What Exactly Does AWS Do? The Engineer's Guide to Cloud Infrastructure
Most people think AWS is just servers in the cloud. They're wrong.
I've spent years building data infrastructure and production AI systems. In 2018, I founded SIVARO specifically to help companies untangle their cloud deployments. And the question I hear most often is "what exactly does AWS do?" It sounds simple. It's not.
Here's the truth: AWS is a coordination problem dressed up as a technology platform.
At its core, AWS gives you three things: compute, storage, and networking. That's it. Everything else — the 200+ services they advertise — is just those three primitives wrapped in different configurations. S3 is storage with a REST API. Lambda is compute with a timer. VPC is networking with rules.
But that stripped-down answer misses the point. Because what AWS actually does is turn capital expenditure into operational expenditure. Instead of buying servers, you rent them. Instead of guessing capacity, you scale. Instead of hiring a team to rack hardware, you click buttons.
I've seen companies burn $2M/month on AWS because they didn't understand what exactly AWS does. And I've seen startups scale from zero to 100K users on $500/month because they did.
Let me break it down for real.
The Three Primitives (Everything Else Is Lipstick)
AWS runs on three core services. Every other service is just a decoration on these:
EC2 — virtual machines. You get a slice of someone else's computer. Pricing is per-second. You can spin one up in 30 seconds. I've provisioned 500 in five minutes for a load test at a fintech client in 2021. It worked. Then we forgot to turn them off and got a $14K bill. That's on us, not AWS.
S3 — object storage. Unlimited. 99.999999999% durability (they guarantee 11 nines). You pay per GB stored and per request made. Simple. Brutal. Effective.
VPC — networking. Your own slice of the internet. Subnets, route tables, NAT gateways, security groups. This is where most people screw up. A misconfigured security group is how that Capital One breach happened in 2019. Don't be that person.
Everything else? RDS is EC2 running a database engine. CloudFront is S3 with caching. Lambda is EC2 with no management — you just upload code and AWS runs it.
When someone asks "what exactly does AWS do?" the honest answer is: AWS abstracts the hardware so you can pretend hardware doesn't matter. Until it does.
Compute: Where Most People Waste Money
I'll say it directly: most companies overprovision compute by 40%.
In 2022, I audited a Series B startup's AWS bill. They were running 200 EC2 instances at 15% CPU utilization. They could have cut to 50 instances with proper auto-scaling and vertical sizing. That's $120K/year burned.
AWS compute options are straightforward:
- On-demand — pay per hour. No commitment. Worst for predictable workloads. Best for experiments.
- Reserved — commit 1-3 years, get 40-72% discount. If you're running a production database 24/7, this is the move.
- Spot — bid for unused capacity. Up to 90% off. But AWS can reclaim the instance with 2 minutes notice. Great for batch jobs, terrible for user-facing sites.
- Savings Plans — commit to a dollar amount per hour. More flexible than reserved. [Better for variable workloads.
Here's a pattern we use at SIVARO for production AI workloads:
python
# Simple auto-scaling policy for inference workloads
import boto3
client = boto3.client('autoscaling')
response = client.put_scaling_policy(
AutoScalingGroupName='inference-asg',
PolicyName='cpu-target-tracking',
PolicyType='TargetTrackingScaling',
TargetTrackingConfiguration={
'PredefinedMetricSpecification': {
'PredefinedMetricType': 'ASGAverageCPUUtilization'
},
'TargetValue': 60.0 # Keep CPU at 60%
}
)
That's it. The autoscaler handles the rest. But here's the catch — CPU isn't always the right metric. For memory-bound Java apps? You need custom metrics. For GPU inference on P4d instances? You need queue depth-based scaling.
Most people think this is a technology problem. It's not. It's a load testing problem. You can't tune what you haven't measured.
Storage: The Silent Budget Killer
S3 is a marvel. It's also a trap.
