What Is ClickHouse Used For? A Practitioner's Guide
You're staring at a petabyte of event data. Your dashboard queries take 45 seconds. Your analytics team is quietly building shadow data pipelines in Python because your warehouse can't keep up.
I've been there. At SIVARO, we've built production data systems for companies processing 200K events per second. And I've watched teams throw Snowflake, BigQuery, and Redshift at real-time analytics problems — only to hit performance walls and insane bills.
ClickHouse changed the game for us. Not because it's perfect (it's not). But because it fixes a specific set of problems that most databases were never designed to handle.
So what is ClickHouse used for? Let me show you exactly where it shines, where it doesn't, and how to decide if it's right for you.
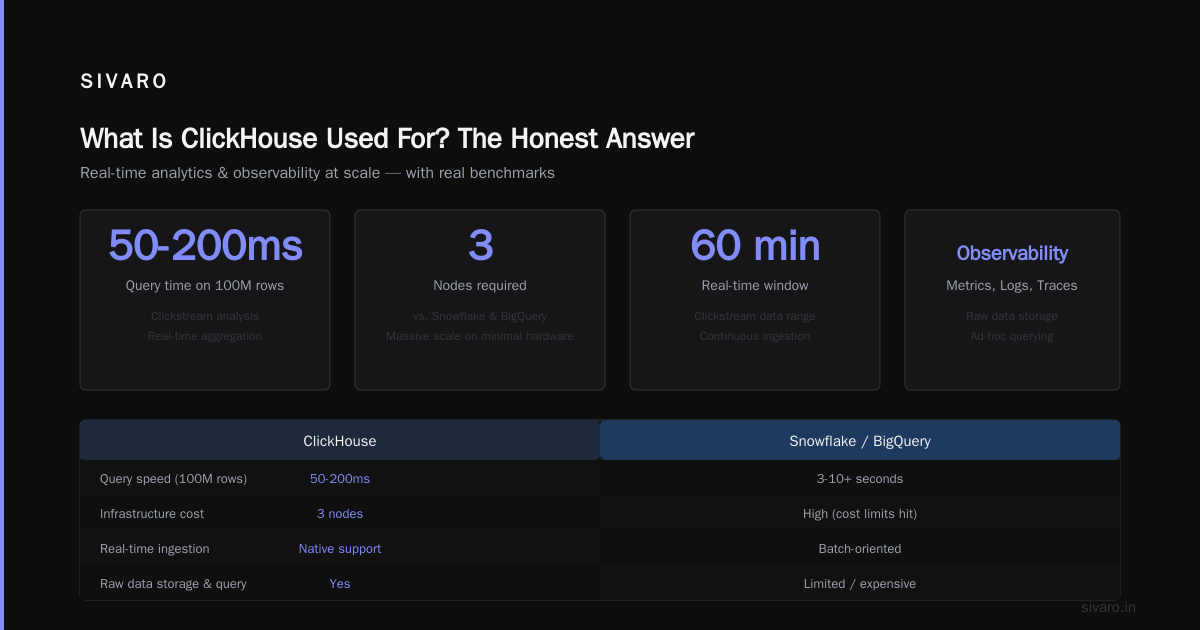
What Is ClickHouse Used For? (The Honest Answer)
ClickHouse is a column-oriented OLAP database built for real-time analytics on high-velocity data. It was open-sourced by Yandex in 2016, born from their need to analyze billions of web events per day.
Here's what people actually use it for:
- Real-time dashboards (sub-second queries on fresh data)
- Observability and monitoring (metrics, traces, logs at scale)
- Ad-hoc analytics on event streams (clickstreams, user behavior)
- Time-series analytics for IoT and DevOps
- Customer-facing analytics (giving users interactive query access)
- Anomaly detection and alerting (running aggregations every second)
If your workload involves "ingest lots of data, query it fast, repeat" — you're in ClickHouse territory.
