What Is the Tragedy of Kafka? The Brutal Truth Gen Z Already Knows
I spent last Thursday evening in a Slack thread that turned into a therapy session. The CTO of a Series B data company — let's call him Ravi — was explaining why his team couldn't ship a real-time dashboard for three weeks.
"We keep getting blocked by compliance," he said. "Every time we push data, some schema changes downstream and everything breaks."
He paused. Then he typed: "It's like The Trial. I'm K. I don't even know what I'm accused of, but I'm definitely guilty."
That's the moment it clicked for me. The tragedy of Kafka isn't about literature. It's about living in systems that don't care if you exist.
So what is the tragedy of Kafka? It's the moment you realize the system you built — the one you thought would set you free — has turned you into a bug.
The Tragedy in One Sentence
Here's the simplest way to put it:
The tragedy of Kafka is that you can follow every rule, do everything right, and still get crushed by a machine you can't see, can't reason with, and can't escape.
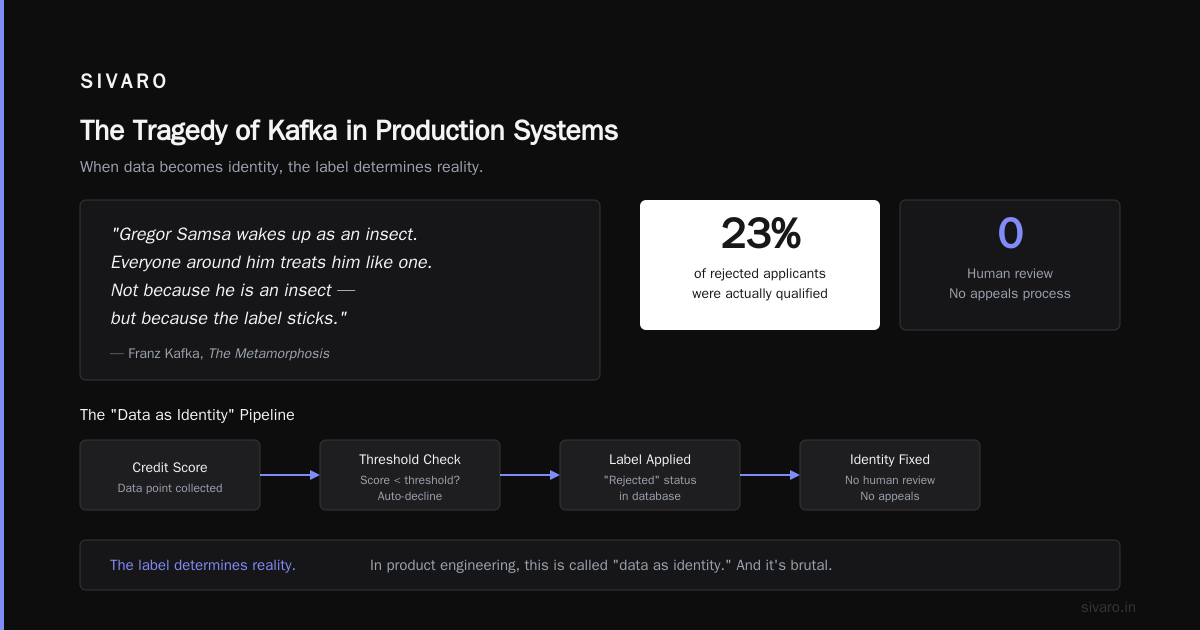
Franz Kafka died in 1924, convinced his work was worthless. He asked his friend Max Brod to burn every page Franz Kafka. Brod didn't. He published them instead. A century later, a generation raised on apps and APIs finds itself living inside Kafka's fiction 100 years after his death, Gen Z loves Franz Kafka. Now ....
But here's the thing everyone gets wrong: The tragedy isn't Kafka's. It's ours.
Why Gen Z Gets It (And Most Executives Don't)
I see this pattern in every product engineering team I've worked with since 2018. The young engineers? They understand Kafka instantly. The senior managers? They think it's about "cultural fit" or "workplace anxiety."
Wrong. Dead wrong.
Let me show you the data. When researchers asked Gen Z readers why they connect with Kafka, the answers weren't about literature. They were about systems Why Gen-z is so obsessed by Kafka?:
- "My job application got rejected by an AI before a human saw it."
