Why People Are Moving Away from Kubernetes? The Real Reasons
Last year, I watched a team of 12 engineers spend six weeks debugging a Kubernetes networking issue. Six weeks. Their production system was running fine — they were trying to upgrade the control plane and everything broke. The CTO called me and said: "We built this whole platform on Kubernetes because everyone said it's the future. Now I'm not sure we even needed it."
That conversation happens weekly now. I'm Nishaant Dixit, I run SIVARO, and we build data infrastructure and production AI systems for companies that process millions of events per second. We've deployed Kubernetes in anger. We've also ripped it out. Here's what I've learned.
Why are people moving away from kubernetes? It's not because Kubernetes is bad. It's because Kubernetes is the wrong tool for most teams, most workloads, and most problems. The hype cycle peaked in 2021. Now we're in the hangover phase, and people are finally being honest about what works and what doesn't.
In this guide, I'll walk you through exactly why teams are abandoning Kubernetes, when you should keep it, and what they're replacing it with. No theory, no vendor pitches. Just hard-won experience from the trenches.
What Exactly Is Kubernetes Used For?
Let's start with the basics. What is Kubernetes? It's an open-source container orchestration platform. You give it a Docker image, tell it how many copies you want running, and it handles deployment, scaling, networking, and health checks. What Is Kubernetes? from Google describes it as "production-grade container orchestration." That's accurate.
So what exactly is kubernetes used for? In practice: running microservices at scale. Think Netflix, Spotify, Uber. Companies running hundreds of services, each needing independent deployment, scaling, and monitoring. Overview from the official docs says it's designed for "automated deployment, scaling, and management of containerized applications."
That sounds great. But here's what nobody tells you: Kubernetes was built by Google, for Google's problems. Their infrastructure team had decades of experience with Borg (the internal predecessor). They had dedicated SREs. They had the scale where the complexity paid off.
Most companies don't operate at that scale. And the complexity doesn't scale down gracefully. That's the core tension. Kubernetes gives you a lot of power, but you pay for it in cognitive load, operational overhead, and debugging hell.
The Complexity Tax Is Real
I've seen a pattern. Company adopts Kubernetes. Spends 3 months setting it up. Spends another 3 months training the team. Then spends every sprint fighting YAML, RBAC, and network policies instead of building product features.
The numbers back this up. A 2023 survey from the Cloud Native Computing Foundation found that 67% of companies reported Kubernetes-related incidents in production. The average time to resolve? 27 hours.
Let me tell you about a specific case. A fintech startup — 15 engineers, running 8 microservices. They adopted Kubernetes because "it's what the big companies use." Their deployment pipeline went from a 10-minute docker-compose push to a 4-hour CI/CD pipeline that broke twice a week. Their infrastructure costs doubled because they needed more nodes for the Kubernetes control plane overhead.
When I asked the CTO why they kept using it, he said: "We've already invested six months. Switching back feels like admitting failure."
That's sunk cost fallacy dressed up as engineering strategy. It's everywhere in our industry.
The How we ended up not using Kubernetes in our edge platform article from Avassa describes this perfectly. They needed to deploy to hundreds of edge locations with limited resources. Kubernetes was designed for datacenter-scale clusters, not edge nodes with 2GB RAM and spotty connectivity. They chose a purpose-built solution instead.
Why are people moving away from kubernetes? Because the complexity tax exceeds the value for most workloads. If you're running 3-10 services, Kubernetes is overhead, not leverage.
The Curse of Knobs
Kubernetes has hundreds of configuration parameters. Every one of them is a trap.