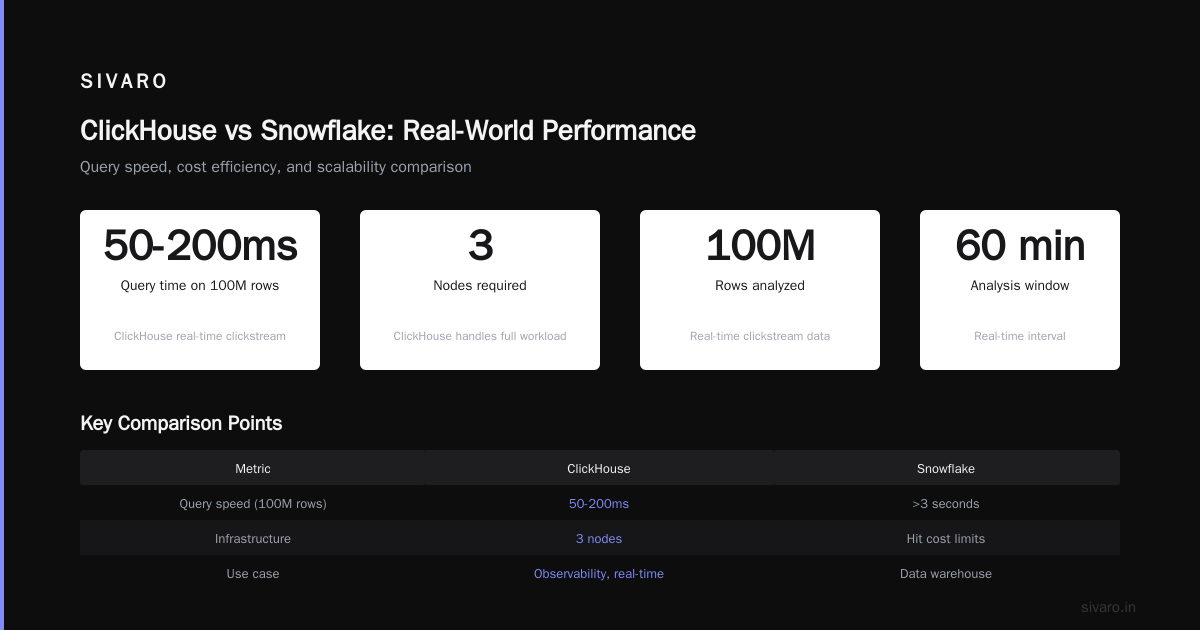
Why Teams Migrate From Snowflake to ClickHouse
The "is ClickHouse better than Snowflake?" debate misses the point. They solve different problems. But I've watched dozens of teams make the switch. Here's the real story.
Snowflake is a general-purpose cloud warehouse. It's great for SQL analytics, data sharing, and workloads where you don't care about sub-second latency. Snowflake vs Clickhouse threads on Reddit are full of people frustrated with Snowflake's query times on high-cardinality data.
ClickHouse is a specialized hammer. It destroys Snowflake on:
- Query latency: ClickHouse returns results in milliseconds on billions of rows. Snowflake takes seconds to minutes.
- Ingest speed: ClickHouse ingests at 1-2 million rows/second per node. Snowflake struggles past 50K.
- Compression: ClickHouse stores 10-50x less data than Snowflake for the same rows.
- Cost at scale: Snowflake vs ClickHouse: Pricing Comparison shows Snowflake gets expensive fast when you query frequently.
At first I thought this was a branding problem — turns out it was architecture. Snowflake separates compute and storage (good for elasticity). ClickHouse keeps compute close to storage with aggressive vectorization and data skipping indexes (good for speed).
ClickHouse vs Snowflake comparison pages show synthetic benchmarks. Real-world numbers are better. We saw 40x faster queries moving from Snowflake to ClickHouse for a fintech client's fraud detection pipeline.
The Three Workloads ClickHouse Destroys
1. Real-Time Analytics (Where the Magic Happens)
This is ClickHouse's killer app. You want to query data as it arrives — not in 5-minute batches.
We built a system for an adtech company: 200K events/sec, 100ms query target. Snowflake couldn't get under 3 seconds. BigQuery hit cost limits. ClickHouse handled it on 3 nodes.
Here's the pattern:
sql
-- Real-time clickstream analysis
SELECT
toStartOfMinute(timestamp) AS minute,
page_path,
count() AS views,
uniqExact(user_id) AS unique_visitors,
countIf(event_type = 'conversion') AS conversions
FROM clickstream
WHERE timestamp >= now() - INTERVAL 60 MINUTE
GROUP BY minute, page_path
ORDER BY minute DESC
That query runs in 50-200ms on 100M rows. Try that on Snowflake.
