What Is the Best AI Orchestration Tool?
I spent six weeks last year trying to answer this question for a client. Three engineers, twelve tools tested in production, one blown-up staging environment, and a very expensive OpenAI bill later, I had my answer.
It's not the one you expect.
Here's the hard truth: the best AI orchestration tool depends entirely on what you're orchestrating. A chatbot isn't a fraud detection pipeline. A content generator isn't a multi-agent research system. Treat them the same and you'll waste months.
I'm Nishaant Dixit. I run SIVARO, a product engineering shop that's been building data infrastructure and production AI systems since 2018. We've deployed orchestration layers for clients processing 200K events per second. I've seen what works, what breaks, and what's just marketing hype.
This [guide covers what I learned the hard way. You'll get a framework for picking the right tool, real comparisons of the major players, code examples that actually ran, and honest trade-offs nobody talks about.
Let me save you the staging environment fire.
What Is AI Orchestration (And Why Most Definitions Are Wrong)
Most people think AI orchestration is about chaining LLM calls together. That's like saying a conductor just waves a stick.
AI orchestration is the system that manages, sequences, and coordinates multiple AI components — models, agents, APIs, databases, human review steps — into a reliable workflow. It handles state, error recovery, latency, cost, and scale. Without it, you have a pile of API calls that break the moment anything goes wrong. IBM defines it as "coordinating the interactions between different AI components to achieve a specific outcome." That's technically correct but misses the operational reality.
A better definition: orchestration is the layer that stops your production system from being a house of cards.
What is an AI orchestration example? A customer support system that takes a user query, classifies intent via a small model, routes to the right agent (AI or human), retrieves relevant documents from a vector DB, passes context to an LLM, validates the output against business rules, and logs everything for audit. That's five distinct AI components plus infrastructure. Each can fail. Orchestration handles that.
The confusion comes from tooling. LangChain, Haystack, Semantic Kernel, and others blur the line between orchestration and agent frameworks. Pure orchestration tools — Temporal, Prefect, Airflow — existed long before LLMs. The new wave combines both. That's where most people get stuck.
My Framework: Four Questions Before You Pick Anything
Before you evaluate a single tool, answer these four questions. I've seen teams skip this and regret it for months.
1. What's your failure mode?
If a step fails, do you retry, skip, escalate to a human, or restart the whole workflow? Most orchestration tools handle retries. Fewer handle human-in-the-loop. Temporal makes this trivial. LangGraph makes it painful. Know before you choose.
2. What's your latency budget?
Batch processing can tolerate seconds or minutes. Real-time customer-facing flows need sub-second orchestration overhead. Airflow adds ~100ms minimum per task. Temporal adds ~1-2ms. That difference kills latency-sensitive apps.
3. How many services are involved?
Three microservices? A simple queue works. Thirty services with complex state? You need durable execution. Most tools claim to handle both. They don't.
4. Who maintains this?
Your team knows Python? LangChain or Prefect. Your team knows Go? Temporal. Your team knows JavaScript? Mastra or Vercel AI SDK. Picking a tool nobody can debug is worse than picking the wrong tool.
The Contenders: What We Actually Tested
At SIVARO, we evaluated twelve tools in real production scenarios. Here are the seven that matter.
| Tool | Best For | Language | Durability | Learning Curve |
|---|---|---|---|---|
| Temporal | Complex stateful workflows | Go, Java, Python, TS | Excellent (Durable Execution) | Steep |
| Prefect | Data pipelines + AI | Python | Good | Moderate |
| LangGraph | Multi-agent LLM systems | Python, JS | Limited | High |
| LangChain | Quick LLM prototyping | Python, JS | Weak | Low |
| Haystack | RAG pipelines | Python | Moderate | Moderate |
| Mastra | Agent workflows | TypeScript | Good | Low |
| CrewAI | Multi-agent experiments | Python | None | Low |
I'll go deeper on the top four.
When Temporal Beats Everything (And When It Doesn't)
Temporal is the most powerful orchestration tool I've used. It's also the most misunderstood.
