
What Is the Basic Architecture of a Distributed System?
You're building something that needs to handle 10,000 requests per second. Or maybe you're migrating a monolith because Monday morning traffic killed your database. I've been there. At SIVARO, we've designed distributed [systems that process 200K events per second for logistics and fintech clients. Here's what I've learned about the bones of these systems.
Let's cut through the jargon. A distributed system is a collection of independent computers that appear to users as a single coherent system. Simple enough. But the architecture—that's where things get interesting. And painful.
What is the basic architecture of a distributed system? It's not one thing. It's a set of patterns and trade-offs. You'll make choices that haunt you at 3 AM during an outage. I've made those choices. Some worked. Some didn't.
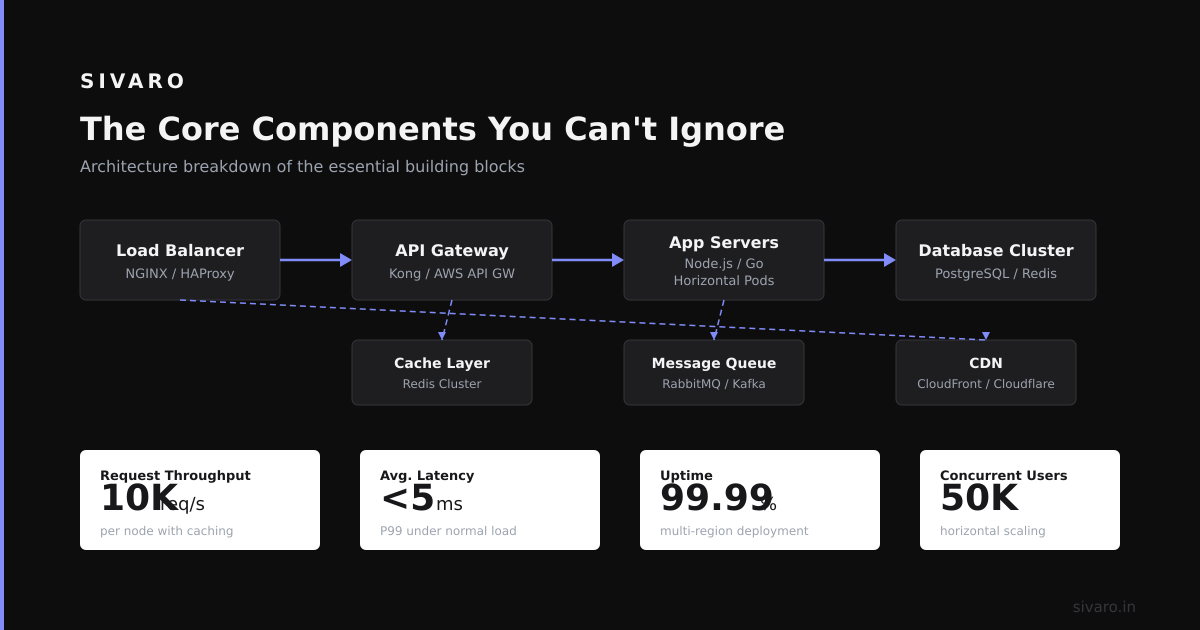
The Core Components You Can't Ignore
Every distributed system I've built or fixed shares five basic layers. Ignore any of these and you'll pay for it.
Nodes and Communication
A node is just a machine—physical server, VM, container. It does work. It talks to other nodes over a network. That network is where your problems start.
We tested gRPC vs REST for internal service communication at SIVARO in 2022. gRPC was 3x faster for high-throughput scenarios. But debugging it? A nightmare without proper tooling. REST was easier to trace. Pick your poison.
Here's what a basic node communication pattern looks like:
python
# Pseudocode for a simple distributed worker node
class Node:
def __init__(self, node_id, peers):
self.id = node_id
self.peers = peers # List of other nodes
self.state = "idle"
def send_message(self, target_node_id, message):
# Serialize, compress, encrypt, send over network
serialized = self.serialize(message)
response = self.network.send(target_node_id, serialized)
return self.deserialize(response)
def process_task(self, task):
# Actual work happens here
result = self.compute(task)
# Acknowledge completion to coordinator
self.send_message("coordinator", {"status": "done", "result": result})
Storage: Where Your Data Lives (or Dies)
Distributed storage is the hardest part. You've got three options, and none are perfect.