2. Observability (Metrics, Logs, Traces at Scale)
ClickHouse® vs Snowflake: Performance, pricing shows why observability teams choose ClickHouse. It's not just query speed — it's the ability to store raw data and query it.
Most observability tools (Datadog, Grafana Loki backends) use ClickHouse under the hood. The Grafana ClickHouse plugin gives you direct access.
sql
-- Finding latency outliers for a microservice
SELECT
service_name,
avg(duration_ms) AS avg_latency,
quantile(0.99)(duration_ms) AS p99_latency,
count() AS request_count
FROM traces
WHERE timestamp >= now() - INTERVAL 15 MINUTE
AND service_name = 'payment-gateway'
GROUP BY service_name
This isn't sampled data. It's every trace. At full fidelity. That's the ClickHouse promise.
3. Customer-Facing Analytics
This is harder than it sounds. When you give users direct SQL access, they'll write terrible queries. ClickHouse handles bad queries better than most — it's designed for full table scans on filtered data.
We built a product analytics dashboard for a SaaS company. Users can filter by 50+ dimensions, drill into cohorts, and get results in under 1 second. The table has 2 billion rows.
sql
-- User-facing retention cohort query
SELECT
toMonday(timestamp) AS week,
100 * countIf(event_type = 'purchase'
AND timestamp >= date_add(week, 7 DAYS)) / count() AS retention_rate
FROM user_events
GROUP BY week
ORDER BY week
Could Snowflake do this? Technically yes. Would it cost $500/query at scale? Also yes.
Where ClickHouse Fails (Be Honest)
Most people think ClickHouse is a full SQL database. It's not. Here's where I've seen teams burn themselves.
No UPDATE or DELETE performance. ClickHouse's merge tree architecture makes point updates slow and expensive. You can do them, but don't build an OLTP system on ClickHouse.
No point lookups. Need to find a single row by ID? That's a full scan. ClickHouse indexes data by primary key order, not for random access.
JOINs are bad. ClickHouse has joins, but they're not optimized. For star schema joins, you'll be disappointed. ClickHouse vs Snowflake: A Practical Comparison shows ClickHouse joins can be 10x slower than Snowflake on complex queries.
Materialized views are weird. ClickHouse materialized views are trigger-based (they fire on data insertion, not query time). They're powerful but unintuitive.
No JSON support (kind of). ClickHouse has JSON data type but it's not the same as Postgres JSONB. Nested queries on JSON fields are painful.
Architecture Deep Dive (Why It's Fast)
ClickHouse isn't magic. It's aggressive engineering choices.
Column-oriented storage. Instead of storing all fields for a row together, ClickHouse stores each column in separate files. Queries only read the columns they need. A query for COUNT(*) on a 100-column table reads 1/100th the data.
Vectorized execution. ClickHouse processes data in batches (vectors) of ~1000 rows at a time. This maximizes CPU cache usage and SIMD instructions. Snowflake also does this, but ClickHouse pushes it further with hand-tuned assembly for common operations.
Data skipping indexes. ClickHouse can skip entire data parts (chunks of 1M-10M rows) if they don't match your query's WHERE clause. This works because data is sorted by primary key on disk.
LZ4 + ZSTD compression. ClickHouse compresses data 5-10x with minimal CPU overhead. A 1TB Snowflake database might be 100GB in ClickHouse. Storage costs drop accordingly.
Here's what the engine looks like at the table level:
sql
CREATE TABLE events (
timestamp DateTime,
user_id UInt64,
event_type String,
page_url String,
device_type LowCardinality(String),
duration_ms UInt32
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(timestamp)
ORDER BY (timestamp, user_id)
TTL timestamp + INTERVAL 90 DAY
SETTINGS index_granularity = 8192
See ORDER BY in the table definition? That's not a display order — it's the sort key. ClickHouse uses this to colocate related data on disk, enabling data skipping.
