Is Kafka Good or Evil? A Practitioner's Take on the Stream Processing Paradox
You're building a data pipeline. Your团队 is debating tech stacks. Someone mentions Kafka. And suddenly the room splits.
Some swear by it. "It's the backbone of modern data infrastructure." Others curse it. "It's a operational nightmare that shouldn't exist."
I've been on both sides. At SIVARO, we've built systems processing 200K events/sec using Kafka. We've also watched teams burn months on Kafka clusters that never delivered.
So — is Kafka good or evil?
The honest answer: it's neither. But your use of it will determine which it becomes.
Let me show you what I mean.
The Gen Z Obsession Problem (And What It Tells Us)
Here's something strange happening right now. Gen Z is obsessed with Franz Kafka — the writer, not the software. Why Gen-z is so obsessed by Kafka? threads on Reddit have thousands of comments. Why GenZ is SECRETLY OBSESSED with this author ? videos rack up millions of views.
The literary Kafka wrote about bureaucratic absurdity. Characters trapped in systems they couldn't understand. Processes that consumed their lives without purpose.
Sound familiar?
That's exactly what happens when teams misuse the software Kafka. You build a pipeline that becomes a maze of configuration. Topics proliferate. Partitions grow. Consumer groups drift. And somewhere along the way, you're not building features anymore — you're debugging Kafka.
Why is Gen Z obsessed with Kafka? One article argues it's because they grew up in systems that feel broken by design. The pandemic. Remote work. Algorithmic feeds they can't control.
I think the same applies to engineers. We inherit data systems that feel like bureaucratic nightmares. Kafka can make that [better. Or it can make it worse.
What Kafka Actually Is (Strip Away the Hype)
Let's be clear. Apache Kafka is a distributed commit log. That's it.
It's not a database. (Though people try to use it as one.)
It's not a message queue. (Though it can behave like one.)
It's not a stream processing engine. (Kafka Streams and ksqlDB sit on top, but they're separate.)
What Kafka does well: decouple producers from consumers in time and space. A producer writes an event. A consumer reads it later — maybe milliseconds, maybe days. The system persists the data, replicates it across nodes, and lets you replay it.
This is powerful. Franz Kafka the writer explored themes of alienation and deferred meaning. Software Kafka similarly lets you defer processing decisions. Write now. Figure out consumption later.
That's both the feature and the trap.
The Good: Where Kafka Shines
Event Sourcing at Scale
At SIVARO, we built a real-time inventory system for a logistics client in 2021. Every item movement — from warehouse to truck to store — needed to be recorded, auditable, and replayable.
Kafka was perfect for this.
python
from kafka import KafkaProducer
import json
producer = KafkaProducer(