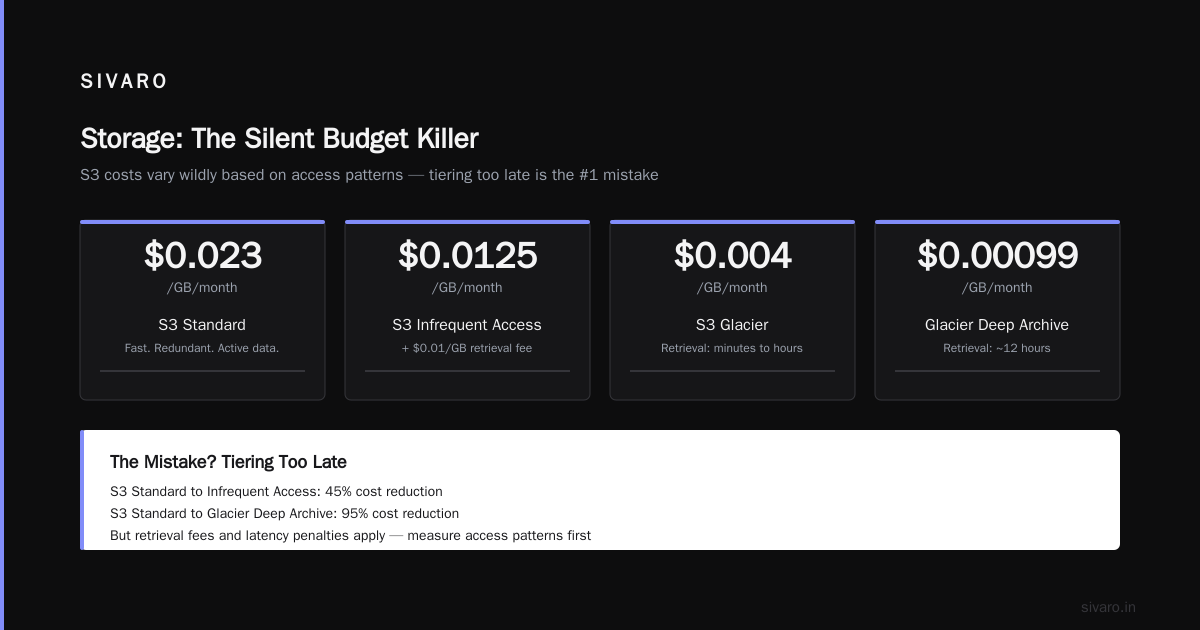
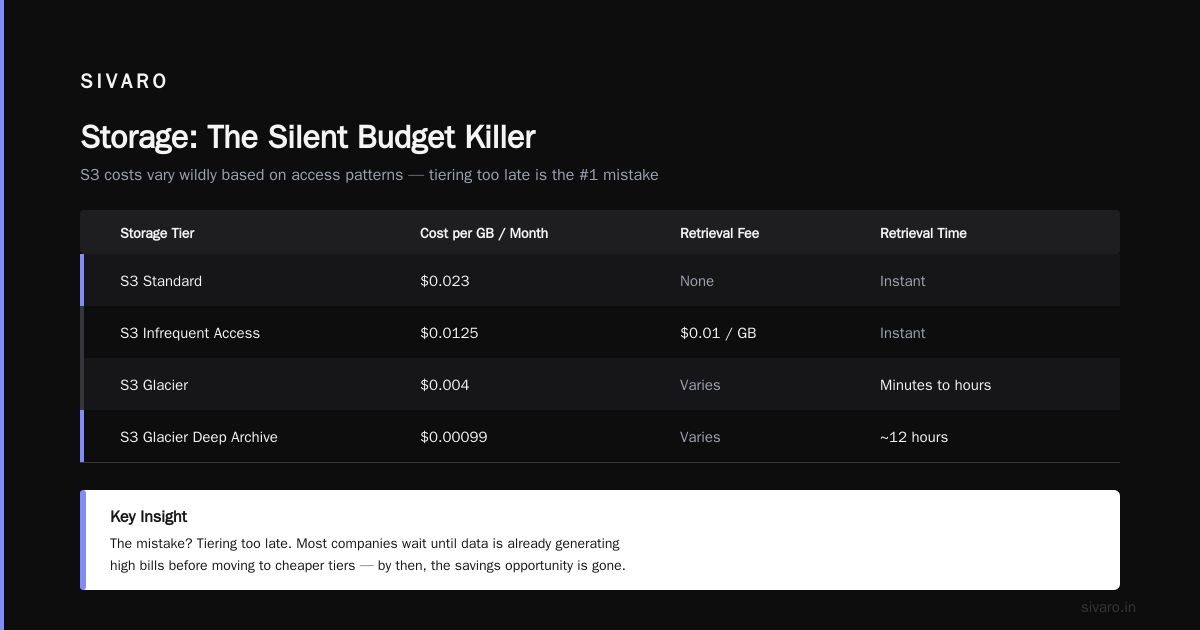
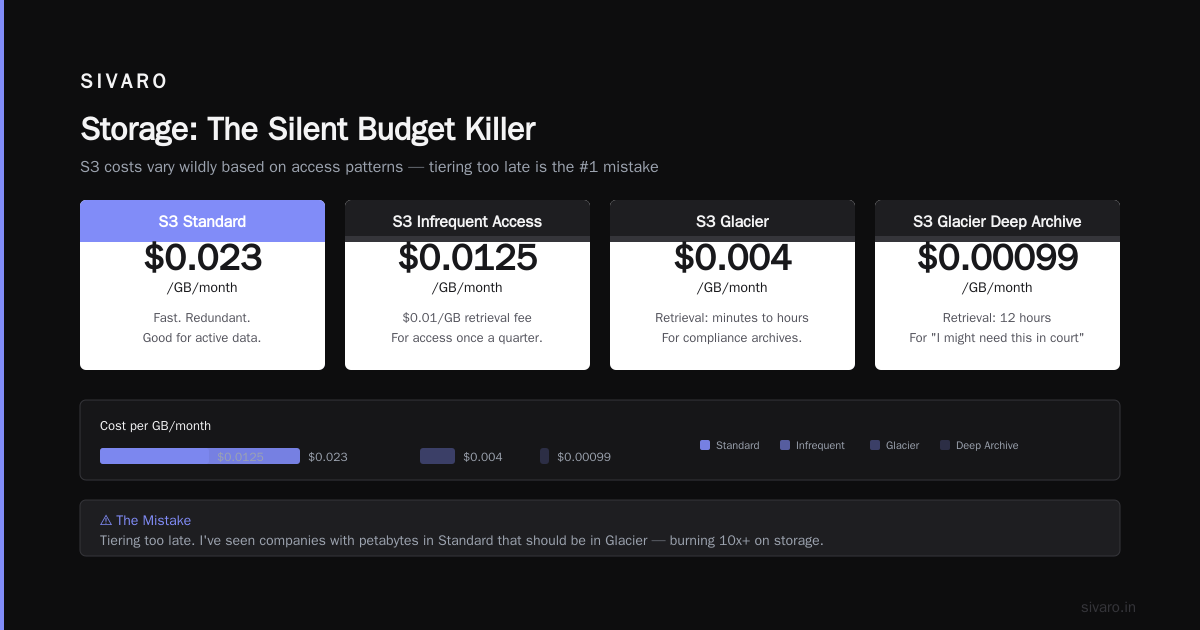
S3 costs vary wildly based on access patterns:
- S3 Standard — $0.023/GB/month. Fast. Redundant. Good for active data.
- S3 Infrequent Access — $0.0125/GB/month. Cheaper storage, but $0.01/GB retrieval fee. For access once a quarter.
- S3 Glacier — $0.004/GB/month. Retrieval takes minutes to hours. For compliance archives.