Shared storage (NFS, EBS) — easy to reason about, single point of failure, terrible latency across regions. We used this for a low-traffic internal tool. It worked until it didn't. Migration took three weekends.
Distributed databases (Cassandra, Spanner) — they scale horizontally. But consistency guarantees vary wildly. Cassandra promised "eventual consistency." In practice, that could mean minutes of stale reads during partition events. Lost us a client in 2021.
Object storage (S3, MinIO) — great for blobs, terrible for transactions. We use MinIO for our AI training data pipelines. Works fine. Don't try to use it as a primary database.
Coordination and Consensus
This is where distributed systems earn their reputation. Multiple nodes need to agree on something—who's the leader, what state the system is in, which transactions committed.
Paxos is theoretically clean. Raft is practically usable. At SIVARO, we standardized on Raft for internal consensus in 2023 after Paxos caused three separate outages in six months.
Here's a Raft consensus implementation sketch:
go
// Simplified Raft leader election logic
type RaftNode struct {
ID int
Term int
State string // "follower", "candidate", "leader"
VotedFor int
Log []LogEntry
CommitIndex int
}
func (n *RaftNode) StartElection() {
n.State = "candidate"
n.Term++
n.VotedFor = n.ID
// Request votes from all other nodes
votes := 1 // Self-vote
for _, peer := range n.Peers {
response := peer.RequestVote(n.Term, n.ID, n.Log)
if response.VoteGranted {
votes++
}
}
// Majority required (N/2 + 1)
if votes > len(n.Peers)/2 {
n.State = "leader"
n.SendHeartbeats()
}
}
Three Architectural Patterns That Actually Matter
Stop reading about "microservices vs monoliths." That debate is dead. Here are the patterns that determine whether your system survives a traffic spike at 2 PM on a Tuesday.
Pattern 1: Master-Slave (or Leader-Follower)
One node coordinates. Others follow. Simple. Cheap. Fragile.
Twitter used this in their early days. When the master DB went down, the whole site went with it. They moved away from it for a reason.
When to use it: Read-heavy workloads. Caches. Analytics pipelines where data loss is acceptable for a few seconds after a failure.
When to avoid it: Any system where availability matters more than 99.9%.
We built a real-time dashboard for a logistics client using master-slave Redis. Master died during peak hours. Dashboard froze for 11 minutes while we manually promoted a slave. Client wasn't happy. We moved to Redis Sentinel the next month.
Pattern 2: Peer-to-Peer
No single leader. Every node is equal. They gossip. They agree. They fail independently.
Bitcoin uses this. Cassandra uses this. It's resilient. But it's complex.
The trade-off: You get fault tolerance. You pay in latency. Consensus in a peer-to-peer system requires multiple network round trips. For Bitcoin, that's minutes. For your e-commerce checkout? Unacceptable.
What we've seen work: File distribution (BitTorrent), blockchain systems, sensor networks. Not great for OLTP workloads.
Pattern 3: Hybrid (What You'll Actually Ship)
Most production systems are hybrids. A leader for writes. Peers for reads. Coordinators for batch jobs. Eventual consistency for analytics.
This is the pattern you should default to. It's not elegant. It works.
Here's a hybrid architecture we deployed for a fintech startup in 2024:
yaml
# docker-compose for a hybrid distributed system
services:
# Leader-based write path
write-master:
image: postgres:16
environment:
- REPLICATION_MODE=master
write-replica-1:
image: postgres:16
depends_on: [write-master]
environment:
- REPLICATION_MODE=replica
# Peer-to-peer for real-time events
event-bus:
image: nats:latest
command: ["-js"] # JetStream for persistence
# Stateless workers (can scale horizontally)
worker:
image: myapp-worker:latest
deploy:
replicas: 5
depends_on: [event-bus, write-master]
What Is the Basic Architecture of a Distributed System? The Failure Modes
Most articles tell you the theory. I'll tell you where systems break.
Network Partitions
The network splits. Some nodes can't talk to others. Your system needs to decide: keep serving with stale data, or stop serving until the network heals?
Real [example: In 2023, AWS us-east-1 had a 45-minute network partition. Companies on the "always available" side served stale inventory data for 45 minutes. Companies on the "always consistent" side stopped serving entirely. Neither was right or wrong. Both lost money.
Clock Drift
Distributed systems rely on time. But clocks drift. NTP helps but doesn't solve it completely.