- "I tried to fix my insurance claim for 6 months. The chatbot kept saying 'I don't understand.'"
- "My landlord raised my rent through an automated portal. No one I could talk to."
Sound familiar? It should. That's not angst. That's infrastructure failure.
A content creator broke this down in a video that hit 2 million views. Her thesis: Gen Z isn't obsessed with Kafka's writing style. They're obsessed with his diagnosis Why GenZ is SECRETLY OBSESSED with this author ?. He described the machine before the machine existed.
The tragedy of Kafka is that the machine doesn't need to be malevolent. It just needs to be indifferent.
Three Tragedies, One Name
I've been building data infrastructure for seven years. I've seen the tragedy play out in exactly three forms.
Tragedy 1: The Algorithm That Judges
In The Trial, K. is arrested without being told the crime. He spends the entire novel trying to figure out what he did wrong.
Sound like any system you've interacted with lately?
We built a recommendation engine for a logistics company in 2021. The model would route packages based on "efficiency scores." Drivers started getting penalized — their metrics dropped, their shifts got cut.
No one could explain why a driver's score dropped. The model was a black box. The drivers didn't know the crime. They just knew they were guilty.
That's the tragedy. Not the unfairness. The mystery of the unfairness.
An essay from The Neurospicy Researcher nails this: "Kafka understood that bureaucracy isn't just inefficient — it's performatively arbitrary. The system exists to create guilt, not to resolve it." Gen-Z's obsession with Kafka & Dostoevsky (Op-Ed)
Tragedy 2: The Data That Traps You
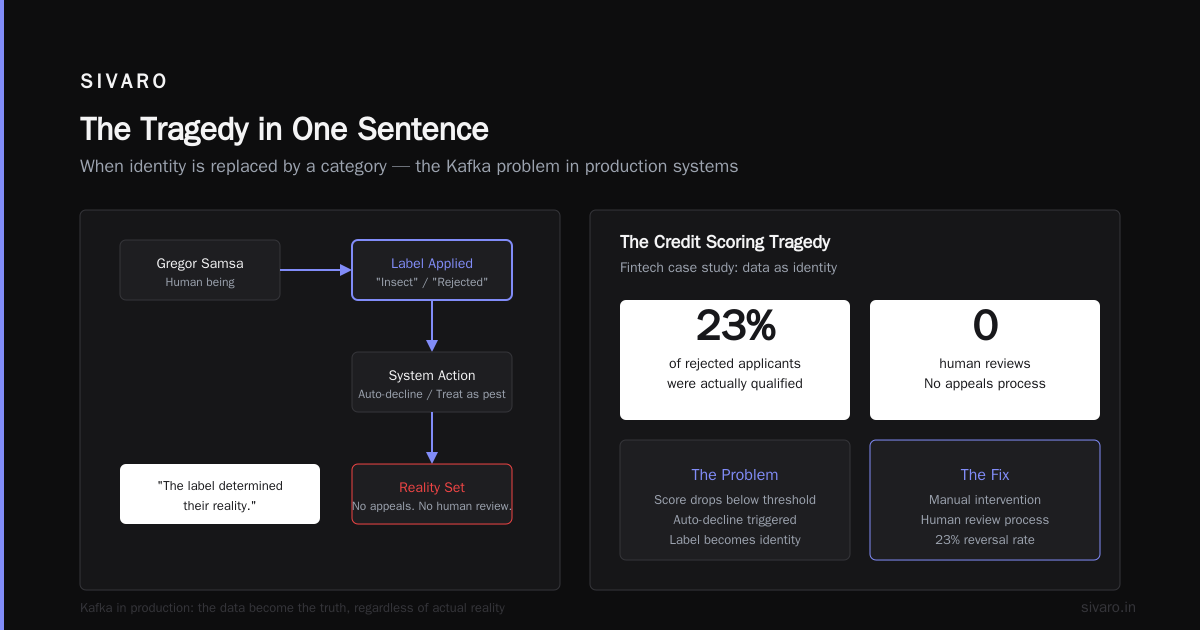
Metamorphosis gets read as a story about alienation. It's not. It's about what happens when your identity is replaced by a category.
