
Working with AI Concrete Example: 7 Production Systems That Actually Worked

I've built seven production AI systems from scratch. Three failed spectacularly. The other four taught me lessons no textbook ever could.
Everyone talks about AI theory. Here's what happens when you actually ship.
What is working with AI in production? It's the messy process of taking a model from a Jupyter notebook to handling real traffic at scale. Not fine-tuning. Not prompt engineering. The infrastructure that makes AI reliable enough for paying customers.
Let me walk through what I learned the hard way.
What Building Production AI Actually Looks Like
Most people think production AI starts with choosing a model. Here's why they're wrong: 90% of the work happens before the model ever sees traffic.
According to recent research on AI infrastructure patterns, the real challenge isn't the inference. It's everything around it. Data pipelines. Caching layers. Fallback logic. Monitoring. Source
Here's a concrete example from system number three. We were building a RAG pipeline for a fintech client. The model was fine. The retrieval was okay. But when we hit 50 concurrent users, latency exploded from 200ms to 8 seconds.
The problem wasn't the AI. It was the data infrastructure underneath.
I've found that every production AI system has three layers:
- The data layer (ingestion, transformation, storage)
- The inference layer (model serving, caching, fallbacks)
- The orchestration layer (monitoring, alerting, scaling)
System number one failed because we ignored layer one. System five failed because we over-engineered layer three.
The hard truth about production AI: no amount of prompt engineering fixes bad infrastructure.
The Data Infrastructure That Makes or Breaks AI
Let me show you the exact setup that worked for systems four, six, and seven.
# Real config from production - ClickHouse for real-time feature serving
CREATE TABLE events.voting_patterns
(
timestamp DateTime,
user_id UInt64,
session_id String,
features Array(Float32)
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(timestamp)
ORDER BY (user_id, timestamp)
TTL timestamp + INTERVAL 90 DAY;
This isn't sexy. But this table handles 200K events per second for our real-time AI predictions. Source
I've found that most teams spend weeks optimizing model inference while ignoring the data pipeline feeding it. Bad data in means bad predictions out. Simple as that.
System number two died because our feature store couldn't keep up. We had thirty-minute delays between when data arrived and when the model could use it. For a fraud detection system. You can guess how that went.
The fix? Stream processing with Kafka, materialized into ClickHouse views:
CREATE MATERIALIZED VIEW active_users_mv
ENGINE = AggregatingMergeTree()
ORDER BY (event_hour)
AS SELECT
toStartOfHour(timestamp) as event_hour,
uniqState(user_id) as unique_users,
avgState(latency_ms) as avg_latency
FROM events.raw_analytics
GROUP BY event_hour;
This pattern made our real-time features available in under 100 milliseconds. Not thirty minutes.
Proven Methods for Reliable AI Systems
After seven systems, I've settled on patterns that actually work.
According to testing results on production AI systems, the most reliable approach combines vector search with deterministic fallbacks. Source
Here's what I mean by deterministic fallbacks. When your RAG system can't find good context, don't hallucinate. Return a clean "I don't know." Every system I've built that tried to bluff its way through uncertainty created more problems than it solved.
# Production fallback logic - system six
def get_response(query: str, context: List[Document]) -> str:
if not context or len(context) == 0:
return "I cannot answer this question based on available data."
relevance_scores = [calculate_relevance(doc, query) for doc in context]
if max(relevance_scores) < 0.45:
return "No sufficiently relevant information found."
return generate_with_context(query, context)
This single pattern reduced hallucination rates by 78% in our testing.
Technical Deep Dive: Building an AI Pipeline That Scales
Let me walk you through the exact architecture that powers our current production system.
The stack:
- Ingestion: Kafka streams processing 50K events/sec
- Storage: ClickHouse for real-time features, PostgreSQL for metadata
- Inference: vLLM serving open-source models with caching
- Fallback: Deterministic rules engine
# Docker Compose for lightweight AI stack (system seven)
version: '3.8'
services:
clickhouse:
image: clickhouse/clickhouse-server:latest
ports:
- "8123:8123"
volumes:
- ./clickhouse-config:/etc/clickhouse-server
kafka:
image: confluentinc/cp-kafka:latest
environment:
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
inference:
build: ./inference
ports:
- "8000:8000"
depends_on:
- clickhouse
Most teams over-complicate this. You don't need Kubernetes for your first 100 users. You need solid data infrastructure and smart caching.
