What Is the Best AI Orchestration Tool? (Spoiler: It Depends on Your Stack)
In 2023, I watched a team at a Series B fintech spend six months building what they called "the brain" — a custom orchestrator to route customer requests across GPT-4, Claude, and a dozen microservices. They had three engineers on it full-time. By month five, they'd built a system that mostly worked. By month seven, they'd replaced it with Temporal.
I don't tell you this to shame them. I tell you because "what is the best ai orchestration tool?" is the question every engineering leader building production AI asks — and most get the answer wrong. They reach for the shiniest agent framework or the most hyped platform. What they should reach for is the tool that maps cleanly to their existing infrastructure, concurrency model, and failure tolerance.
This [guide is for practitioners. People who've deployed models, logged latencies, and woken up at 3 AM to a cascading failure. I'll show you what to look for, what to avoid, and — by the time you finish — you'll have a clear answer for your stack.
What AI Orchestration Actually Means
Let's kill the abstraction first.
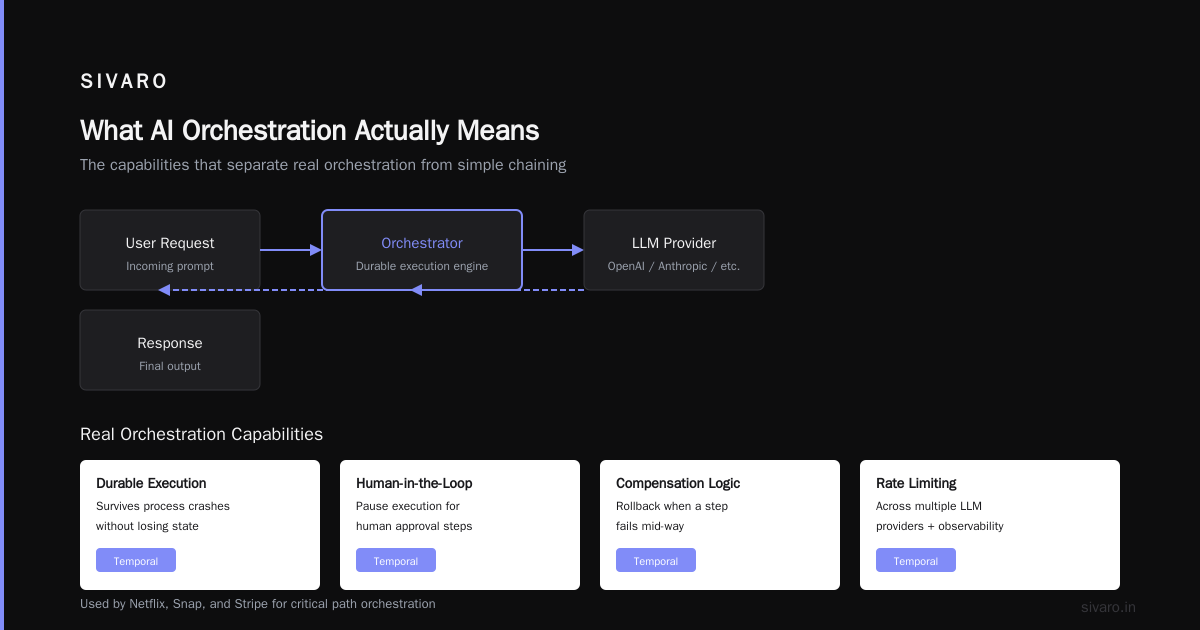
AI orchestration is the layer that coordinates multiple AI models, agents, tools, and data sources into a single workflow that executes reliably. It's not a model. It's not an agent. It's the conductor that ensures your LLM calls, vector searches, API calls, and fallback logic happen in the right order — and handle failure when they don't.