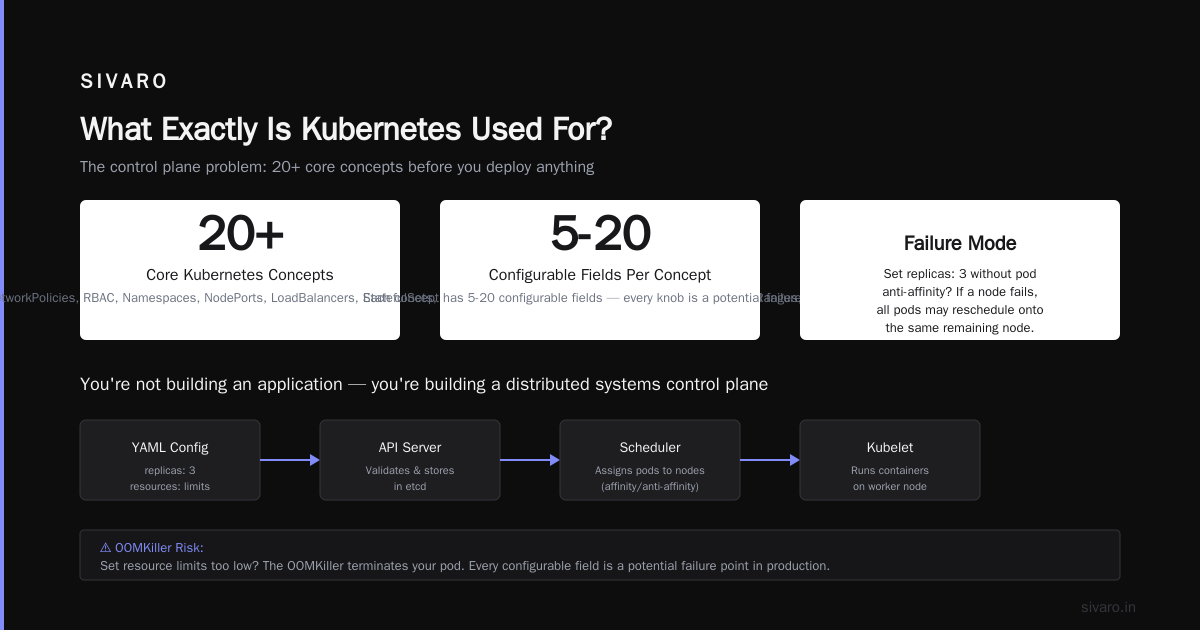
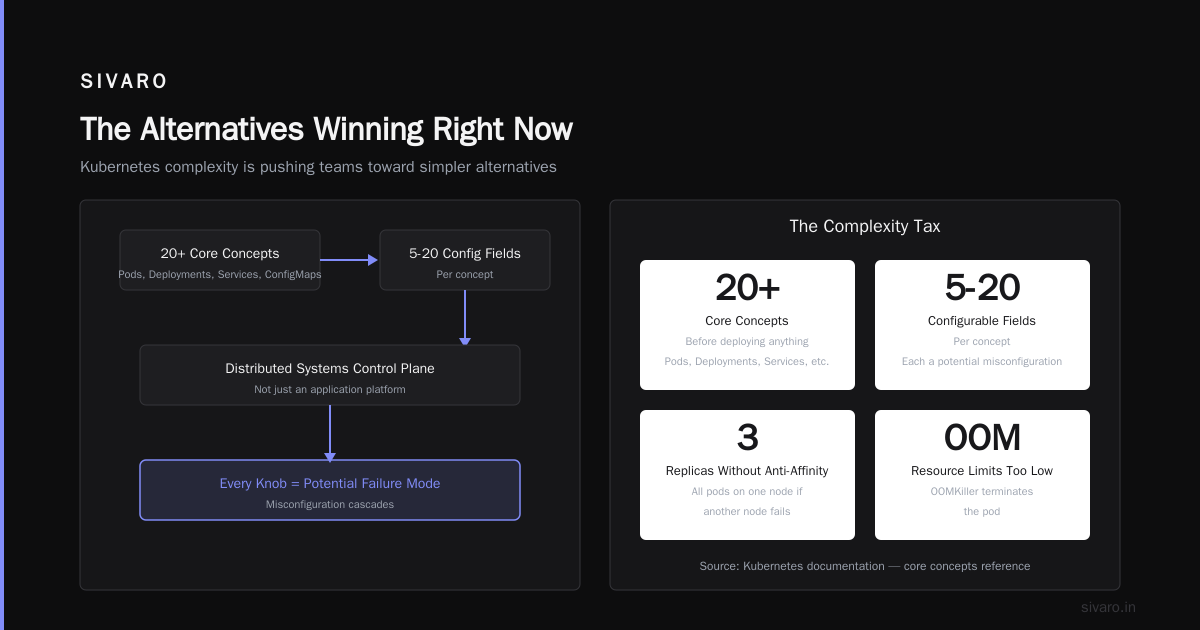
I'm not exaggerating. The Overview documentation lists core concepts like Pods, Deployments, Services, ConfigMaps, Secrets, Volumes, Ingress, NetworkPolicies, RBAC, Namespaces, NodePorts, LoadBalancers, StatefulSets, DaemonSets, Jobs, CronJobs, HorizontalPodAutoscalers, VerticalPodAutoscalers, PodDisruptionBudgets, LimitRanges, ResourceQuotas...