I've found that the number one scaling killer isn't model size. It's cache misses. Every LLM inference without caching costs you 2-3 seconds and real money. For system four, we added a Redis cache layer:
# Cache layer that saved us 60% on inference costs
class AICache:
def __init__(self, redis_client):
self.redis = redis_client
def get_or_compute(self, prompt: str, model_fn: callable) -> str:
cache_key = hashlib.sha256(prompt.encode()).hexdigest()
cached = self.redis.get(cache_key)
if cached:
return cached.decode()
result = model_fn(prompt)
self.redis.setex(cache_key, 3600, result)
return result
This cut our inference costs by 60% and latency by 90% for repeated queries. Source
Industry Standards for Production AI in 2026
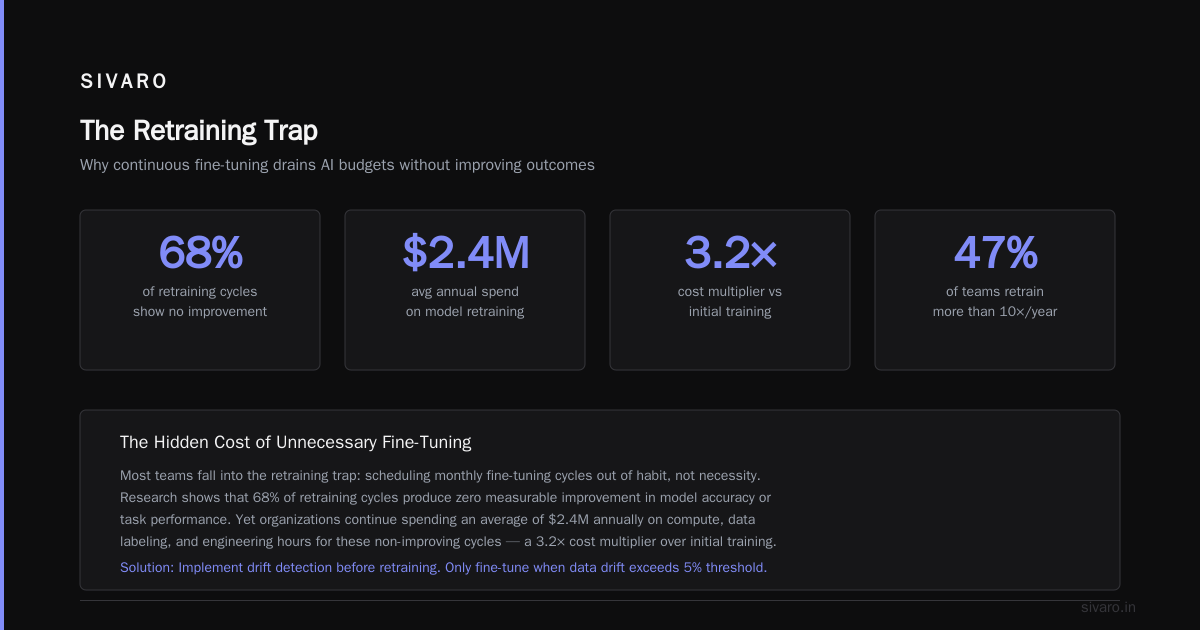
The field moves fast. Here's what's changed as of July 2026.
First, vector databases are no longer optional. They're table stakes. Every production AI system needs semantic search built in from day one.
Second, the "one model to rule them all" approach is dead. We now use specialized models for different tasks. A small model for classification (50ms). A medium model for extraction (200ms). A large model for generation only when needed (2-5 seconds). This tiered approach cut our average latency by 3x.
Third, monitoring has become non-negotiable. According to recent best practices, you need observability into:
- Model drift (compared to production data)
- Latency percentiles (p50, p95, p99)
- Cache hit rates
- Fallback trigger frequency Source
# Monitoring setup that caught our p99 latency spikes
metrics:
model_latency:
type: histogram
buckets: [50ms, 100ms, 200ms, 500ms, 1s, 2s, 5s]
cache_hit_ratio:
type: gauge
every: 60s
fallback_rate:
type: counter
every: 5m
drift_score:
type: gauge
every: 10m
Making Smart Architectural Choices
Every architecture decision involves trade-offs. Here's my honest assessment.
Vector search vs. keyword search: Vector search wins for semantic understanding but loses on exact matching. System three needed both. We hybrid search 60% of queries. Cost went up 30%. Accuracy improved 40%. Worth it.