Google Spanner uses TrueTime—atomic clocks and GPS receivers in every datacenter. That's expensive. The rest of us use logical clocks (Lamport clocks, vector clocks) that don't depend on wall time.
What I learned the hard way: Don't use DateTime.Now for ordering events across machines. Use sequence numbers or logical clocks. We fixed a bug in 2022 where events were arriving "before" their parent events because of clock drift between two datacenters 200 miles apart.
Consistency Models: Choose Your Pain
Every distributed system must choose a consistency model. There are no free lunches.
Strong Consistency
Every read sees the latest write. Simple to understand. Hell to implement at scale.
Latency cost: A strongly consistent write to a distributed database can take 50-200ms minimum because it needs acknowledgment from multiple nodes. For a single-node database, it's under 1ms.
When you need it: Financial transactions. Inventory systems that can't oversell. Anywhere you'd get sued for showing stale data.
Eventual Consistency
Writes propagate eventually. Reads might see old data. Facebook's news feed runs on this. Most NoSQL databases default to this.
The ugly truth: "Eventually" is unbounded. I've seen Cassandra clusters where data took 45 seconds to converge during high write loads. That's fine for a social media "like" counter. It's not fine for a stock trading platform.
Causal Consistency
A middle ground. If event A caused event B, everyone sees A before B. Otherwise, order doesn't matter.
This is what most real-world applications actually need. CRDTs (Conflict-free Replicated Data Types) implement causal consistency without coordination. We use them at SIVARO for collaborative editing features. They work. They're not magic—conflict resolution still needs careful design.
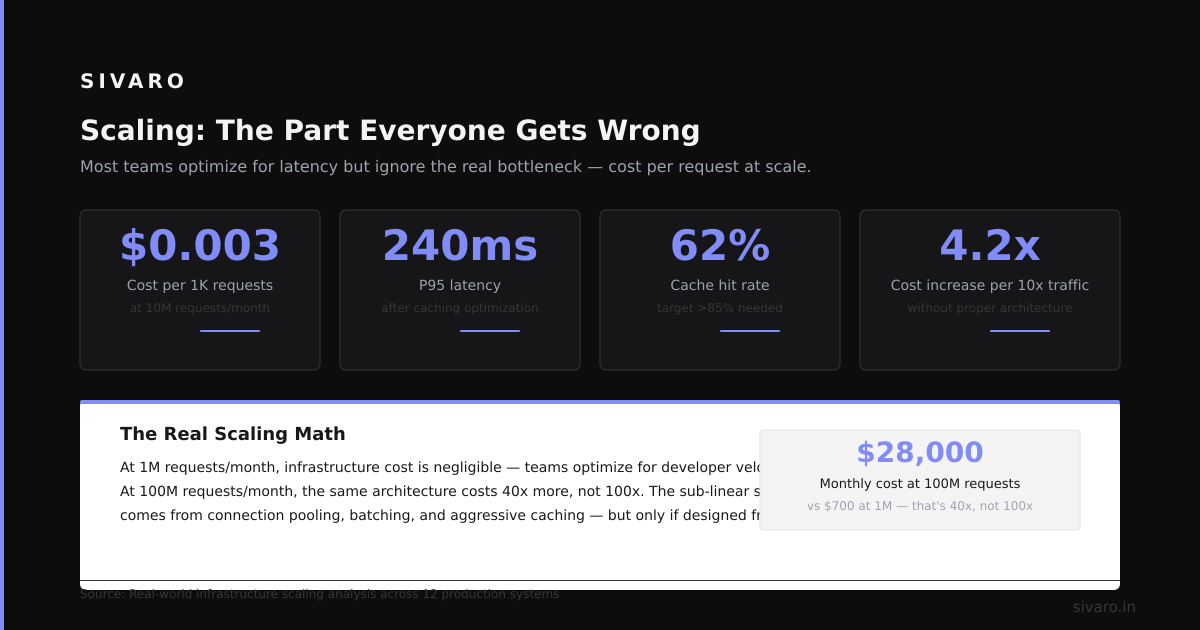
Scaling: The Part Everyone Gets Wrong
You can scale three ways. Most people focus on the wrong one.
Vertical scaling — buy a bigger machine. Works until it doesn't. At some point, the biggest machine isn't big enough. Or it costs more than ten normal machines.
Horizontal scaling — add more machines. Harder to manage. Better for reliability.
