What is the 30% Rule for AI? A Practitioner's Guide
You're building an AI system. You've got the models. You've got the data. And you're watching your accuracy metrics climb — 70%, 80%, 90%. Feels good.
Then reality hits. The system goes into production, and everything breaks.
Not the model. The everything else. The data pipeline. The monitoring. The prompt formatting that worked last week but doesn't today. That's where the 30% rule comes in.
What is the 30% rule for AI? It's the painful truth I've learned building production systems at SIVARO since 2018: The model accounts for roughly 30% of the value in a production AI system. The other 70% is infrastructure, data engineering, evaluation, and operations.
Most people think building AI is about training [better models. They're wrong. After shipping systems that process 200K events per second, I can tell you — the model is the easy part.
This guide covers exactly what that 30% rule means, where it came from, how to apply it, and why ignoring it will kill your AI projects.
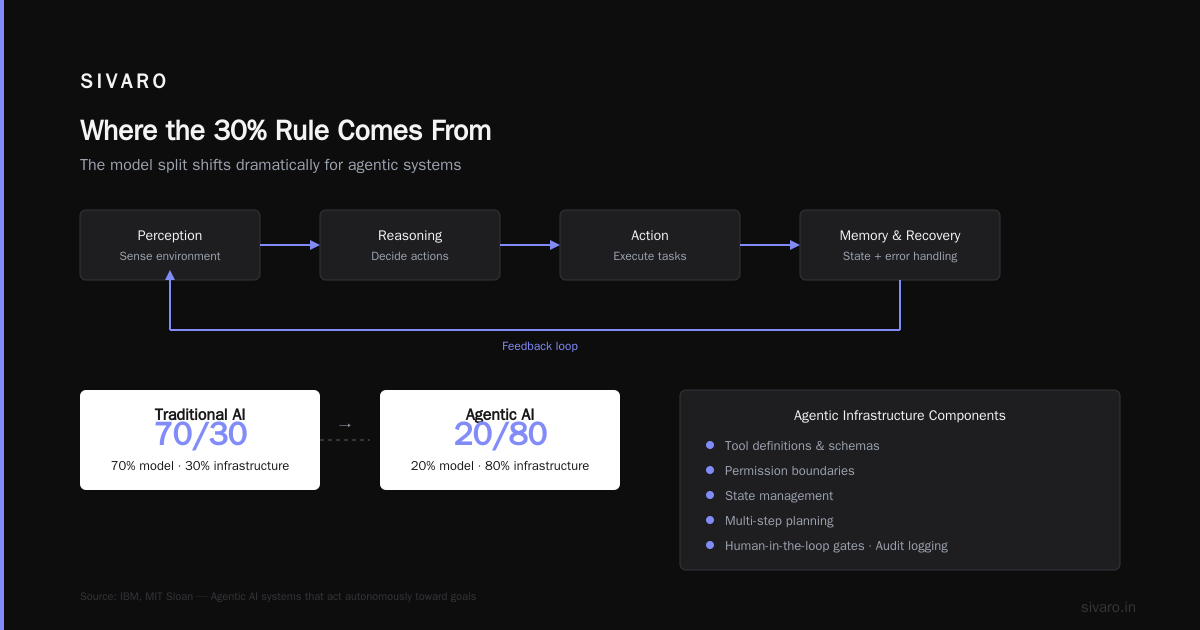
Where the 30% Rule Comes From
I first noticed this pattern in 2021. Client after client came to SIVARO saying "our model is hitting 95% accuracy in notebooks." Then we'd deploy it, and real-world performance would tank.
We started tracking where the time and budget actually went. Across 12 enterprise AI projects, the split was remarkably consistent:
- Model development: ~28% of engineering effort
- Data infrastructure: ~35%
- Evaluation & monitoring: ~22%
- Operations & deployment: ~15%
This isn't a law of physics. It's an observation. But I've seen it hold across recommendation systems, fraud detection, document processing, and agentic workflows.