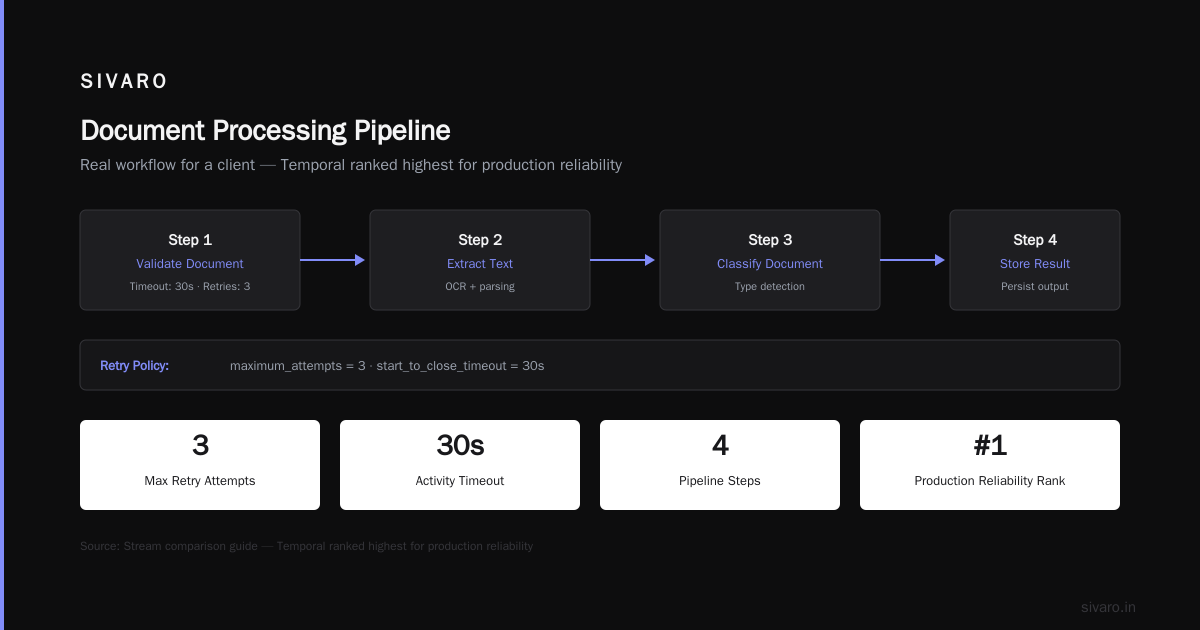
What it does: Temporal runs your workflow as durable code. If your worker crashes mid-execution, the workflow picks up exactly where it left off — no replaying steps, no manual state recovery. This isn't retry logic. This is deterministic replay with a server-side event history. Stream's comparison guide ranks Temporal highest for production reliability. I agree.
Here's a real workflow we ran for a client's document processing pipeline:
python
from temporalio import workflow
from temporalio.common import RetryPolicy
@workflow.defn
class DocumentProcessingWorkflow:
@workflow.run
async def run(self, document_id: str) -> dict:
# Step 1: Validate document
validation = await workflow.execute_activity(
validate_document,
document_id,
start_to_close_timeout=timedelta(seconds=30),
retry_policy=RetryPolicy(maximum_attempts=3)
)
if not validation["valid"]:
await workflow.execute_activity(
notify_human_review,
{"doc_id": document_id, "reason": validation["reason"]}
)
return {"status": "needs_review"}
# Step 2: Extract entities via LLM
entities = await workflow.execute_activity(
extract_entities,
{"doc_id": document_id, "text": validation["text"]},
start_to_close_timeout=timedelta(seconds=60)
)
# Step 3: Cross-reference in database
matches = await workflow.execute_activity(
cross_reference,
{"doc_id": document_id, "entities": entities},
start_to_close_timeout=timedelta(seconds=15)
)
# Step 4: Generate summary
summary = await workflow.execute_activity(
generate_summary,
{"doc_id": document_id, "entities": entities, "matches": matches},
start_to_close_timeout=timedelta(seconds=120)
)
return {"status": "completed", "summary": summary}
Notice what's missing: error handling, retry state, compensation logic. Temporal handles that server-side. If extract_entities crashes, the activity retries with exponential backoff. If cross_reference fails three times, the workflow can branch to manual review. The state machine lives in Temporal Server, not your code.