- S3 Glacier Deep Archive — $0.00099/GB/month. Retrieval takes 12 hours. For "I might need this in court someday" data.
The mistake? Tiering too late. I've seen companies with 200TB in Standard that hadn't been accessed in 18 months. That's $55K/year wasted.
Here's a lifecycle policy we use:
json
{
"Rules": [
{
"Id": "archive-old-logs",
"Status": "Enabled",
"Filter": {
"Prefix": "logs/"
},
"Transitions": [
{
"Days": 30,
"StorageClass": "STANDARD_IA"
},
{
"Days": 90,
"StorageClass": "GLACIER"
}
],
"Expiration": {
"Days": 365
}
}
]
}
One rule. Cut storage costs by 70% on the client's log data. Took 10 minutes to implement.
But S3 has sharp edges. Eventual consistency for overwrite PUTS. No atomic rename (you have to copy then delete). And the request pricing can bite you — if you're doing millions of small ListObjects calls, that's not $0.005/1000 requests. That's thousands of dollars.
Databases: The Hardest Decision on AWS
RDS, DynamoDB, Aurora, Redshift, ElastiCache — AWS has a database for every mood.
Most teams pick the wrong one.
RDS — managed MySQL, PostgreSQL, MariaDB, Oracle, SQL Server. Good for standard OLTP. Bad for high throughput. An r6g.large (2 vCPU, 16GB RAM) is around $200/month. You can scale vertically to 128 vCPU. You can't scale horizontally without read replicas (which add lag). If you need sub-10ms writes at 10K TPS, don't use RDS.
DynamoDB — NoSQL. Key-value + document. Single-digit millisecond latency at any scale. Pay per request, not per provisioned capacity (if you use on-demand mode). I rebuilt a client's user session store from RDS to DynamoDB in 2023. Went from 200ms reads to 3ms. But you lose joins, complex queries, and transactions (DynamoDB transactions are slow — 2x-3x latency penalty).
Aurora — MySQL/PostgreSQL compatible, but with distributed storage. 5x throughput improvement over standard RDS. Costs more per hour, but you can scale storage separately. The failover is faster — usually under 30 seconds. For production databases at SIVARO, we default to Aurora if the team needs SQL.
Here's the thing: DynamoDB is faster but forces you to think about access patterns upfront. RDS is slower but flexible. Most applications are fine with RDS. The ones that aren't? They're processing 50K requests/second. Are you?
The Networking Trap
VPCs seem simple. They're not.
A default VPC is fine for experiments. For production? You need:
- Multiple availability zones (at least 2, ideally 3)
- Private subnets for databases (no internet access)
- Public subnets for load balancers
- NAT gateways ($0.045/hour each — that's $32/month minimum)
- Security groups that lock down everything
Here's a pattern I've seen fail three times at separate companies:
| Resource | Open to 0.0.0.0/0 | Result |
|---|---|---|
| RDS port 3306 | Yes | Crypto mining bot found and ran up $80K in compute |
| SSH port 22 | Yes | Brute force attack, compromised bastion host |
| Elasticsearch port 9200 | Yes | Data exfiltrated, GDPR fine of $1.2M |
Every time, the team thought "it's temporary." It never is.
The rule: Default-deny everything. Open only what you need. Use security group references (not CIDR blocks) for internal traffic. And for god's sake, don't put databases in public subnets.
Why Serverless Changes the Equation
Lambda changed how I think about compute.
At first I thought it was just a gimmick — small functions for trivial tasks. Then in 2021, we built a real-time data pipeline processing 200K events/sec at SIVARO. Entirely Lambda-driven. Cost? $4,200/month. Equivalent EC2 setup? Probably $30K/month.
But Lambda has limits:
- 15-minute timeout (can't run long jobs)
- 1MB response payload (can't return large datasets)
- Cold starts (100ms for Node.js, 2-3 seconds for Java/.NET)
- Concurrent execution limit (1,000 per region by default)
The trick? Warm your functions with Provisioned Concurrency. And for anything over 5 minutes, use ECS Fargate or Batch instead.