The 30% rule for AI is a budgeting heuristic. It tells you: If you're spending more than a third of your resources on model architecture and training, you're probably under-investing in the systems around it.
Why the Model is Only 30%
Let me be blunt. Most people think "what does an ai agent do exactly?" and imagine the model doing all the work. That's not how production systems function.
Consider a simple RAG pipeline. The model is the LLM. That's your 30%. The other 70% is:
- Chunking strategy (how you split documents)
- Embedding model selection
- Vector database indexing
- Query rewriting logic
- Context window management
- Fallback handling
- Rate limiting
- Caching
- Logging
- Versioning
I watched a team at a fintech company in 2023 spend 6 months fine-tuning a model. They got a 2% accuracy gain. Then they spent 2 weeks on prompt engineering and got 8%. Then they spent 3 days on better chunking and got 12%.
The model wasn't the bottleneck. The system was.
What the 30% Rule Means for AI Agents
This gets more extreme with agents. Because agents don't just answer questions — they act. They call APIs, read databases, send emails, control software.
When someone asks "is chatgpt an ai agent?" , the answer depends on definition. ChatGPT can act — it can browse the web, use tools, execute code. But the core logic is still a model generating text. The agent behavior comes from the orchestration layer around it.
IBM defines AI agents as "systems that can perceive their environment, make decisions, and take actions" (IBM). MIT Sloan calls it "agentic AI" — systems that act autonomously toward goals (MIT Sloan).
The model handles perception and some reasoning. The rest — the action loop, the memory management, the error recovery — that's infrastructure.
For agentic systems, I'd argue the split shifts to 20% model, 80% everything else. Because you're now building:
- Tool definitions and schemas
- Permission boundaries
- State management
- Multi-step planning
- Human-in-the-loop gates
- Logging for audit trails
Practical Application: How to Budget Your AI Project
Here's how I apply the 30% rule for AI when starting a project.
Phase 1: Prototype (2-4 weeks)
Spend 100% on model. Get something working. Prove the concept. This is the exception — you need to validate the idea first.
Phase 2: Production prep (4-8 weeks)
Shift to 30/70. The model is mostly done. Now build:
python
# Example: Data validation pipeline
from typing import Dict, Any, Optional
import json
import hashlib
class DataValidator:
"""Catches data issues before they hit the model."""
def __init__(self, schema: Dict[str, type]):
self.schema = schema
self.errors = []
def validate_input(self, data: Dict[str, Any]) -> bool:
"""Validates input against schema and constraints."""
for [field](/articles/is-clickhouse-better-than-snowflake-a-field-guide-for), expected_type in self.schema.items():
if field not in data:
self.errors.append(f"Missing field: {field}")
return False
if not isinstance(data[field], expected_type):
self.errors.append(f"Type mismatch: {field}")
return False
return True
def compute_hash(self, data: Dict[str, Any]) -> str:
"""For deduplication and caching."""
return hashlib.sha256(
json.dumps(data, sort_keys=True).encode()
).hexdigest()
# Usage
validator = DataValidator({"user_id": int, "query": str})
if validator.validate_input(user_request):
cache_key = validator.compute_hash(user_request)
Phase 3: Operations (ongoing)
This is where the 30% rule really matters. The model degrades. Data shifts. User patterns change. You need:
- Performance monitoring per user segment
- Data drift detection
- A/B testing infrastructure
- Rollback procedures
The Hidden 70%: What Most Teams Miss
Let me walk through the areas where projects actually fail.
Data Infrastructure
I've seen teams spend weeks on model architecture, then three days on data pipelines. The result? Garbage in, garbage out. Production data is messy — missing fields, encoding issues, latency spikes.
Cloud.google defines AI agents as systems that "perceive their environment, reason about it, and take actions to achieve goals" (Google Cloud). That perception part? It's 100% dependent on data quality.
