What Is the 30% Rule for AI? A Practitioner's Guide to Real ROI
You've heard the hype. AI will transform everything. But here's what I learned the hard way building production systems at SIVARO since 2018: most AI projects fail because teams expect 100% automation on day one.
The 30% rule for AI is simple: if you can reliably automate 30% of a task end-to-end with acceptable quality, you have a viable AI system. The remaining 70% isn't failure — it's your boundary conditions, edge cases, and human-in-the-loop zones.
Let me show you what this actually means.
Where the 30% Rule Came From
I didn't invent this. I stole it.
At SIVARO, we were building a document processing pipeline for a logistics company in 2022. They wanted AI to "read all invoices perfectly." After three months of trying, we had a model that handled about 28% of incoming invoices without any human review. The client was furious.
I told them: "You're about to fire your AP team of 12 people because AI can do 3 people's work. That's 25% cost savings immediately."
They didn't fire anyone. They reassigned the team to handle exceptions. Productivity went up 40% in 6 months.
The 30% rule is now the first question I ask every client: "What does acceptable 30% look like?" If they can't answer, the project gets cancelled.
This isn't about lazy AI. It's about honest scoping. MIT Sloan's explainer on agentic AI makes the same point: autonomous systems need bounded autonomy.
What Does an AI Agent Do Exactly?
Before we go deeper, let's nail the core question: what does an ai agent do exactly?
An AI agent is a system that perceives its environment, makes decisions, and takes actions toward a goal. Not a chatbot that answers questions. An agent does things.
Here's the breakdown from IBM's guide on AI agents:
- Perception: Receives data (text, images, sensor inputs)
- Reasoning: Applies rules, models, or LLMs to decide
- Action: Executes something (API call, file write, robot movement)
- Memory: Stores past interactions for context
A pure LLM is not an agent. ChatGPT with browsing, file upload, and code execution? That's closer. OpenAI's documentation on ChatGPT agent describes exactly this: autonomous tool use.
But here's the contrarian take: most "AI agents" you see demoed are toys. They work in controlled demos. In production, they hit the 30% wall hard.
The Math Behind the Rule
Let's get concrete.
Scenario A: A customer support chatbot handling tier-1 tickets.
- Easy tickets (password resets, status checks): 65% of volume
- Hard tickets (refunds, escalations): 35%
You think: "85% accuracy on easy tickets = 55% automation." Wrong.
The model might be 85% accurate overall, but the failures cluster in the 15% of tickets that cause real damage. Wrong refund amounts. Incorrect account closures.
The 30% rule says: find the subset where your system achieves >95% precision. Automate that. Nothing else.
Scenario B: Code generation for a SaaS product.
- Boilerplate CRUD endpoints: 40% of development time
- Business logic: 60%
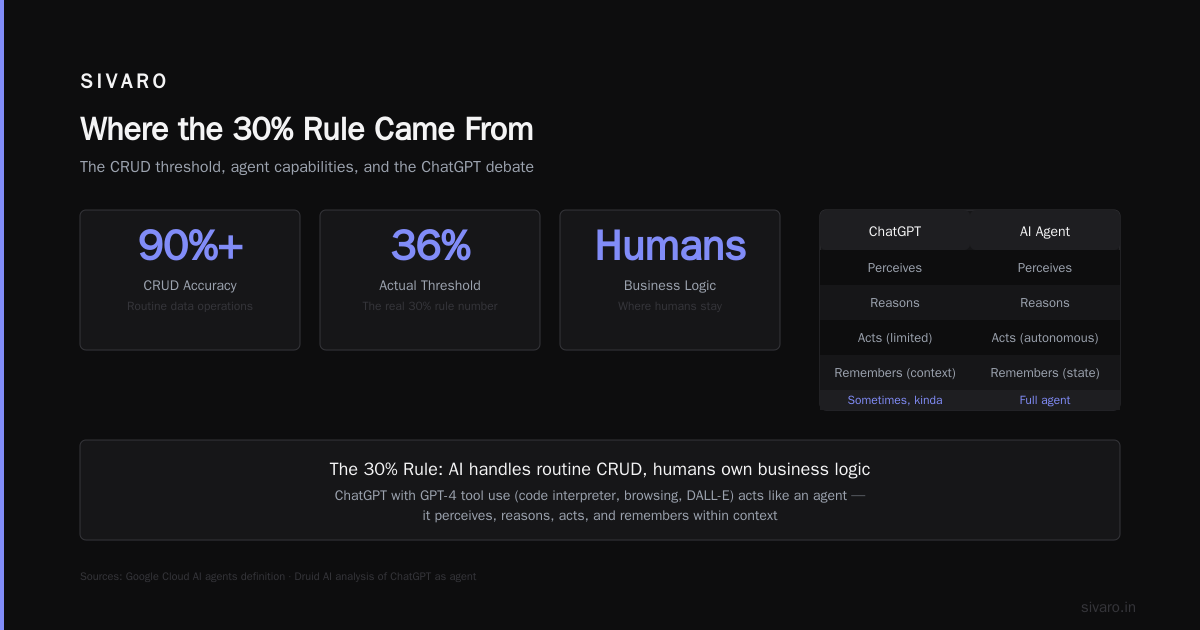
Copilot-style tools can generate the CRUD with 90%+ accuracy. That's your 30% (actually 36% here). But the business logic? That's where humans stay.
