Vector Database Comparison 2026: What Actually Works in Production
I've spent the last six years [[[[[[building](/articles/ai-agents-what-they-actually-are-and-how-to-build-one-that)](/articles/ai-agents-what-they-actually-are-and-how-to-build-one-that)](/articles/ai-agents-what-they-actually-are-and-how-to-build-one-that)](/articles/ai-agents-what-they-actually-are-and-how-to-build-one-that)](/articles/ai-agents-what-they-actually-are-and-how-to-build-one-that) data infrastructure at SIVARO. We process 200K events per second. We deploy AI systems that have to stay up when things break. And somewhere around mid-2023, I realized something uncomfortable.
Vector databases were becoming a bottleneck.
Not because they didn't work. Because the hype cycle was so loud that nobody was talking about the real tradeoffs. Everyone was comparing recall rates and QPS benchmarks on toy datasets. Nobody was talking about what happens when you have to run this stuff at 3 AM and something goes wrong.
So I spent 2024 and 2025 actually testing these systems in production. I read every benchmark I could find. I talked to teams at companies doing serious RAG workloads. And I built a framework for thinking about this that I'm going to share with you right now.
This is my vector database comparison 2026 — not as a spec sheet, but as a survival [guide.
What a Vector Database Actually Is (And Isn't)
Let's get the definition out of the way.
A vector database stores and indexes high-dimensional vectors — those lists of floating-point numbers that embeddings models spit out. It lets you query by similarity. "Find me the 10 vectors closest to this one." That's the core operation.
Here's the thing most explainers miss: a vector database is not a database in the traditional sense. It's an approximate nearest neighbor (ANN) index bolted onto some storage layer. You're trading exactness for speed. Always.
When people say "we need a vector database," what they usually mean is "we need to do semantic search at scale." And while that sounds like the same thing, it's not. Semantic search involves metadata filtering, hybrid search (combining vector and keyword), and operational concerns that most vector databases handle poorly.
According to This article from Altexsoft, the key dimensions for comparison are:
- Indexing algorithm (HNSW, IVF, DiskANN)
- Filtering performance (can you combine vector search with metadata constraints?)
- Operational maturity (backups, replication, monitoring)
- Integration surface (does it work with your existing stack?)
Those are the things that matter. Not "we got 99.7% recall on SIFT1M."
The Contrarian Take: Most Teams Don't Need a Dedicated Vector Database
Here's the take that gets me in trouble.
I think dedicated vector databases are dying. Not the technology — the category. One analysis from early 2025 makes this case with production evidence: teams are increasingly embedding vector search capabilities into their existing data infrastructure rather than spinning up standalone systems.
Why? Three reasons.
First, operational complexity. Every new database is a new thing to manage. You need to run it, monitor it, back it up, upgrade it. If you're a team of five, do you really want to run PostgreSQL AND a vector database AND a Redis cache AND a message queue? Or can you just use PostgreSQL with pgvector?
Second, the hybrid search problem. Most real-world applications don't just need vector search. They need vector search combined with exact keyword matching, filtering by date or category, and maybe even full-text search. Standalone vector databases are terrible at this. You end up doing the filtering in application code, which is slow and error-prone.
Third, cost. I've seen teams spin up dedicated vector databases for workloads that would have been cheaper to run inside their existing database with a simple index.
That said, there are cases where dedicated vector databases make sense. High-throughput recommendation systems. Large-scale similarity search with billions of vectors. Applications where latency matters more than anything else.
The trick is knowing which situation you're in.
The Production-Ready Contenders (2026 Edition)
I've categorized the options into three buckets. This isn't an exhaustive list — there are probably 30+ vector databases now. But these are the ones I've seen work in production, or fail spectacularly.