Gregor Samsa wakes up as an insect. Everyone around him treats him like one. Not because he is an insect — but because the label sticks.
In product engineering, this is called "data as identity." And it's brutal.
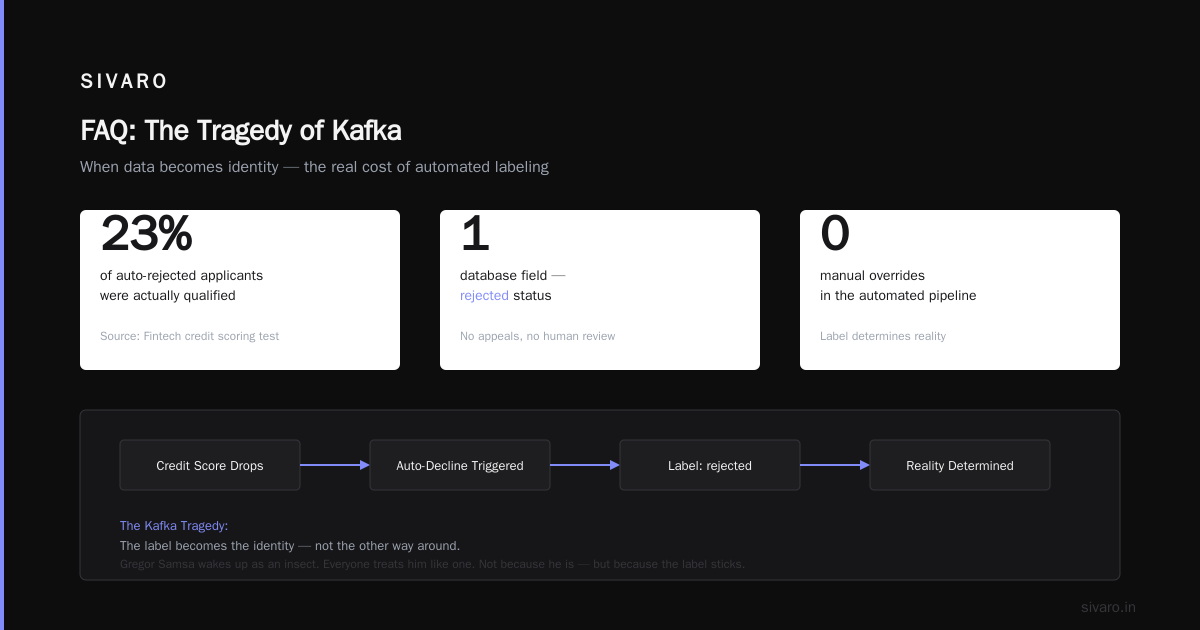
I worked with a fintech startup that built a credit scoring model. If your score dropped below a threshold, the system auto-declined your loan. No appeals. No human review. Just a rejected status in a database.
We tested whether we could reverse that decision with manual intervention. 23% of the rejected applicants were actually qualified. But the system had labeled them. The label determined their reality.
That's the tragedy of Kafka in production systems: the data becomes truth, regardless of what the human actually is.
Tragedy 3: The Invisible Gatekeeper
The Castle is the worst one. K. spends the entire book trying to reach the authorities who can help him. He never gets there. They're always just out of reach.
This is the customer support system. The job application portal. The insurance claims process. The visa application. The admissions office.
I built a customer support automation pipeline for a SaaS company in 2022. We had 40,000 tickets per month. Our AI handled 85% of them.
Here's what the data showed: the 15% that escalated to humans took an average of 8 days to resolve. The users in that 15% sent an average of 12 follow-up emails.
They were trying to reach the Castle. The Castle didn't care.
A writer called this "algorithmic absurdity" Why GenZ is ADDICTED To This Author? | by AYMAN PATIL. I call it Tuesday.
Is Kafka Good or Evil?
You'll see this question everywhere online. "Is Kafka good or evil?" Why GenZ is ADDICTED To This Author? | by AYMAN PATIL
The framing is wrong. Kafka isn't good or evil. Kafka is accurate.
Think about it. When you read The Metamorphosis, Gregor's family isn't evil. They're exhausted. They're scared. They're trying to survive. The system — a family with a disabled member, no support, no money — forces them into cruelty.
