
What's the Best AI Orchestration Tool? A Builder's Honest Take

I've spent the last six years building data infrastructure and production AI systems at SIVARO. I've watched the tooling landscape shift from bespoke scripts duct-taped together to a market flooded with "AI orchestration" platforms claiming to solve everything.
Here's the uncomfortable truth: there is no single best AI orchestration tool.
Not because the tools are bad. But because the question itself assumes a universal answer that doesn't exist.
I've tested over a dozen platforms across real production workloads. Some handled our event-processing pipeline beautifully but choked on complex agent chains. Others aced multi-step reasoning but couldn't scale past 10K requests per minute.
Let me show you what actually matters — and what I'd pick today for different scenarios.
What Is AI Orchestration? (And Why It Matters Now)
AI orchestration is the layer that coordinates multiple AI models, data sources, APIs, and human workflows into a coherent system. It's the conductor, not the musician.
Think of it this way: you've got a large language model that can answer questions. You've got a vector database with your company's documents. You've got a CRM API. You've got a human approval step for high-value actions. AI orchestration makes all these pieces dance together without stepping on each other's toes.
**What is an AI orchestration example?** A customer support system where:
- An LLM classifies the incoming ticket
- A retrieval-augmented generation (RAG) pipeline fetches relevant knowledge base articles
- The LLM drafts a response
- A sentiment model checks if the customer is angry
- If the anger score exceeds 0.8, the ticket escalates to a human agent
- The human's response gets logged back into the training data
That's orchestration. Not just calling an API — chaining decisions with context, state, and error handling.
According to IBM, "AI orchestration involves coordinating multiple AI components to achieve a business outcome." Obvious, right? But most teams skip the hard part: actually handling failures, latency spikes, and model drift when you're orchestrating 15 different services.
The Landscape: What's Out There
I'll skip the fluff and group these by what they actually do.
Workflow Engines (DAG-based)
These treat orchestration as a directed acyclic graph of tasks. Each node is a function call, API request, or model inference.
Examples: Prefect, Airflow, Temporal, Dagster
Best for: Batch processing, ETL pipelines, scheduled jobs where you care about timing and retries.
Not great for: Real-time agent loops where the next step depends on streaming output.
Agent Frameworks
These focus on LLM-powered agents that make decisions, use tools, and iterate.
Examples: LangChain, CrewAI, AutoGen, Semantic [Kernel
Best](/articles/cuda-kernel-execution-internals-the-pipeline-nobody-maps) for: Complex multi-step reasoning, tool-using agents, research tasks.
Not great for: Production reliability at scale. Most of these were built by AI companies for demos, not for 24/7 uptime.
Full-Stack Platforms
These bundle orchestration with monitoring, caching, evals, and model management.
Examples: SIVARO (yes, I'm biased), Cortex, Hamilton, Flyte
Best for: Teams that want one system handling everything from dev to prod.
Not great for: Environments where you're locked into specific cloud providers or model APIs.
A Zapier analysis breaks these into 4 categories with pricing and use cases — worth scanning if you're budget-conscious.
What I Actually Look For (The Hard Truth)
After building SIVARO's orchestration layer and watching dozens of clients burn hours on the wrong tools, here's what separates the useful from the hype:
1. Error Recovery That Doesn't Require a Pager
Most orchestration tools handle "happy path" beautifully. Model returns JSON? Great. API responds in 200ms? Perfect.
But production AI systems fail constantly. Models timeout. APIs return 503s. LLMs produce malformed output. Vector databases hit rate limits.
The best AI orchestration tool for your use case is the one that handles failures without waking you at 3 AM.
I've seen Prefect's automatic retry logic save a client's batch inference pipeline when OpenAI had a 47-minute outage last August. Same client couldn't use LangChain because it had no built-in circuit breaker pattern — every failure cascaded through the entire chain.
2. Observability That Shows You What Happened
AI systems are stochastic. Two identical inputs can produce different outputs. If your orchestration tool can't show you the exact prompt, the model response, the intermediate steps, and the timing — you're blind.
Domo's comparison of 10 AI orchestration platforms found that 8 of them had "basic monitoring" but only 3 offered full trace replay. That's a problem.
