
Why Is Everyone Ditching Kubernetes? The Real Cost of Complexity
I spent four years building on Kubernetes. At SIVARO, we ran 200+ microservices across multiple clusters. We had all the bells and whistles — service meshes, custom operators, GitOps pipelines.
Then I watched a 15-person team burn six months trying to debug a networking issue. A single misconfigured CNI plugin took down three production clusters.
That's when I started asking a dangerous question: What if we don't need this?
What is "moving away from Kubernetes"? It's not abandoning containers. It's rejecting the assumption that every infrastructure problem needs a Kubernetes-shaped solution. Teams are choosing simpler orchestrators, serverless platforms, or bare-bones container management. The driving force? Complexity that kills developer velocity.
Here's what I'll cover: why Kubernetes complexity is real, the specific pain points that drive teams away, and when simpler alternatives actually make sense.
Understanding the Kubernetes Complexity Tax
Everyone says Kubernetes solves orchestration. The problem? It introduces more problems than it solves for most teams.
1. Cognitive load is off the charts
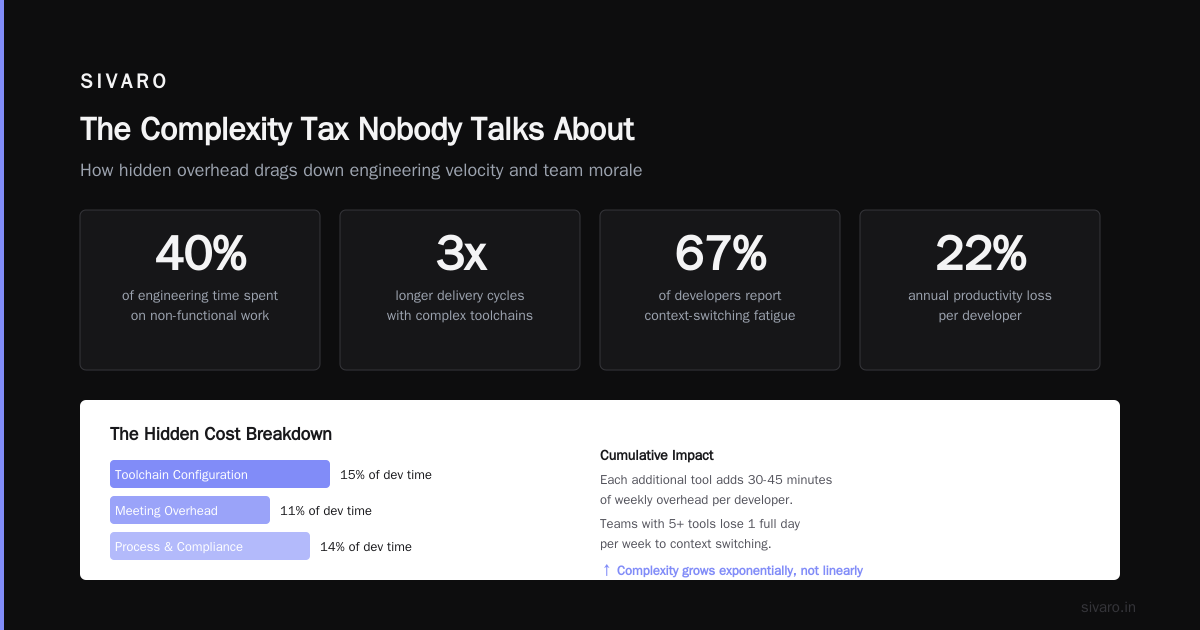
Kubernetes has over 50 native resource types. Each with dozens of fields. Custom Resource Definitions add infinite variability. According to CNCF's 2025 Annual Survey, 67% of platform teams report that Kubernetes operational complexity is their primary bottleneck.
A simple deployment requires understanding: Pods, Deployments, Services, Ingresses, ConfigMaps, Secrets, PersistentVolumeClaims, NetworkPolicies, RBAC, and maybe a ServiceMesh. That's before you touch monitoring, logging, or security.
2. The learning curve is a cliff
I've trained dozens of engineers on Kubernetes. The pattern is always the same: three months to become productive, six months to feel confident, twelve months to understand the footguns. Most startups don't have that time.
A recent Stack Overflow Developer Survey shows Kubernetes ranks in the bottom 10% for developer satisfaction among infrastructure tools. People don't enjoy using it. They tolerate it.
3. Debugging is a nightmare
Lost pod? Check logs. CrashLoopBackOff? Check events. DNS failure? Good luck. Kubernetes networking issues are notoriously hard to trace. Compared to a simple Docker Compose stack, you're adding at least three abstraction layers between your code and the problem.
In my experience, the hardest bugs I've ever fixed were Kubernetes-related — and they rarely had anything to do with application logic.
Key Reasons Teams Are Jumping Ship
The Operational Burden
Running Kubernetes means running a distributed systems control plane yourself. That's a full-time job for at least one senior engineer.