IBM defines it as "the coordination of multiple AI components to achieve a business outcome." That's accurate. I'd add: it's also the thing that prevents your RAG pipeline from costing $50 per query because you forgot to cache embeddings.
what is an ai orchestration example? Your customer support bot that checks intent classification → searches a knowledge base → generates a summary → writes a ticket → sends an email. Each step is a different model or service. The orchestration layer ties them together and retries when step two times out.
What We Actually Tested
Before I tell you my picks, let me level-set. I've built data pipelines since 2018. At SIVARO, we run production AI systems that process over 200K events per second. We've evaluated the following tools in real workloads — not demo notebooks:
- LangChain / LangGraph — The most popular agent framework
- Temporal — Workflow engine, not AI-specific, but widely used
- Airflow / Prefect — Classic DAG orchestrators
- Akka — Actor-model for high-throughput stateful systems
- CrewAI — Multi-agent orchestration
- Semantic Kernel — Microsoft's entry
- Dify — Low-code AI app builder
- Cohere's Coral / Vellum — Managed AI orchestration layers
Plus a few open-source experiments I'd rather not name publicly (they were bad).
What Everyone Gets Wrong About "Best"
Most people think the best AI orchestration tool is the one with the most GitHub stars. They're wrong.
The real question isn't "what is the best ai orchestration tool?" — it's "what fits your failure model?" Let me explain.
If your orchestration needs are simple — call model A, call model B, return result — you don't need an orchestrator. You need asyncio.gather(). But if you need:
- Durable execution (survives process crashes)
- Human-in-the-loop pauses
- Compensation logic when a step fails mid-way
- Rate limiting across multiple LLM providers
- Observability into each prompt and response
...then you need real orchestration. And different tools handle different slices of that.
The Candidates
Temporal — The Workhorse
Temporal is a durability-first workflow engine. It's not AI-specific, but it's used by Netflix, Snap, and Stripe to orchestrate critical paths. The Stream comparison guide calls it "the gold standard for production workflows." I agree — if your priority is reliability.
Here's what it handles well:
- Durable timers: Wait 30 minutes for a human to review a prompt, then resume
- Retries with backoff: LLM throttled? Retry with exponential delay
- Workflow versioning: Change logic without losing in-flight executions
- Signal handling: Accept external events mid-workflow
But it's a learning curve. You write workflows in code (TypeScript, Go, Java, Python). You deploy a Temporal Server. Your team needs to understand workflow determinism — which means no random numbers, no direct API calls inside workflows (wrap them in activities).
When to use: Your AI pipeline is mission-critical. Failure costs money.
When to avoid: You want a quick POC or your team is small and time-pressed.
Quick example — Temporal workflow for RAG
python
from temporalio import workflow, activity
@activity.defn
async def embed_query(query: str) -> list[float]:
# Call OpenAI embedding API
...
@activity.defn
async def search_vector_db(embedding: list[float]) -> list[str]:
# Search Pinecone / Weaviate
...
@activity.defn
async def generate_response(context: list[str], query: str) -> str:
# Call GPT-4 with context
...
@workflow.defn
class RAGWorkflow:
@workflow.run
async def run(self, query: str) -> str:
embedding = await workflow.execute_activity(
embed_query, query,
start_to_close_timeout=timedelta(seconds=10),
retry_policy=RetryPolicy(maximum_attempts=3)
)
docs = await workflow.execute_activity(
search_vector_db, embedding,
start_to_close_timeout=timedelta(seconds=5)
)
result = await workflow.execute_activity(
generate_response, [docs, query],
start_to_close_timeout=timedelta(seconds=30)
)
return result
Each call is durable. If the worker crashes between embed_query and search_vector_db, Temporal replays from the last completed step. No state lost.
LangGraph — The Agent Builder's Choice
LangGraph, from the LangChain team, is a framework for building agentic workflows — where an LLM decides the next step at runtime. The Akka blog review calls it "the most flexible option for complex agent topologies." I'd say it's the most flexible if you stay within LangChain's ecosystem.