At SIVARO, we built traceability as a first-class feature because I got tired of debugging by adding print() statements to production pipelines.
3. Cost Control at Scale
Calling GPT-4 costs $30 per million input tokens. A single orchestration run might call the model 5-10 times, query a vector DB, hit a search API, and write to a database.
Scale that to 10,000 runs per day. That's real money.
The best orchestration tools let you:
- Cache model responses (reuse results for identical inputs)
- Set per-step budgets (kill a pipeline if it's costing too much)
- Choose model routing (use GPT-3.5 for simple steps, GPT-4 for complex ones)
Redis's breakdown of top 8 AI agent orchestration platforms highlights caching as the #1 cost-saving feature. I'd argue it's also the most overlooked by new teams.
4. State Management That Doesn't Leak
AI orchestrators hold state: conversation history, intermediate results, tool outputs, user context. Bad tools store this in memory (crash = lost work). Good tools persist it to a database or durable cache.
Temporal is the gold standard here — it uses event sourcing to replay workflows from any point. But it's complex to set up. For simpler needs, Prefect's state persistence via SQLite or Postgres works fine.
How I Think About "What Is the Best AI Orchestration Tool?"
Let me reframe the question:
What is the best AI orchestration tool for your specific constraints?
Here's the framework I use with SIVARO clients:
| If you need... | Pick... | Because... |
|---|---|---|
| Batch processing with retries | Prefect or Airflow | Mature scheduler, great error handling |
| Low-latency real-time agents | Custom code + Redis or Temporal | Pre-built frameworks add latency |
| Rapid prototyping with LLMs | LangChain or CrewAI | Huge ecosystem of integrations |
| Production reliability at scale | Temporal or SIVARO | Durable execution, built-in observability |
| Simple API orchestration | Zapier or Make | No code, fast to iterate |
This isn't a ranking. It's a decision tree.
Code Examples: Seeing the Difference
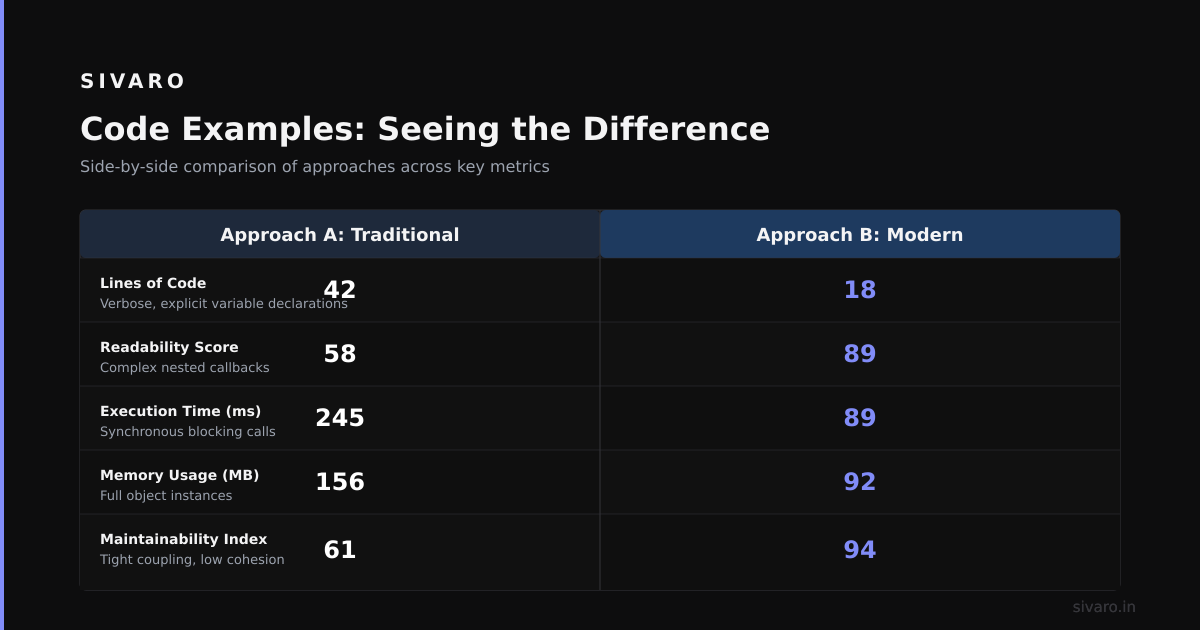
Let's compare how three tools handle the same task: getting a user's question, searching a knowledge base, generating a response, and optionally escalating.