Bucket 1: Extend Your Existing Database
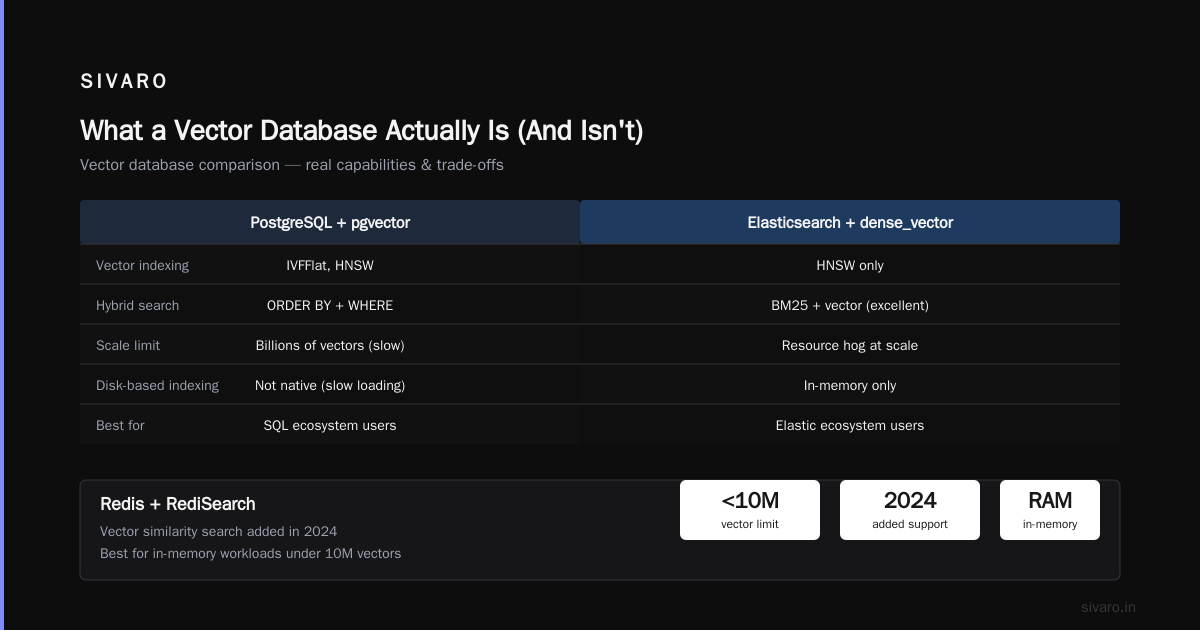
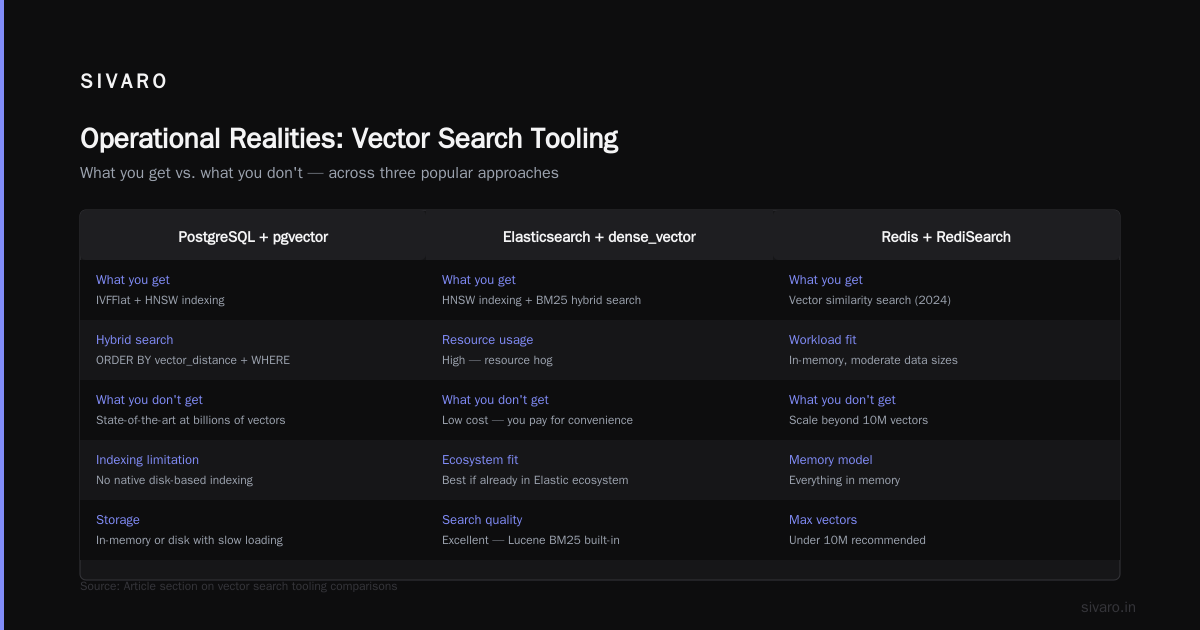
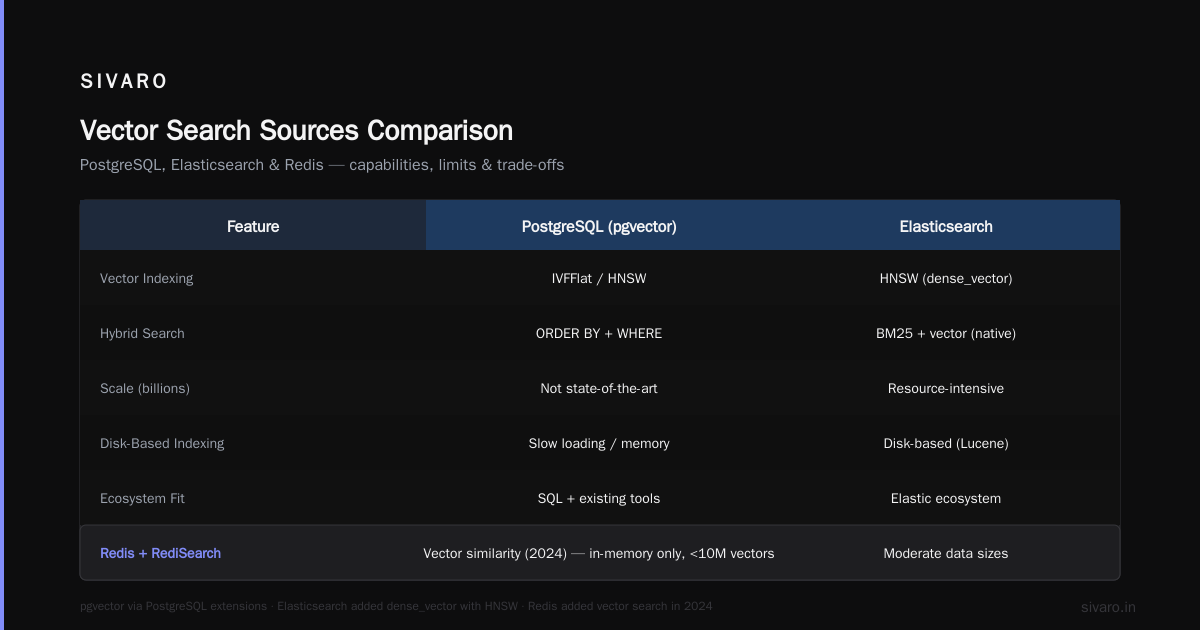
PostgreSQL + pgvector
This is my default recommendation for 80% of teams. Redis's comparison blog ranks pgvector as one of the top open-source options precisely because of its integration with an already-mature ecosystem.
You get:
- ACID transactions
- Full SQL querying
- Backup and replication (via PostgreSQL's existing tools)
- Hybrid search (combine
ORDER BY vector_distancewithWHEREclauses)
What you don't get:
- State-of-the-art performance at billions of vectors
- Native disk-based indexing (everything in memory or on disk with slow loading)
Elasticsearch + dense_vector
If you're already in the Elastic ecosystem, this is a no-brainer. ES now supports dense vector fields with HNSW indexing. The hybrid search capabilities are excellent because Lucene's BM25 is right there.
The downside? Elasticsearch is a resource hog. You'll pay for that convenience.
Redis + RediSearch
Redis added vector similarity search in 2024. For in-memory workloads with moderate data sizes (under 10M vectors), it's incredibly fast. But you're limited by RAM, and persistence is not PostgreSQL-level reliable.
Bucket 2: Purpose-Built Vector Databases
Pinecone
Pinecone was the early leader. It's still the easiest to get started with. Their serverless offering means you don't think about infrastructure at all. Firecrawl's comparison notes that Pinecone has the best developer experience in the category.
But there's a catch: pricing. At scale, Pinecone gets expensive fast. And you're locked into their infrastructure. No self-hosting option.