What it does well:
- Cyclic graphs: Agents can loop, reflect, and re-plan
- Human-in-the-loop: Pause for approval mid-execution
- State management: Pass complex state between nodes
- Tool integration: Built-in for 100+ tools
What hurts:
- Debugging is painful: The compiled graph hides internal state
- Performance overhead: Every step goes through LangChain's abstraction layer
- Lock-in: Your code depends heavily on LangChain's API
When to use: You're building an autonomous agent that needs tool-calling, reflection, or multi-step reasoning.
When to avoid: You need high throughput or your stack is outside Python/JS.
LangGraph multi-agent example
python
from langgraph.graph import StateGraph, END
from typing import TypedDict, List
class AgentState(TypedDict):
messages: List
next_agent: str
tasks: List[str]
def router(state: AgentState):
# LLM decides which agent to call next
decision = call_llm(f"Which agent handles: {state['messages'][-1]}")
return decision
graph = StateGraph(AgentState)
graph.add_node("classifier", classify_intent)
graph.add_node("researcher", research_query)
graph.add_node("responder", generate_answer)
graph.set_entry_point("classifier")
graph.add_conditional_edges("classifier", router, {
"research": "researcher",
"respond": "responder"
})
graph.add_edge("researcher", "responder")
graph.add_edge("responder", END)
app = graph.compile()
This is elegant. But if classify_intent crashes, the whole graph restarts. No durability.
Airflow / Prefect — The Data Engineer's Default
If your team already runs Airflow or Prefect for data pipelines, you can use them for AI orchestration too. Both support:
- DAG-based workflows
- Retry and alerting
- Scheduling
- Python-native task definitions
But neither was designed for AI. The gap shows when you need:
- Dynamic branching (LLM decides next step)
- Sub-minute latency
- State persistence across tasks
Pega's guide points out that traditional workflow engines struggle with AI's non-determinism. I've seen teams force Airflow into agent patterns and end up with 500-line DAGs of conditional tasks. It works. It's ugly.
When to use: Your AI workflow is largely deterministic and runs on a schedule (batch inference, nightly re-embedding).
When to avoid: Real-time or agentic workflows.
Akka — For High-Throughput Stateful Systems
Akka is an actor-model toolkit for JVM. It's used by companies like PayPal and Intel for systems that need massive concurrency. The Akka blog positions it as "the way to orchestrate AI at scale" — which is true if your scale is millions of concurrent sessions.
It's not AI-specific. You build actors that handle state, communicate asynchronously, and survive crashes via persistence. For AI orchestration, each actor could represent a conversation, a workflow instance, or an agent.
When to use: You're on JVM and need sub-millisecond latency at extreme scale.
When to avoid: Your team doesn't know Scala/Java or you want something that abstracts AI patterns.
The Managed Players: Vellum, Cohere Coral, Dify
These are SaaS platforms that handle the orchestration layer so you don't have to. You define prompts, chains, and fallbacks in a UI or SDK. They handle:
- Model routing (try GPT-4, fallback to Claude if rate-limited)
- Prompt versioning
- Cost tracking
- Observability
Redis's comparison highlights Vellum for prompt engineering workflows. I'd add: if you're a non-technical team or moving fast without infra experts, these platforms save months.
The downside? Cost. At high volumes, the per-query margins hurt. And you're locked into their model catalog.