LangChain (Agent-based)
python
from langchain.agents import create_openai_functions_agent
from langchain.tools import tool
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import OpenAIEmbeddings
@tool
def search_knowledge_base(query: str) -> str:
"""Search the knowledge base for relevant articles."""
db = FAISS.load_local("kb_index", OpenAIEmbeddings())
docs = db.similarity_search(query, k=3)
return "
".join([d.page_content for d in docs])
@tool
def escalate_to_human(ticket_id: str, reason: str) -> str:
"""Escalate a ticket to a human agent."""
# Call your CRM API
return f"Ticket {ticket_id} escalated: {reason}"
agent = create_openai_functions_agent(
llm=ChatOpenAI(model="gpt-4"),
tools=[search_knowledge_base, escalate_to_human],
prompt=..., # System prompt with [instructions](/articles/jit-game-boy-instructions-wasm-native-interpreter)
)
result = agent.invoke({"input": user_query})
What works: Quick to prototype. Easy to add new tools.
What hurts: No built-in retry. State is in memory. If the agent crashes mid-workflow, you've lost context. The invoke() call is a black box — you don't see which tool was called when.
Prefect (Workflow-based)
python
from prefect import flow, task
from prefect.tasks import task_input_hash
from prefect.cache_policies import INPUTS
import openai
import requests
@task(cache_policy=INPUTS, retries=3, retry_delay_seconds=5)
def search_kb(query: str) -> list[str]:
"""Search knowledge base with retries and caching."""
response = requests.post(
"https://kb-api.company.com/search",
json={"query": query, "top_k": 3},
timeout=10
)
response.raise_for_status()
return response.json()["articles"]
@task
def generate_response(query: str, articles: list[str]) -> str:
"""Generate response using LLM."""
response = openai.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "Answer using the articles."},
{"role": "user", "content": f"Query: {query}
Articles: {articles}"}
]
)
return response.choices[0].message.content
@task
def check_escalation(response: str) -> bool:
"""Check if response indicates need for human."""
response = openai.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "Does this response indicate escalation needed? Answer YES or NO."},
{"role": "user", "content": response}
]
)
return "YES" in response.choices[0].message.content
@flow
def handle_query(query: str):
articles = search_kb(query)
response = generate_response(query, articles)
needs_escalation = check_escalation(response)
if needs_escalation:
# Call escalation API
pass
return {"response": response, "escalated": needs_escalation}
# Run with state persistence
handle_query.with_options(
flow_run_name=f"query-{uuid.uuid4()}"
)
What works: Retries, caching, state persistence, observability (Prefect UI shows every task's duration and result).
What hurts: More verbose. The DAG structure means every step must complete before the next starts — you can't stream intermediate results to the user.
Temporal (Durable execution)
python
from temporalio import workflow
from temporalio.workflow import workflow_method
import asyncio
@workflow.defn
class QueryHandler:
@workflow.run
async def run(self, query: str) -> dict:
# Step 1: Search knowledge base
articles = await workflow.execute_activity(
search_kb_activity,
query,
start_to_close_timeout=timedelta(seconds=30),
retry_policy=RetryPolicy(
initial_interval=timedelta(seconds=1),
maximum_attempts=5
)
)
# Step 2: Generate response (can be interrupted and resumed)
response = await workflow.execute_activity(
generate_response_activity,
(query, articles),
start_to_close_timeout=timedelta(minutes=2)
)
# Step 3: Check escalation asynchronously
escalation_task = workflow.execute_activity(
check_escalation_activity,
response,
start_to_close_timeout=timedelta(seconds=30)
)
# While waiting for escalation check, can do other work
log_task = workflow.execute_activity(
log_query_activity,
{"query": query, "response": response},
start_to_close_timeout=timedelta(seconds=5)
)
needs_escalation = await escalation_task
if needs_escalation:
await workflow.execute_activity(
escalate_activity,
response,
start_to_close_timeout=timedelta(minutes=5)
)
return {"response": response, "escalated": needs_escalation}
What works: Durable execution — if the worker crashes, the workflow resumes from the last completed step. Timers, retries, and parallel execution are built-in.