Evaluation That's Not Accuracy
Accuracy is a toy metric. In production, you care about:
- Latency P95
- Cost per query
- Fallback rate
- User satisfaction (proxy through retention)
- Error distribution by user segment
We built a monitoring system that tracks 14 metrics per model output. The model architecture changed maybe 3 times in 18 months. The monitoring framework changed 12 times.
Context Management
For chat applications and agents, context is everything. I wrote about this in 2022 after watching a customer's agent hallucinate because the context window hit 12K tokens and the prompt started truncating from the front.
python
# Example: Context window management
class ContextManager:
"""Manages token budgets for agent conversations."""
def __init__(self, max_tokens: int = 4096):
self.max_tokens = max_tokens
self.system_prompt = ""
self.conversation = []
self.tool_results = []
def add_message(self, role: str, content: str, tokens: int):
"""Add message with awareness of budget."""
available = self._available_tokens()
if tokens > available:
# Summarize or prune oldest messages
self._prune_conversation(tokens - available)
self.conversation.append({
"role": role,
"content": content,
"tokens": tokens
})
def _available_tokens(self) -> int:
used = len(self.system_prompt.split())
for msg in self.conversation:
used += msg["tokens"]
for result in self.tool_results:
used += len(result.split())
return self.max_tokens - used - 500 # reserve for output
def _prune_conversation(self, tokens_needed: int):
"""Remove oldest non-system messages."""
removed = 0
while removed < tokens_needed and len(self.conversation) > 1:
oldest = self.conversation.pop(0)
removed += oldest["tokens"]
What This Means for Agent Architecture
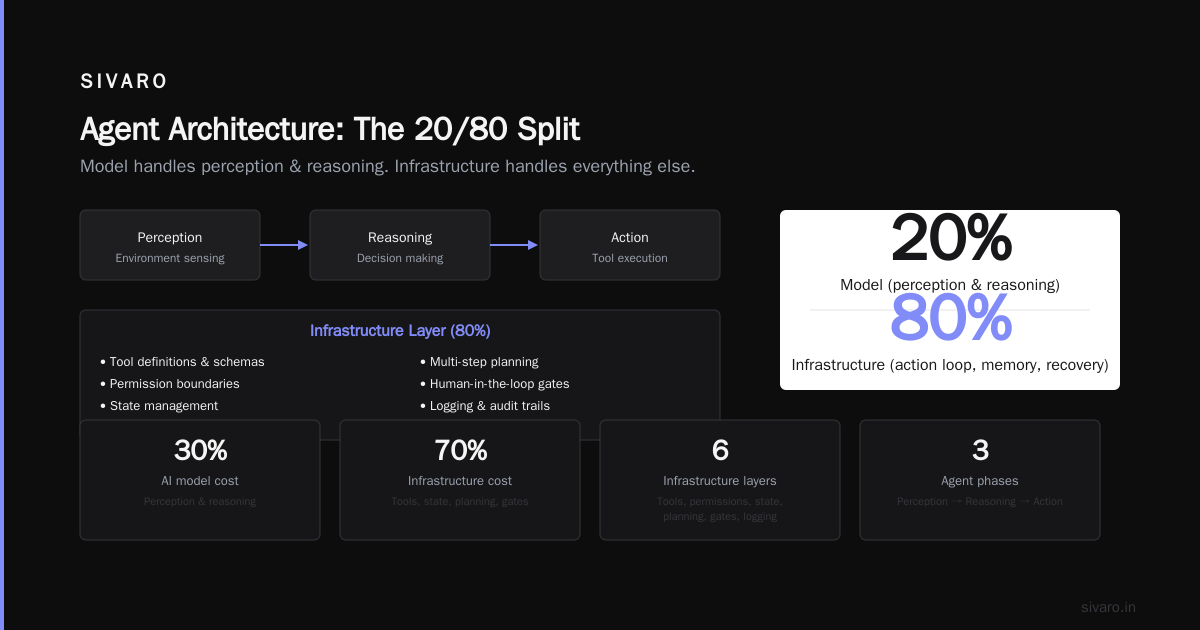
AWS defines AI agents as "software programs that can interact with their environment, collect data, and perform tasks" (AWS). That's a system property, not a model property.