bootstrap_servers=['kafka1:9092', 'kafka2:9092'],
value_serializer=lambda v: json.dumps(v).encode('utf-8'),
acks='all' # Wait for all replicas
)
# Record an inventory event
event = {
"item_id": "SKU-4821",
"location": "warehouse-07",
"action": "pick",
"quantity": 12,
"timestamp": "2024-11-15T14:23:01Z"
}
producer.send('inventory-events', value=event)
producer.flush()
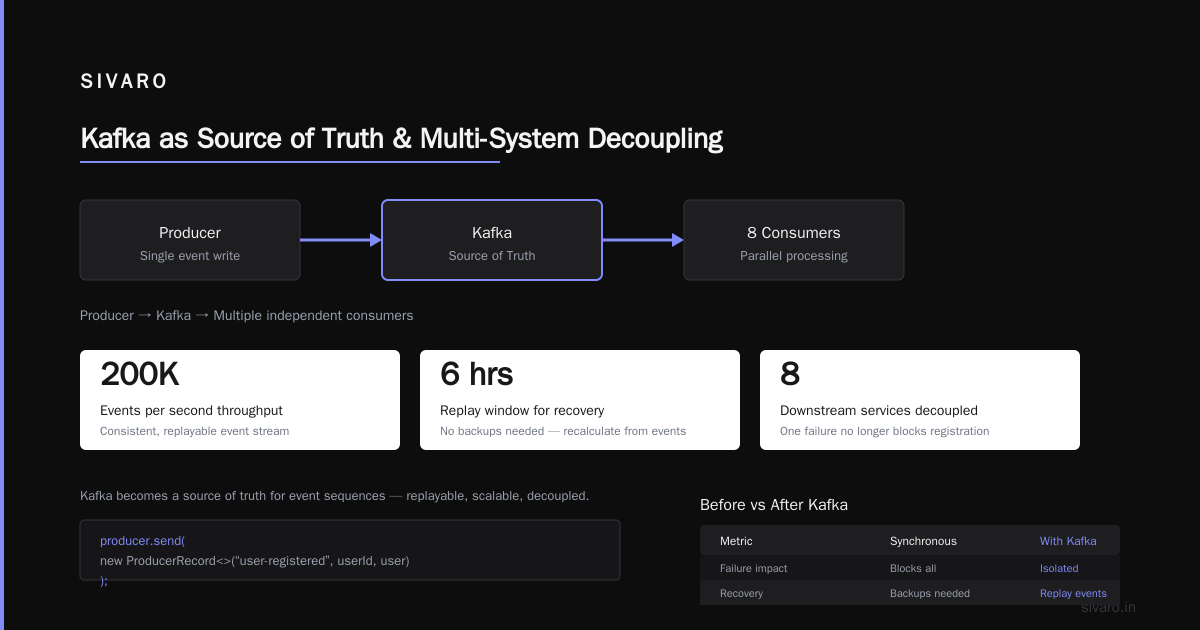
This worked. 200K events per second, consistent, replayable. When a bug caused incorrect stock counts in the database, we didn't need backups — we replayed the last 6 hours of events from Kafka and recalculated.
That's the good. Kafka becomes a source of truth for event sequences.
Multi-System Decoupling
Another client — a fintech startup — had a problem. Their user registration service would call 8 downstream services synchronously. One failure blocked everything.
Kafka solved it. The registration service wrote a single event. Eight independent consumers picked it up and processed it in parallel.
java
// Producer side — just one write
producer.send(new ProducerRecord<>("user-registered", userId, userData));
// Consumer 1: Send welcome email
// Consumer 2: Create analytics profile
// Consumer 3: Initialize credit check
// Consumer 4: Set up payment preferences
Latency dropped. Resilience improved. A failure in email dispatch didn't block credit checks.
This is Kafka at its best. It absorbs traffic spikes. It isolates failures. It lets teams develop independently.
The Evil: Where Kafka Bites Back
The Configuration Hell
Here's where most people get burned.
Kafka has 40+ configuration parameters per component. Broker configs. Producer configs. Consumer configs. Topic configs. Miss one and your cluster behaves mysteriously.
I've seen teams spend 3 weeks debugging "message loss" that turned out to be acks=0 on the producer side. Or consumer group rebalancing that took 5 minutes because session.timeout.ms was set to 30 seconds with 200 partitions.
yaml
# A partial list of Kafka configurations that WILL bite you
broker:
default.replication.factor: 3
min.insync.replicas: 2
unclean.leader.election.enable: false # Don't set this to true unless you hate data
producer:
acks: all # Not 0, not 1
retries: 5
enable.idempotence: true
consumer:
session.timeout.ms: 15000 # Too short = rebalancing storms
max.poll.interval.ms: 300000 # Too long = lag detection issues
auto.offset.reset: earliest # Or latest, depending on your use case
Each of these choices has trade-offs. acks=all guarantees durability but increases latency. enable.idempotence=true prevents duplicates but costs throughput. unclean.leader.election.enable=true lets the cluster recover faster but can lose acknowledged writes.
The evil isn't Kafka — it's the assumption that default configs work for production. They don't. You need to understand every parameter.
The Operational Tax
Running Kafka in production is a job. Not a feature.