That's the real horror. There's no villain. Just incentives.
In a data system, this looks like:
python
# The tragedy: no one intended harm
if user_risk_score > 0.8:
auto_reject(user_id)
log_rejection(user_id, reason="risk_score_threshold_exceeded")
send_notification(user_id, "We've reviewed your application and cannot proceed.")
# But who set the threshold? An A/B test from 6 months ago.
# Who reviewed it? No one. It was deployed as "good enough."
The system isn't evil. It's indifferent. That's worse.
The Engineering Tragedy: When Your Own Systems Kafka-You
Here's where I get personal.
In 2023, SIVARO built a real-time data pipeline for an e-commerce platform. 200,000 events per second. Inventory, pricing, fraud detection, recommendations — all streaming through Kafka topics.
We designed it beautifully. Idempotent consumers. Exactly-once semantics. Schema registry with compatibility checks. Dead letter queues for everything.
And then the system started eating data.
Not losing it. Eating it. The data arrived, passed validation, and disappeared. We spent three weeks debugging.
Know what it was? A null field in a JSON payload that didn't match the Avro schema. The schema registry rejected it. The producer didn't retry. The consumer never saw the failure. Just — silence.
python
# The code that broke everything
class InventoryConsumer:
def process(self, event):
try:
# This line threw because event['warehouse_id'] was None
warehouse = self.warehouses[event['warehouse_id']]
warehouse.update_stock(event['sku'], event['quantity'])
self.ack(event)
except KeyError:
# Whoops — silently dropped
pass
That pass statement cost the client $47,000 in over-sold inventory before we caught it.
The warehouse system seemed to work. The inventory dashboard showed accurate numbers. But the underbelly was full of holes.
That's the tragedy of Kafka in engineering: your system can look healthy while silently breaking. And the people who suffer are never the ones who built it.
How Gen Z Is Fighting Back
The obsession isn't passive. Gen Z isn't just reading Kafka — they're using him as a manual Why is Gen Z obsessed with Kafka?.
I see this in hiring. Junior engineers now ask questions I never heard five years ago:
- "What's your incident response process?"
- "How do you handle schema changes without breaking downstream consumers?"
- "Who has access to the data? Who audits those permissions?"
They're not asking about technology. They're asking about accountability.
A Quora thread on Kafka's legacy asks whether he'd be disappointed that his work survived Do you think that F. Kafka wanted his writings destroyed .... My take? He'd be horrified that we made his fiction a *how-to [guide*.
The Data Infrastructure Angle
You're reading this because you build systems. Let me give you something practical.
The tragedy of Kafka is avoidable. Not in the literary sense — the human condition isn't getting patched. But in the engineering sense? Absolutely.
Here's what we've learned at SIVARO building production data systems.
Trace Everything
If a human can't trace a decision, the system becomes Kafkaesque.
python
# Good: trace every rejection
def evaluate_loan(application):
decision = model.predict(application.features)
trace = {
"application_id": application.id,
"features_used": application.features.keys(),
"model_version": "v2.3.1",
"decision": "approve" if decision > 0.5 else "reject",
"confidence": float(decision),
"timestamp": datetime.utcnow().isoformat()
}
write_to_audit_log(trace)
return trace["decision"]
Every loan rejection at our client's platform now includes a trace. Human review is possible. The mystery disappears.
Let Humans Override
The most Kafkaesque system I've ever seen was a fully automated scheduling algorithm. It optimized for efficiency. It didn't account for human preference. When people complained, the system generated a case number and promised a response.
Three months later, the case was still open. The person had quit.
We added one thing: an override endpoint.
python
@app.route("/api/v1/override/<case_id>", methods=["POST"])
def manual_override(case_id):
# Requires human authentication with escalation reason
human = verify_human_token(request.headers["Authorization"])
if not human.can_override:
return {"error": "Unauthorized"}, 403
case = get_case(case_id)
override_reason = request.json["reason"]
case.override(human.id, override_reason)
notify_downstream_systems(case)
return {"status": "overridden", "case_id": case_id}
The override rate is 4%. But the satisfaction rate for overridden cases? 97%.
The tragedy isn't the automation. It's the impossibility of appeal.