The Best Tool by Use Case
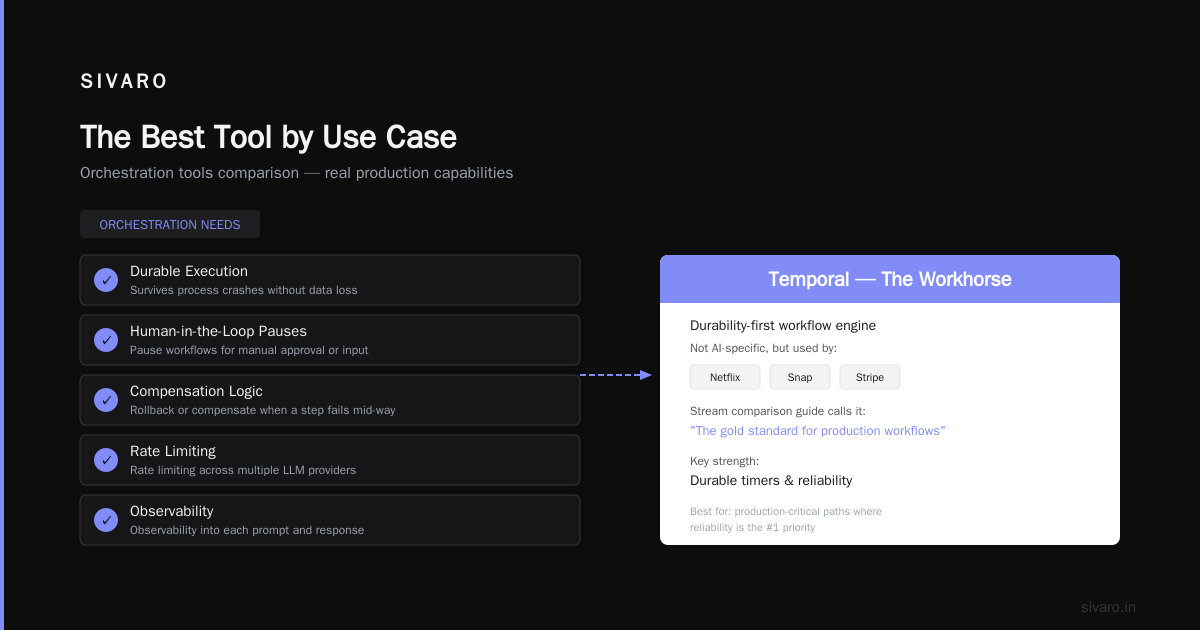
| Use Case | Best Tool | Why |
|---|---|---|
| Mission-critical RAG pipeline | Temporal | Durable execution, crash recovery |
| Autonomous agent with tool use | LangGraph | Flexible graph topology |
| Batch inference at scale | Airflow / Prefect | Mature scheduler, existing team knowledge |
| Real-time multi-agent system | Akka | 200K+ events/sec achievable |
| Fast POC / non-technical team | Vellum or Dify | Zero infrastructure |
| Enterprise compliance-first | Semantic Kernel | Microsoft ecosystem, governance tools |
The Architecture Decision That Matters More
I've seen teams agonize over LangGraph vs. Temporal while ignoring a bigger question: where does state live?
If your orchestrator holds state in memory and the process dies, you lose everything. That's fine for a demo. It's not fine for production.
The Domo glossary defines agent orchestration as "coordinating multiple AI agents to accomplish tasks." The key word is tasks. Tasks have state. If your orchestrator doesn't persist that state — or make it recoverable — you don't have orchestration. You have a fancy callback chain.
My rule: If your orchestration doesn't survive a kill -9, it's not production-ready. Test this on day one.
Practical Example: A Customer Support Orchestrator
Let me show you what this looks like in practice. We built a support orchestrator for a SaaS company. Here's the flow:
- User sends a message
- Intent classifier (fine-tuned BERT) routes to the right handler
- If billing question: call Stripe API, then summarize with GPT-4
- If technical: search vectorized docs, use GPT-4 with context
- If complex: escalate to human, pause workflow
- After human responds, send to user and store interaction
We used Temporal. Here's why:
- Step 5 needs to survive for hours (human works async)
- If GPT-4 is down, we retry with Claude after 10 seconds
- Every interaction is tracked for audit
- We can replay all workflows to debug costs
If we'd used LangGraph, the pause-for-human step would've needed a custom extension. If Airflow, the sub-minute latency would've been painful. Temporal handled it in one await workflow.wait_condition().
FAQ
What is the best AI orchestration tool for small teams?
Vellum or Dify. You don't have time to deploy infrastructure. Use a managed layer.