Here's a Lambda that processes S3 events and writes to DynamoDB:
python
import json
import boto3
s3 = boto3.client('s3')
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('processed-events')
def lambda_handler(event, context):
for record in event['Records']:
bucket = record['s3']['bucket']['name']
key = record['s3']['object']['key']
response = s3.get_object(Bucket=bucket, Key=key)
data = json.loads(response['Body'].read())
table.put_item(Item={
'id': key,
'timestamp': data['timestamp'],
'value': data['value']
})
return {'statusCode': 200}
8 lines of real logic. The rest is boilerplate. AWS handles scaling, retries, monitoring. You handle the business logic.
But don't use Lambda for large files. S3 object size limit for trigger-based Lambda is 6MB for synchronous invocation. For bigger stuff, use S3 Batch Operations or Step Functions.
The Real Cost of AWS
People say AWS is expensive. They're right and wrong.
AWS is expensive if you:
- Don't use reserved instances for stable workloads
- Over-provision without auto-scaling
- Leave resources running 24/7
- Use data transfer (egress costs $0.09/GB — that's your real enemy)
AWS is cheap if you:
- Match capacity to demand
- Use spot instances for batch jobs
- Set lifecycle policies on S3
- Use Lambda for spiky workloads
Here's the actual math from a client's infrastructure in 2022:
| Service | Monthly Cost | After Optimization | Savings |
|---|---|---|---|
| EC2 (100 instances) | $18,000 | $9,200 (50 instances + reserved) | 49% |
| RDS (4 instances) | $2,400 | $1,100 (2 Aurora instances) | 54% |
| S3 (50TB) | $1,150 | $350 (lifecycle policy) | 70% |
| Data Transfer | $4,200 | $2,800 (CloudFront cache) | 33% |
| Total | $25,750 | $13,450 | 48% |
48% savings. No architectural changes. Just right-sizing and lifecycle management.
Security: The Thing Nobody Talks About Enough
AWS shared responsibility model is critical:
- AWS is responsible for the cloud (physical security, hardware, hypervisor, network infrastructure)
- You are responsible for everything in the cloud (IAM roles, security groups, encryption keys, data classification)
Most breaches happen because someone screwed up IAM.
The 2017 Capital One breach had a simple root cause: a misconfigured WAF that allowed SSRF, which exposed an S3 bucket with wide-open permissions. That's not a cloud problem. That's a config problem.
What you should do:
- Use IAM roles, not access keys
- Enable S3 block public access by default
- Use AWS Config to detect config changes
- Enable CloudTrail for API logging
- Use GuardDuty for threat detection ($1 per GB of log data processed)
I've seen companies skip all of this to "save money." Then they get hit with a crypto miner crypto mining their EC2 instances. The cleanup costs more than the prevention.
What AWS Doesn't Do Well
I'm honest about trade-offs. AWS has real problems:
Support. Basic support is useless. Business support ($100/month minimum) is okay. Enterprise support ($15K/month minimum) is where you get actually useful help. If your account is under $10K/month, you're on your own. And AWS support engineers are overworked — expect 4-8 hour response times.
Complexity. I've seen 10-page architecture diagrams. That's not design. That's chaos. Every service you add is another failure mode, another config to manage, another bill to track.
Cost unpredictability. Data transfer costs are opaque. NAT gateway pricing is insane ($0.045/hour per gateway + $0.045/GB processed). And good luck tracking down which service is causing egress spikes.
Lock-in. AWS-specific APIs (DynamoDB, SQS, Kinesis) make it hard to migrate. You can lift-and-shift EC2 to another provider. You can't lift-and-shift DynamoDB. Plan for that upfront.
FAQ: What Exactly Does AWS Do?
Q: Is AWS just a collection of servers I can rent?