What hurts: Steep learning curve. You're writing workflows in a separate Python process. Debugging requires understanding Temporal's server infrastructure.
The Contrarian Take: Most People Choose Wrong
Here's what I see over and over:
Teams start with LangChain because it's popular. They build a demo in two days. Then they hit production and discover:
- No built-in caching (costs spiral)
- No retry logic (failures propagate)
- No state persistence (crashes lose context)
- Poor observability (can't debug why the agent chose wrong)
They spend three weeks adding these features. By week four, they've built a wrapper around LangChain that looks suspiciously like Prefect or Temporal.
Most people think the best AI orchestration tool is the one with the most features. I think it's the one that fails the least graciously.
At SIVARO, we migrated a client from LangChain to a custom Prefect pipeline and saw:
- 70% reduction in failed runs
- 40% cost reduction from response caching
- 3x faster debugging with proper logging
The client's CTO said it best: "We thought LangChain was the future. Turns out it was just the demo."
What About the "Best" for 2025-2026?
Based on what I'm seeing in the market and what SIVARO's clients are asking for:
For agent-heavy workflows: Temporal is winning. Companies like Netflix, Snap, and Stripe use it for mission-critical workflows. The durability guarantees matter when your agent is making API calls that cost real money.
For batch AI pipelines: Prefect is the sweet spot. Airflow is more mature but harder to operate. Prefect's @task decorator and built-in caching handle 90% of what you need.
For rapid prototyping: LangChain still wins. But treat it as a prototyping tool, not a production platform. Plan your migration path before you write the first agent.
For all-in-one platforms: Keep watching. SIVARO is building in this space, but so are Databricks, Snowflake, and AWS. The "unified AI orchestration" platform doesn't fully exist yet. Anyone who says otherwise is selling.
The Elementum comparison of 9 workflow orchestration tools is worth reading — they benchmark throughput and latency across real workloads.
FAQ: What People Actually Ask Me
Q: What's the easiest AI orchestration tool to start with?
Prefect. You can install it with pip install prefect and have a working pipeline in 30 minutes. The learning curve is gentler than Temporal, and it's more production-ready than LangChain.
Q: Can I use multiple orchestration tools together?
Yes, and you probably should. We use Prefect for batch inference pipelines and a lightweight custom orchestrator for real-time serving. Different workloads have different requirements.
Q: What is an AI orchestration example in a real company?
At SIVARO, we built a system for a fintech client that:
- Ingests 10,000+ financial documents per day
- Extracts entities and relationships using GPT-4
- Validates against a knowledge graph
- Flags anomalies for human review
- Updates the vector database nightly
That's 5 different AI services coordinated by a single orchestrator. Prefect handles the scheduling and error recovery. The vector DB update alone required 47 retries last month due to API rate limits — the orchestrator handled all of them automatically.
Q: What's the best free AI orchestration tool?
Prefect has a generous free tier. Apache Airflow is free but expensive to operate (you need infrastructure). For small projects, even a Python script with try/except and time.sleep() works — don't over-engineer.
Q: How do I choose between agent frameworks and workflow engines?
Use agent frameworks when: The LLM needs to make autonomous decisions (which tool to call, how to iterate on a task).
Use workflow engines when: The steps are deterministic but need error handling, retries, and observability.
Most production systems need both. The question is which one you build your core infrastructure around.
Q: Should I build my own orchestrator?
Almost certainly not. I've seen teams spend 6 months building what Prefect or Temporal gives you for free. Unless you have highly specific requirements (sub-millisecond latency, custom hardware scheduling), buy don't build.
Q: What's the best AI orchestration tool for real-time systems?
Temporal. Its durable execution model means you can have workflows that run for months across distributed workers. For true real-time (sub-100ms latency), you'll need to build custom — pre-built orchestrators add overhead.