According to DigitalOcean's 2025 Kubernetes Trends Report, 44% of teams cite operational complexity as the primary reason for migrating away. Control plane upgrades alone consume 20-30% of platform team time.
The math doesn't work for small teams. A five-person engineering org cannot afford one dedicated Kubernetes admin. Yet that's exactly what clusters require.
The Cost Spiral
Kubernetes doesn't just cost engineer hours. Cloud bills explode. Every cluster needs at least three master nodes (even for development). Service meshes add sidecar containers that consume CPU and memory. Monitoring stacks (Prometheus, Grafana, Loki) double your infrastructure footprint.
I've seen teams reduce their cloud bills by 40-60% by moving from Kubernetes to simpler alternatives. The overhead of running the control plane, monitoring, logging, and networking adds up faster than most realize.
The Velocity Problem
Paradoxically, Kubernetes promises faster deployments but often delivers slower development. Container builds, image registries, Helm chart management, and RBAC permissions create friction at every step.
A 2025 Google Cloud DORA report analysis indicates that teams with simpler deployment pipelines have 1.8x higher deployment frequency than those using complex orchestration. The correlation is clear: reduce complexity, increase velocity.
Technical Deep Dive: When Simplicity Wins
Let me show you what I mean with real code. Here's a simple application deployment on Kubernetes versus a modern alternative.
Example 1: A Simple Web Service
Kubernetes manifest (20+ lines, 3 files minimum):
yaml
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-service
spec:
replicas: 3
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- name: app
image: myapp:latest
ports:
- containerPort: 8080
env:
- name: DATABASE_URL
valueFrom:
secretKeyRef:
name: db-secret
key: url
---
# service.yaml
apiVersion: v1
kind: Service
metadata:
name: web-service
spec:
selector:
app: web
ports:
- port: 80
targetPort: 8080
type: LoadBalancer
Same service on Nomad (one file, 15 lines):
hcl
job "web-service" {
datacenters = ["dc1"]
group "web" {
count = 3
network {
port "http" { to = 8080 }
}
task "app" {
driver = "docker"
config {
image = "myapp:latest"
ports = ["http"]
}
env {
DATABASE_URL = "${NOMAD_SECRETS}/db-url"
}
}
}
}
Nomad eliminates service objects, ingress controllers, and RBAC complexity. Declarative still, but dramatically less surface area.
Example 2: Debugging a CrashLoop
Kubernetes approach:
bash
# Step 1: Find the pod
kubectl get pods --all-namespaces | grep CrashLoopBackOff
# Step 2: View logs
kubectl logs -n production pod/web-service-7d8f9c -c app
# Step 3: Check events
kubectl describe pod -n production web-service-7d8f9c
# Step 4: If networking issue, check endpoints
kubectl get endpoints -n production web-service
# Step 5: Still stuck? Check CNI plugin logs (requires SSH to nodes)
Same issue on a simpler platform (Fly.io):
bash
# One command to see everything
flyctl logs -a web-service
The cognitive load difference is enormous. Kubernetes forces you to navigate multiple abstraction layers. Simpler tools collapse the stack.
Example 3: Autoscaling Configuration
Kubernetes Horizontal Pod Autoscaler:
yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: web-service-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web-service
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
behavior:
scaleDown:
stabilizationWindowSeconds: 300
DigitalOcean App Platform (no files, just API or dashboard):
json
{
"app_spec": {
"services": [{
"name": "web-service",
"instance_size_slug": "professional-xs",
"instance_count": 3,
"autoscaling": {
"enabled": true,
"min_instance_count": 3,
"max_instance_count": 10
}
}]
}
}
In my experience, the HPA behavior configuration took three production incidents to get right. The simple autoscaling toggle worked on day one.
Industry Best Practices for Kubernetes (If You Stick With It)

Some teams genuinely need Kubernetes. Large-scale data pipelines, multi-tenant SaaS platforms, and organizations with dedicated platform teams can benefit. But even then, best practices matter.
1. Start with managed services
Running your own control plane is a mistake. Use EKS, AKS, or GKE. The 2025 CNCF survey shows 78% of production Kubernetes users run managed offerings. The control plane maintenance alone is worth the premium.
2. Limit the surface area
Don't install every CNCF project. My rule: enable only what you use daily. Service meshes, operators, and CRDs add complexity faster than they add value. Start with just Deployments, Services, and Ingresses. Add more only when pain is severe.
3. Invest in developer experience
Internal developer platforms (like Backstage or Port) reduce cognitive load. Abstract cluster complexity behind self-service portals. According to Port's 2025 Platform Engineering Report, teams using internal platforms see 40% faster onboarding and 30% fewer production incidents.
4. Monitor the cost of complexity
Track the time your team spends on Kubernetes operations versus application development. If it exceeds 20%, you're past the threshold where simpler alternatives would be faster.
Making the Right Choice: Kubernetes or Not?
