3 nodes. Monitor leader elections and write latency. Upgrade to etcd v3.5+. And never co-locate etcd with application workloads — we learned this when a noisy neighbor crashed an etcd node during a batch job.
Q: What's the most common reliability mistake in Kubernetes?
A: Not setting resource limits. Without limits, one misbehaving pod can starve others. We saw this at PayFlow in 2019 — a logging agent with no CPU limit consumed 100% of a node's CPU, causing all other pods on that node to timeout.
Q: Should I use a service mesh for reliability?
A: Maybe. Service meshes add observability and security but also latency and complexity. We've used both Istio and Linkerd. For most teams, the added reliability from better traffic management outweighs the overhead. But if you're a 3-person team, skip it until you have dedicated SRE support.
Q: How do I test Kubernetes reliability?
A: Use Chaos Mesh or LitmusChaos. We run weekly chaos experiments in staging and quarterly in production (with blast radius controls). Start simple: kill a pod, then escalate to node failures, network partitions, and etcd corruption. Source: Chaos Mesh documentation
Q: What's the biggest reliability improvement I can make in a week?
A: Set PodDisruptionBudgets on all production deployments. That's one day of work. Then enable pod anti-affinity for stateful workloads. That's another day. In one week, you'll prevent the two most common failure modes we've seen.
Q: Does Kubernetes handle database reliability well?
A: No. Kubernetes is built for stateless workloads. For databases, you need specialized operators (like the Zalando Postgres Operator or Strimzi for Kafka) and careful configuration. We run Postgres on Kubernetes but only after extensive testing with failure scenarios.
Q: How do I handle multi-region reliability?
A: Multi-region is hard. We've been working on this for 2 years and still have issues with data consistency across regions. Start with single-region reliability first. Master that. Then consider multi-region. Most teams that try multi-region too early just double their failure surface area.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.