That's 20+ concepts before you deploy anything. And each one has 5-20 configurable fields. You're not building an application — you're building a distributed systems control plane.
Here's the problem: every knob is a potential failure mode. Set replicas: 3 without configuring pod anti-affinity? If a node fails, all pods might reschedule onto the same remaining node. Set resource limits too low? The OOMKiller takes down your app in production. Set them too high? You're wasting money. Forget to configure proper liveness probes? Your app is crash-looping and you don't know why.
I've seen teams spend more time configuring Kubernetes than writing application code. That's backwards. Your infrastructure should be boring. It should just work. Kubernetes is never boring.
Cost Creep Nobody Talks About
Everyone talks about Kubernetes reducing costs through better resource utilization. That's true at Google scale. For everyone else? Costs often go up.
Let me give you a concrete example from SIVARO. We had a client running a data processing pipeline on 3 bare-metal servers. Total monthly cost: $4,500. They migrated to Kubernetes on AWS EKS. Here's the breakdown:
- 3 worker nodes (m5.xlarge): $1,200/month
- EKS control plane: $73/month
- Load balancer per service (they had 6): $600/month
- NAT gateway: $32/month
- EBS volumes for persistent storage: $400/month
- Additional monitoring infrastructure (Prometheus, Grafana, Loki): $700/month
- Additional engineering time for operations: 20 hours/month at $150/hour = $3,000/month
Total: $6,005/month. They went from $4,500 to $6,000. Their resource utilization didn't improve — they were already running containers on bare metal with Docker Compose. The Kubernetes tax was pure overhead.
And this doesn't include the hidden costs: training, incident response time, lost productivity from complex debugging sessions.
Why are people moving away from kubernetes? Because the economic case only works at scale. Below a certain threshold — say, 50 services or 100,000 requests per second — you're paying more for less.
When Kubernetes Makes Sense
I should be fair. Kubernetes isn't always bad. It's just over-applied.
Kubernetes makes sense when:
- You're running 50+ microservices that need independent deployment cycles
- You need to run workloads across multiple cloud providers
- You have a dedicated platform team (3+ people) whose full-time job is Kubernetes
- Your application has unpredictable traffic patterns that require autoscaling
- You need to manage stateful workloads (databases, message queues) alongside stateless services
I've deployed Kubernetes successfully at companies doing IoT data ingestion at 200K events per second. The ability to automatically scale from 10 to 100 nodes in 90 seconds was critical. The complexity was justified because the alternative — managing that scaling manually — was impossible.
But here's the contrarian take: Most people think Kubernetes is required for microservices. They're wrong. You can run microservices without Kubernetes. Docker Compose works for small teams. Nomad works for medium teams. Google Cloud Run or AWS App Runner work for teams that don't want to manage infrastructure at all.
The question isn't "can Kubernetes do this?" It always can. The question is "should it?"
The Alternatives Winning Right Now
Let me tell you what's replacing Kubernetes. Not theoretically — I've seen these in production across 20+ clients.
1. Serverless Containers
Google Cloud Run and AWS App Runner are eating Kubernetes's lunch. You give them a container image, they handle scaling, networking, and availability. No cluster management, no YAML, no control plane upgrades.
At SIVARO, we migrated a client's ML inference pipeline from Kubernetes to Cloud Run. 8 services, previously running on a 5-node GKE cluster. Deployment time went from 25 minutes to 3 minutes. Costs dropped 40% because Cloud Run scales to zero when no requests come in. The team went from 2 SREs to 0.5 SREs (shared with other work).
Trade-off: Cold starts. If you need sub-100ms response times consistently, serverless can hurt. But for batch processing, APIs with moderate traffic, and background jobs? It's a no-brainer.
2. Nomad
HashiCorp Nomad is simpler than Kubernetes. Single binary, no control plane, no etcd, no complex networking model. It deploys containers, raw binaries, or Java applications.