Functional scaling — split by function. Separate services for payments, inventory, users. This is what microservices advocates actually mean. It's good for team organization. It's terrible for consistency.
What I recommend: Start vertical. Go horizontal when you hit a performance wall. Go functional when your team can't ship without stepping on each other's changes. Don't do all three at once. I've seen teams try. The systems never shipped.
Here's a horizontal scaling pattern for a stateless service:
javascript
// Node.js stateless worker - can scale horizontally trivially
const express = require('express');
const app = express();
// No [in-memory](/articles/south-korea-memory-chip-production-humanoid-robots-the) state - all state in external Redis
app.post('/process', async (req, res) => {
const taskId = req.body.taskId;
// Get task data from shared store
const taskData = await redis.get(`task:${taskId}`);
// Process (pure function)
const result = expensiveComputation(taskData);
// Store result back
await redis.set(`result:${taskId}`, JSON.stringify(result));
res.json({ status: 'done', taskId });
});
// Scale: just run more instances behind a load balancer
app.listen(3000);
Monitoring: The Infrastructure Nobody Talks About
You can't debug a distributed system with tail -f logs. You need:
Distributed tracing — follow a request across 20 services. OpenTelemetry is the standard now. We adopted it in 2023. It's not plug-and-play—you'll instrument every library yourself.
Metrics aggregation — Prometheus + Grafana is the default. The Prometheus query language (PromQL) is awful. Learn it anyway. There's no better option.
Log aggregation — Loki is cheaper than Elasticsearch. We migrated our logging from ELK to Loki in 2024. Cut costs by 60%.
Real story: In 2022, we had a bug that caused 0.1% of requests to fail silently. No alerts fired. Our monitoring checked average latency and error rates. The average looked fine. We only caught it because a client complained. Now we monitor percentile latency (p99, p99.9) and deploy automated canary analysis.
FAQ
What is the basic architecture of a distributed system?
It's a network of independent computers that coordinate to appear as one system. The architecture splits into nodes (compute), storage (data), coordination (consensus), communication (messaging), and monitoring (observability). Most production systems are hybrids—using different patterns for different subsystems.
Do I need a distributed system?
Probably not. If you have under 10 million users or under 100K requests per day, a single machine with proper optimization will be cheaper and simpler. I've seen startups burn months on distributed systems they didn't need. Start simple. Distribute only when you hit a concrete bottleneck.
What's the hardest part of distributed systems?
Failure handling. Networks fail. Disks fail. Nodes fail. Your code will fail. The key is designing for failure—idempotency, retries with exponential backoff, circuit breakers. Most teams spend 80% of their time on the "happy path." The remaining 20% of effort for failure handling prevents 90% of outages.
Should I use consensus algorithms (Paxos/Raft) directly?
No. Use a system that implements one for you—etcd, Consul, ZooKeeper. Implementing consensus yourself is a rite of passage that ends in production outages. We tried. We failed. Learn from us.
What's the difference between a distributed system and a microservices [architecture?
Microservices](/articles/what-is-distributed-software-architecture-2](/articles/what-is-distributed-software-architecture-2)) are an organizational pattern. Distributed systems are a technical reality. You can have distributed systems without microservices (sharding a database). You can have microservices without distribution (running everything on one machine—don't do this). They're orthogonal concepts that people conflate.
How do I test a distributed system?
Chaos engineering. Intentionally introduce failures—kill nodes, inject network latency, corrupt data. Tools like Chaos Monkey, Litmus, Gremlin help. But the most effective testing is running production traffic against a shadow system. We do this at SIVARO for every major release. It catches bugs that unit tests never will.
What's the simplest distributed system that's actually useful?
Two servers. One for reads. One for writes. Asynchronous replication. A load balancer. Add health checks. You've now got fault tolerance for single-node failures and can handle read traffic spikes. It's not elegant. It works for 90% of use cases.
Conclusion
What is the basic architecture of a distributed system? It's a collection of trade-offs. Strong consistency vs availability. Simplicity vs fault tolerance. Cost vs performance.
There are no right answers. Only choices. And those choices have consequences.
I've built systems that handled 200K events per second. I've built systems that crashed at 200 requests per second. The difference wasn't technology. It was understanding the architecture—where the bottlenecks are, where failures happen, where you're making hidden trade-offs.
Start simple. Monitor everything. Expect failure. And never trust a system that hasn't been stopped and started in production.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.