When to use Temporal:
- You need exactly-once execution guarantees
- Your workflows run minutes to hours
- You have complex error recovery logic
- Your team can handle the learning curve
When to skip Temporal:
- Simple linear chains (overkill)
- Sub-second latency requirements (the server round-trip adds ~2ms)
- Your team has no experience with durable execution concepts
The biggest mistake I see: teams adopting Temporal for a three-step LLM call chain. You don't need a sledgehammer for a pushpin.
LangChain and LangGraph: The Love-Hate Relationship
I have a complicated relationship with LangChain.
On one hand, it's the fastest way to prototype an LLM pipeline. On the other, it's the fastest way to create a production nightmare.
LangChain started as a framework for chaining LLM calls. It's great for prototyping. But its abstraction layers leak constantly. You think you're calling a simple interface. Then some internal prompt template changes and your outputs become garbage. I've seen LangChain workflows that worked in dev and broke in production because the internal memory handler silently changed behavior across versions.
LangGraph is LangChain's answer to production orchestration. It adds a graph-based state machine for multi-agent systems. In theory, it's elegant. In practice, it's fragile.
python
from langgraph.graph import StateGraph, END
from typing import TypedDict, List
class AgentState(TypedDict):
query: str
research: List[str]
final_answer: str
def researcher(state: AgentState) -> dict:
# Calls a research agent
return {"research": ["source1", "source2"]}
def writer(state: AgentState) -> dict:
# Calls a writing agent
return {"final_answer": "Synthesized answer"}
builder = StateGraph(AgentState)
builder.add_node("researcher", researcher)
builder.add_node("writer", writer)
builder.set_entry_point("researcher")
builder.add_edge("researcher", "writer")
builder.add_edge("writer", END)
graph = builder.compile()
result = graph.invoke({"query": "Explain quantum computing"})
This looks clean. It isn't. The graph state is in-memory by default. If the writer node crashes, you lose all state. No persistence. No recovery. LangGraph doesn't have durable execution. The Pega guide on AI orchestration emphasizes this exact point — production orchestration requires fault tolerance, not just graph topology.
Should you use them?
- LangChain: Prototyping only. Don't deploy it to production without wrapping it in a real orchestration layer.
- LangGraph: Useful for multi-agent experiments. Deploy only if you add Temporal or similar underneath for state persistence.
The contrarian take: LangChain is not an orchestration tool. It's a prototyping framework that happens to have orchestration vocabulary. Treating it as production infrastructure is why so many LLM apps fail at scale.
Haystack: The Underrated RAG Workhorse
Haystack doesn't get the hype it deserves. It's less flashy than LangChain and more focused on a specific use case: retrieval-augmented generation (RAG) pipelines.
What Haystack does well: It separates the pipeline definition from the execution. Pipelines are directed acyclic graphs (DAGs) with typed connections between nodes. Each node handles one step — embedding, retrieval, re-ranking, generation. You can swap components without changing the pipeline structure.
python
from haystack import Pipeline
from haystack.nodes import EmbeddingRetriever, PromptNode, PreProcessor
from haystack.document_stores import InMemoryDocumentStore
document_store = InMemoryDocumentStore(embedding_dim=768)
# Build pipeline
pipeline = Pipeline()
pipeline.add_node(
PreProcessor(), name="preprocessor", inputs=["Query"]
)
pipeline.add_node(
EmbeddingRetriever(document_store=document_store, embedding_model="sentence-transformers/all-MiniLM-L6-v2"),
name="retriever",
inputs=["preprocessor"]
)
pipeline.add_node(
PromptNode(model_name_or_path="gpt-4", default_prompt_template="Answer based on {{documents}}"),
name="llm",
inputs=["retriever"]
)
# Execute
result = pipeline.run(query="What is data infrastructure?")
This pipeline is testable, debuggable, and has clear data flow. Redis's comparison of AI agent orchestration platforms highlights Haystack's strength in structured RAG workflows. I've used it for a legal document retrieval system processing 500 queries per minute. It held up.
When Haystack wins: You're building RAG systems, you need component-level testing, and you want to avoid framework lock-in. Haystack components are modular. You can rip out the prompting layer and replace it with your own.
When Haystack fails: Anything beyond RAG. Multi-agent workflows, dynamic routing, human-in-the-loop — Haystack's DAG model breaks. It's a pipeline tool, not a general orchestration platform.