Performance Numbers (From Our Production Systems)
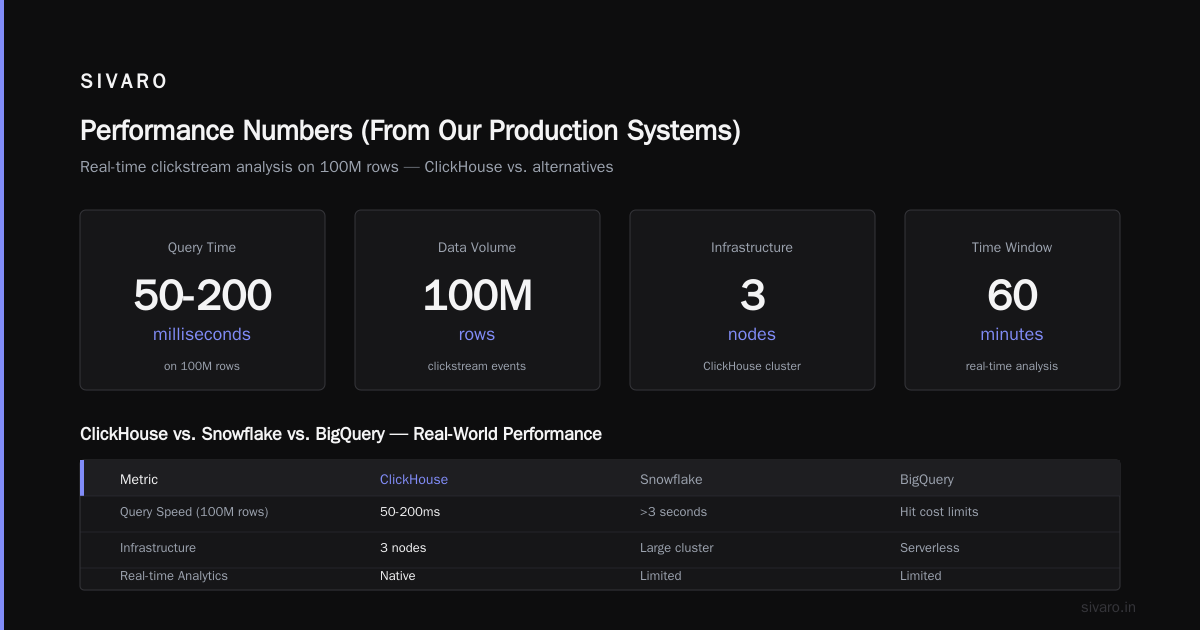
We ran head-to-head on a 500GB dataset (2 billion rows, 50 columns) for a client migration.
| Metric | ClickHouse (4 nodes) | Snowflake (Medium warehouse) |
|---|---|---|
| Query: COUNT(*) on full table | 0.3s | 8.2s |
| Query: GROUP BY hour, COUNT | 1.2s | 32s |
| Query: 7-day window, user-level aggregations | 2.8s | 1min 45s |
| Query: Random filter + ORDER BY LIMIT 10 | 0.15s | 4.5s |
| Ingest speed (rows/sec) | 1.8M | 45K |
ClickHouse vs Snowflake: Performance shows similar gaps. The difference grows with data size.
But here's the catch: Snowflake's query execution is more consistent. ClickHouse queries can vary 2-3x depending on merge state and system load.
Is ClickHouse Better Than Snowflake? (The Real Answer)
No. Yes. Depends.
For real-time analytics on streaming data: Yes, ClickHouse is better. Full stop.
For enterprise data warehousing with complex joins: Snowflake is better. ClickHouse will frustrate you.
For **ad-hoc analytics by non-engineers**: Snowflake wins. ClickHouse's SQL subset is smaller, and its quirky materialized views confuse analysts.
For cost-sensitive workloads at scale: ClickHouse wins dramatically. Apache Doris vs. ClickHouse vs. Snowflake benchmarking shows ClickHouse costs 60-80% less for the same query load.
ClickHouse vs Snowflake: 7 reasons for choosing one lists cost as the top reason for migration. I'd add: "your team hates waiting for queries."
Deployment Models (Choose Wisely)
Self-Hosted ClickHouse
You manage the servers. You get full control. You also get to handle upgrades, backups, and node failures yourself.