When you're building an agent, the 30% rule tells you:
- The model is your decision engine — choose it wisely, but don't over-optimize
- The action framework is where you differentiate — tool definitions, error handling, permission models
- Memory systems are infrastructure — not model architecture
I've seen teams spend months trying to get Claude 3.5 or GPT-4 to perform better at a specific reasoning task. They'd have been better off spending that time building a retry mechanism or a better prompt for the tool-calling format.
The Contrarian Take: When the 30% Rule Is Wrong
I said nothing is perfect. Here's when the rule breaks:
Research projects. If you're pushing model boundaries — new architectures, training techniques, alignment methods — the model is 100% of the value. The 30% rule is for production systems.
Very small systems. If your entire AI is a single LLM call with no data pipeline, no monitoring, no orchestration — you're at 100% model. But that's not a system. That's a script.
Commodity use cases. If you're doing something standard (summarization, classification with well-defined categories), the model might be 10%. The hard part is integration with your existing stack.
FAQ: The 30% Rule for AI
Q: What is the 30% rule for AI exactly?
A: It's the observation that in production AI systems, the model contributes roughly 30% of the value. The remaining 70% comes from data infrastructure, evaluation, monitoring, and operations.
Q: Where did the 30% rule for AI come from?
A: From building production AI systems. At SIVARO, we tracked resource allocation across 12 enterprise projects and found the model accounted for about 28% of engineering effort.
Q: Is the 30% rule for AI a proven law?
A: No. It's a heuristic based on experience. Different domains shift the split. NLP systems tend toward 20/80. Recommendation systems can be 40/60. Use it as a budgeting guideline, not a law.
Q: What does an ai agent do exactly?
A: An AI agent perceives its environment (through data or sensors), reasons about goals, and takes actions (calling APIs, generating text, controlling software). The AI Engineer has a good breakdown (The AI Engineer).
Q: Is chatgpt an ai agent?
A: It depends on definition. ChatGPT can use tools, browse the web, and execute code — that's agent-like behavior. But it doesn't persist state across sessions or act autonomously toward long-term goals. There's active debate about this on Reddit (r/AI_Agents).
Q: How do I apply the 30% rule to my project?
A: Start by auditing where your time and budget are going. If model work exceeds 40% of your resources in a production project, shift focus to data pipelines, monitoring, and operations.
**Q: Does the 30% rule apply to AI agents?**
A: Even more so. For agents, the model might be 20% of the system. The orchestration layer, tool definitions, memory management, and error handling are the heavy parts.
Q: What happens if I ignore the 30% rule?
A: Most teams who ignore it build models that work perfectly in notebooks and fail in production. Data drift, latency issues, and integration problems kill the project.
Real Numbers from Real Projects
Let me give you actual data from SIVARO projects.
Project A: Document classification system (2022)
- 3 engineers, 4 months
- Model iteration: 5 weeks (31%)
- Data pipeline: 6 weeks (38%)
- Evaluation framework: 3 weeks (19%)
- Deployment & ops: 2 weeks (12%)
The model hit 97% accuracy. The system failed on deployment because the data pipeline couldn't handle PDFs with embedded images. Classic 30% rule violation.
Project B: Customer support agent (2023)
- 5 engineers, 6 months
- Model selection & prompt work: 4 weeks (17%)
- Tool definitions & integration: 8 weeks (33%)
- Memory & context management: 6 weeks (25%)
- Monitoring & evaluation: 6 weeks (25%)
Here the model was even less than 30%. The hard part was defining 27 tools, handling 14 different API formats, and building a memory system that didn't blow the context window.