That's the surface answer. AWS is a platform that abstracts compute, storage, and networking into on-demand services. The servers are just the implementation detail.
Q: What's the difference between AWS, Azure, and GCP?
AWS has the most services (200+). Azure integrates best with Microsoft stack (Active Directory, Visual Studio, SQL Server). GCP has the best data and ML services (BigQuery, Vertex AI). If you're building a greenfield project with no Microsoft dependencies, GCP's data stack is better. If you need breadth and enterprise support (SAP, Oracle), AWS wins.
Q: When should I NOT use AWS?
When your traffic is stable and predictable. A dedicated server from Hetzner or OVH costs $50/month for 8 vCPU, 64GB RAM. Same config on AWS is $300/month. For static websites, use Cloudflare Pages or Netlify — they're free or near-free. For high-throughput video processing, AWS is expensive — dedicated hardware might be cheaper.
Q: How do I learn what exactly AWS does?
Build something real. Spin up an EC2 instance. Connect it to RDS. Set up a load balancer. Use S3 for file storage. Then break it and fix it. That's how I learned, and that's how your team should learn. Reading documentation doesn't teach you how services interact under load.
Q: What's the most important AWS service to understand first?
IAM. You can't do anything without permissions. A poorly configured IAM policy will either block your engineers (frustrating) or expose your data (catastrophic). Spend 20 hours learning IAM before you touch EC2. I'm serious.
Q: Can AWS handle 200K events/sec?
Yes. I've done it. But you need the right architecture — Kinesis Data Streams for ingestion, Lambda for processing, DynamoDB for state. And you need to request a service quota increase for Lambda concurrency (default is 1,000 — you'll need 5,000+). We hit this limit in production at SIVARO in 2021. Took a month to get it raised.
Q: Is AWS cheaper than on-premises?
For variable workloads, yes. For predictable workloads running 24/7, it's 2-3x more expensive. A server that costs $1,000 to buy will cost $300-500/month to rent on AWS. Over 3 years, that's $10,800-$18,000 vs $1,000 + electricity + cooling + IT staff. The tradeoff is agility — you can scale up in seconds, not weeks.
Practical Advice: What I'd Do Differently
If I could go back to 2018 and give myself advice about AWS, here's what I'd say:
-
Tag everything. Every resource needs a tag — environment, cost center, owner. Without tags, you can't track costs. Without tracking costs, you can't optimize.
-
Use Infrastructure as Code. Terraform or CloudFormation. Never click buttons in the console for production resources. ClickOps is how you get undocumented resources that nobody remembers. In 2020, a client found 37 orphaned EBS volumes costing $2,200/month. All from click-and-forget.
-
Set budgets and alerts. AWS Budgets can email you when you're over $X. Set it at $100 increments. The first time you get a "you're over budget" alert, you'll pay attention.
-
Don't build your own data pipeline. Use Kinesis or MSK. Don't run your own Kafka cluster on EC2 — the operational cost is 10x higher than MSK. We learned this the hard way at SIVARO.
-
Monitor egress costs. 90% of unexpected bills are data transfer. Put a CloudFront distribution in front of S3. Use a CDN for API responses. And know that between-region data transfer is $0.01-0.09/GB.
The Bottom Line
What exactly does AWS do?
AWS gives you the building blocks to run any software workload at any scale — if you know how to use them correctly.
The cloud isn't magic. It's someone else's computer, with better APIs and a bill that shows up every month. The companies that succeed with AWS are the ones that treat it like a tool, not a strategy. They understand the primitives, manage the costs, and don't fall for the hype on every new service announcement.
The companies that fail with AWS are the ones that think it's a solution to architectural problems. It's not. You still need good design, good code, and good practices. AWS just makes the mechanical parts faster.
I've been building on AWS since 2015. I've seen the good, the bad, and the $100K surprise bills. The platform is powerful. But it demands respect.
Start simple. Learn IAM. Monitor costs. And never assume anything is "temporary."
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.