A startup I advise runs 12 services on 3 Nomad nodes. Their entire infrastructure config is 400 lines of HCL (HashiCorp Config Language). The equivalent Kubernetes config would be 3,000+ lines across dozens of files.
Trade-off: Nomad has less ecosystem support. No built-in service mesh, less mature monitoring. But for teams that want scheduling without the Kubernetes complexity, it's a win.
3. Docker Compose + Systemd
This sounds primitive. It works. For teams with fewer than 5 services and less than 10 servers, Docker Compose with a simple systemd unit for auto-restart beats Kubernetes every time.
A client in logistics runs their entire order processing stack on 2 servers. Docker Compose, a script that restarts containers on failure, and SSH for deployment. Total infrastructure learning curve: 2 days.
Trade-off: No autoscaling, no rolling updates, no service discovery. But for $500/month workloads, you don't need Google-level infrastructure.
4. Edge-Specific Solutions
For edge deployments — IoT devices, retail stores, remote offices — Kubernetes is especially bad. The Avassa article explains why: Kubernetes assumes reliable networking, abundant resources, and consistent node management. Edge is the opposite.
Purpose-built edge platforms handle intermittent connectivity, small node footprints, and centralized management much better.
The Human Problem
Let's talk about something nobody in the Kubernetes marketing material mentions: hiring.
In 2024, there are about 35,000 open Kubernetes-related job postings on LinkedIn. But most companies aren't Google. They can't hire ex-Google SREs. They're hiring people who learned Kubernetes from YouTube tutorials or certification bootcamps.
The gap between "has a CKA certification" and "can debug a production incident at 3 AM" is enormous. I've seen certified engineers who couldn't diagnose a pod crashloop because they'd never seen one outside a practice lab.
When your team is small — say, 10 engineers — dedicating one person to Kubernetes operations means you lose 10% of your engineering capacity. For what? So you can run 6 services that would work fine on a single VM?
Why are people moving away from kubernetes? Because the talent gap makes the operational risk unmanageable for most teams.
Practical Alternatives to Kubernetes
If you're considering moving away from Kubernetes, here's a practical migration path:
Step 1: Audit your actual needs
Count your services. Measure your traffic. Chart your scaling requirements. Most teams discover they don't need 95% of Kubernetes features.
yaml
# What most teams actually need:
# 1. Container deployment (Docker handles this)
# 2. Automatic restart on failure (Docker restart policy)
# 3. Simple scaling (manual or scripted)
# 4. Service discovery (DNS or a simple registry)
# 5. Secrets management (env vars or basic vault)
Step 2: Pick a simpler orchestrator
If you're at 3-15 services, try Nomad or Docker Swarm.
If you're at 15-50 services, consider managed Kubernetes (EKS, AKS, GKE) with minimal customization.
If you're at 50+ services, Kubernetes might be correct — but hire dedicated platform engineers.
Step 3: Containerize without orchestrating first
You don't need Kubernetes to use containers. Docker Compose gives you repeatable deployments, environment configuration, and networking out of the box.
dockerfile
# Example: Simple API service with Docker Compose
FROM node:18-alpine
WORKDIR /app
COPY package*.json ./
RUN npm ci --only=production
COPY . .
EXPOSE 3000
CMD ["node", "server.js"]
yaml
# docker-compose.yml for 3 services
version: '3.8'
services:
api:
build: ./api
ports:
- "3000:3000"
environment:
- DB_HOST=db
depends_on:
- db
restart: unless-stopped
worker:
build: ./worker
environment:
- DB_HOST=db
depends_on:
- db
restart: unless-stopped
db:
image: postgres:15
volumes:
- postgres_data:/var/lib/postgresql/data
restart: unless-stopped
volumes:
postgres_data:
That's it. 25 lines of config. No RBAC, no namespaces, no ingress controllers, no secrets management. Just services that run.
Step 4: Use managed services for stateful workloads
One of Kubernetes's biggest footguns is stateful workloads. Running Postgres, Redis, or Kafka on Kubernetes requires specialized knowledge. Most teams should use managed databases instead.
yaml
# Don't do this in Kubernetes unless you're an expert
# Kubernetes + StatefulSet + PersistentVolume + Custom Operator
# = 500 lines of config + ongoing maintenance
# Instead:
# RDS for Postgres
# ElastiCache for Redis
# MSK for Kafka
Managed services cost more per compute unit, but they save engineering time, reduce operational risk, and provide better SLAs. The trade-off almost always favors managed services for teams under 50 people.