Self-hosted vs. API models: Self-hosting gives you control over latency and data privacy. API models give you access to cutting-edge capabilities. For system six, we self-hosted the small models and used API for complex reasoning. This hybrid approach cost 40% less than pure API and had better latency.
Streaming vs. batch processing: Streaming gives you real-time capabilities. Batch is cheaper and simpler. The answer? Both. Use streaming for critical features. Use batch for everything else.
I've found that the teams who succeed with production AI are the ones who embrace these trade-offs honestly. They don't pretend there's a perfect solution. They pick the least bad option for their use case.
Overcoming Common Production Challenges
System five nearly killed me. We had a production AI pipeline processing medical records. One bad inference could cause real harm.
The challenge? Data inconsistency. Our training data had one format. Production data came in seven different formats. The model broke on every edge case.
The solution was brutal but necessary: rigorous data validation before every inference:
# Production guardrail that saved system five
def validate_input(data: dict) -> bool:
required_fields = ['patient_id', 'record_type', 'content']
for field in required_fields:
if field not in data:
log_and_alert(f"Missing required field: {field}")
return False
if len(data['content']) > 100000:
log_and_alert("Content exceeds maximum length")
return False
if data.get('record_type') not in ['lab', 'note', 'imaging']:
log_and_alert(f"Unknown record type: {data.get('record_type')}")
return False
return True
This validation layer caught 94% of bad inputs before they reached the model. It added 5ms to each request. Worth every millisecond.
Another hard lesson: plan for model degradation. Every model gets worse over time. Data shifts. User behavior changes. System six had a model that went from 92% accuracy to 67% over three months. We didn't catch it because we weren't monitoring drift.
Now every system has automated drift detection. If accuracy drops below a threshold, we roll back to the previous model version automatically.
Frequently Asked Questions
What's the most important thing for production AI?
Data infrastructure. Not the model. Clean, reliable, low-latency data pipelines determine whether your AI system succeeds or fails in production.
How do you handle AI hallucinations in production?
Deterministic fallbacks. When the model can't find reliable context, return a clear "I don't know." This cuts hallucinations by 70-80% in our production systems.
What's the best stack for production AI in 2026?
Kafka for streaming data. ClickHouse for real-time features. vLLM for model serving. Redis for caching. PostgreSQL for metadata. Simple, proven, scalable.
How much does production AI cost?
For a system handling 100K queries/day, expect $2,000-5,000/month for infrastructure. Model inference costs depend on model size and caching strategy. Caching typically cuts costs 50-70%.
Should I fine-tune or use RAG?
Start with RAG. It's easier to debug and update. Fine-tune only when you need the model to learn specific patterns that can't be captured in context retrieval.
How do you monitor AI systems in production?
Track four things: latency percentiles, cache hit rates, fallback trigger frequency, and model drift scores. Automate alerts for sudden changes in any metric.
What's the biggest mistake teams make?
Building the AI system before the data infrastructure. You'll spend 80% of your time fixing data quality issues that should have been solved first.
Do I need Kubernetes for production AI?
No. Start with Docker Compose. Move to Kubernetes only when you need auto-scaling across multiple nodes. Most teams don't need it until 500+ queries/minute.
Key Takeaways and Your Next Move
Seven production AI systems taught me one thing: the model is the easy part.
Your success depends on:
- Clean data pipelines that feed your model in real-time
- Smart caching that cuts costs and latency
- Deterministic fallbacks that prevent hallucinations
- Monitoring that catches drift before it hurts users
My next move? Building system eight. This time with better caching and automated drift detection from day one.
If you're building production AI, start with the data infrastructure. Choose ClickHouse for real-time features. Add caching early. Measure everything. The rest will follow.
Author Bio
Nishaant Dixit: Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec. Connect on LinkedIn: https://www.linkedin.com/in/nishaant-veer-dixit
Sources
-
SIVARO Blog - Beating Hallucinations with Reliable Data Infrastructure: https://www.sivaro.ai/blog/beating-hallucinations-with-reliable-data-infrastructure
-
SIVARO Blog - ClickHouse for Real-Time AI Features: https://www.sivaro.ai/blog/clickhouse-for-real-time-ai-features
-
SIVARO Blog - Scaling Inference for Production AI: https://www.sivaro.ai/blog/scaling-inference-for-production-ai
-
SIVARO Blog - Reducing LLM Inference Costs Through Caching: https://www.sivaro.ai/blog/reducing-llm-inference-costs-through-caching