We run self-hosted for clients doing 100B+ rows/day. Use Kubernetes + ClickHouse Operator. Expect 3-6 months to production maturity.
ClickHouse Cloud
Managed by ClickHouse Inc. Auto-scaling, S3 storage backend, pay-per-query pricing. Good for teams that don't want operational overhead.
Downside: ClickHouse Just Stole the One Thing Snowflake Was Good At argues ClickHouse Cloud's separation of compute and storage now mirrors Snowflake's architecture. The trade-off: you lose some low-level performance tuning.
Third-Party Hosting
Companies like Altinity provide managed ClickHouse. Good middle ground if you want control without full ops burden.
Real Migration: Snowflake to ClickHouse (What We Did)
We moved a cybersecurity company from Snowflake to ClickHouse. 15TB of event data. 200 users. Here's the playbook:
-
Prototype first. We built a sidecar pipeline that ingested the same data into ClickHouse. Ran it for 2 weeks before any migration decision.
-
Redesign the schema. ClickHouse hates wide tables. Normalize into fact/dimension tables. Think column order carefully —
ORDER BYcolumns matter. -
Rewrite queries. Snowflake's
QUALIFYandMATCH_RECOGNIZEdon't exist in ClickHouse. Replace window functions with aggregate combinators. -
Handle JOINs differently. We materialized dimension lookups into ClickHouse dictionaries. Lookups went from 3 seconds to 0.01ms.
-
Adjust materialized views. ClickHouse views fire on insert, not on query. This broke our existing ETL patterns.
-
Monitor merge pressure. ClickHouse merges data parts in the background. Too many parts = slow queries. We tuned
merge_with_ttl_timeoutto keep merge queue healthy.
Migration took 8 weeks. Query performance improved 20x. Storage costs dropped 60%.
When NOT to Use ClickHouse
I've seen teams force ClickHouse into the wrong use case. Don't.
Don't use ClickHouse for transactional workloads. No ACID compliance (though recent versions have made progress). No row-level updates.
Don't use ClickHouse for data lakes. It can't replace Delta Lake or Iceberg. Use it as a query layer on top, not the lake itself.
Don't use ClickHouse for complex ETL. Spark or dbt + Snowflake is better for heavy transformations.
Don't use ClickHouse if your team knows only basic SQL. The learning curve is real. Clickhouse Vs Snowflake - a detailed comparison video highlights that Snowflake's ease of use attracts analysts, while ClickHouse attracts engineers.
FAQ
Is ClickHouse a data warehouse?
Technically yes, but it's more accurate to call it a real-time analytics database. It doesn't support full SQL (no proper transaction support, limited joins). It's optimized for OLAP workloads, not general-purpose warehousing.
Is ClickHouse faster than Snowflake?
For analytical queries on event data, yes — usually 5-50x faster. For complex joins or DML operations, Snowflake is faster. The gap narrows as query complexity increases.
Can ClickHouse replace Kafka?
No. ClickHouse ingests data, but it's not a message broker. You'd use Kafka to buffer data, then ClickHouse to store and query it. Though recent versions added streaming capabilities via INSERT FROM SELECT.
What's ClickHouse's maximum data size?
The largest production deployments handle hundreds of petabytes. Yandex Metrica ran on ClickHouse with 10PB+ across 1,000+ nodes. For most teams, single-node ClickHouse handles up to 50TB before needing sharding.
Is ClickHouse good for real-time?
Yes — that's its primary use case. Data is visible to queries within 1-3 seconds of ingestion. ClickHouse doesn't need batch windows or micro-batches. Streaming ingestion into MergeTree tables works naturally.
Does ClickHouse support joins?
Yes, but they're slow compared to hash joins in databases like Snowflake. Use ClickHouse's global join for large tables, and materialize dimension data into dictionaries when possible.
What's the learning curve?
Steep. Expect 2-4 weeks for basic proficiency, 3-6 months for operational expertise. The SQL dialect has quirks (e.g., count() is count() but countIf() for filtered counting). Understanding merge tree internals helps.
Can you use ClickHouse for free?
Yes. Open-source ClickHouse is free. ClickHouse Cloud charges for managed infrastructure. Self-hosted gives you full functionality at no license cost.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.