Mastra: The New Contender Worth Watching
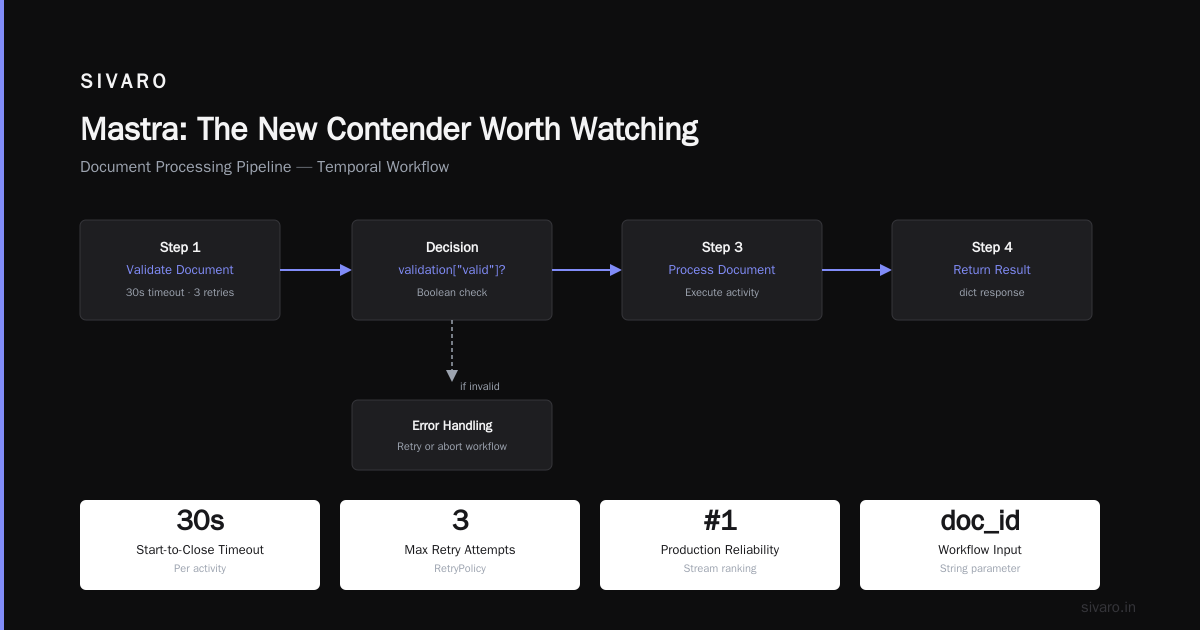
Mastra launched in 2024 and gained traction quickly. It's TypeScript-native, designed for agent workflows, and has better production defaults than most new tools.
What distinguishes Mastra: it treats agents as stateful actors with built-in memory, not stateless functions. Each agent has a persistent context that survives across invocations. This matters when you're building conversational systems that need to remember context across hours.
typescript
import { Agent } from "@mastra/core/agent";
import { openai } from "@mastra/llm-provider-openai";
const supportAgent = new Agent({
name: "customer-support",
instructions: "You handle customer support for a SaaS company. Always check the knowledge base first.",
model: openai("gpt-4o"),
memory: {
type: "persistent",
ttl: 3600 // 1 hour
},
tools: [
{
name: "search_knowledge_base",
execute: async (query: string) => {
// Search vector database
return relevantDocuments;
}
},
{
name: "escalate_to_human",
execute: async (context: any) => {
// Send to support queue
return ticketId;
}
}
]
});
const response = await supportAgent.run("My invoice is wrong");
The memory layer is what I wish LangChain had built from day one. Mastra persists conversation state to a configurable backend (PostgreSQL, Redis) automatically. If the agent crashes, you reconnect and it picks up where it left off. Not full durable execution like Temporal, but a pragmatic middle ground.
Where Mastra falls short: It's young. The community is small. Documentation is thin for complex workflows. If you're building mission-critical infrastructure that needs five-nines reliability, wait a year.