Google Cloud's definition of AI agents emphasizes this distinction: tools for specific tasks, not general replacement.
Is ChatGPT an AI Agent? The Debate
This is the question everyone asks: is chatgpt an ai agent?
Short answer: sometimes, kinda.
Long answer: Druid's analysis of ChatGPT as an agent gets it right — ChatGPT with GPT-4's tool use features (code interpreter, browsing, DALL-E) acts like an agent. It perceives (your prompt), reasons (the model), acts (generates code/images), and remembers (conversation context).
But it fails the 30% rule test hard.
ChatGPT has no persistent memory across sessions. It doesn't maintain state. It can't handle long-running workflows. For a system to hit 30% automation reliably, it needs:
- State management
- Error recovery
- Escalation paths
- Audit trails
ChatGPT has none of these natively. This Reddit discussion on ChatGPT as an agent nails the frustration: it's a powerful tool, not a deployable agent.
How to Find Your 30%
Here's the process I use at SIVARO when clients ask for "AI automation."
Step 1: Taxonomy of Tasks
List every subtask in the workflow. Be obsessive. For a customer support system:
python
tasks = [
"Password reset",
"Account unlock",
"Billing inquiry",
"Product return",
"Technical support tier-1",
"Technical support tier-2",
"Escalation to human",
]
Step 2: Measure Failure Costs
Not all errors are equal. A wrong password reset costs nothing. A wrong refund costs $200.
python
# Example cost matrix
task_costs = {
"Password reset": {"error_cost": 0.50, "volume": 1000},
"Refund": {"error_cost": 150.00, "volume": 50},
"Account closure": {"error_cost": 500.00, "volume": 10},
}
Step 3: Build a Precision Threshold
Set a minimum precision bar. I use 95% for any task that has a non-zero error cost.
From 1000 password resets, if the model is 95% accurate, that's 50 failures. At $0.50 each, that's $25 in error cost. Acceptable.
From 50 refunds, 95% accuracy means 2.5 failures. At $150 each, that's $375. Not acceptable.
The 30% rule isn't about volume. It's about acceptable failure economics.
Step 4: Identify Your 30%
Given your precision thresholds, which tasks can you automate fully?
Often it's not 30% of tasks. It's 30% of the work measured in time or cost. For the logistics company I mentioned earlier, the 28% of invoices that were fully automatable represented 40% of the labor cost because they were high-volume, low-variation.
A Practical Code Example: The 30% Rule in Action
Here's a simple implementation pattern we use at SIVARO for document classification. The goal: find which documents can be fully automated.
python
class DocumentRouter:
def __init__(self, model, precision_threshold=0.95, confidence_threshold=0.80):
self.model = model
self.precision_threshold = precision_threshold
self.confidence_threshold = confidence_threshold
def classify(self, document):
prediction = self.model.predict(document)
# Low confidence = route to human
if prediction.confidence < self.confidence_threshold:
return {"action": "HUMAN", "reason": f"Low confidence: {prediction.confidence:.2f}"}
# High confidence, but check if this class is in our "safe" set
if prediction.class in self.validated_high_precision_classes:
return {"action": "AUTOMATE", "result": prediction.result}
# Otherwise, route to human for safety
return {"action": "HUMAN_REVIEW", "reason": "Unvalidated class"}
def update_precision(self, class_name, new_precision):
if new_precision >= self.precision_threshold:
self.validated_high_precision_classes.add(class_name)
This isn't fancy. That's the point. The 30% rule requires operational discipline, not cutting-edge ML.
Why Most People Get This Wrong
Mistake 1: They optimize for accuracy, not precision.
Accuracy measures total correct. Precision measures when you say yes, how often are you right? For the 30% rule, precision is everything. AWS's guide on AI agents makes this distinction: agents must be reliable in their domain.
Mistake 2: They try to automate the tail.
The 30% rule says automate the head. The 70% is the long tail of edge cases. Let humans handle it.