You need:
- Zookeeper (or KRaft in newer versions) — another distributed system to manage
- Monitoring — JMX metrics are abundant but confusing
- Rebalancing — adding brokers causes partition redistribution that can take hours
- Disk management — Kafka writes to disk sequentially, but if partitions grow unevenly, you get hotspots
- Consumer lag — no built-in alerting beyond basic tools
A 2023 startup I consulted for tried to run Kafka on 3 t3.medium instances. Their peak throughput was 5 MB/s. The cluster crashed twice a week. They spent more time rebooting brokers than processing data.
Kafka requires infrastructure maturity. If you don't have a dedicated platform team, don't run Kafka yourself. Use Confluent Cloud, Redpanda, or AWS MSK.
The Cognitive Overhead
The worst evil is subtle. It's the way Kafka changes how your team thinks.
You start modeling everything as events. The database becomes a secondary concern. Eventual consistency becomes the norm. Debugging becomes "replay from the beginning of time" — which works until you have 6 months of events in a topic and replaying takes 4 hours.
I've seen teams build Kafka-only architectures. No databases. No caches. Just topics and consumers. Everything written twice. Impossible to query efficiently.
What is the tragedy of Kafka? The Quora answers talk about the writer's desire to destroy his own work. The software Kafka has a similar tragedy: it can destroy your architecture if used indiscriminately.
When Not to Use Kafka
Let me save you some pain. Don't use Kafka when:
- Your throughput is under 1000 events/second. A PostgreSQL table with triggers works fine. Don't add the complexity.
- You need exactly-once delivery to a database. Kafka has exactly-once semantics on the producer-consumer side, but downstream interactions are tricky. Idempotent consumers are simpler.
- Your team has never run a distributed system. Start with RabbitMQ or Redis. Learn the patterns. Graduate to Kafka.
- You're building a simple web app. Kafka is for systems, not applications.
I made this mistake in 2020. A client wanted real-time dashboards. Throughput: 200 events/second. I recommended Kafka. Three months later, we had a working system — but it was 5x more complex than a Redis pub/sub solution with a materialized view.
Most people use Kafka because they think they need it. They don't. They need ordered event processing at scale. Kafka provides that, but so do simpler tools for simpler cases.
The Gen Z Connection (Why This Matters Now)
Why GenZ is ADDICTED To This Author? | by AYMAN PATIL suggests that Franz Kafka's appeal lies in the feeling of being trapped in systems you can't comprehend.
That's exactly how junior engineers feel when thrown into a Kafka-based architecture. They see topics with cryptic names. They read consumer group rebalancing logs. They debug "the offset is committed but the message wasn't processed."
Gen-Z's obsession with Kafka & Dostoevsky (Op-Ed) argues that existential anxiety drives the literary obsession. Maybe the same drives technical obsession. Engineers want systems that work — but Kafka forces them to confront complexity, uncertainty, and deferred understanding.
100 years after his death, Gen Z loves Franz Kafka. Now ... The irony? They ought to read Kafka (the writer) to understand Kafka (the software). Both require patience. Both reward persistence. Both can break you.
Making Kafka Good (Patterns That Work)
After building systems with Kafka since 2018, here's what works.
Use Schema Registry
Don't send raw JSON. Use Avro or Protobuf with Schema Registry. It enforces compatibility. It prevents silent schema drift. It makes consumers know what they're reading.
json
{
"type": "record",
"name": "InventoryEvent",
"fields": [
{"name": "item_id", "type": "string"},
{"name": "location", "type": "string"},
{"name": "action", "type": {"type": "enum", "symbols": ["pick", "pack", "ship", "receive"]}},
{"name": "quantity", "type": "int"},
{"name": "timestamp", "type": "long"}
]
}
This catches errors at write time, not read time. Your consumers won't crash because a producer added a required field.
Implement Idempotent Consumers
Kafka doesn't guarantee exactly-once delivery to external systems. Your consumer can fail after processing but before committing the offset. Your consumer can process, commit, then crash — and the next consumer in the group picks up from the committed offset, missing the last message.