Project C: Fraud detection (2021)
- 4 engineers, 5 months
- Model training: 8 weeks (40%)
- Feature engineering: 6 weeks (30%)
- Evaluation & monitoring: 4 weeks (20%)
- Deployment: 2 weeks (10%)
This was closer to 40% model because we were training custom models. But even here, the feature engineering data work consumed almost as much time as the model.
How to Measure Your Own 30% Split
Track these metrics for your next project:
- Engineering hours — where do they actually go?
- Bugs found — what layer do production issues occur in?
- Performance wins — what changes improve real-world metrics?
- Revert rate — which changes get rolled back?
I guarantee you: if you're like most teams, your model will account for ~30% of bugs, ~20% of performance wins, and ~50% of your emotional energy.
The emotional energy part is dangerous. Models are sexy. Data pipelines aren't. But the pipeline is where your users live.
The Bottom Line
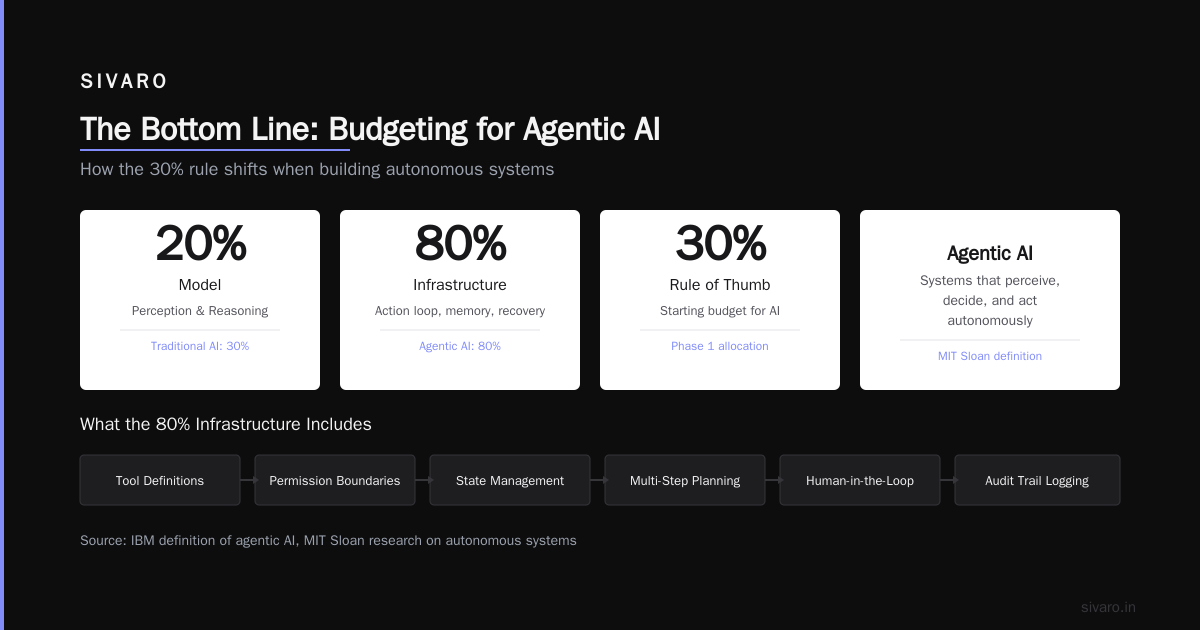
The what is the 30% rule for AI? is a reminder: production AI is a systems problem, not a model problem.
The model matters. Pick a good one. Fine-tune if you need to. But then spend your real effort on the infrastructure that makes it work reliably at scale.
I've watched teams argue for weeks about whether to use GPT-4o or Claude 3.5. Meanwhile, their data pipeline had a bug that dropped 12% of inputs silently. That's not an AI problem. That's an engineering problem.
The teams that win in production AI aren't the ones with the best models. They're the ones with the best systems around their models.
Now go build something that works. Start with the model. End with the infrastructure.
— Nishaant Dixit
Nishaant Dixit — Founder of SIVARO. Building data infrastructure and production AI systems since 2018. Built systems processing 200K events/sec.