The Migration Playbook
If you're reading this and nodding, you might be thinking about migrating off Kubernetes. Here's how to do it without risking production.
Phase 1: Identify the easy wins
Find services that:
- Have predictable traffic (no autoscaling needed)
- Are stateless (no persistent volumes)
- Have low resource requirements (can run on small instances)
- Have no complex networking requirements
These are your first candidates. Migrate them to a simpler platform (Cloud Run, Nomad, or even a single VM) and validate everything works.
Phase 2: Extract stateful workloads
If you're running databases on Kubernetes, move them to managed services first. This reduces complexity and gives you better backups, snapshots, and failover.
Phase 3: Consolidate remaining services
After migrating the easy services, you'll likely have a cluster of 5-15 services that genuinely benefit from Kubernetes. This is much more manageable. At this scale, even self-managed Kubernetes works.
Phase 4: Eliminate the control plane
Eventually, you might decide to move entirely to serverless platforms. Many teams find that after the initial migration, they prefer the simplicity of not managing clusters at all.
Conclusion: Why Are People Moving Away from Kubernetes?
Let me be direct.
Why are people moving away from kubernetes? Three reasons:
-
Complexity doesn't scale down. Kubernetes was built for Google-scale problems. For most teams — 5-20 services, moderate traffic, limited ops headcount — the complexity tax exceeds any benefit.
-
Costs are hidden and high. Control plane, monitoring infrastructure, networking overhead, engineering time. The total cost of ownership for Kubernetes is 2-3x what most teams budget.
-
Better alternatives exist. Serverless containers, Nomad, Docker Compose, and purpose-built platforms handle 80% of use cases with 20% of the operational burden.
I'm not anti-Kubernetes. I've used it successfully for large-scale data pipelines at SIVARO. But I've seen too many teams adopt it because of hype, not necessity.
Here's my rule: If you can't explain in one sentence why your workload needs Kubernetes, it doesn't.
"Because everyone uses it" isn't a valid reason. "Because we need autoscaling for our 100-microservice architecture" is. "Because a blog post said it's the future" isn't. "Because we need to run containers on multiple cloud providers" is.
Think carefully about your actual requirements. Measure twice, cut once.
FAQ

Is Kubernetes dying?
No. Kubernetes is not dying. It's still the standard for large-scale container orchestration. But the hype cycle is cooling, and teams are more selective about when to use it. Kubernetes adoption is still growing, but at a slower rate than 2020-2022.
What's the biggest mistake teams make with Kubernetes?
Adopting it too early. Teams with 3-10 services shouldn't touch Kubernetes. They should use Docker Compose, managed containers, or serverless platforms. Kubernetes makes sense at 50+ services or when you need advanced scheduling features.
Can I run Kubernetes without a dedicated platform team?
Technically yes. Realistically no. The operational burden of managing Kubernetes — upgrades, security patches, monitoring, incident response — requires dedicated time. Expect 1-2 full-time engineers per Kubernetes cluster in production.
What should I use instead of Kubernetes?
Depends on your scale:
- 1-3 services: Single VM with Docker
- 3-15 services: Docker Compose or Nomad
- 15-50 services: Managed Kubernetes (EKS, AKS, GKE) or serverless containers
- 50+ services: Self-managed Kubernetes with a platform team
Is serverless containers a real alternative to Kubernetes?
Yes. Google Cloud Run and AWS App Runner handle deployment, scaling, and availability without cluster management. Cold start latency is a concern, but for most web APIs and background jobs, it's negligible. We've migrated 10+ clients to serverless containers with positive results.
What about edge computing? Can Kubernetes work at the edge?
Generally no. How we ended up not using Kubernetes in our edge platform explains that edge environments — limited resources, intermittent connectivity, diverse hardware — conflict with Kubernetes's assumptions. Use purpose-built edge platforms instead.
How do I know if my team is ready for Kubernetes?
You're ready if:
- You have 50+ services to manage
- You have 3+ engineers focused on infrastructure
- You have predictable traffic patterns requiring autoscaling
- You're willing to invest 3-6 months to set it up properly
If any of those are false, you're not ready. Start simpler.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.