The fix: make your consumer idempotent.
python
def process_event(event):
# Check if already processed
if cache.exists(f"processed:{event['order_id']}"):
return # Already handled this one
# Process the event
database.execute("UPDATE orders SET status = ? WHERE id = ?",
event['new_status'], event['order_id'])
# Mark as processed
cache.set(f"processed:{event['order_id']}", True, ex=86400)
This pattern handles duplicates, replays, and failures. It's not elegant — it's necessary.
Partition by Business Key
Kafka guarantees order within a partition. That means: if you need events for a specific order to be processed in sequence, partition by order_id.
python
producer.send('order-events',
key=str(order_id).encode(), # Ensures same order_id goes to same partition
value=order_event_json)
But here's the trap: if you partition by a high-cardinality key (like user ID), you get many partitions. Many partitions mean many connections. Too many partitions cause rebalancing issues.
Keep partition count under 100 per broker. More than that causes management overhead. Less than 10 per broker means you're not parallelizing enough.
The Counterintuitive Truth
Most people think: "Kafka is complex but necessary for scale."
They're wrong about the necessary part.
Kafka is for specific problems:
- Replaying event streams
- Decoupling systems that can't agree on availability windows
- Building audit logs that survive individual system failures
If you don't have those problems, Kafka adds cost without benefit.
Has anyone read anything by Franz Kafka? Facebook groups discuss the literary Kafka's bizarre, labyrinthine stories. The software Kafka creates labyrinths too — but they're avoidable.
FAQ
Q: Is Kafka good or evil for small teams?
A: Evil, unless your small team has distributed systems experience. Even then, consider managed services first.
Q: Why is Gen Z obsessed with Kafka (the writer)?
A: Multiple sources suggest it's about identifying with characters trapped in absurd systems. The Neurospicy Researcher argues it reflects modern digital alienation.
Q: Can Kafka lose data?
A: Yes. With acks=0 or acks=1, yes. With acks=all, min.insync.replicas=2, and replication.factor=3, it's very hard to lose committed data. But not impossible — the disk can fail, the leader can be reassigned.
Q: What's the tragedy of Kafka (the software)?
A: That it's both powerful and misunderstood. Teams adopt it without understanding trade-offs, then blame the tool for their failed architecture.
Q: Kafka vs RabbitMQ — when to use which?
A: Kafka for event sourcing, replay, high throughput (>10K/s). RabbitMQ for task queues, routing, lower throughput with simpler semantics.
Q: What's the minimum viable Kafka setup?
A: 3 brokers, replication factor 3, min.insync.replicas 2, Zookeeper/KRaft cluster with 3 nodes. Don't run fewer. You need fault tolerance.
Q: Does Kafka have a positive use besides data infrastructure?
A: Yes — it's used in healthcare for patient event streams, in finance for transaction logs, in logistics for shipment tracking. Franz Kafka (1883-1924) - PMC explores the literary influence, but the software has real-world impact.
Q: Should I use Kafka for real-time analytics?
A: Only if you need replay. For dashboards, use a stream processor on top (ksqlDB, Flink) or push to a time-series database. Kafka alone doesn't query well.
The Verdict
Is Kafka good or evil?
It's a tool. Like fire. Useful when contained, destructive when wild.
The good: event sourcing, decoupling, replay, resilience at scale.
The evil: operational complexity, cognitive overhead, overengineering trap.
The real question isn't "is Kafka good or evil?" It's "does your problem require Kafka? "
If the answer is yes — and you understand the trade-offs — Kafka becomes an extraordinary tool. If the answer is "Kafka is cool and everyone uses it" — you're building your own nightmare.
Franz Kafka the writer died in 1924, asking for his works to be destroyed. Fortunately, his friend ignored him.
Maybe the lesson is: sometimes the best thing you can do with a Kafka system is know when to not deploy it.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.