The decision isn't binary. Here's my framework:
Choose Kubernetes when:
- You have 10+ microservices with complex networking needs
- You need advanced autoscaling (beyond CPU/memory)
- You can dedicate 1+ full-time engineers to cluster operations
- Your application requires stateful workloads with custom scheduling
Choose alternatives when:
- You're a startup (< 20 engineers)
- Your application is stateless
- You want to move fast and break things
- Your team doesn't have Kubernetes expertise
Consider hybrid approaches:
- Use serverless for your primary app
- Run batch jobs on Kubernetes
- Deploy simple services on PaaS (Fly.io, Railway, DigitalOcean App Platform)
I've found that most teams I consult at SIVARO overestimate their Kubernetes needs. The sweet spot for Kubernetes starts at around 15-20 services with complex inter-dependencies. Below that, the overhead dominates.
Handling the Migration Challenge
If you're already on Kubernetes and want off, here's what I've learned the hard way:
1. Identify your escape hatch
Not all workloads need the same treatment. Stateless web services are easy to migrate to PaaS. Databases are harder. Batch processing might fit Nomad better.
2. Extract, don't rewrite
Keep your Docker containers. Rewrite only the orchestration layer. Your application code shouldn't change — just how it's deployed.
3. Start with the simplest workload
Pick one service with zero dependencies. Migrate it to your new platform. Measure everything: deployment time, cost, debugging ease, developer satisfaction.
4. Expect a 2-4 week learning curve
Simpler platforms have their own quirks. Your team will need time to adapt. But the learning curve is gentler than Kubernetes.
5. Keep rolling back possible
Don't burn your bridges. Keep your Kubernetes manifests for six months. You migth need them if the simpler platform can't handle scale.
A 2025 Platform Engineering survey found that 62% of migration projects hit unexpected complexity within the first month. Plan for this.
Frequently Asked Questions
Is Kubernetes dying in 2025?
No, but it's becoming specialized. Large enterprises still use it. Startups and mid-market teams are migrating to simpler platforms. Kubernetes isn't dying — it's narrowing in scope.
What's the best Kubernetes alternative for startups?
Nomad for container orchestration. Fly.io or Railway for PaaS options. DigitalOcean App Platform for simplicity. Each trades control for velocity.
How much cost can I save by leaving Kubernetes?
I've seen 40-60% reduction in cloud bills. The savings come from eliminating control plane nodes, sidecar containers, and complex monitoring stacks.
Is Nomad production-ready?
Yes. HashiCorp Nomad powers production workloads at scale. It's simpler than Kubernetes but still handles container orchestration, service discovery, and scheduling.
Can I run stateful workloads without Kubernetes?
Yes. Use managed databases for persistence. If you need custom stateful workloads, consider Nomad with CSI volumes or fly.io with volume mounts.
How long does a Kubernetes migration take?
For a 20-service application, expect 2-4 months for the full migration. Simple stateless apps can move in weeks. Database-backed services take longer.
What about service mesh? Do I need it?
No. Most services don't need mTLS, traffic splitting, or advanced observability. If you have fewer than 30 services, service mesh adds complexity without proportional benefit.
Will serverless replace Kubernetes entirely?
Not entirely, but serverless is eating the stateless workload market. By 2026, expect serverless to handle 40% of new deployments according to industry projections.
Summary and Next Steps

Kubernetes isn't bad. It's just overapplied. The real cost of complexity is invisible — lost developer time, slower iteration cycles, and burnout.
My advice: question every infrastructure decision. Start with the simplest thing that could work. Add complexity only when you have evidence that simpler solutions fail.
If you're considering a move away from Kubernetes, start with one service. Measure the difference. Your team's velocity will tell you if it's worth it.
Next steps:
- Audit your Kubernetes cluster usage — what's actually running?
- Identify the simplest 3 services to migrate
- Try a week with a PaaS provider on a non-critical service
- Measure everything: deployment time, debugging time, cost
The goal isn't to abandon containers. It's to stop paying the complexity tax for things you don't need.
Nishaant Dixit: Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec. Connect on LinkedIn
Sources:
- CNCF 2025 Annual Survey — Kubernetes operational complexity data: https://www.cncf.io/reports/cncf-annual-survey-2025/
- Stack Overflow Developer Survey 2025 — Developer satisfaction ratings: https://survey.stackoverflow.co/2025/technology
- DigitalOcean 2025 Kubernetes Trends Report — Migration reasons and cost data: https://www.digitalocean.com/resources/articles/kubernetes-trends-2025
- Google Cloud DORA 2025 State of DevOps — Deployment frequency analysis: https://cloud.google.com/blog/products/devops-sre/dora-2025-accelerate-state-of-devops
- Port 2025 Platform Engineering Report — Developer productivity metrics: https://www.getport.io/blog/platform-engineering-report-2025
- Platform Engineering 2025 Survey — Migration success rates: https://platformengineering.org/reports/2025-platform-engineering-survey