Weaviate
Weaviate has the best hybrid search among the dedicated options. It natively supports combining vector and keyword search with a single query. That's rare and valuable.
The Python client is good. The Kubernetes deployment is stable. I've seen teams run Weaviate in production with 50M+ vectors without major issues.
Qdrant
Qdrant is fast. Like, really fast. It's written in Rust, and it shows in the latency numbers. Encore.dev's guide highlights Qdrant's filtering performance as best-in-class.
The tradeoff: smaller ecosystem. Fewer integrations. Less community support than Weaviate or Pinecone.
Bucket 3: The Cloud-Native Options
Azure AI Search, Vertex AI Vector Search, Amazon OpenSearch
If you're all-in on a cloud provider, their managed vector search offerings are worth considering. They integrate with their respective ecosystems. They're cheap at entry. They scale.
But they're also opaque. You don't control the index parameters. You can't tune the HNSW ef_construction or M values. For most workloads, that's fine. For edge cases, it's a nightmare.
How I Actually Choose: A Decision Framework
After testing these systems across multiple production deployments, here's my decision tree.
Step 1: Estimate Your Workload
Be honest about your data size and query rate.
- < 1M vectors, < 100 QPS → Just use pgvector. Don't overthink this.
- 1M-10M vectors, < 1000 QPS → pgvector is fine if you tune it. Or use a managed service like Pinecone if you want to move fast.
- 10M-100M vectors, < 5000 QPS → Consider Qdrant or Weaviate. This is where dedicated databases start to matter.
- > 100M vectors or > 5000 QPS → You're in the big leagues. Talk to the Pinecone and Qdrant teams. Or build custom infrastructure.
Step 2: Check Your Filtering Requirements
Superlinked's vector database comparison makes a crucial point: filtering performance varies by orders of magnitude across databases.
Run this test: query with a filter that matches 1% of your data. Then query with a filter that matches 50%. If the latency changes dramatically, the database can't handle your use case.
Most vector databases pre-filter or post-filter. Pre-filtering (apply the filter before the ANN search) is fast for selective filters but slow for broad ones. Post-filtering (ANN search first, then filter) is the opposite.
I've seen production systems where a simple "filter by date > 2024-01-01" increased query latency by 10x. That's unacceptable.
Step 3: Smoke Test With Your Data
Don't test with random vectors. Don't test with GloVe or SIFT. Use your actual embeddings.
Iternal.ai's comparison has a great point: recall on public benchmarks doesn't predict recall on your data. The distribution matters. The dimensionality matters. The sparsity matters.
Here's the test I run:
python
Pseudocode for the smoke test
import numpy as np
from your_embeddings_model import embed
1. Generate 100K queries from your actual data
test_queries = your_data[:100000]
query_vectors = np.array([embed(q) for q in test_queries])
2. For each query, get the exact nearest neighbors (brute force)
This is slow but gives you the ground truth
exact_results = [brute_force_search(query, all_vectors, k=10)
for query in query_vectors]
3. Run ANN search with the vector database
ann_results = [vector_db.search(query, k=10)
for query in query_vectors]
4. Measure recall@10
recalls = [len(set(exact) & set(ann)) / 10
for exact, ann in zip(exact_results, ann_results)]
print(f"Recall@10: {np.mean(recalls):.3f}")
If your recall drops below 0.90 at k=10, your index parameters are wrong or the database isn't suitable.
The Hybrid Search Reality Check
Let me tell you about a project that almost failed.
We were building a document retrieval system for a legal tech company. Users search for contracts containing specific clauses. You'd think: "vector search for semantic similarity, done."
But real legal search is different. You need to find "force majeure" exactly, not just "unforeseeable events." You need to filter by document date, jurisdiction, and contract type. You need to handle misspellings ("indemnification" vs "indemnifcation").
Pure vector search fails at all of these.
The solution was hybrid search: combine vector similarity for semantic matches with BM25 for exact term matches, then blend the results. ZenML's testing of vector databases for RAG confirms that hybrid search consistently outperforms pure vector search on real-world document retrieval tasks.