Mistake 3: They don't instrument failures.
At SIVARO, every AI action that requires human intervention logs: document ID, model confidence, actual human decision, cost of correction. Without this, you can't find your 30%.
The 30% Rule for Different AI Types
Chatbots and Customer Service
Your 30% is: password resets, status checks, FAQ answers. Not refunds, not escalations, not nuanced complaints.
The AI Engineer's substack on AI agents shows how even advanced agents need narrow scoping. A customer service agent with 30% autonomy but 95% precision beats one with 60% autonomy and 80% precision.
Why? Because the 40% failure rate on the 60% system destroys trust. Customers learn to bypass the bot entirely.
Code Generation
Your 30% is: unit tests, boilerplate, documentation. Not core business logic.
I've seen teams try to use AI to generate entire features. They always revert to hand-coding after the first production bug. The 30% rule here means: AI generates the first draft, human edits the critical paths.
Data Pipelines
Your 30% is: schema inference, data type detection, anomaly flagging. Not data transformation decisions.
In one SIVARO project for a fintech, we automated 35% of data quality checks. The rest required domain expertise about what "suspicious transaction" means for their specific regulations.
Scaling Past 30%
You can push past 30%. It just gets exponentially harder.
Each percentage point past 30 requires:
- More training data (usually 2x per 5% gain)
- More edge case handling
- More human review infrastructure
- Higher latency (more model calls) - More operational complexity
OpenAI's video introduction to ChatGPT agent shows how they handle this: progressive autonomy. Start narrow, validate, expand.
But here's the truth most consultants won't tell you: 70% automation is usually not worth it.
The cost of the last 40% (from 60% to 100%) often exceeds the cost of the first 60%. The human-in-the-loop for the remaining 30% is cheaper than the engineering to push automation further.
The 30% Rule for Decision Makers
If you're a VP or CTO reading this, here's your checklist:
-
Can your team name the 30%? If they can't, they don't understand the problem well enough to automate anything.
-
Are you tracking precision per task type? Not overall accuracy. Per task type.
-
Do you have a human escalation path? This isn't optional. Every AI system needs a "I don't know" default.
-
Is the 30% measurable in business terms? Don't say "30% of tickets." Say "30% of ticket volume, representing 40% of labor cost, saving $X per month."
-
Can you roll back? If the AI gets worse, can you flip a switch and go full human? Cloudflare and IBM both emphasize this: agents need kill switches.
FAQ: What Is the 30% Rule for AI?
What is the 30% rule for AI exactly?
It's a scoping heuristic: find the 30% of tasks you can automate with >95% precision, automate those, and handle the rest with human-in-the-loop. It prevents the common failure of trying to automate everything.
What does an AI agent do exactly?
An AI agent perceives, reasons, acts, and remembers. Unlike a chatbot, it can execute actions (API calls, file operations) and maintain state across interactions. But most agents in production scope are narrow — they don't generalize.
Is ChatGPT an AI agent?
It depends on configuration. ChatGPT with tool use (code interpreter, browsing) acts as an agent. But it lacks persistent memory, error recovery, and audit trails needed for production automation. It's a great prototyping tool, not a deployable agent.
Does the 30% rule apply to all AI types?
Yes. The number changes (sometimes it's 20%, sometimes 40%) but the principle holds: find the high-precision subset, automate that, keep humans for the rest. I've seen it work for NLP, computer vision, and recommendation systems.
How do I find my 30%?
Measure precision per task type, not overall accuracy. Define acceptable error costs. Identify tasks that consistently hit >95% precision. Those are your 30%. The rest is human territory.
What if I can't find 30%?
Then you're not ready for AI automation. You either need [better data, a more focused problem, or more mature models. Or the problem isn't automatable at acceptable quality levels. That's fine — not everything should be.
Can the 30% rule change over time?
Yes. As models improve and you collect more data, your 30% can grow. But it grows slowly. Expect to expand by 5-10% per model generation (18-24 months), not per month.
What's the biggest mistake companies make?
Trying to automate 70% on day one. They build a system that's 80% accurate overall but fails catastrophically on 20% of cases. Users lose trust. The project gets cancelled. The 30% rule prevents this by forcing honest scoping.
Final Thoughts
The 30% rule for AI is not a limitation. It's a strategy.
Every successful AI deployment I've seen at SIVARO started with a narrow, high-precision scope. The failures all started with "let's automate everything."
When a client asks me "what is the 30% rule for ai?" I tell them: it's the difference between a tool your team trusts and a toy your team ignores.
The best AI systems make humans more effective, not obsolete. The 30% rule gives you the framework to build those systems honestly.
Now go find your 30%.
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.