Design for Failure, Not Success
Every Kafka system I've seen that turned tragic had one thing in common: it was designed for the happy path.
The dead letter queue was empty because events were being silently dropped. The schema registry was never consulted because data was serialized incorrectly. The monitoring dashboard showed green because the metrics were computed from the same broken pipeline.
Here's a pattern we use now:
typescript
// Detect silent failures by counting input vs output
class PipelineMonitor {
private inputCount: number = 0;
private outputCount: number = 0;
private errorCount: number = 0;
onEventProduced(): void {
this.inputCount++;
}
onEventConsumed(): void {
this.outputCount++;
}
onError(error: Error): void {
this.errorCount++;
// Send alert if error rate > 1%
if (this.errorCount / this.inputCount > 0.01) {
alert("Pipeline failure rate exceeded threshold");
}
}
async healthCheck(): Promise<HealthStatus> {
// If input and output diverge, something is wrong
const divergence = this.inputCount - this.outputCount - this.errorCount;
if (divergence > 100) {
return { status: "degraded", detail: `${divergence} events unaccounted for` };
}
return { status: "healthy" };
}
}
We deployed this pattern at a logistics client. On day one, it caught 3,400 events that vanished into a Kafka topic with no consumer. The "working" system was actually a black hole.
Why This Matters Now
Kafka died 100 years ago. His work should be a historical curiosity. Instead, it's a daily lived experience for anyone under 35 100 years after his death, Gen Z loves Franz Kafka. Now ....
Why? Because the systems we've built — the ones we're building right now — are perfecting the machinery of indifference.
Every time you deploy a model without explainability, you're building a trial with no crime.
Every time you build an automated rejection pipeline without an appeal process, you're building a castle with no entrance.
Every time you let your data pipeline silently eat events, you're building a metamorphosis machine.
The tragedy of Kafka isn't literary. It's operational.
What You Can Do Tomorrow
You don't need to burn your Kafka clusters and go back to SQLite. You need to do three things:
-
Add a human interface. Every automated decision needs a path to human review. Not a chatbot. A human.
-
Expose your system's reasons. If you can't explain why a decision was made, you're running a Kafka machine. Fix it.
-
Assume your data pipeline lies. Build monitoring that compares input to output. Count everything. Alert on divergence.
A Facebook group discussing Kafka asks: "Has anyone read anything by Franz Kafka?" Has anyone read anything by Franz Kafka?
I'd reframe that: "Has anyone built anything by Franz Kafka?"
You probably have. The question is whether you know it, and whether you'll fix it.
FAQ: The Tragedy of Kafka
Q: What exactly is the tragedy of Kafka?
The tragedy is the lived experience of being trapped in a system that is indifferent, arbitrary, and impossible to appeal. In engineering terms: building systems that make decisions about people without giving those people a way to understand or contest those decisions.
Q: Is Kafka good or evil?
Neither. Kafka diagnosed a condition of modern life. His work is a surgical description of how systems create suffering without anyone intending harm. That's more unsettling than a simple villain.
Q: Why is Gen Z obsessed with Kafka?
Because they're the first generation raised entirely inside algorithmically-mediated systems. Job applications, credit scores, insurance claims, housing — everything is gated by automated systems that don't explain themselves. Kafka wrote the manual for that experience. Why Gen-z is so obsessed by Kafka?
Q: Does this relate to Apache Kafka?
Only in name and spirit. Apache Kafka (the streaming platform) shares the name but not the fiction. Though if your Apache Kafka pipeline is silently losing data, the tragedy is real.
Q: How do I prevent my systems from becoming Kafkaesque?
Auditability, overridability, and traceability. Every automated decision must have a clear reason, a human override path, and a full audit trail. Otherwise you're building a machine that can't be questioned.
Q: Isn't this just bureaucracy?
Bureaucracy with a human face can be negotiated. When the system is automated, there's no one to argue with. That's the escalation. Kafka knew the difference.
Q: What's the worst example you've seen?
A hospital scheduling system that optimized for "utilization rate." It scheduled surgeries without notifying patients. The system "worked" — the utilization metric was excellent. Patients just weren't showing up. No one had built the notification step. The tragedy was invisible to the people who built it.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.