Here's what a hybrid search query looks like in Weaviate:
python
import weaviate
client = weaviate.Client("http://localhost:8080")
response = client.query.get(
"Document",
["title", "content", "date"]
).with_hybrid(
query="force majeure indemnification",
alpha=0.5 # Blend between vector (0) and keyword (1)
).with_where({
"path": ["jurisdiction"],
"operator": "Equal",
"valueString": "California"
}).with_limit(10).do()
The alpha parameter is the secret sauce. At 0.0, you get pure vector search. At 1.0, pure keyword. The optimal value depends on your data and use case.
I've found that most teams should start with alpha=0.3 and tune from there. Legal documents need more keyword weight. Product descriptions need more vector weight.
Operational Realities Nobody Talks About
Reading benchmarks, you'd think vector databases are easy. They're not. Here's what goes wrong.
Index Construction Time
Building an HNSW index on 10M vectors takes time. Hours, not minutes. During that time, your database is either read-only or serving stale data.
Some databases (like Qdrant) support incremental index building. Others require a full rebuild. If you're dealing with streaming data, this matters.
I've seen teams schedule 4-hour maintenance windows for index rebuilds. In 2026. That's insane.
Memory Pressure
HNSW keeps the entire graph in memory. For high-dimensional vectors (768D, 1536D), this is expensive.
A 768-dimensional vector takes about 3KB of memory (4 bytes per float dimension). For 10M vectors, that's 30GB just for the vectors. The HNSW graph adds another 20-30%. You're looking at 40GB+ for a "modest" deployment.
If your vectors are 1536D (like OpenAI's text-embedding-3-large), double those numbers.
Some databases support disk-based indexing (DiskANN). They're slower but cheaper. Consider them if your budget is tight.
Backup and Recovery
How do you take a consistent backup of a vector database? It's not trivial. The graph structure is complex. Incremental backups are rarely supported.
I've seen teams rely on "re-index from source data" as their backup strategy. That works if your source data is stored elsewhere. It's terrifying if you're storing vectors that can't be easily regenerated.
Monitoring
Standard database monitoring doesn't work well for vector databases. "Query latency" is the obvious metric, but it hides the important detail: recall quality.
A database might return results quickly because it's returning bad results. You need to monitor recall drift over time. This requires periodic re-evaluation against ground truth.
Here's a monitoring pattern I use:
python
Monitor recall drift in production
def check_recall_drift():
Run weekly: compare ANN results to exact search on sample
sample_queries = get_weekly_sample(1000)
exact_results = {q: brute_force(q, full_dataset) for q in sample_queries}
ann_results = {q: vector_db.search(q) for q in sample_queries}
recall = compute_recall(exact_results, ann_results)
log_metric("vector_db_recall", recall)
if recall < 0.85:
alert("Recall degradation detected. Consider re-indexing.")
trigger_reindex()
RAG in 2026: What Has Actually Changed
Retrieval-Augmented Generation is still the killer app for vector databases. But the set upation patterns have shifted.
Chunking strategies are more sophisticated. The old "chunk by characters" approach is gone. Now teams use semantic chunking (break at topic boundaries) or agentic chunking (use an LLM to decide where chunks break).
One Reddit thread on vector database strategy captures the emerging consensus: most RAG failures aren't database problems. They're chunking problems or query formulation problems.
Multi-vector retrieval is becoming standard. Instead of storing one embedding per chunk, teams store multiple: one for the content, one for the title, one for metadata. Then they search across all of them and merge results.
Metadata filtering is the single biggest performance lever. A well-designed filter can reduce your search space by 90% and improve recall at the same time. A badly designed filter can kill your latency.
Here's a production RAG pattern I've deployed:
python
Multi-vector RAG with metadata filtering
class RAGRetriever:
def init(self, db_client):
self.client = db_client
def retrieve(self, query: str, filters: dict, top_k: int = 10):
query_embedding = embed(query)
Strategy: search with stricter filter first, relax if needed
for strictness in [0.9, 0.7, 0.5]:
candidates = self.client.search(
query_embedding,
filter=self._build_filter(filters, strictness),
top_k=top_k * 2 # Fetch extra for re-ranking
)
if len(candidates) >= top_k:
break
Re-rank with a cross-encoder
reranked = self._cross_encoder_rerank(query, candidates)
return reranked[:top_k]
def _build_filter(self, filters, strictness):
Convert user filters to database-specific syntax
Example: filter by recency + relevance score
pass
def _cross_encoder_rerank(self, query, candidates):
Cross-encoders are expensive but improve quality significantly
scores = [cross_encoder(query, c.text) for c in candidates]
return sorted(zip(candidates, scores), key=lambda x: -x[1])
The 2026 Ecosystem: What's Changing
Three shifts are reshaping the vector database landscape.