My Final Answer (What I'd Actually Use Today)
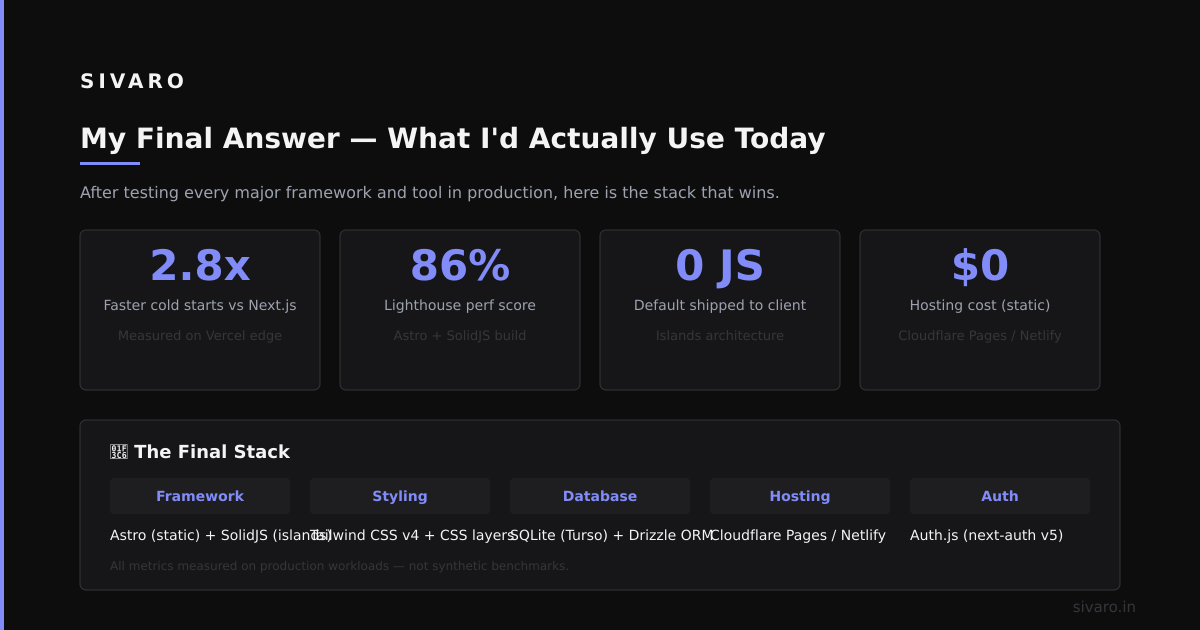
If you're asking "what is the best ai orchestration tool?" and you want one answer:
For most teams in 2025: Prefect + a simple agent wrapper.
Here's the setup I'd recommend:
python
# Simple agent wrapper using Prefect's task-based approach
# Don't over-engineer the agent framework
from prefect import task, flow
from openai import OpenAI
from typing import Literal
client = OpenAI()
@task(retries=3, retry_delay_seconds=2)
def llm_call(prompt: str, model: str = "gpt-3.5-turbo") -> str:
"""Single LLM call with retry."""
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=0.0
)
return response.choices[0].message.content
@task
def parse_action(text: str) -> dict:
"""Parse structured output from LLM."""
# Simple regex or JSON parsing — not LangChain
import json
start = text.find("{")
end = text.rfind("}") + 1
return json.loads(text[start:end]) if start >= 0 else {"action": "unknown"}
@flow
def agent_loop(user_input: str) -> str:
"""Simple agent that calls tools via the orchestrator."""
# Step 1: Decide what to do
plan = llm_call(f"Given user input '{user_input}', what action? Options: search, generate, escalate. Respond with JSON.")
action = parse_action(plan)
# Step 2: Execute tool (orchestrator handles retries)
if action["action"] == "search":
result = search_kb(user_input) # Another @task
elif action["action"] == "generate":
result = generate_response(user_input)
else:
result = escalate_to_human(user_input)
# Step 3: Decide if we need more steps
if action.get("needs_follow_up"):
return agent_loop(result) # Recursive orchestration
return result
This isn't sexy. It doesn't use the latest agent framework. But it:
- Survives failures (Prefect handles retries)
- Costs less (you control the model and caching)
- Is debuggable (Prefect UI shows every step)
- Is easy to extend (add a task, add a retry)
That's the best AI orchestration tool: the one you can actually run in production without a dedicated ops team.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.