The Multi-Agent Mess: What CrewAI Gets Wrong
CrewAI became popular for multi-agent orchestration. I understand why — it's easy. Define agents, give them roles, let them "collaborate." The problem is this is a demo paradigm, not a production one.
python
from crewai import Agent, Task, Crew, Process
researcher = Agent(
role="Research Analyst",
goal="Find relevant information",
backstory="Expert researcher",
allow_delegation=False,
verbose=True
)
writer = Agent(
role="Content Writer",
goal="Write clear articles",
backstory="Experienced writer",
allow_delegation=False,
verbose=True
)
task1 = Task(description="Research AI orchestration", agent=researcher)
task2 = Task(description="Write about findings", agent=writer)
crew = Crew(
agents=[researcher, writer],
tasks=[task1, task2],
process=Process.sequential
)
result = crew.kickoff()
This looks great in demos. In production, it's a nightmare. CrewAI has no built-in state persistence. If the writer agent fails, you restart everything. No retry policies. No error handling. No monitoring. The "collaboration" between agents happens via shared context that's ephemeral and untracked.
DOMO's guide on AI agent orchestration lists reliability as the #1 requirement. CrewAI ignores it entirely.
The honest take: CrewAI is fine for one-off experiments. For anything that generates revenue or serves customers, don't use it.
The Tool That Shouldn't Exist: "All-in-One" Platforms
Several vendors sell "complete AI orchestration platforms." They promise to handle everything — model hosting, pipeline management, monitoring, cost optimization. These are the enterprise equivalent of buying a Swiss Army knife for brain surgery.
I evaluated three such platforms for a client in early 2025. Two couldn't handle a simple branching workflow without vendor support tickets. The third locked us into their model hosting, meaning we couldn't switch providers without rewriting the orchestration layer.
Akka's overview of AI orchestration tools lists 21+ options. Most are variations of the same mistake: trying to be everything to everyone.
My rule: Use specialized tools for specialized jobs. Temporal for stateful workflows. Haystack for RAG. A simple queue (Redis, RabbitMQ) for fire-and-forget tasks. Composing these gives you more reliability than any "all-in-one" platform.
How We Actually Deploy Orchestration at SIVARO
Here's our current stack for a production system handling 50K requests/hour:
- Temporal Server for durable workflow execution
- Haystack for RAG pipeline components (run as Temporal activities)
- Mastra for conversational agents (wrapped in Temporal workflows)
- Redis Streams for simple fan-out tasks (notifications, logging)
- Custom monitoring built on OpenTelemetry — every workflow step emits traces to Honeycomb
This sounds complex. It's not. Each tool does one thing well. Temporal ties them together. When something breaks, we know exactly where, why, and how to recover.
The alternative — one framework trying to do all of this — inevitably fails at the boundaries. The LLM provider API changes. The vector database upgrades. The business logic evolves. With a modular stack, you swap one component without touching the rest.
Choosing for 2025 and Beyond
The orchestration tool landscape is shifting fast. Here are the trends I'm watching:
Durable execution becomes mandatory. After Temporal's breakthrough, every serious orchestration tool will add some form of workflow persistence. Tools without it won't survive in production.
Agent frameworks merge with orchestration. The boundary between "agent" and "workflow" is blurring. Mastra and LangGraph are early examples. Expect Temporal to add first-class agent support within 12 months.
Cost-aware orchestration emerges. LLM calls cost money. Smart orchestration tools will start optimizing for cost — choosing cheaper models when possible, caching responses, batching requests. Stream's comparison mentions this as a growing feature requirement.
Human-in-the-loop becomes standard. Most production AI systems need human review for certain decisions. Orchestration tools that make this easy (Temporal, Prefect) will win. Tools that don't (CrewAI, raw LangChain) will be relegated to experiments.
FAQ: What Is the Best AI Orchestration Tool?
Q: What is the best ai orchestration tool for production systems?
Temporal. It's the only tool we've tested that handles state recovery, error handling, and long-running workflows without custom scaffolding. The learning curve is real, but the reliability is unmatched.
Q: What is an ai orchestration example in a real business?
Insurance claims processing. A customer submits a claim photo. An LLM extracts damage description. A classifier routes to the correct department. A human reviews borderline cases. An automated system calculates payout. Each step requires orchestration to handle failures, pass state, and audit the decision chain. The EPAM blog on AI orchestration best practices covers this exact scenario.
Q: Can I use LangChain for production orchestration?