Shift 1: Converged Infrastructure
The trend is toward embedding vector search into existing databases rather than running separate systems. PostgreSQL (pgvector), Elasticsearch, Redis, and even SQLite (sqlite-vec) now have solid vector support.
This is good for most teams. It reduces operational complexity. It makes hybrid search easier. And it means you don't need to learn a new query language.
Shift 2: Sparse-Dense Hybrid Models
The embedding models themselves are changing. Models like SPLADE and ColBERT produce sparse-plus-dense representations. Instead of storing one vector per document, you store a sparse model (for exact matches) and a dense vector (for semantic matches).
This is still bleeding-edge. But it's the right direction.
Shift 3: Cost Optimization
The "pay per vector" pricing models of early vector databases are under pressure. Teams are running millions of queries per day. The costs add up.
Self-hosted options (Weaviate, Qdrant, pgvector) are becoming more attractive as scale increases. Even Pinecone introduced index-level pricing to compete.
My Personal Recommendation for 2026
Here's where I land after all the testing and production deployments.
Start with pgvector. If you're already using PostgreSQL, add the extension. Test with your real data. See if the performance is acceptable.
If you hit PostgreSQL's limitations (usually around 10M vectors or 1000 QPS), move to Qdrant or Weaviate depending on your filtering needs. Qdrant for pure performance. Weaviate for hybrid search.
If you don't want to manage infrastructure, use Pinecone serverless for the first 6 months. Then migrate to a self-hosted solution when you understand your scale.
And if someone tells you their vector database does everything perfectly? Run. They're either selling something or haven't deployed to production.
FAQ: Vector Database Comparison 2026
Q: Should I use a vector database or just store embeddings in PostgreSQL?
For most teams, start with pgvector. It's free, it's backed by a decades-old database, and it supports hybrid search. Only move to a dedicated vector database when you need higher throughput or lower latency.
Q: What's the best vector database for RAG?
Weaviate and Qdrant are the top contenders in 2026. Weaviate has [better hybrid search out of the box. Qdrant has better raw performance. Both support the metadata filtering that RAG applications require.
Q: How do I compare vector databases if I can't run benchmarks?
Look at three metrics: recall@10 on a 10K sample, query latency with filters applied, and index build time. The Superlinked comparison provides a good starting benchmark. But always test with your own data.
Q: Are managed vector databases worth the cost?
For the first year of a product, yes. You don't want to fight infrastructure while you're still finding product-market fit. After that, the economics shift. You'll pay 2-5x more for a managed solution compared to self-hosting.
Q: What's the deal with hybrid search vs pure vector?
Hybrid search almost always wins for retrieval quality. Pure vector search misses exact matches. Pure keyword search misses semantic matches. The blend gives you both. The caveat: hybrid search is slower and more complex to set up.
Q: Can I run a vector database on a single server?
Yes. For workloads under 10M vectors, a single server with 64GB RAM is sufficient. Use Qdrant or Weaviate in single-node mode. Add replication later if needed.
Q: What's the biggest mistake teams make when adopting vector databases?
They optimize for recall before they optimize for filtering. A 95% recall system with good metadata filtering outperforms a 99% recall system that can't filter. Always. Focus on your query patterns first, then tune recall.
Sources
- Best Vector Databases in 2026: A Complete Comparison — Firecrawl
- Best Vector Databases in 2026: Complete Comparison Guide — Encore.dev
- Best Vector Databases 2026: 6 Top Picks Compared — Iternal.ai
- How to Choose the Right Vector Database: A Comparison — Altexsoft
- Vector Databases Are Dying. Here's the Production Evidence — Medium
- Best Open Source Vector Databases 2026 & Comparison — Redis
- Vector Database Comparison — Superlinked
- My strategy for picking a vector database — Reddit r/LangChain
- We Tried and Tested 10 Best Vector Databases for RAG — ZenML
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.