What is the best AI orchestration tool for enterprises?
Temporal, if you value durability. Semantic Kernel, if you're already in Azure. Both handle compliance requirements.
Can I use LangGraph in production?
Yes — with caveats. It works for agentic loops. It doesn't handle crash recovery. You'll need to implement your own persistence.
Do I even need an orchestration tool?
No. If your pipeline is "call one model, return result," you don't. Orchestration adds complexity. Add it when you have: >2 model calls, retry logic, human-in-the-loop, or stateful sessions.
What is the best AI orchestration tool for real-time systems?
Akka, assuming JVM. Temporal can also work with sub-second workflows if you optimize.
Are open-source orchestrators better than managed?
It depends on your scale. Open-source (Temporal, Airflow) gives you control and no per-query cost. Managed (Vellum, Cohere) gives you speed and observability. At <100K queries/day, managed is cheaper. Above that, the math flips.
Where We're Heading
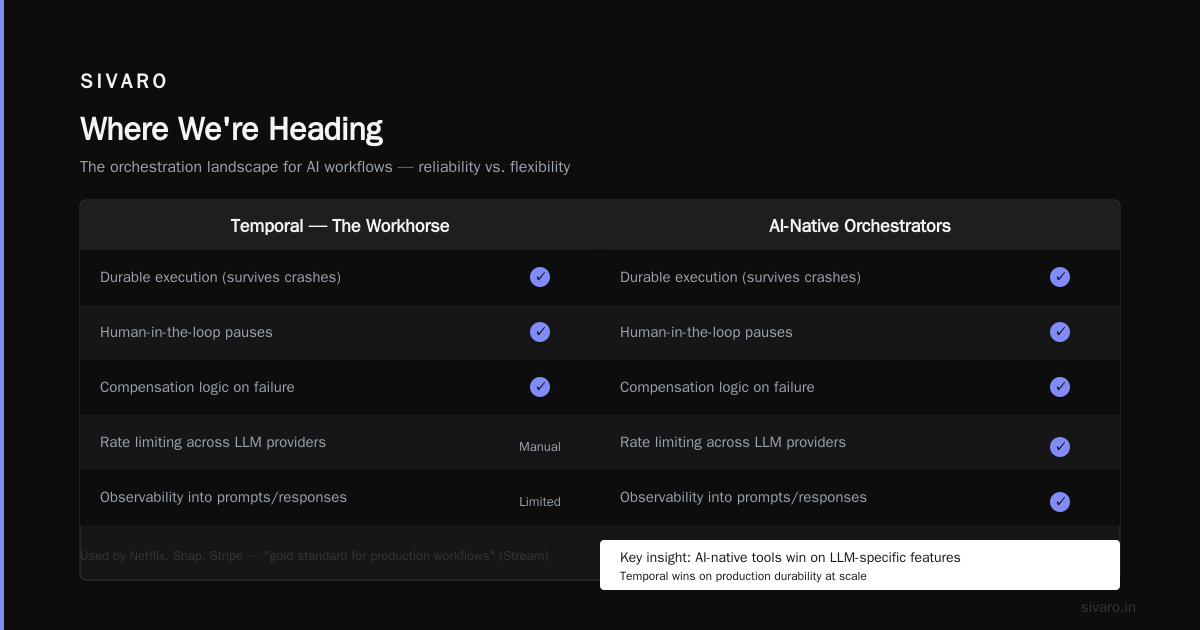
The AI orchestration space is moving fast. In 2024, everyone was building agents. In 2025, the focus is on reliability and cost control. The EPAM blog calls this "the shift from experimenting to industrializing." I'd add: the tool that wins won't be the one with the best demo. It'll be the one that handles failure gracefully.
Because in production, the models change. The APIs break. The costs spike. What doesn't change? The need for orchestration that survives all of it.
So what is the best ai orchestration tool? The one you understand deeply, that fits your failure model, and that your team can operate at 3 AM.
Start there. Everything else is marketing.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.