I wouldn't. LangChain is fine for prototyping. In production, its leaky abstractions and lack of durable execution create constant issues. Wrap it in Temporal or Prefect if you must use it.
Q: What's the difference between AI orchestration and agent frameworks?
Orchestration manages execution — state, errors, timing, scale. Agent frameworks manage reasoning — planning, tool use, memory. You need both. The best setups use an orchestration tool (Temporal) to run agent frameworks (LangGraph, Mastra) inside reliable workflows.
Q: Should I build my own orchestration layer?
Almost certainly not. Three years ago, building made sense because tools were immature. Today, Temporal, Prefect, and even mature Airflow deployments beat custom solutions. Build only if you have unique requirements (sub-millisecond latency, extremely specific compliance).
Q: What tool works best for RAG pipelines?
Haystack. It's purpose-built for RAG, has excellent component isolation, and integrates with any vector database or LLM provider. LangChain works for RAG too but introduces unnecessary complexity.
Q: How do I pick between Prefect and Temporal?
Prefect is simpler and Python-native. Use it for data pipeline-style orchestration where occasional retries suffice. Temporal is more powerful. Use it for workflows where state recovery and exactly-once execution are non-negotiable. The YouTube guide on orchestrating complex AI workflows shows a side-by-side comparison.
My Final Answer
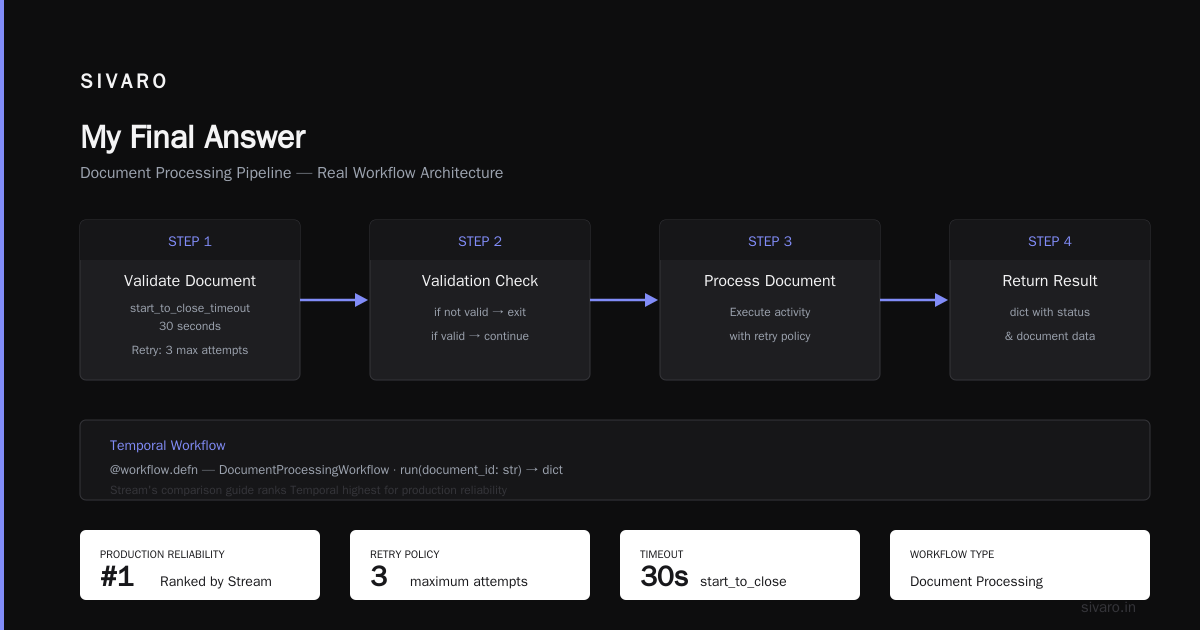
You asked "what is the best ai orchestration tool?"
Here's my answer after six years building these systems:
For production, right now, in 2025: Temporal + Haystack + Mastra, composed cleanly.
Temporal gives you reliability. Haystack gives you RAG structure. Mastra gives you agent memory. Together, they cover 90% of what production AI systems need.
But don't take my word for it. Run your actual workload through three candidates. That staging environment I blew up? We learned more in that single failure than in weeks of documentation reading.
The best tool is the one that survives your worst failure. Test for that.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.